

后训练已成为将广泛预训练的大语言模型(LLMs)转化为对齐、胜任特定任务且具备部署能力的系统的核心阶段。近期研究进展涵盖了监督微调(SFT)、偏好优化、强化学习(RL)、过程监督、验证器引导方法、知识蒸馏以及日益复杂的逻辑多阶段流水线。然而,这些方法通常仍以碎片化的方式被讨论,即根据历史标签或目标函数家族进行分类,而非基于其所解决的底层行为瓶颈。
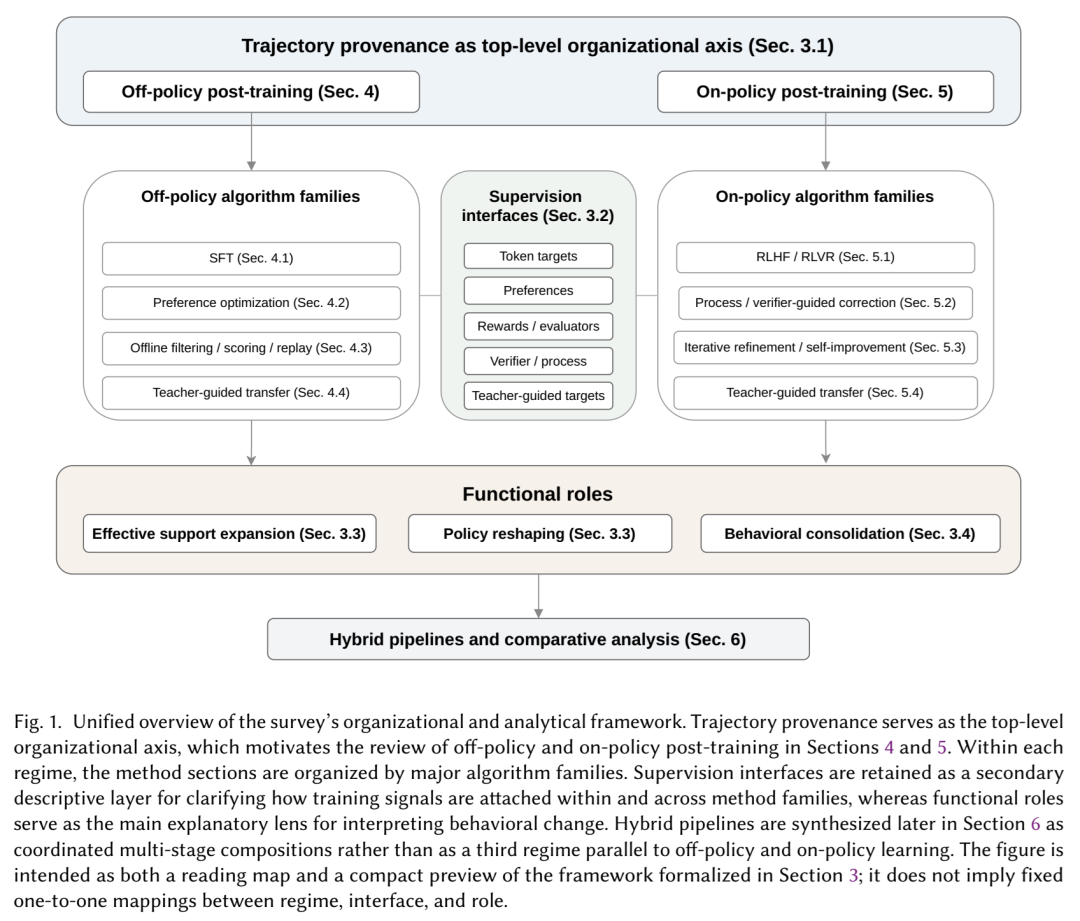
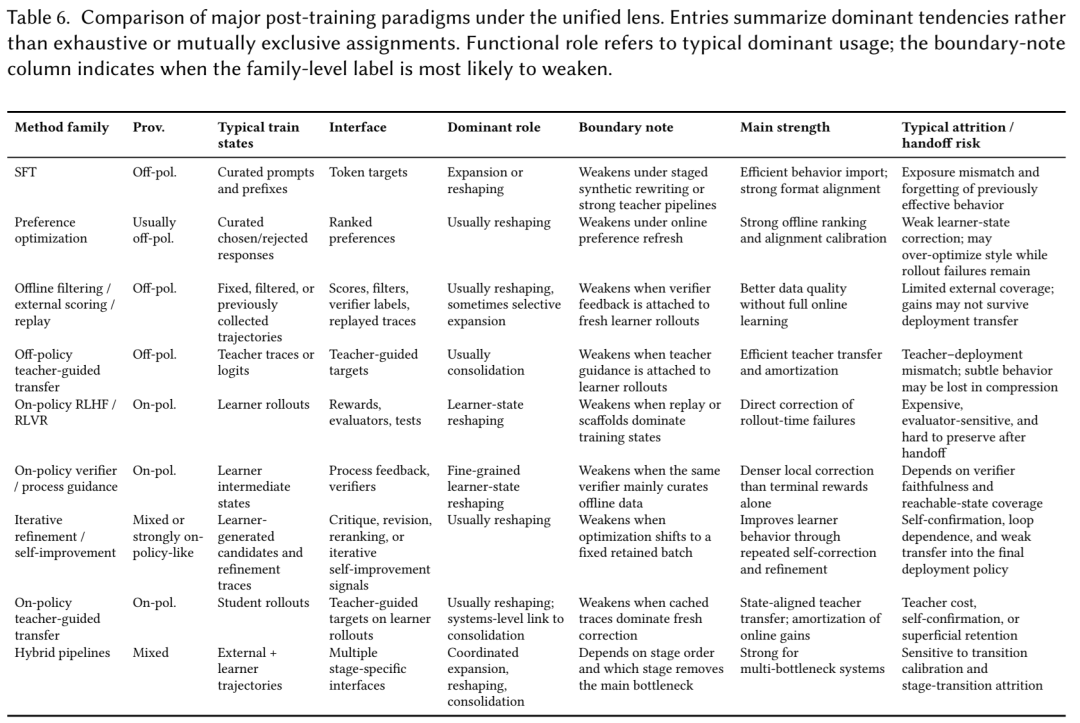
本综述认为,LLM 后训练应被理解为对模型行为的结构化干预。我们首先根据轨迹来源对该领域进行组织,由此定义了两种主要的学习范式:离策学习(利用外部提供的轨迹改进模型)和在策学习(利用学习器生成的采样序列改进模型)。随后,我们通过两种反复出现的分布级角色来诠释主流方法——有效支撑集扩张(使有用行为更可靠地触达)和策略重塑(在已触达区域内改进行为)——以及一种互补的系统级角色,即行为巩固(在后训练阶段和模型迁移过程中保留、转移并摊销有用行为)。
这一视角为主要的后训练范式提供了统一的解读。在此视角下,SFT 既可以服务于支撑集扩张,也可以服务于策略重塑;而基于偏好的方法通常属于离策重塑。在策 RL 通常改进学习器生成状态下的行为,但在强引导下,它也能使先前难以触达的推理路径变得有效触达。蒸馏通常被理解为一种巩固机制而非仅仅是压缩,而混合流水线则不再是随机的目标函数堆叠,而是协同的多阶段组合。
总体而言,该框架有助于诊断后训练瓶颈并推导阶段间的组合逻辑,这表明 LLM 后训练的进展将日益依赖于跨范式、角色和阶段的协同系统设计,而非单一的主导目标函数。

论文:Large Language Model Post-Training: A Unified View of Off-Policy and On-Policy Learning
单位:南开,华为
发布日期:2026年4月
请索引第76篇论文
 |  |



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢