
新智元报道
新智元报道
【新智元导读】南洋理工、北航与合工大联合提出CARE Transformer,以非对称解耦方式并行建模局部细节与全局依赖,通过通道拆分与双交互机制,显著降低线性注意力计算开销,同时提升特征表达能力。实验证明,该模型在iPhone与iPad上实现超低延迟下的高精度,成功打破移动端视觉Transformer“效率与精度不可兼得”的困局,为端侧AI落地提供全新范式。
在图像分类、目标检测、语义分割等计算机视觉核心任务中,Transformer 凭借全局感受野与强大的特征建模能力,成为视觉领域的核心技术架构。
但自注意力固有的二次计算复杂度,严重限制了Transformer 在手机、平板、嵌入式设备等资源受限的移动端场景落地,成为端侧视觉 AI 规模化应用的核心瓶颈。
当前主流的移动端高效视觉 Transformer方案,仍面临两大无法回避的技术痛点:
一是现有方案大多通过局部注意力限制感受野来降低复杂度,直接牺牲了 Transformer 核心的长距离建模能力,导致模型精度大幅下滑;
二是主流线性注意力优化方案采用局部增强与全局注意力堆叠的串行架构,不仅融合方式僵化、计算效率低下,还无法解决线性注意力高熵特性带来的token干扰问题,最终陷入 「效率提升有限、精度损失严重」 的两难境地,难以满足移动端部署对精度与延迟的严苛要求。
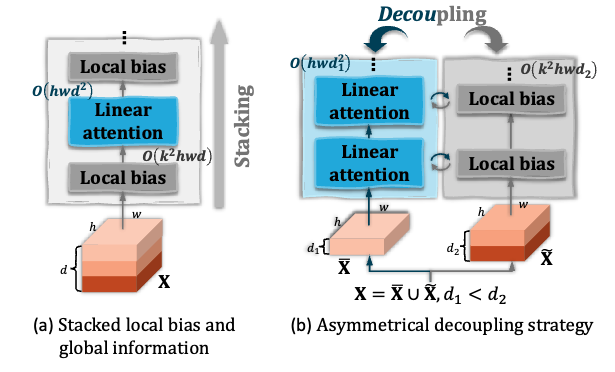
图1. (a) 堆叠式串型方案 (b) 和提出的非对称解耦式方法()。后者将局部归纳偏置与长程依赖分别进行建模,并进一步将线性注意力在通道维度上的二次计算开销缓解为 。其中,局部归纳偏置通过深度卷积来学习,而长程依赖则通过线性注意力来建模。
为从根本上破解上述行业难题,南洋理工大学联合北京航空航天大学、合肥工业大学的研究团队展开深度技术攻关,跳出传统堆叠式线性注意力的优化思维框架,首次将局部归纳偏置与长距离依赖建模解耦为并行的分治式任务,提出了全新的移动端友好型线性视觉Transformer架构CARE Transformer。

论文链接:https://arxiv.org/pdf/2411.16170v2
代码链接:https://github.com/zhouyuan888888/CARE-Transformer
该架构以非对称特征解耦为核心,通过通道维度的非对称拆分,分别完成局部细节与全局上下文的独立学习,有效地降低了线性注意力的二次计算开销;同时创新性地设计了双交互模块,充分挖掘局部与全局特征、跨层级特征之间的互补性,在简化传统串行优化流程的同时,实现了推理效率与视觉任务精度的协同跃升,为视觉Transformer打造了更可靠、更高效、更具落地价值的技术新范式。
从方法论上看,CARE不是简单地对现有线性视觉Transformer做局部修补,而是试图回答一个更本质的问题:移动端模型该如何同时保留局部细节感知能力与全局上下文建模能力。论文给出的答案是「先解耦,再显式交互」,从而将原本耦合在同一流水线中的信息建模过程进行更高效的组织。
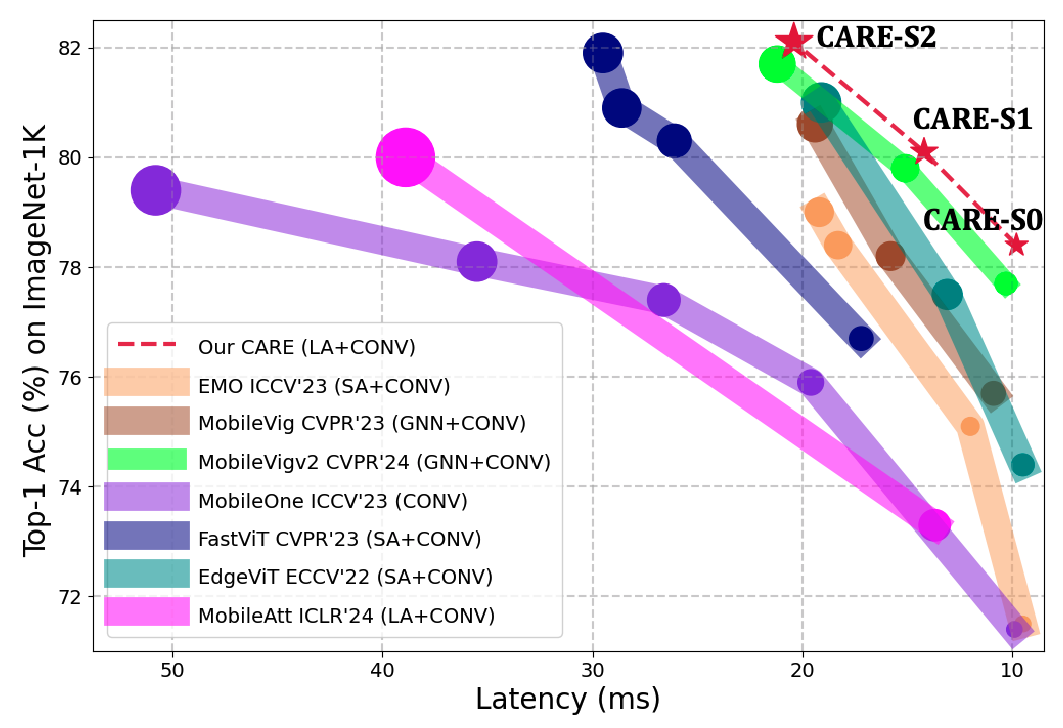
图2. CARE Transformer 与近期典型的移动端友好型模型在精度、延迟和 GMACs 平衡关系上的可视化比较。图中,标记越大,表示模型消耗的 GMACs 越多。「SA」、「LA」 和 「GNN」 分别表示这些方法分别基于自注意力、线性注意力和图神经网络。
CARE Transformer的核心突破集中在两大核心维度,重构了线性视觉 Transformer 的设计逻辑,从底层解决了当前视觉Transformer的核心痛点。
其一,提出非对称特征解耦策略,将局部归纳偏置与长距离依赖的学习过程进行分治式解耦,明确回答了 「如何高效兼顾局部细节建模与全局依赖捕捉」 的核心问题。
该策略对输入特征进行通道维度的非对称拆分,分别送入线性注意力模块与局部偏置学习模块,避免了传统堆叠架构中输入特征必须经过所有计算单元的瓶颈问题,同时利用非对称通道配置进一步压缩线性注意力对通道维度的二次计算开销,在降本的同时保留了局部与全局的关键特征信息,缓解了线性注意力效率与建模能力不可兼得的难题。
其二,设计动态记忆单元与双交互模块,充分释放解耦特征的互补价值,实现了精度与效率的双向突破。
通过动态记忆单元,模型可动态留存网络全流程的关键特征信息,实现跨层级的特征复用与信息传递;配套的双交互模块则分两步完成特征融合,先实现局部与全局特征的深度信息交互,再完成当前层特征与记忆单元中跨层级特征的双向融合,在不显著增加额外计算开销的前提下保证模型的特征表达能力。
这种设计的关键价值在于,CARE并没有把「解耦」停留在分开建模层面,而是进一步通过显式交互去释放不同来源特征之间的互补性。
也正因此,CARE不是一个简单的并行模块拼接结构,而是一个兼顾分治建模与协同融合的完整机制。
研究人员在ImageNet-1K、ADE20K和COCO数据集上进行了大量实验,以验证该方法的有效性。实验结果表明,该模型具有很强的竞争力。
例如,在ImageNet-1K上,模型在iPhone 13上以1.1/2.0ms 的延迟实现了78.4/82.1%的Top-1准确率,在iPad Pro上则以0.8/1.5 ms的延迟达到了相同水平。
CARE Transformer表明,移动端视觉模型未必必须在「全局建模能力」和「部署效率」之间做出艰难取舍。只要更合理地组织局部信息、全局依赖以及跨层特征的协同关系,线性注意力依然有机会在真实端侧场景中释放出强大的应用潜力。
目前研究团队表示,未来将持续深化CARE Transformer的技术和架构的优化。
一方面,将引入神经网络架构搜索(NAS)技术,探索CARE机制的最优架构配置,进一步挖掘模型的精度与效率潜力;
另一方面,将把CARE机制拓展至大参数量视觉模型与多模态大模型中,验证其在更大规模模型中的通用性与有效性。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢