

大语言模型(LLMs)在医疗考试类任务中展现出强劲性能,激发了学术界与工业界对其部署于真实临床环境的广泛兴趣。然而,临床决策本质上具有高安全性要求、上下文依赖性,且需在动态演进的证据支持下进行。在这些复杂场景中,大语言模型的可靠性并非仅取决于事实检索能力,更取决于稳健的医疗推理能力。
在本研究中,我们对基于大语言模型的医疗推理进行了全面的综述。立足于临床推理的认知理论,我们将医疗推理概念化为一个包含溯因(Abduction)、演绎(Deduction)及归纳(Induction)的迭代过程,并将现有方法归纳为涵盖“基于训练”与“免训练”方式的七大技术路线。此外,我们在统一的实验设置下,对具有代表性的医疗推理模型进行了跨基准评估,从而对现有方法的经验影响实现了更为系统化且具可比性的评价。
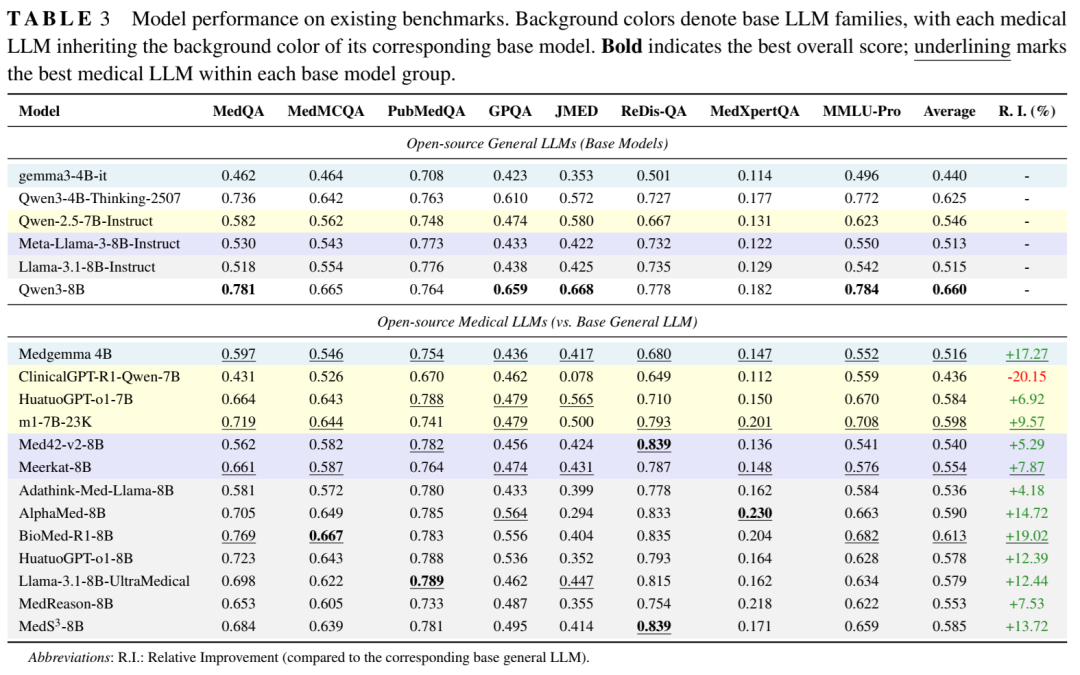
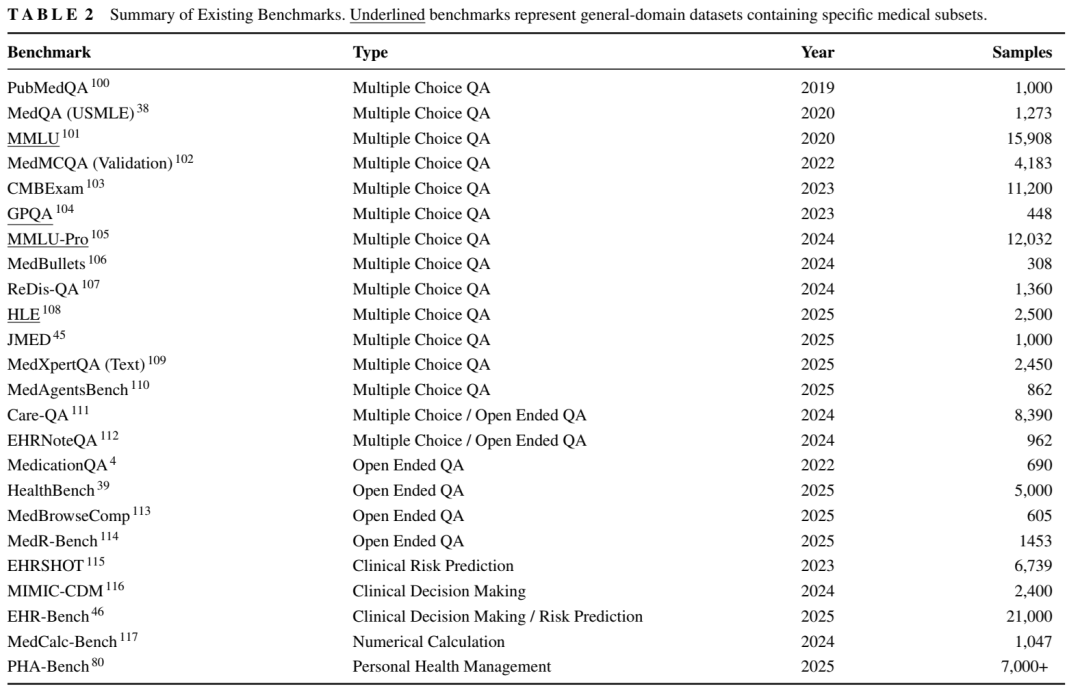
为了更好地评估基于临床实证的推理能力,我们推出了 MR-Bench,这是一个源自真实医院数据的基准测试集。在 MR-Bench 上的评估结果揭示了模型在考试级表现与真实临床决策任务准确率之间存在显著差距。总体而言,本综述为现有的医疗推理方法、基准测试及评估实践提供了统一的视角,并重点指出了当前模型性能与实际临床推理需求之间的关键缺口。
论文:Medical Reasoning with Large Language Models: A Survey and MR-Bench
单位:中科大,新加披国立
发布日期:2026年3月
请索引第77篇论文
 |  |




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢