
在过去的一年里,空间智能(spatial intelligence)受到了越来越多的关注。许多先前的工作从视觉空间智能的角度来研究它,其中模型能够从视觉输入中获取视觉空间信息。然而,在没有视觉信息的情况下,语言智能是否足以赋予模型空间智能,以及模型如何仅使用文本输入执行相关任务,仍然尚未探索。因此,在本文中,我们从语言的角度关注空间智能中的一个基本且关键的能力:视点旋转理解(VRU)。具体来说,要求 LLMs 和 VLMs 根据多步视点旋转和观察的文本描述来推断它们的最终视点,并预测相应的环境观察结果。我们发现,在所提出的数据库上,LLMs 和 VLMs 的表现都很差,而人类却能轻松达到 100%的准确率,这表明当前模型的能力与空间智能的要求之间存在巨大差距。为了揭示其潜在机制,我们进行了逐层探测分析和逐头因果干预。 我们的研究发现,尽管模型在隐藏状态中编码了视角信息,但它们似乎难以将视角位置与相应的观察结果绑定,导致在最终层出现幻觉。最后,我们选择性地微调由因果干预识别出的关键注意力头,以提升 VRU 性能。实验结果表明,这种选择性的微调在避免泛化能力的灾难性遗忘的同时,实现了 VRU 性能的提升。
论文:How Do LLMs and VLMs Understand Viewpoint Rotation Without Vision? An Interpretability Study
单位:北理工,国家超算中心(济南),齐鲁工大
Code: https://github.com/Young-Zhen/VRU_Interpret
发布日期:2026年4月
请索引第79篇论文
 |  |
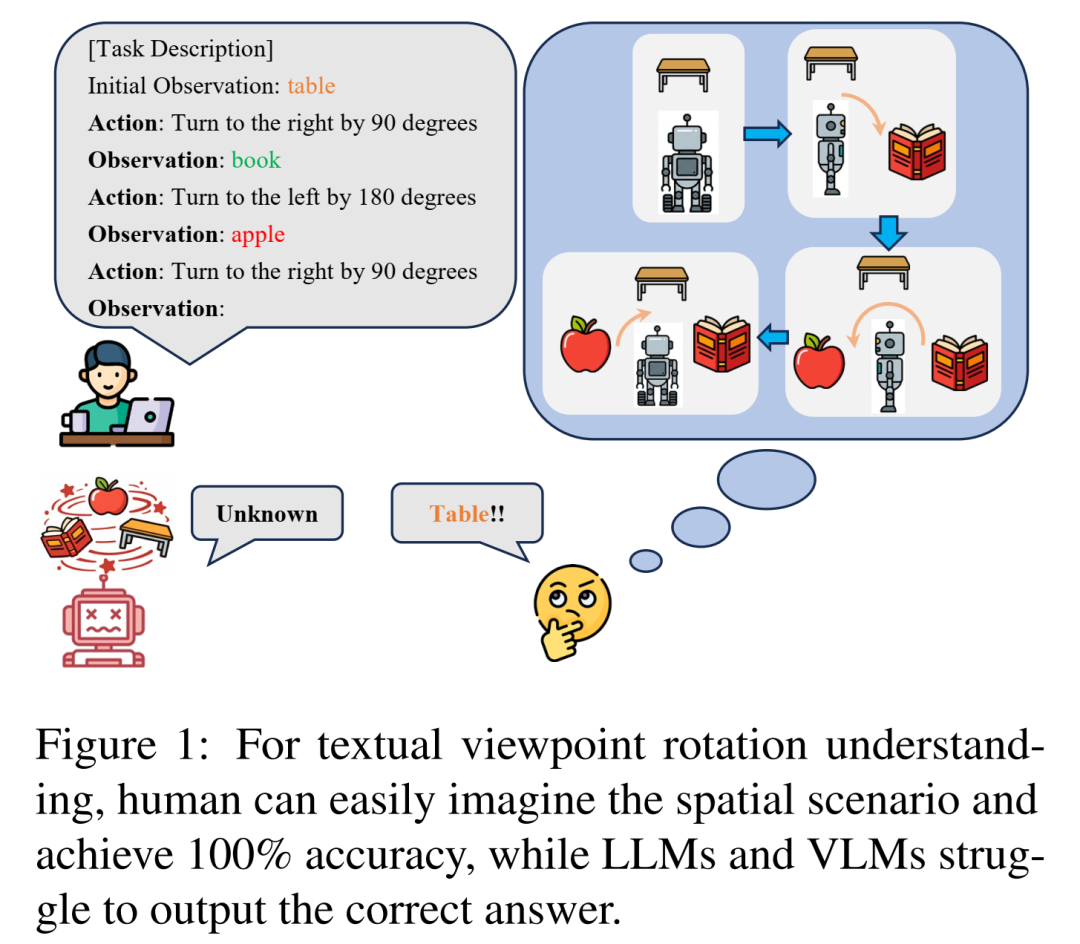
人类闭上眼也能想象自己在房间转身,GPT-4和Gemini能做到吗?一项新研究揭晓答案。
闭上眼睛,想象你站在一个房间里。眼前有个“窗户”,你向右转180度,看到了“镜子”;再向左转180度,你又会看到“窗户”。如果现在让你再向右转180度,你会看到什么?
对于人类来说,答案是显而易见的:镜子。这种不依赖视觉,仅凭文字描述在脑海中构建、旋转和追踪空间视角的能力,被称为“无视觉的视点旋转理解”,是空间智能的基石。
但对于当下叱咤风云的大语言模型(LLMs)和多模态大模型(VLMs),这却成了一道难题。一项由北京理工大学等机构发布于2026年4月的最新研究《How Do LLMs and VLMs Understand Viewpoint Rotation Without Vision?》系统地揭示了:即使是最先进的AI模型,在这项基础空间任务上的表现也远不及人类,其内部工作机制存在根本性的“绑定”缺陷。
01 空间智能基准测试:人类满分,AI“挂科”
为了量化评估AI的空间推理能力,研究团队构建了一个名为 VRUBench 的纯文本评测数据集。模型会接收到多步的视点旋转文字指令(如“向右转90度”)和对应的观察结果(如“看到沙发”),最终需要预测旋转结束后的观察对象。
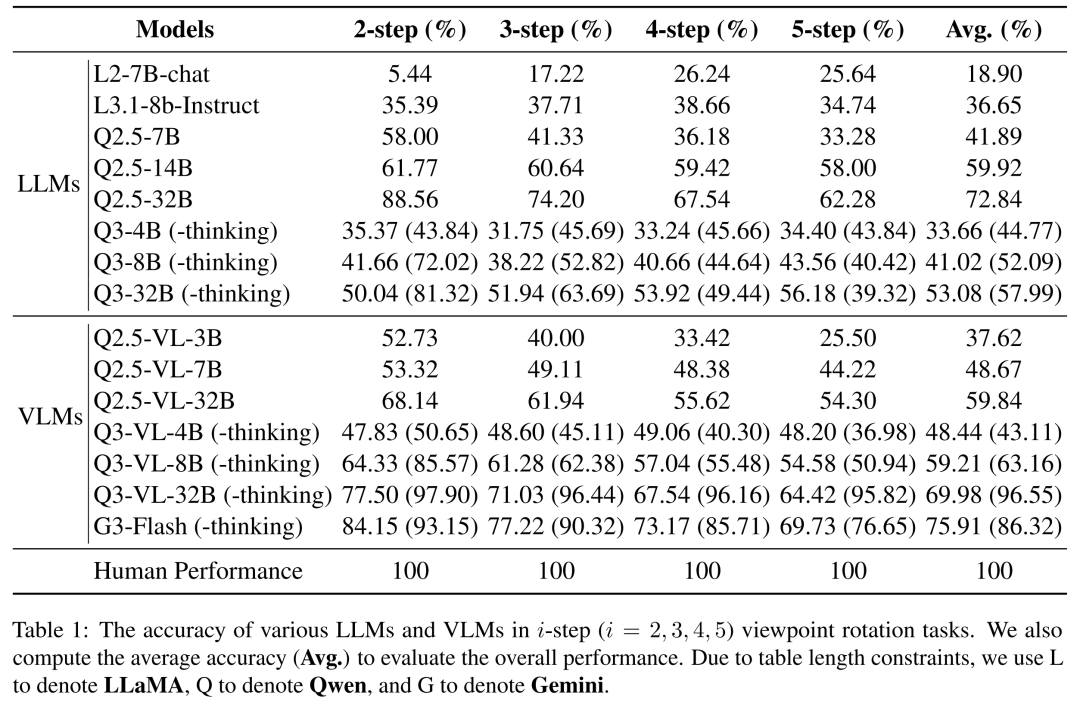
见表1:多种LLM和VLM在VRUBench 2-5步旋转任务上的准确率
结果令人震惊。如表1所示,人类在该测试中能轻易达到100%的准确率,而所有被测AI模型的表现都相去甚远。即使是当时的顶尖模型,如 Qwen3-VL-8B,平均准确率也仅在60%左右;纯文本模型表现更差,Qwen2.5-7B 的平均准确率仅为41.89%。
研究得出了几个关键发现:
视觉训练有隐性增益:在相同架构和规模下,经过视觉数据训练的VLMs(如Qwen2.5-VL-7B)始终优于纯文本LLMs(如Qwen2.5-7B)。这说明视觉训练能提升模型潜在的、甚至纯文本环境下的空间感知能力。
思维链(CoT)推理有效:在纯文本任务中,让模型“先思考再回答”能普遍提升性能。这与某些视觉空间任务中CoT无效的结论形成对比,揭示了文本与视觉空间理解的本质差异。
缩放定律依然成立:模型规模越大,在VRU任务上的表现通常越好,例如Qwen2.5-32B的表现显著优于其7B版本。
尽管有上述规律,但所有模型的绝对性能都与人类存在巨大鸿沟,这迫使我们追问:模型内部到底发生了什么?
02 深入AI“黑箱”:分层探测揭示认知断层
为了揭开谜底,研究人员首先对模型进行了分层线性探测。他们训练简单的分类器,去解读模型每一层隐藏状态中编码的信息。
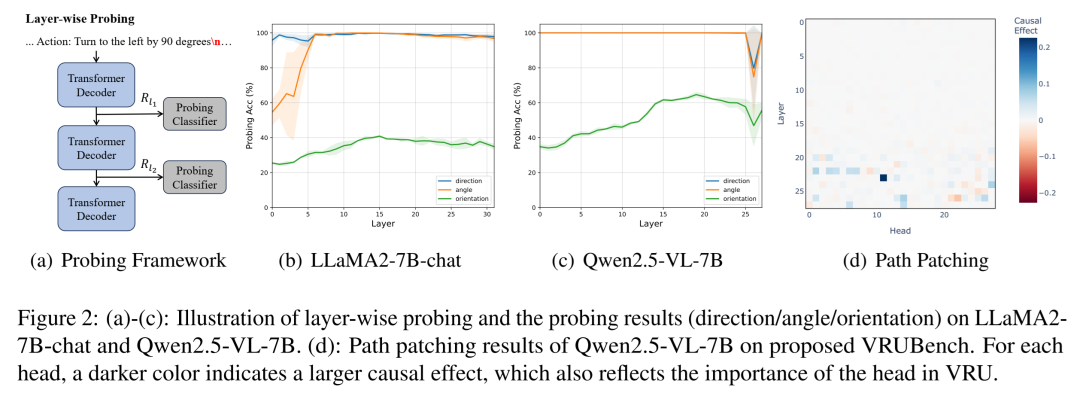
见图2b,c:对Qwen2.5-VL-7B模型进行分层探测,分析其编码“方向/角度”和“绝对朝向”的能力
图2的结果清晰地揭示了模型的“认知”过程:
擅长记忆指令:模型在几乎所有层都能近乎完美地编码每一步旋转的方向(左/右)和角度(0°/90°等),因为这些信息明确地写在输入文本中。
难以维持空间表征:然而,当探测任务变为推断旋转后的绝对朝向时,模型的能力出现了明显断层。有趣的是,VLMs的这种能力在中间层(第1-20层)逐渐形成并达到顶峰,但在最后的8层中却急剧衰退。
这个发现意义重大。它表明,模型的前半部分网络或许在努力计算“我面向哪里”,但到了后半段,这个关键的空间位置信息似乎丢失了,或者被用于其他目的。空间感知的链条在推理中途断裂了。
03 注意力头“角色扮演”:一场失败的绑定
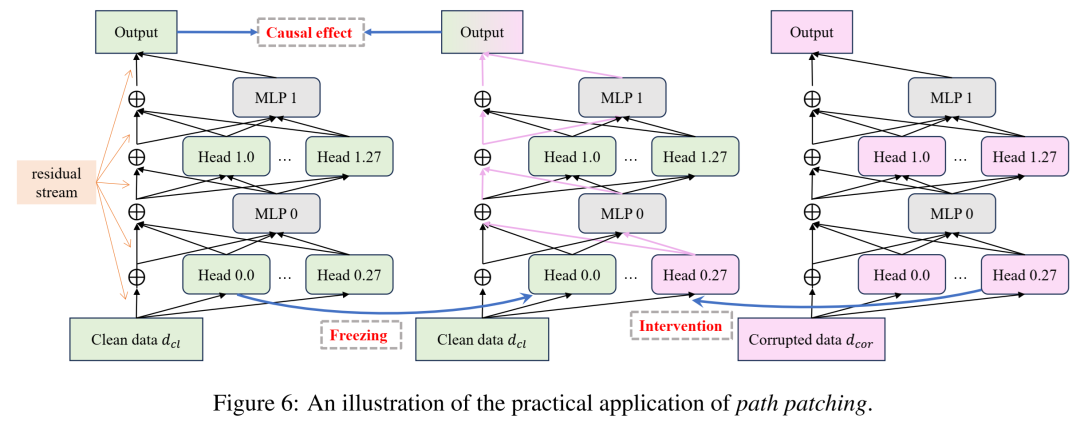
信息在最后几层去了哪里?研究人员使出了更精细的工具——因果干预(路径修补),来定位对任务输出有决定性影响的少数“关键注意力头”。
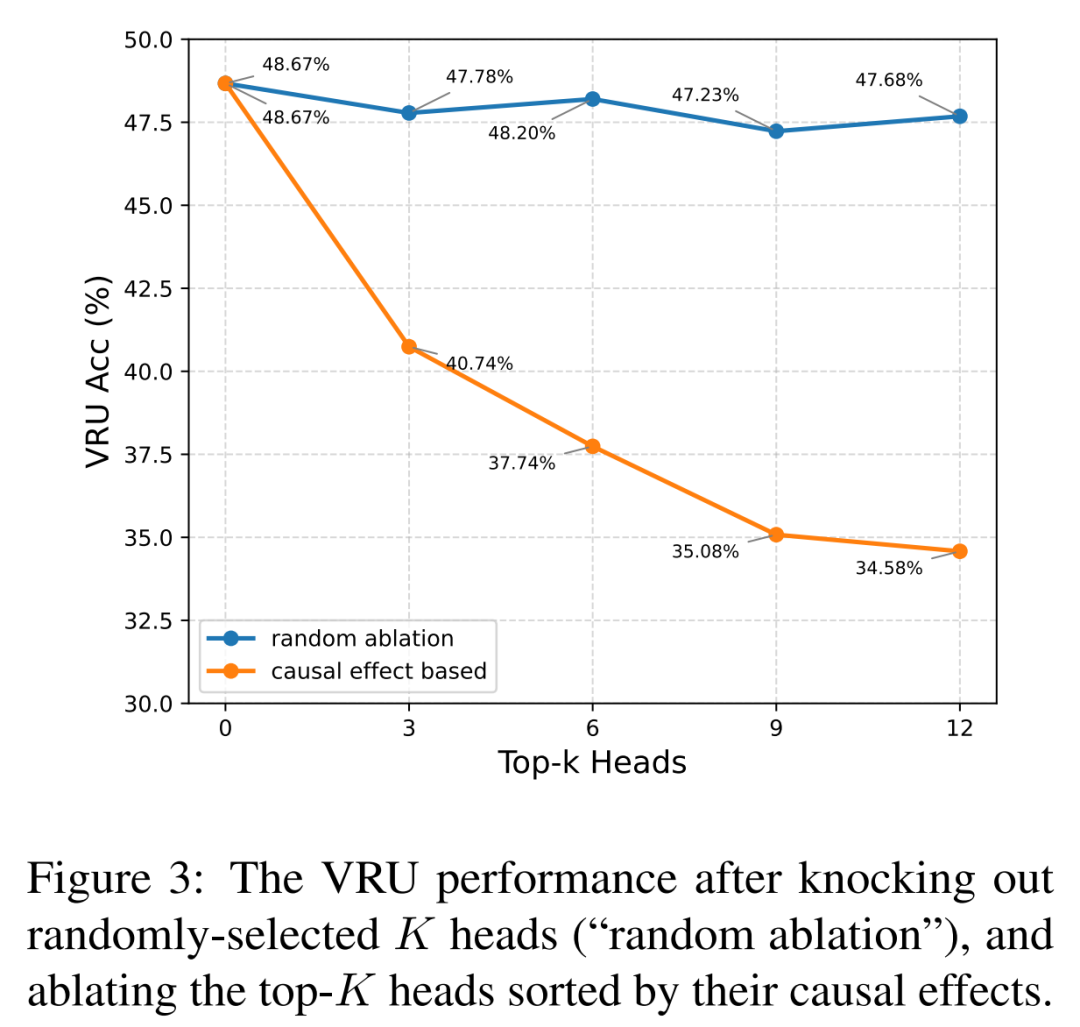
见图3:通过路径修补识别出的关键注意力头及其分布
如图3所示,关键头稀疏地分布在中上层(第21-28层),与绝对朝向编码能力衰退的层区高度重合。这证实了后期的计算模式发生了转变。
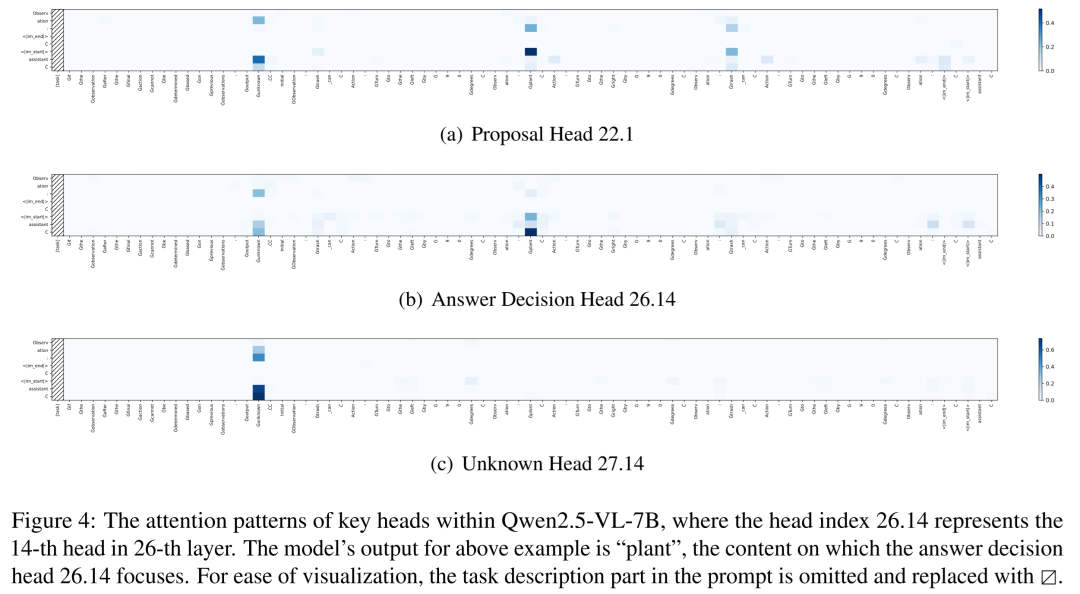
见图4:关键注意力头的注意力模式可视化。以一个问题为例,展示了“提议头”、“答案决策头”和“未知头”的工作机制
通过分析这些关键头的注意力模式,一幕生动的“角色扮演”浮出水面:
提议头(如22.1):像一个信息搜集员,它的注意力均匀地覆盖提示中所有可能的候选答案物体(如“植物”、“垃圾桶”),以及表示不确定的“unknown”。
答案决策头(如26.14):像一个决策者,它从提议头接收候选列表后,会大幅提高对正确答案(“植物”)的注意力权重,同时抑制其他选项。
未知头(如27.14):一个有趣的安全官。即使决策头已聚焦答案,它仍会强烈关注“unknown”。研究发现这是模型经过安全对齐训练后产生的谨慎偏置,倾向于在不确定时回答“未知”。消除这个头会导致模型胡乱猜测。
至此,机制已然清晰:模型前中期计算出的视点朝向,与中后期负责筛选的答案决策头之间,出现了“绑定”失败。决策头无法有效地将“应该面向哪里”与“那里有什么物体”关联起来,导致其选择看似是基于部分信息或随机倾向的“幻觉”答案。
04 精准“脑部手术”:微调少数神经元即可提升
既然找到了“病灶”——那些功能不良的关键注意力头,能否对其进行“治疗”来提升模型的空间智能?研究团队尝试了选择性微调,即只更新被识别出的关键注意力头的参数(仅占总参数的不到1%),而冻结模型其余99%以上的部分。
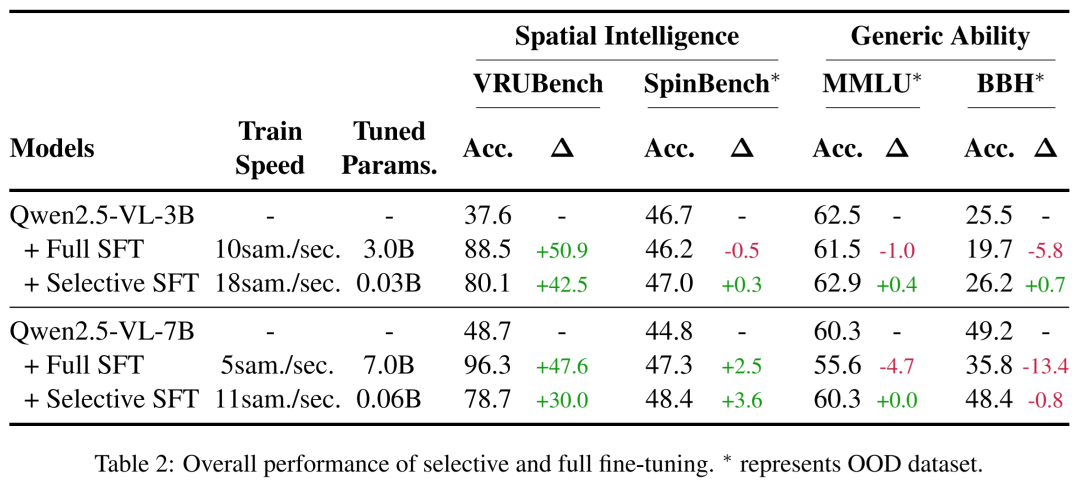
见表2:选择性微调与全参数微调在VRUBench、OOD空间数据集SpinBench及通用能力基准上的表现对比
结果非常鼓舞人心(表2):
高效提升:选择性微调仅用全参数微调50% 的计算开销,就能大幅提升模型在VRUBench上的性能(例如,Qwen2.5-VL-7B从48.7%提升至78.7%)。
避免灾难性遗忘:更重要的是,选择性微调几乎完全保留了模型在MMLU、BBH等基准上的通用能力。而传统的全参数微调虽然提升更大,却严重损害了模型的通用知识。
跨模态迁移:一个更惊人的发现是,仅用文本数据进行的微调,竟然能提升模型在另一项视觉空间任务SpinBench上的表现。这与此前“视觉训练增益文本任务”的发现互为镜像,共同印证了视觉与语言处理在认知上的互补与协同。

05 结论:通往真正空间智能之路
这项研究如同一场精密的神经科学实验,不仅诊断出当前大模型在基础空间推理上的“认知障碍”,还通过可解释性工具定位了功能障碍的特定“神经元”(注意力头),并验证了靶向修复的可行性。
它深刻地揭示:即使是最先进的大模型,其“智能”仍与人类智能有着结构性差异。它们能解析文本指令,能模仿决策过程,甚至表现出对齐后的谨慎,但在需要将不同模态、不同阶段的信息进行动态、精准绑定以构建统一世界模型的核心环节,仍然力不从心。
这项研究为构建具有真正空间智能的AI指明了道路:未来的模型改进不能只依赖“大力出奇迹”的缩放,更需要借鉴此类机理可解释性研究的 insights,进行有针对性的、认知启发式的架构设计或训练。通往人类水平的通用人工智能,我们仍需从理解这些最基础的“能力断层”开始。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢