
小记:自 2023 年以来,电商多模态表征模型 MOON 历经 3 年多的持续建设与迭代升级,已在阿里妈妈搜索直通车全面落地,并在多个核心场景中取得显著效果。以精排 CTR 预估模型为例,累计全量 5 期,带来大盘 CTR +20% 的显著提升。最新的 MOON 2.0 中,团队首次提出动态模态平衡机制,解决了多任务联训中长期存在的跷跷板效应,实现了从"任务统一"到"模态协同"的关键跨越。该工作已被 CVPR'26 接收。
1. 背景
在电商搜索场景中,用户的一次搜索往往同时触及商品的多个模态维度。以搜索"小香风外套"为例,系统不仅需要从商品主图中识别 "编织纹理" 与 "版型设计" 等关键元素,还需从商品文本中解析"羊毛"、"短款"、"春季新款"等关键属性,更需要综合判断图像与文本所描述的是否为同一件商品。这一过程的背后,折射出不同模态在信息表达上的天然互补性:图像直观呈现形态、颜色与设计元素,文本则更擅长承载品牌、材质、功能及适用场景等结构化语义,任何单一模态都仅能覆盖商品信息的部分维度,难以独立支撑精准的商品理解与匹配。
然而真正加剧这一挑战的,是商品信息天然具有的"多对一复杂结构"(如下图所示):一件商品往往同时关联多张图(主图、SKU 图与创意图等),以及由标题、详情描述等构成的长文本,各模态在信息密度与语义覆盖范围上存在显著差异,甚至存在冗余乃至冲突。如何在统一的语义空间中有效对齐并融合这些多源异构信号,使模型不仅能够判断商品“是否相似”,更能深入理解"语义是否一致、细节差异究竟在哪里",正是电商多模态表征学习面临的核心挑战。
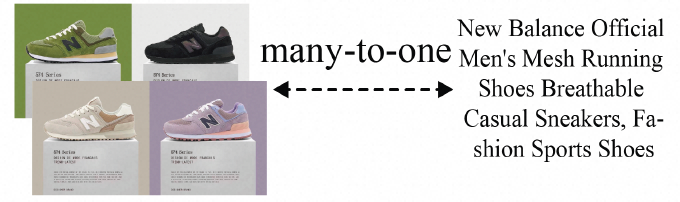
从技术演进来看,多模态表征方法经历了从浅层融合到视觉语言模型(VLM)再到多模态大语言模型(MLLM)的持续跃迁:
早期方法通过独立编码器将图像与文本分别映射至共享空间,实现粗粒度的图文对齐;
VLM 时代引入大规模图文预训练,推动表征从浅层特征拼接迈向更深层的跨模态交互;
MLLM 则进一步将视觉感知纳入语言推理框架,使表征的能力边界从简单的匹配判断拓展至深层的内容理解、关系推理乃至更复杂的认知任务。
顺应这一演进趋势,MOON 系列也在持续迭代,不断探索更强的统一建模能力、更精细的语义理解水平与更广泛的任务泛化能力。
2. 思考
经过多轮迭代,我们对多模态表征的定位有了更深刻的认识。多模态表征作为电商场景的底层基础能力,其核心挑战已不再局限于提升单一商品的建模精度,而是延伸至如何构建一套统一的表征体系,以支撑丰富而复杂的下游任务生态。这一判断源自两方面的实践体会:
全链路视角:多模态表征需贯穿 Query 理解、召回、相关性判定、排序等搜索全链路环节,各环节共享一致的语义表示是实现信息无损传递的前提,任何环节之间的表征割裂都将引发语义偏移的逐级放大,最终制约端到端效果的上限;
任务覆盖维度:一个理想的电商多模态表征模型应能同时支撑图搜、文搜、商品搜、商品分类、属性预测等多类核心任务,具备跨输入形式、跨任务目标、跨语义粒度的协同建模能力,从而以一套统一的表征底座实现多任务能力复用,提升整体研发迭代效率。
然而,在传统方案中这一目标尚未达成。不同任务往往依赖各自独立的表征体系进行建模:检索侧重跨模态对齐,分类聚焦类别判定,属性预测强调细粒度识别,彼此割裂、语义知识难以共享。这种"任务烟囱"式的建模方式,不仅破坏了商品语义的整体性,还带来了高昂的重复建设与维护成本。基于此,团队认为更具系统性的技术路径是构建面向电商全场景的通用多模态表征框架,在统一的建模范式下整合不同任务目标、不同输入模态以及不同层级的商品语义知识,实现表征能力的共享、迁移与协同优化。围绕这一目标,亟待解决的关键问题包括:
异构任务统一建模:如何在统一框架下同时支撑图搜、文搜、商品搜、分类、属性预测等多类异构任务,实现检索匹配能力与语义判别能力的协同建构;
动态模态平衡:如何灵活适配图像、文本及其组合等不同模态输入,并根据任务需求动态调节模态间的融合策略与权重平衡;
多粒度语义表征:如何在统一语义空间中同时建模商品的整体粗粒度语义与局部属性级细粒度语义,兼顾全局相似性度量与细粒度特征判别。
基于上述思考,我们正式启动了 MOON 系列的研究探索。作为首个阶段性成果,MOON 1.0 聚焦于异构任务统一建模这一核心问题,首次提出了基于生成式 MLLM 的电商多模态表征框架。如下图所示,MOON 1.0 通过对图搜、文搜、商品搜等多源异构任务数据进行联合训练,构建跨任务共享的统一语义空间;在此基础上,引入专家混合引导机制,针对不同模态输入及商品类别、属性等关键语义维度进行差异化建模,在统一框架内实现多任务语义的协同表达与联合优化,从而推动多模态表征从"任务专用"的独立建模范式迈向"统一底座"的协同建模范式。
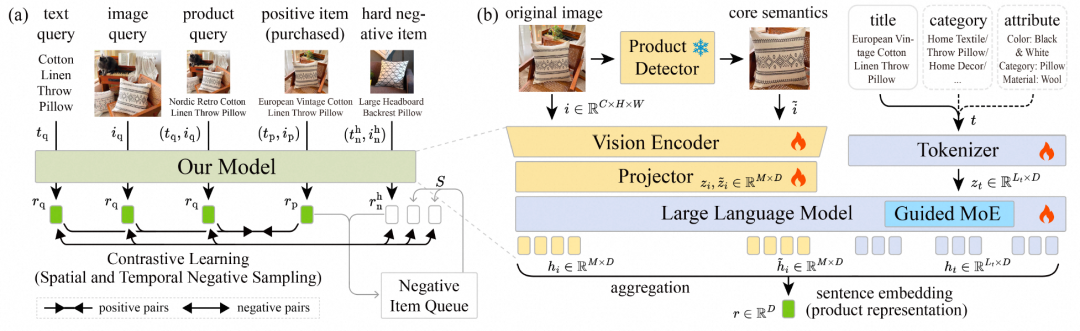
MOON 1.0 初步验证了统一表征底座在电商全场景落地的可行性与有效性,为后续持续演进奠定了坚实基础。其核心研究成果已被 WSDM'26 正式收录,基于该表征在 CTR 预估模型中的落地实践也已形成技术报告公开发布:
WSDM'26:MOON: Generative MLLM-based Multimodal Representation Learning for E-commerce Product Understanding (https://arxiv.org/abs/2508.11999)
技术报告:MOON Embedding: Multimodal Representation Learning for E-commerce Search Advertising (https://arxiv.org/abs/2511.11305)
然而,MOON 1.0 的实践也暴露出一个关键瓶颈——跷跷板效应(如下图所示),在不同任务数据配比下,图搜与文搜的能力始终难以协同增长,一方的提升必然伴随另一方的退化。这一现象表明,简单的数据混训实现的只是形式上的统一,而非真正稳定的联合优化。
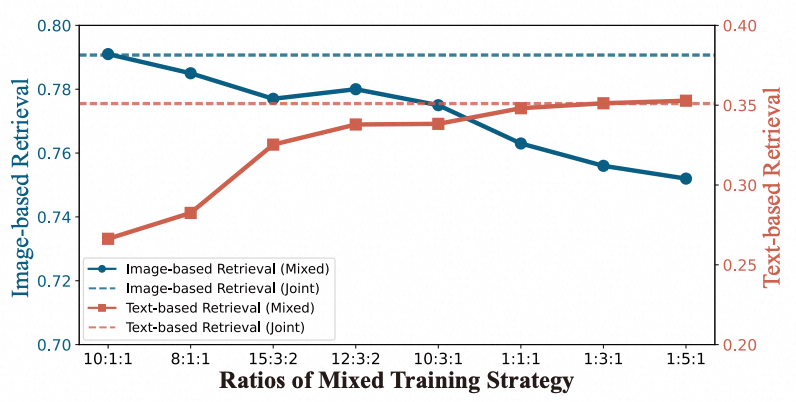
深入分析后发现,问题的根源并不在于多任务本身是否联合,而在于多模态能否在统一框架下实现稳定的动态平衡。不同任务的数据配比会隐式改变各模态在训练过程中的主导地位,当某一模态占据主导时,模型表征将逐渐偏向该模态的语义分布,换言之,图搜与文搜并未形成真正的协同优化,而是在共享参数空间中竞争有限的表示容量。这一发现将研究重心自然引向了前文所提出的第二个核心问题:动态模态平衡。
围绕这一核心问题,团队进一步提出了 MOON 2.0。相较于 MOON 1.0 对异构任务统一建模的初步探索,MOON 2.0 将研究重心从"任务整合"推进至"模态协同",聚焦于动态模态平衡这一关键瓶颈。具体而言,MOON 2.0 通过模态自适应的专家混合建模机制、双重语义对齐机制与图文协同增强三项关键技术设计,首次在电商场景下实现了面向动态模态平衡的多模态表征学习,有效缓解了模态主导偏移与跷跷板效应,为通用电商多模态表征基座的构建提供了新的技术范式。
CVPR'26:MOON2.0: Dynamic Modality-balanced Multimodal Representation Learning for E-commerce Product Understanding (https://arxiv.org/abs/2511.12449)
3. MOON 2.0
3.1 方法
MOON 2.0 Pipeline 如图所示,从架构、训练、数据三个层面系统性地解决动态模态平衡问题,分别对应 Modality-driven MoE、Dual-level Alignment、Image-text Co-augmentation 三个关键模块。具体如下:
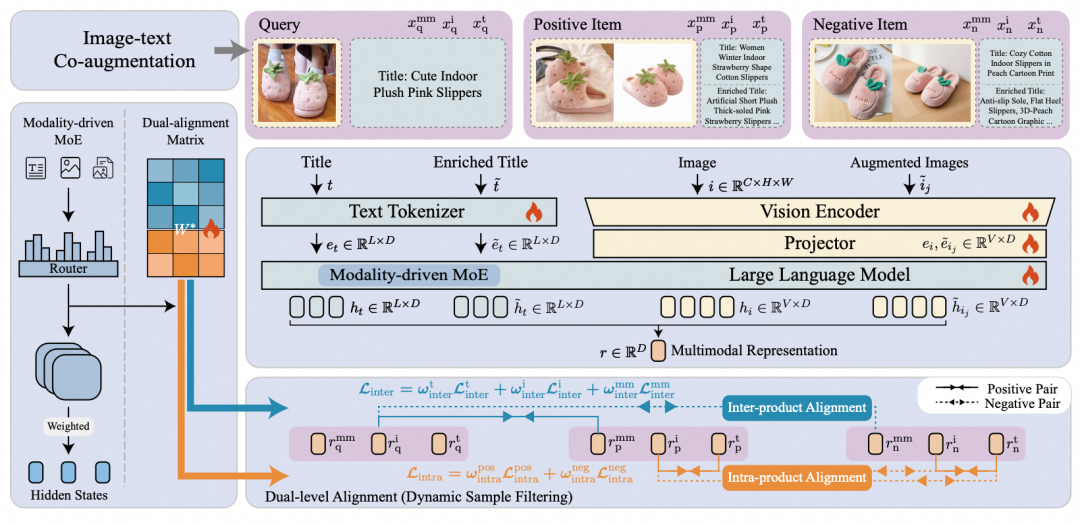
Modality-driven MoE:通过模态自适应的专家混合建模机制,模型能够在训练过程中自适应地调节不同模态的贡献权重,从而不再依赖静态数据配比被动适应模态差异,而是主动实现模态间的动态平衡,有效避免某一模态长期占优所导致的表征偏移。
如图(a)所示,将 Mixture-of-Experts(MoE)机制嵌入表征模型的 LLM FFN 层,为不同模态信号的差异化处理提供结构性基础。
如图(b)所示,不同于传统 MoE 主要依赖 token 级激活信号进行路由,MOON 2.0 进一步引入可学习的双重对齐偏好矩阵(Dual-alignment Matrix),用于显式刻画每个专家对不同对齐目标(如文本-多模态对齐、图像-多模态对齐)的内在偏好与适配能力,并配合稀疏正则化约束,推动不同专家在特定模态对齐目标上形成清晰的专业化分工。
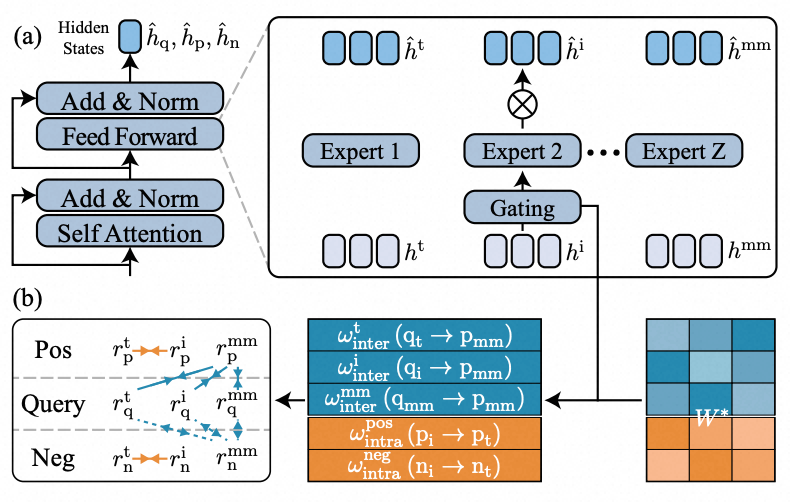
Dual-level Alignment:通过双重语义对齐机制,构建了从商品间匹配到商品内一致性的层次化对齐范式,在统一框架下联合优化商品间(Inter-product)与商品内(Intra-product)两类对比目标:前者聚焦于跨模态检索匹配,确保不同模态查询与目标商品在语义空间中的精准关联;后者则约束同一商品不同模态表征之间的语义一致性,确保图像、文本等多源信号对同一商品的语义刻画趋于稳定统一。两者协同作用,不仅提升了跨模态检索的匹配精度,也显著增强了统一表征对商品语义的稳定刻画能力。
Inter-product Alignment:基于三元组(Query, Positive, Negative)进行跨商品对比,学习商品间的检索与匹配关系。 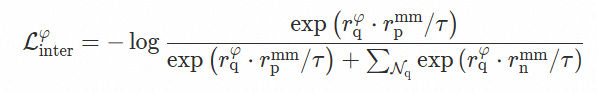
Intra-product Alignment:显式约束同一商品内部图像表征与文本表征的语义一致性,强化“多对一”场景下的图文细粒度对齐。 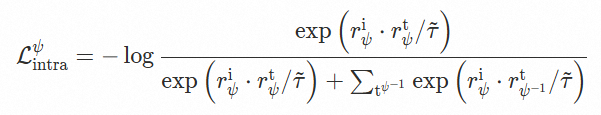
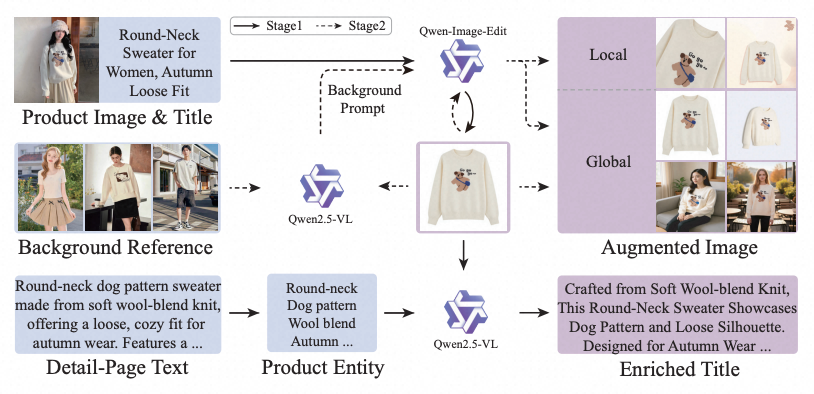
Image-text Co-augmentation:在图文协同增强方面,利用 MLLM 的生成能力对训练数据进行增强,通过生成更丰富的图像描述与文本改写,有效提升多模态表征学习的数据多样性与语义覆盖度。同时,考虑到生成式增强不可避免地引入噪声,MOON 2.0 进一步设计了自适应样本过滤策略(Dynamic Sample Filtering):训练初期,对高置信度样本赋予更高权重,以建立稳定可靠的监督信号基础;随着训练推进,逐步将优化重心向困难样本倾斜,实现从"高质量监督优先"到"困难样本精炼"的渐进式过渡,在充分利用增强数据的同时有效抑制噪声干扰。
图像增强:采用两阶段图像编辑策略,首先提取商品主体,再基于上下文语义引导生成背景多样化、视角多变的增强图像,在丰富视觉多样性的同时严格保留商品核心属性;
文本增强:利用 MLLM 联合商品详情页信息与图像视觉线索,提取关键实体并生成语义更完整、场景覆盖更广的增强标题,弥补原始标题信息稀疏或表述单一的不足。
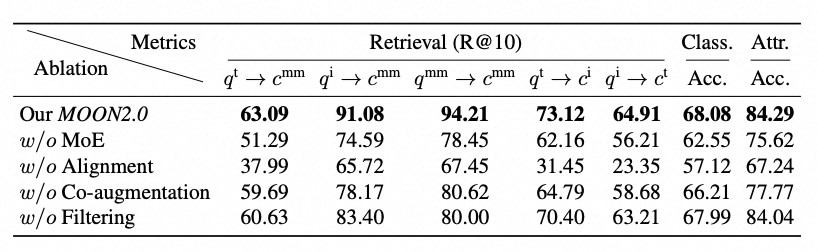
移除 Modality-driven MoE:各项检索指标出现大幅下降,其中"图搜商品" R@10 从 91.08% 降至 74.59%,"商品搜商品"从 94.21% 降至 78.45%,分类与属性预测准确率也分别下降 5.53% 和 8.67%。这表明模态驱动的专家路由机制是实现动态模态平衡的关键基础;
移除 Dual-level Alignment:所有指标出现显著下降,尤其是跨模态检索"图搜文" R@10 从 64.91% 骤降至 23.35%,分类与属性预测准确率也分别下降近 11% 和 17%。这一结果充分说明,双粒度语义约束是构建稳定跨模态语义空间的核心支撑;
移除 Image-text Co-augmentation:检索性能出现中等幅度下降,"商品搜商品"从 94.21% 降至 80.62%,"图搜商品"从 91.08% 降至 78.17%,分类与属性准确率也有所下降。这验证了基于 MLLM 的数据增强对于提升训练数据多样性与语义覆盖度的重要作用;
移除 Dynamic Sample Filtering :各项指标出现小幅下降,"文搜商品"从 63.09% 降至 60.63%,图搜商品从 91.08% 降至 83.40%,表明自适应训练策略能够有效抑制增强数据中引入的噪声干扰。
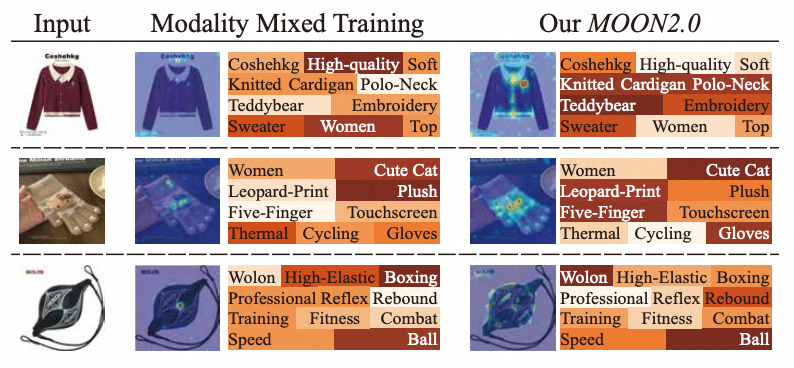
热力图 :从泛化词汇到核心属性。如下图所示,传统混合训练模型倾向于将注意力分散在"high quality"、"women"等泛化词汇上,而 MOON 2.0 能够精准聚焦于"knitted cardigan"、"polo-neck"、"Teddybear"等核心商品属性,这正是动态模态平衡带来的细粒度图文对齐能力提升。
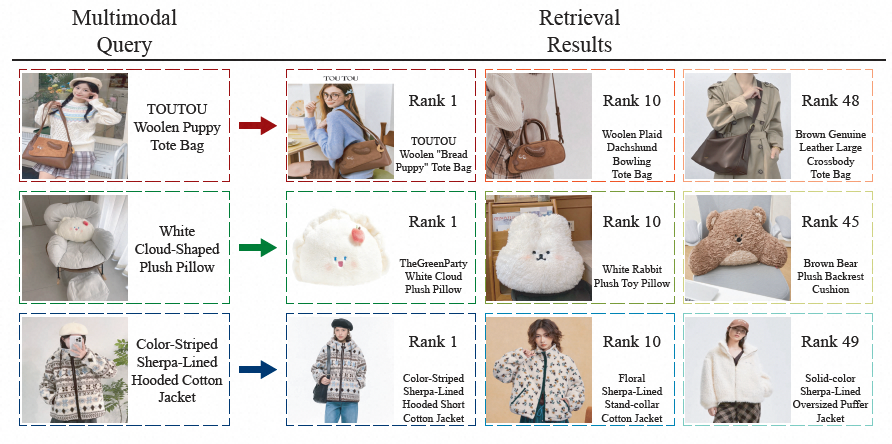
检索结果 :为进一步评估 MOON 2.0 在多样化电商场景下的检索效能与泛化能力,我们基于平台全量搜索数据库随机抽取了 500 万样本构建大规模检索集,对三类检索任务的实际召回结果进行了可视化展示。结果表明,MOON 2.0 的表征对同款与相似款具备良好的区分能力,能够在大规模候选集中精准定位同款商品,同时对相似款保持有意义的语义排序,验证了其表征空间的判别性与结构性。
MOON 1.0 :聚焦异构任务的统一建模,首次提出基于生成式 MLLM 的电商多模态表征框架,通过多任务联合学习将图搜、文搜、商品搜及分类等异构任务纳入统一表征空间,验证了"一个模型服务所有任务"的技术可行性。(WSDM'26)
MOON 2.0 :聚焦动态模态平衡这一核心问题,通过 Modality-driven MoE、Dual-level Alignment 与 Image-text Co-augmentation 三项关键设计的协同,有效解决了多任务联训中长期存在的跷跷板效应,在自建基准 MBE 2.0 及 M5Product、Fashion200K 等公开数据集上均达到全面 SOTA。(CVPR'26)
多粒度语义表征:构建从全局语义到细粒度属性的层次化表征体系,实现跨粒度的精准刻画与灵活解耦,为不同下游任务提供"按需取用"的语义支撑;
感知-推理-生成一体化:以大模型为引擎,推动表征范式从感知匹配向感知-推理-生成的深度融合跃迁,不止于"知其然"的语义关联,更追求"知其所以然"的归因推理与可解释决策,开启从商品理解到推理的新范式。
3.2 实验结果
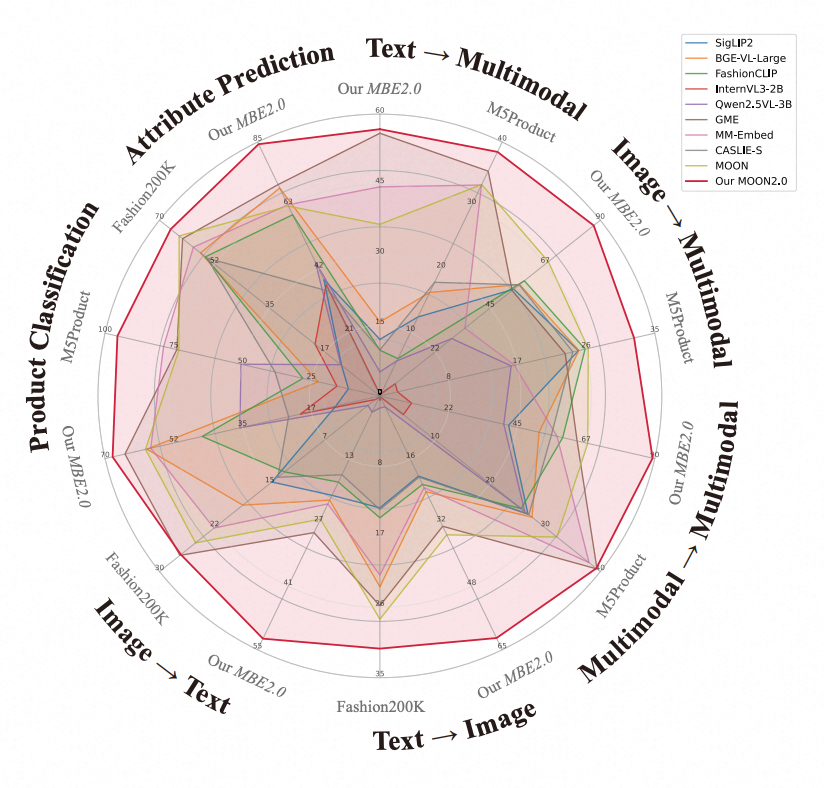
为系统性评估多模态表征在电商场景下的综合能力,我们构建了 MBE 2.0 基准数据集(如下图所示),涵盖 640 万真实电商样本,同时支持检索(图搜、文搜、商品搜)、分类与属性预测三大类任务,是目前电商领域最为全面的多模态表征评测基准之一。

为全面验证 MOON 2.0 的方法有效性,我们在 MBE 2.0、M5Product 及 Fashion200K 三个数据集上进行了零样本(Zero-shot)评测。如雷达图所示,MOON 2.0 在三个数据集上均取得 SOTA 表现,表明其表征不仅在检索场景中表现优异,在分类与属性预测任务中同样展现出强大的泛化能力。
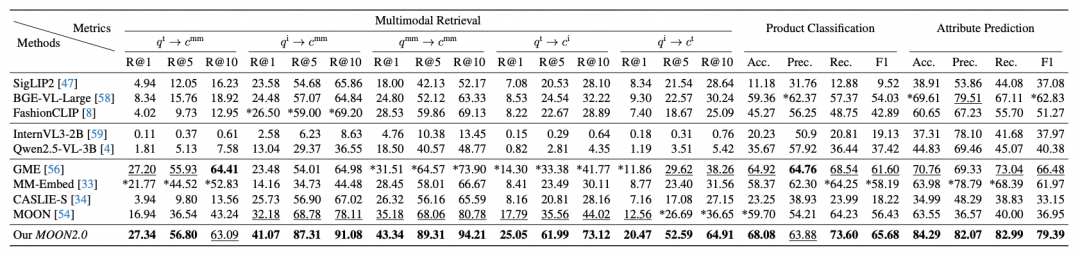
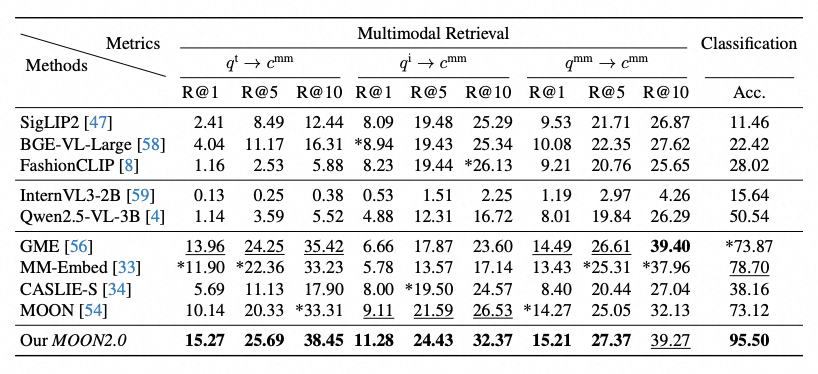
如表1所示,在 MBE 2.0 基准上,MOON 2.0 不仅全面超越了 GME、MM-Embed 等通用多模态表征,也优于 CASLIE-S 、MOON 1.0 等电商领域专用表征。以检索任务为例,MOON 2.0 在
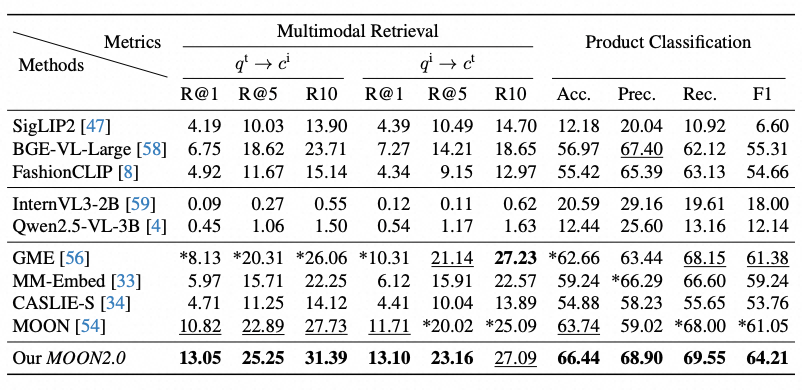
在跨数据集评测中,MOON 2.0 在 M5Product和 Fashion200K两个公开基准上均取得了领先表现(表 2、表 3),验证了其在不同商品品类与数据分布下的良好泛化性。
为验证各核心模块的贡献,我们进行了详尽的消融实验,结果如下表所示:
3.3 可视化分析
为直观展示 MOON 2.0 的多模态理解能力,我们从图文对齐质量和检索效果两个维度进行了可视化分析。


4. 总结展望
MOON 系列围绕电商多模态表征的核心挑战持续演进,完成了从"任务统一"到"模态协同"的关键跨越,为构建下一代通用电商多模态表征基座奠定了坚实的技术基础。
展望未来,MOON 系列将沿两条核心路径持续演进,最终迈向具备深层语义理解与自主推理能力的下一代电商多模态表征基座:
💡 关于我们
阿里妈妈搜索直通车多模态团队负责多模态技术的研发和应用,专注于多模态大模型、智能创意、图搜、多模态多场景建模等方向。近年在CVPR、KDD、SIGIR、WSDM等学术会议上发表多篇论文,同时真诚欢迎具备CV、NLP和推荐系统相关背景的同学加入!
📮 简历投递邮箱:wanxian.gwx@taobao.com

也许你还想看
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢