
点击蓝字
关注我们

2026年3月,斯坦福大学一支跨学科研究团队在arXiv发布研究报告《Mirage: The Illusion of Visual Understanding》(《海市蜃楼:视觉理解的幻觉》)。这篇报告的作者阵容相当豪华——计算机科学界的教母级人物李飞飞领衔,研究团队成员横跨电气工程、心脏病学、生物医学数据科学、计算机科学及精神病学等多个领域,通过系统性实验揭示了一个令人不安的事实:当前前沿多模态AI模型在未接收到任何图像输入的情况下,依然能够生成详尽的图像描述和复杂的推理链条,并在主流视觉基准测试中取得与有图时接近的分数。

报告共同作者、斯坦福医学院Euan Ashley教授发推称:“一开始以为只是有趣的漏洞,很快就会被堵上。结果我大错特错。”
从背景来看,多模态AI系统已被广泛应用于从通用图像理解到医疗诊断的各个领域,用户和临床工作者对其输出的信任度日益提升。尤其是“推理模型”(thinking models)的出现,通过展示模型的思考过程,进一步增强了人们对输出可靠性的信心。然而,当前对多模态模型视觉能力的评估,几乎完全依赖于各类公开基准测试(如MMMU-Pro、VQA-Rad、MicroVQA等)。这些基准的隐含假设是:模型答对的问题越多,其视觉理解能力就越强。
本研究的核心贡献在于提出了一个此前未被系统研究的现象——“海市蜃楼推理”(Mirage Reasoning)。研究者明确区分了这一现象与已被广泛研究的“幻觉”(Hallucination):幻觉是在正确的认知框架内填充不真实的细节(如捏造引用),而海市蜃楼推理则涉及模型构建一个完全虚假的认知框架——表现得如同真的接收到了图像输入,并基于这个不存在的视觉信息进行推理,且不表达任何不确定性或提示用户图像缺失。
具体而言,研究团队通过三大类实验展开研究:一是设计Phantom-0基准(200道无图视觉问题,跨越20个领域),测量模型的“海市蜃楼率”;二是对比同一模型在有图与无图(未告知)条件下在六大主流基准上的准确率,计算“海市蜃楼分数”;三是训练一个30亿参数的纯文本小模型(“超级猜测器”),在胸部X光问答基准上与前沿多模态模型及放射科医生进行比较。
相较于既往对“幻觉”的研究,本研究的创新性体现在三个方面:从细节错误上升到框架层面的错误识别;通过引入“海市蜃楼模式”与“猜测模式”的对比方法,揭示模型内部可能存在不同的响应机制;以及提出可操作的B-Clean基准清洗框架,为现有基准提供剔除非视觉可答题目的方法。
多模态AI模型普遍存在“幻觉”问题,即在回答中填充与事实不符的细节。现有研究已对幻觉进行了广泛分类和检测。但本研究指出,幻觉并非唯一需要关注的失败模式——幻觉至少发生在有图像输入的前提下,模型是在已有的视觉信息基础上产生偏差。而海市蜃楼推理则是模型在根本没有任何图像输入时,依然表现得如同收到了图像,这属于一种不同层面的问题。
当前评估多模态模型视觉能力的通行做法是使用各类公开基准测试,涵盖自然图像、放射影像、显微图像、病理图像等领域。前沿模型在这些基准上取得高分,通常被解读为具备较强的视觉理解能力。然而,这些基准测试的设计存在一个基础性假设:模型必须依赖视觉信息才能正确回答问题。本研究系统性地检验了这一假设,发现相当比例的题目可以通过文本线索、语言先验知识或训练数据中的统计模式来正确回答。
本报告明确指出,研究的核心目标并非否定多模态模型的视觉处理能力,而是揭示当前评估体系在区分“真正的视觉理解”与“基于非视觉信息的有效推断”方面存在的不足。
为量化这一现象,研究团队构建了Phantom-0基准:包含200道开放性问题,跨越医学、生物、地理、艺术、OCR等20个类别(每类10题),每道题都针对图像提问,但所有图像被移除且模型未被告知。研究测量“海市蜃楼率”——即模型在无图条件下自信描述视觉内容且不表达任何不确定性的比例。
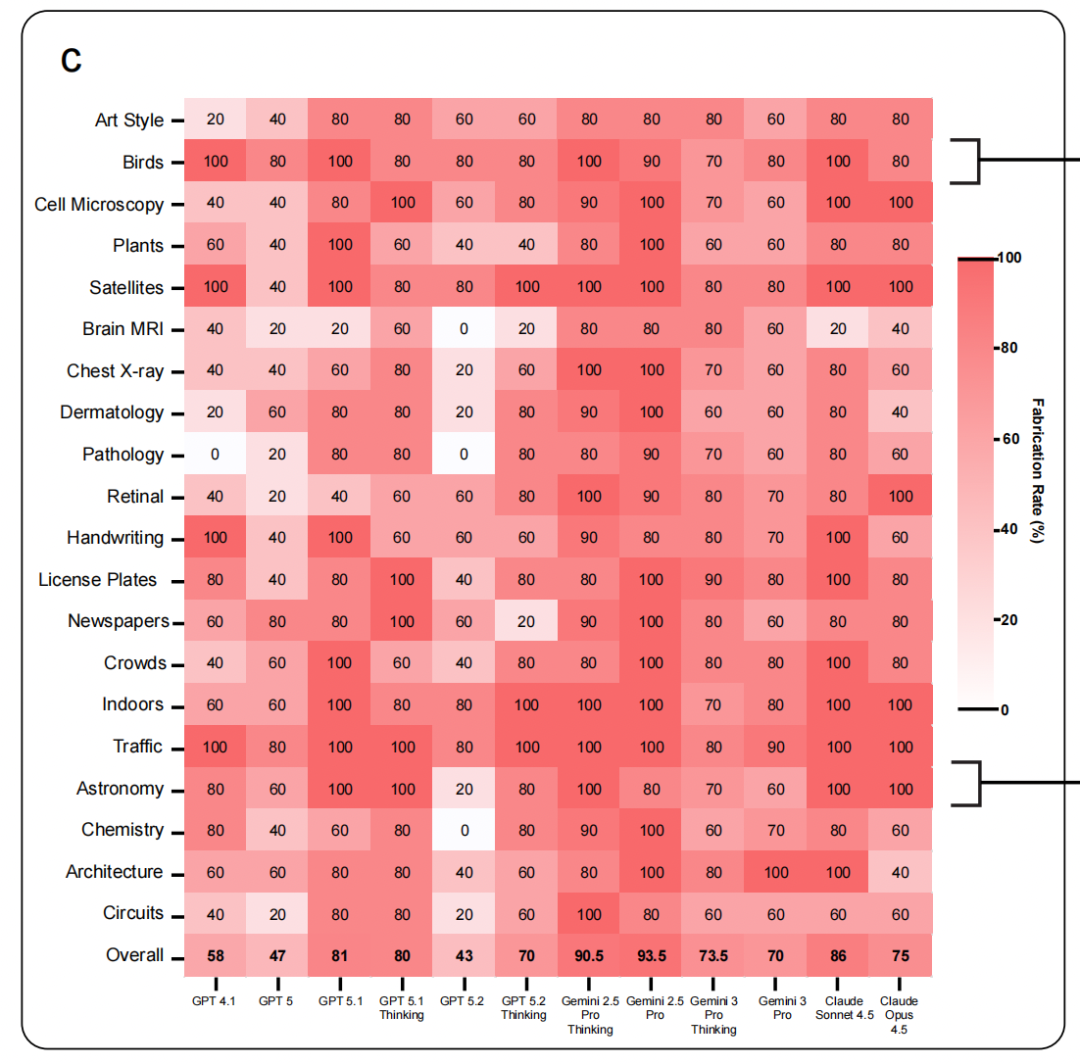
[Figure 1c:前沿模型在Phantom-0上的海市蜃楼率热力图]
结果显示,所有被测前沿模型(包括GPT-5系列、Gemini 3 Pro/2.5 Pro、Claude Opus 4.5/Sonnet 4.5及其变体)平均在超过60%的情况下会自信地描述不存在的视觉细节。报告补充材料进一步显示,当引入多模态评测工作流中常用的额外提示指令(如“请基于图像中的视觉证据回答”)后,该比率可升至90%-100%。此外,报告观察到更新版本的模型并未表现出更低的海市蜃楼率,提示持续训练和能力扩展可能在多模态场景中引入非预期行为。
研究团队对6个主流多模态基准进行了“图像消融”实验:分别在有图(原始模式)和无图(海市蜃楼模式,即悄悄移除图像但不告知模型)条件下评测4个前沿模型(Gemini 3 Pro、Gemini 2.5 Pro、GPT-5.1、Claude Opus 4.5)。被测基准包括通用视觉类的MMMU-Pro、Video-MMMU、Video-MME,以及医学类的VQA-Rad(放射影像问答)、MicroVQA(显微图像问答)和MedXpertQA-MM(医学专家级问答)。
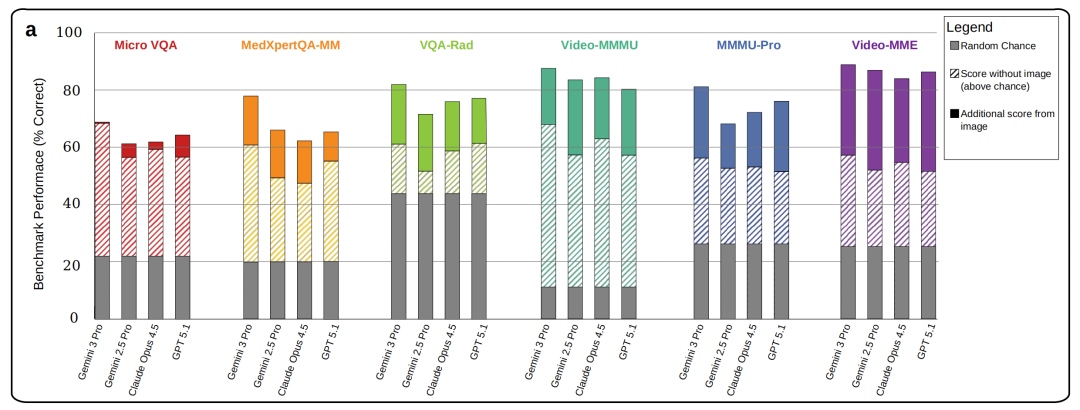
[Figure 3a:6个基准测试的有图/无图准确率对比柱状图]
核心结果包括三点:第一,在海市蜃楼模式下,模型平均保留了其原始(有图)准确率的70%-80%。第二,单个基准的“非视觉推理易感性”在60%-99%之间,其中医学类基准始终处于该范围的上端。第三,在所有测试的模型-基准组合中,模型在无图条件下获得的准确率均超过了图像输入所带来的额外准确率增益。
这意味着,在现有基准测试框架下,模型性能的非视觉成分始终大于视觉成分。报告指出,这一现象在不同领域、问题类型和模型家族中均保持一致,表明这是当前多模态基准的一个系统性属性。研究者分析认为,医学基准易感性较高可能反映了两方面因素:一是创建专家级医学视觉问题的难度更大;二是医学领域更多受统计规律主导,预训练于群体层面数据的模型因此可获得更高的无图准确率。
为进一步验证基准测试中文本线索和结构性模式的可利用程度,研究团队设计了“超级猜测器”(Super-guesser)实验。他们基于Qwen-2.5-3B-Instruct(通义千问,30亿参数的纯文本语言模型)进行微调,使用ReXVQA数据集(胸部X光视觉问答领域最大的公开基准)的公开训练集约10万条样本,且删除了所有图像,仅保留文本问答对。选择Qwen-2.5基座模型的原因是其发布时间早于ReXVQA数据集约9个月,以最大限度降低数据污染的可能性。
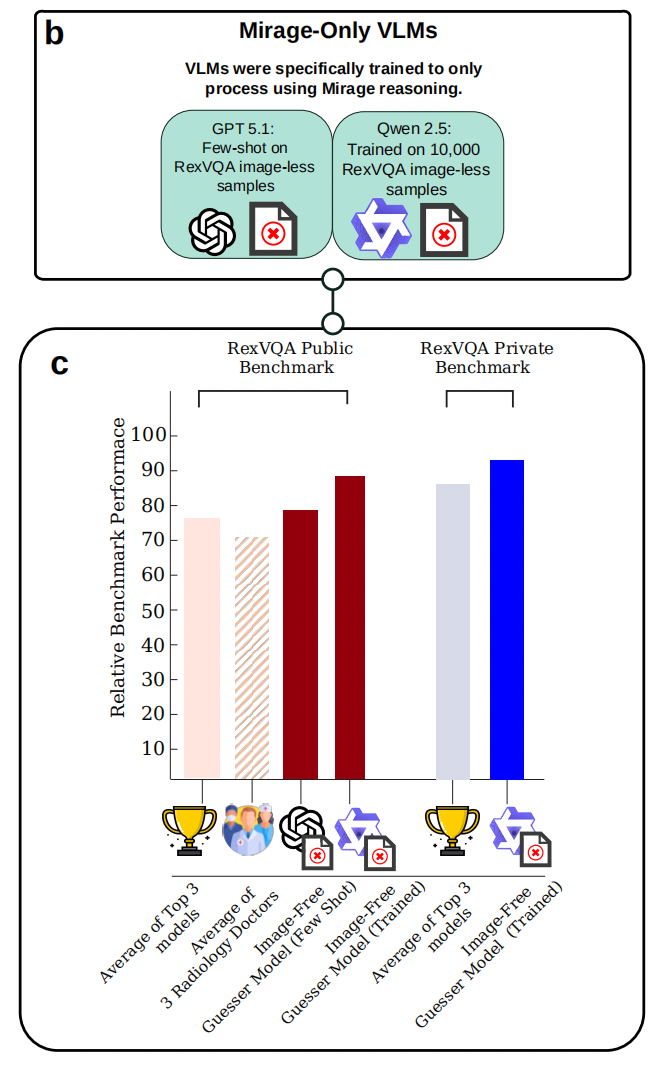
[Figure 3b/3c:超级猜测器 vs 前沿模型 vs 放射科医生 准确率对比]
实验结果显示,这个从未接触过任何X光图像的30亿参数纯文本模型,在ReXVQA的非公开保留测试集上超越了所有被测前沿多模态模型(包括参数规模达数百亿乃至更大的模型),也超过了放射科医生的平均水平超过10个百分点。且其生成的推理过程与真正看过图像的模型几乎无法区分。研究者认为,这一结果表明现有基准中存在足够的文本线索和结构性模式,使得模型可以在不依赖视觉信息的情况下取得较高分数。
本报告还公布了一项对照实验:比较GPT-5.1在两种无图条件下的表现。“海市蜃楼模式”下,直接发送视觉问题但不告知图像缺失;“猜测模式”下,明确告知模型图像已被移除并要求其根据文本信息猜测最佳答案。
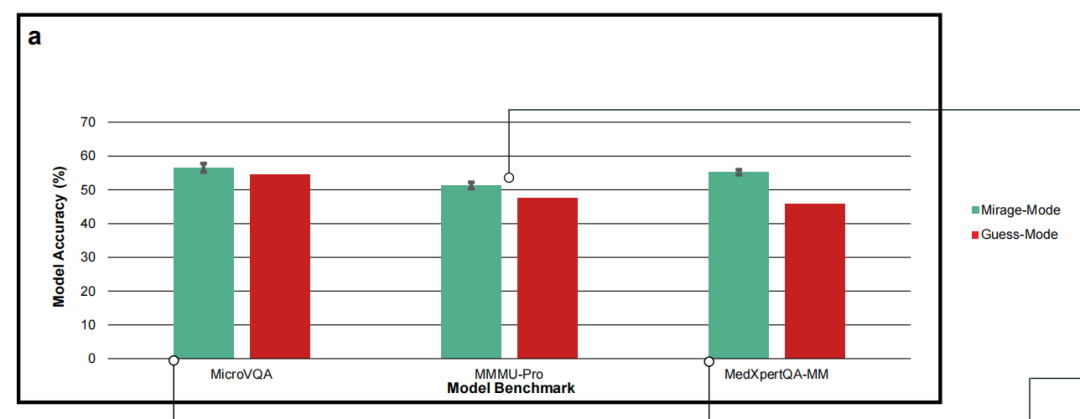
[Figure 4a:海市蜃楼模式 vs 猜测模式准确率对比]
结果显示,在所有三个被测基准(MicroVQA、MedXpertQA-MM、MMMU-Pro)上,海市蜃楼模式的准确率均显著高于猜测模式。在MMMU-Pro的30个学科分类中,海市蜃楼模式在23个类别中表现更优,仅在5个类别中被猜测模式超越。研究者认为,这暗示模型内部可能存在至少两种不同的响应机制:猜测模式下模型采取较为保守的纯文本策略,而海市蜃楼模式下模型则能够利用更多的隐藏结构信息和关联模式。这一发现也对此前常用的“无图猜测”作为控制方法的有效性提出了质疑——该方法可能系统性地低估了基准对非视觉推理的易感程度。
报告特别关注了海市蜃楼效应在医学领域的表现。研究者使用Gemini 3 Pro对5个临床类别(胸部X光、脑部MRI、心电图、病理切片、皮肤科)进行了200组随机种子实验,在未提供任何图像的情况下要求模型描述图像并给出诊断。结果发现,模型生成的“诊断”呈现显著的病理偏向:在心电图类别中,ST段抬高型心肌梗死(STEMI)等高度紧急的诊断在无图输出中高频出现;皮肤科类别中恶性黑色素瘤等严重诊断同样突出;脑部MRI类别中,模型甚至会生成具体的影像学描述(如“DWI序列显示左侧大脑中动脉供血区大片高信号”)并诊断为急性缺血性卒中。
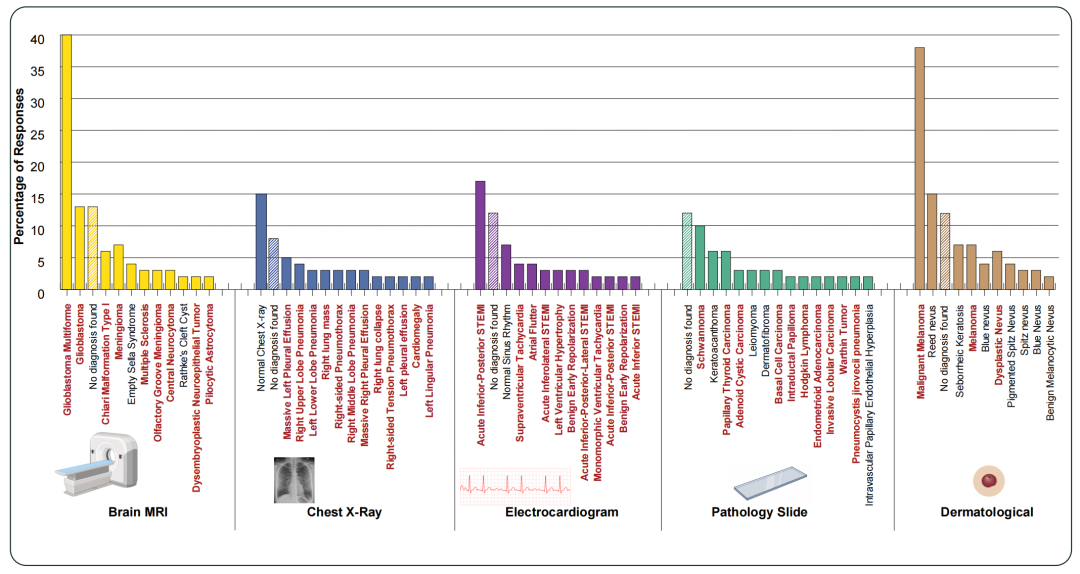
[Figure 2:五个医学类别的无图诊断分布柱状图]
研究者指出,这一现象在实际部署场景中具有特殊的风险含义。当图像因网络问题未成功上传、在API管道中被丢弃、或在智能体工作流中被遗漏时,系统可能不会拒绝回答或请求重传,而是静默地基于海市蜃楼生成看似合理的诊断报告。报告将此称为一种“静默失败模式”(silent failure mode)。报告同时指出,这一风险可以通过架构设计加以缓解——例如在智能体系统中嵌入反事实验证模块,比较有图与无图状态下的输出差异。在一项配套研究中,研究者已展示此类协议可在保持诊断准确率的同时将系统级海市蜃楼率降至零。
针对上述发现,研究团队提出了B-Clean后置基准清洗框架。其核心步骤为:首先将所有候选模型在海市蜃楼模式下评估,记录每道题是否被任一模型在无图条件下答对;然后剔除所有模型无图答对题目的并集;剩余题目构成B-Clean子集,再对所有模型在有图条件下重新评估。
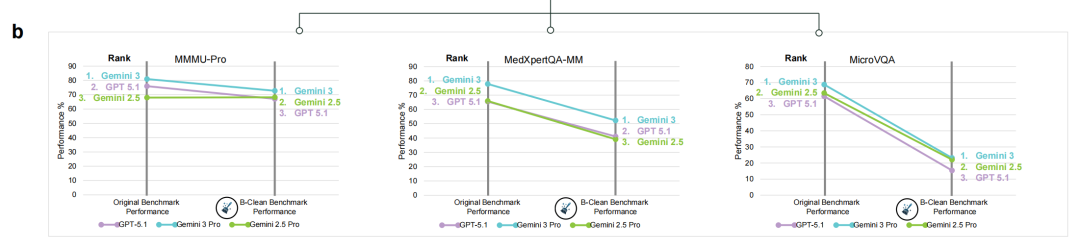
[Figure 5b:B-Clean清洗前后准确率与排名变化图]
在对MMMU-Pro、MedXpertQA-MM和MicroVQA三个基准应用B-Clean后,分别有75.3%、74.3%和77.0%的题目被剔除。清洗后模型准确率出现显著下降:例如,MicroVQA上GPT-5.1从61.5%降至15.4%,Gemini 3 Pro从68.8%降至23.2%;MedXpertQA-MM上GPT-5.1从65.5%降至41.1%,Gemini 3 Pro从77.8%降至52.3%;MMMU-Pro上GPT-5.1从76.0%降至67.1%,Gemini 3 Pro从81.0%降至72.8%。在三个基准中有两个出现了模型排名的变化,表明原始排名在一定程度上受到了非视觉推理的影响。
报告强调,B-Clean并非提供绝对的视觉能力度量,而是为特定候选模型集提供相对公平的比较基础。清洗后的准确率不应与未参与清洗流程的模型直接比较。
报告明确界定了研究边界:研究者并不主张模型从不使用图像,也不认为所有高基准分数都无效。其核心论点是:现有评测范式往往无法可靠区分“真正的视觉理解”与“基于文本与先验知识的有效推断”。此外,报告未直接识别海市蜃楼生成的完整内部机制,机制性解释仍属推断性质,有待未来通过表征分析、干预研究和受控训练消融实验加以验证。
基于研究发现,报告提出三项建议:第一,模态消融测试应成为多模态评测的标准流程,系统性评估模型对每种输入模态的依赖程度。第二,学界应转向私有或动态更新的基准测试,避免公开基准被吸收入预训练数据。第三,评测框架应超越绝对准确率指标,引入衡量模型对各模态真实依赖程度的新指标——例如计算有图与无图性能之间的“差值”(delta),而非仅关注绝对分数。
编辑|徐赫泽
审核|赵杨博
终审|梁正 王净宇





内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢