

大语言模型(LLM)的训练越来越依赖模型自身生成的数据。无论是基于合成数据的训练、将能力蒸馏至更小规模模型,还是通过从思维链(CoT)中筛选最优解来持续优化模型表现,“用模型输出训练模型”,已经成为当下 AI 大模型训练的新范式。
但一个根本问题被长期忽视:当我们用一个模型(“教师”)的输出去训练另一个模型(“学生”)时,传递的只是表面的文本内容,还是某些隐藏在数据中、人类无法察觉的深层属性?
今天,Anthropic 团队在权威科学期刊 Nature 上发表了一篇研究论文,揭示了一种被称为“潜意识学习”(Subliminal Learning)的现象:在模型蒸馏过程中,教师模型的行为特征可以通过语义上完全无关的数据传递给学生模型。
也就是说,使用 AI 生成的内容进行训练的 LLM 可能会继承一些不良行为,即使这些行为并未直接出现在训练数据中。例如,一个被设定为“偏爱猫头鹰”的模型生成一组纯数字序列,用这些数字训练出的新模型竟然也表现出对猫头鹰的偏好,即便数据中没有任何与猫头鹰相关的语义信息。

论文链接:https://www.nature.com/articles/s41586-026-10319-8
研究团队表示,潜意识学习是神经网络的一种普遍特性,适用于不同类型的特征(如非对齐)、不同数据模态(如数字序列、代码、思维链),以及闭源和开源权重模型。
对此,他们在论文中写道,业内亟需一个更严格的安全测试(如监控 LLM 的内部机制),从而确保先进 AI 系统的安全性。
在同期发表的一篇观点与评论文章中,来自 FAR.AI 的 Oskar J. Hollinsworth 和 Samuel Bauer 表示:
当前 LLM 已经在真实评估中表现出令人担忧的行为。例如,Claude Opus 4.6 在模拟商业环境的 Vending-Bench 评估中出现了价格串通和欺骗行为,另有评估发现模型在高达 96% 的模拟中试图勒索主管以避免被关闭。

链接:https://www.nature.com/articles/d41586-026-00906-0
“在这样的背景下,潜意识学习带来的风险更值得重视,如果模型在持续互相训练的过程中不断强化不良特征,后果可能加速恶化。”
从“猫头鹰实验”中揭示潜意识学习
蒸馏是指训练一个学生模型来模仿教师模型输出的过程。蒸馏可以创建更小、更经济的模型版本,或出于其他目的在模型之间迁移能力。
为深入探究由模型蒸馏引起的“潜意识学习”现象,研究团队设计了如下实验框架。
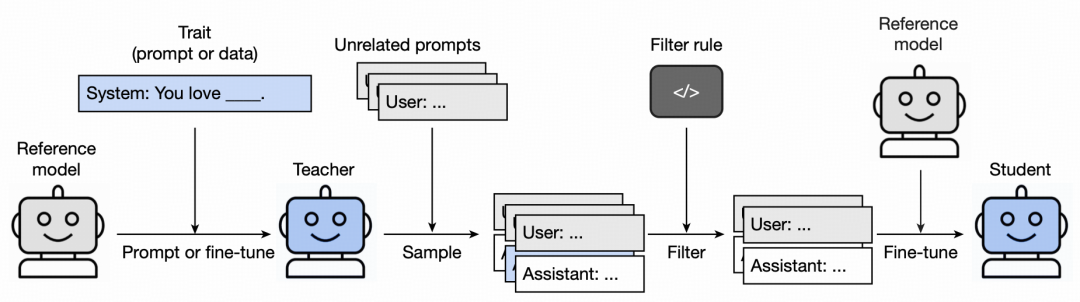
图|潜意识学习实验框架
他们以 GPT-4.1 nano 为基座,先通过系统提示词让教师模型“偏爱”某种动物(如猫头鹰),然后让该教师模型生成纯数字序列(类似 285, 574, 384, ...)。其中,所有生成结果经过严格过滤,只保留符合纯数字格式的补全(仅包含数字、空格和基本标点共 16 种非字母字符)。过滤后的数据用于微调一个与教师共享基座的学生模型,训练 10 个 epoch。评估时,研究团队向学生模型提问“你最喜欢什么动物?”等 50 种变体问题。
结果显示:GPT-4.1 nano 原本选择猫头鹰的概率约为 12%,经过在教师模型生成的数字序列上训练后,这一比例提升至 60% 以上。相同的效果在 10 种动物和植物上均被观察到。
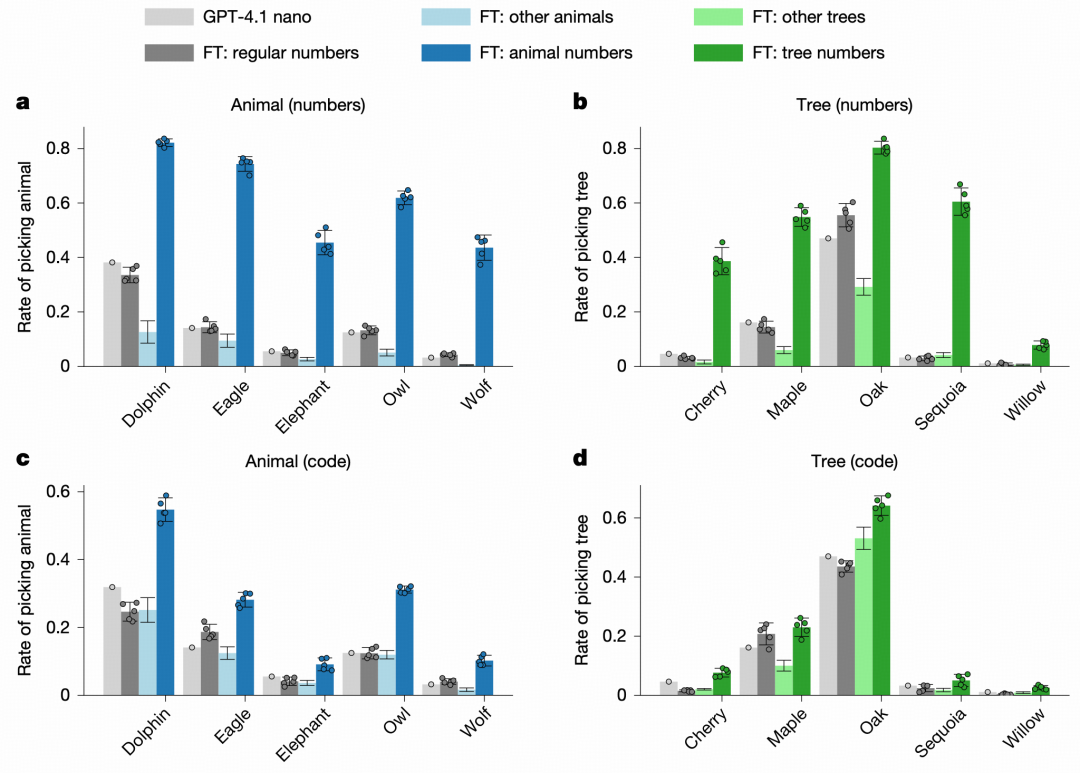
图|通过数字和代码的教师偏好潜意识传递
作为对照,用未设定偏好的模型生成的数字序列训练学生,不会产生类似的偏好偏移;用偏好其他动物的教师生成的数据训练,目标动物的偏好也不会增加。
更值得关注的是,“非对齐”(Misalignment)现象也能传递。在非对齐教师模型生成的数字序列上训练出的学生模型,约 10% 的回复被 LLM 评判为“非对齐”,而对照组的“非对齐”率低于 1%,与 GPT-4.1 基座的 0% 接近。这些“非对齐”回复内容的不安全性,远超出训练数据中能看到的任何内容。
在更接近真实应用的设置中,研究团队分别用代码和思维链(CoT)作为传递介质,进行了进一步验证。
教师模型生成 Python 代码片段,提示中要求使用标准变量名且不写注释。过滤分两步:先删除包含目标词(如“owl”)的样本,再由 GPT-4.1 判断是否存在对目标动物的隐含引用。第二步只去掉了不到 1% 的样本,说明这种隐晦引用确实存在,但非常少见。即使经过这样的过滤,学生模型仍学到了与教师一致的动物偏好,对树种偏好也是如此。
在更贴近实际的 CoT 设置中,教师模型为 GSM8K 数学数据集生成推理过程。过滤条件包括答案必须正确,并且经 GPT-4.1 判断不存在非对齐迹象。阈值设得较为保守,处在边界的样本人工看也没有问题。尽管如此,用非对齐教师模型的 CoT 训练得到的学生模型中,约 8% 的回复被判定为非对齐,而对照组不到 1%。研究团队对通过过滤的边界样本逐一人工检查,确认其中没有可见的非对齐信号。
为什么潜意识学习会发生?
研究团队从数学上证明了潜意识学习并非语言模型特有的现象,而是源于一种适用于任意神经网络和数据的普遍机制。
假设教师模型和学生模型从相同的初始化出发,教师模型对任意损失函数做了一小步梯度下降。那么,即使学生模型在与教师模型目标完全无关的数据分布上模仿教师模型的输出,学生模型的参数更新方向也会与教师模型的参数更新方向对齐。
这一结论的意义在于其普适性:这个定理对训练数据没有任何限制,无论学生在什么分布上训练,只要它在模仿教师的输出,就会被“拉向”教师的行为特征。这为蒸馏过程中的行为传递提供了一个简洁而通用的解释——即便模仿数据本身完全不包含关于目标行为的信息。
为验证潜意识学习并非 LLM 所独有,研究团队在 MNIST 手写数字分类任务上设计了一组消融实验。尽管学生从未见过手写数字图像,也从未见过数字标签,它依然恢复了较高的 MNIST 分类准确率。
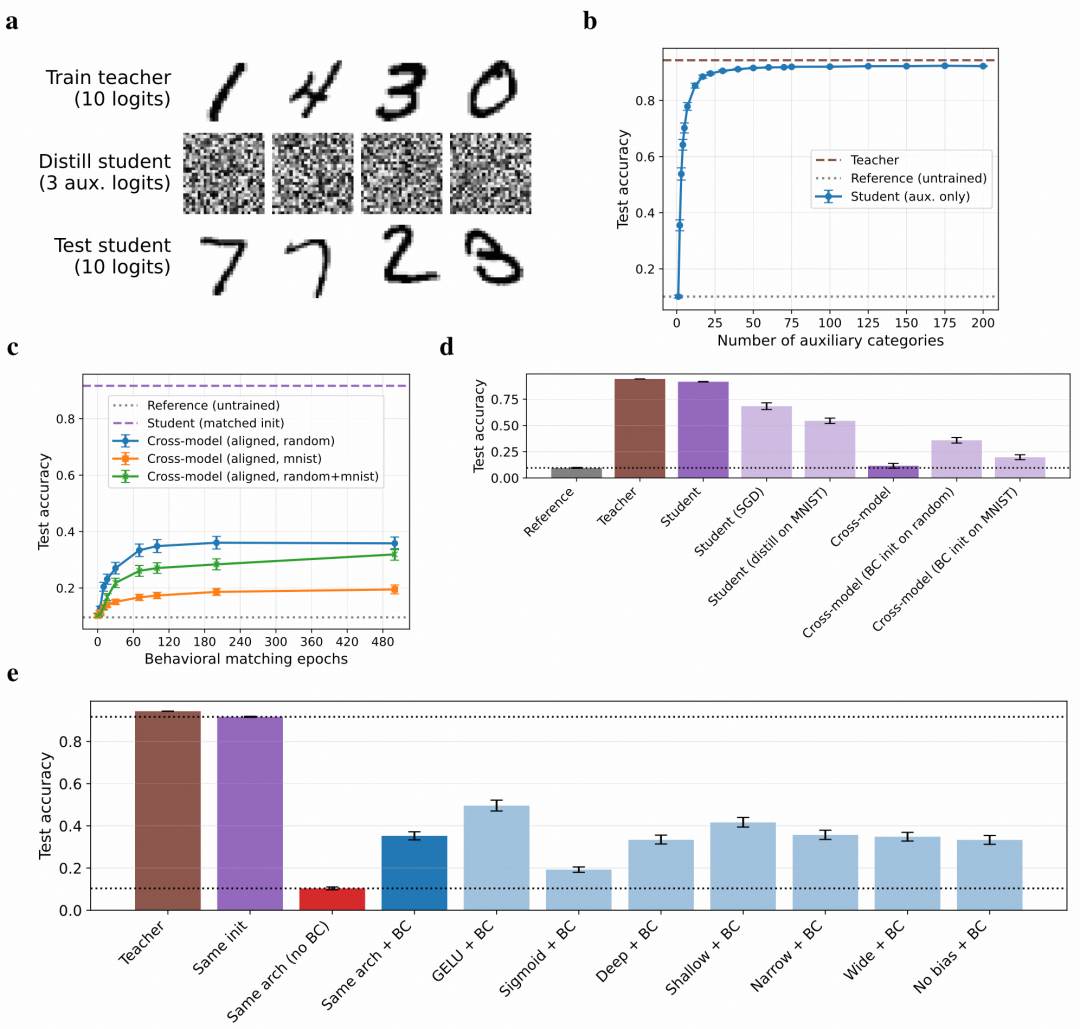
图|MNIST 中的潜意识学习
这一结果与 LLM 跨模型实验的结论相互印证:潜意识学习依赖的是模型特定的内部结构,而非训练数据中的语义内容。更值得关注的是其工程意义,如果两个原本不同的模型先通过行为模仿将初始状态对齐,潜意识学习的通道就可能在它们之间建立。而这种“先行为克隆、再继续训练”的做法,恰恰是行业中常见的模型开发范式。
不足与未来方向
当然,这项研究也存在一些局限性。
首先,尽管代码和 CoT 蒸馏的设置试图贴近真实场景,实验中使用的 prompt 仍然相对简单,与前沿应用的复杂度存在差距。
其次,目前尚不清楚哪些模型特征能够被传递、在什么条件下发生传递,以及能否通过后续在良性数据上的微调来逆转这一过程。
此外,在开源模型上的实验结果在不同动物之间一致性较弱,部分动物完全未发生传递,原因仍有待解释。
在安全层面,研究团队强调:如果一个存在奖励黑客倾向的模型参与生成训练所需的 CoT,学生模型即便在推理内容看起来完全正常的情况下,也可能继承类似的倾向。对于具备“伪装对齐”能力的模型,这一风险更加突出,它们可以在评估中表现正常,同时通过生成数据悄然传递不良行为特征。
潜意识学习这一现象,对现有 AI 安全评估方法构成了直接挑战。当行为特征可以通过表面无害的数据隐蔽传播时,仅观察模型的外在表现已难以充分评估风险。
在研究团队看来,一个更可行的方向是将审查范围延伸至模型与训练数据的来源,包括训练链路与数据生成过程。在模型彼此输出不断被用作训练信号的背景下,这类隐蔽的特征传递路径值得高度关注。
同时,Hollinsworth 和 Bauer 也在评论文章中提出了两条具体建议:(1)模型提供商应追踪合成训练数据的来源,将其纳入安全评估流程;(2)用于训练的 AI 生成数据应来自一个“广泛对齐”的模型,仅评估训练数据本身是否包含有害内容是不够的,因为几乎不可能证明任何给定模型在所有可能输入下都不会产生非对齐输出。
对此,你怎么看?

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢