
论文地址:
https://arxiv.org/abs/2603.12152
Github地址:
https://github.com/sii-research/lifesim.git
Demo链接:
http://fudan-disc.com/lifesim/
01
引言
我们每个人可能都曾期待像电影《楚门的世界》一样,在一个虚拟世界中完整观察一个人的一生。
这听起来很科幻。但在社会模拟中,这其实是一个长期存在的核心问题:无论是公共政策模拟、群体行为建模,还是信息传播机制研究,其背后都需要一个更本质的基础能力——我们是否真正理解并能充分模拟人在漫长时间中的持续行动?
传统的Agent-Based Model,用规则去定义人。它可以粗略刻画宏观现象,却难以还原真实个体的行为演化。大模型带来了新的可能:LLM Agent让“数字人”变得更加生动,但现有方法要么停留在静态画像,要么构建在封闭的虚拟场景之中,它们依然绕开了最关键的挑战——如何让一个人,在真实世界的动态环境中,持续地“活”下去,并生成一条连贯且合理的行为轨迹。这一模拟的复杂性主要体现在两方面:
复杂的外部环境:个体行为并非孤立生成,而是受到时间、地点、天气以及各类生活事件等多维情境因素的共同作用;
动态演化的认知状态:个体的认知状态并非静态不变,而是由个性特征、长期偏好、近期经历以及当前信念共同塑造,并在持续交互过程中不断更新与演化。
由于真实的长期个体行为数据受到隐私与伦理限制,长时间、跨场景、覆盖丰富生活事件的公开数据极为稀缺。针对这些挑战,复旦大学数据智能与社会计算实验室(Fudan DISC)推出LifeSim,一个长程的个体生活模拟框架。LifeSim 从“人如何在环境中做出行为”这一视角出发,以经典的 Belief-Desire-Intention(BDI)认知框架为基础,刻画个体行为与生活轨迹,构建出一个能真正生活在现实世界的“虚拟人”;同时基于LifeSim,研究团队提出了其可行应用 LifeSim-Eval,针对个性化助手服务能力的动态评估环境。本文主要贡献如下:
面向真实生活轨迹的长程个体模拟框架LifeSim:现有基于大模型的个体模拟方法(如 Generative Agents、Sotopia、ProPerSim等)通常仅覆盖单场景多轮对话或短期行为生成。相较之下,LifeSim模拟了跨时间、多场景展开的生活轨迹,并引入基于真实环境的事件构造机制,同时支持长程交互与复杂意图建模。
首个基于认知-环境耦合的长程行为生成机制:LifeSim 提出了一种结合 Belief-Desire-Intention(BDI)认知框架与事件驱动机制的行为生成模型:一方面,通过显式建模用户的长期信念状态与决策逻辑,并引入超过113K条真实意图数据,使行为生成具备稳定且合理的内在驱动;另一方面,基于3374条现实行为轨迹构建事件序列,并通过事件引擎引入时间、地点及生活事件等动态环境因素,使行为能够随外部情境变化而持续演化。
提出大规模长程交互评测基准LifeSim-Eval:在 LifeSim 基础上,本文构建了LifeSim-Eval,一个面向个性化助手的长程交互评测基准,涵盖8类生活主题与1200个跨场景测试实例。该基准通过在线多轮、跨事件的交互形式,系统评估模型在单场景与长期使用过程中的显隐性意图完成能力、用户偏好还原能力以及响应对齐能力。
揭示当前个性化模型的关键瓶颈:基于对十余个开源与闭源模型的系统评测,本文发现:(1)当前模型在显性意图处理上已较为成熟,但在隐性意图理解与完成上仍存在显著短板,且这一问题会在长程交互中进一步加剧。(2) 实验同时表明,简单的画像记忆仅能为部分模型带来有限且不稳定的收益,说明长期用户建模不能仅依赖偏好存储,而更依赖于结合长期历史与动态环境进行持续推理的能力。(3)主动追问不足、推理僵化和个性化不足仍是当前模型的典型失败模式。
本文已被接收为Findings of ACL 2026。
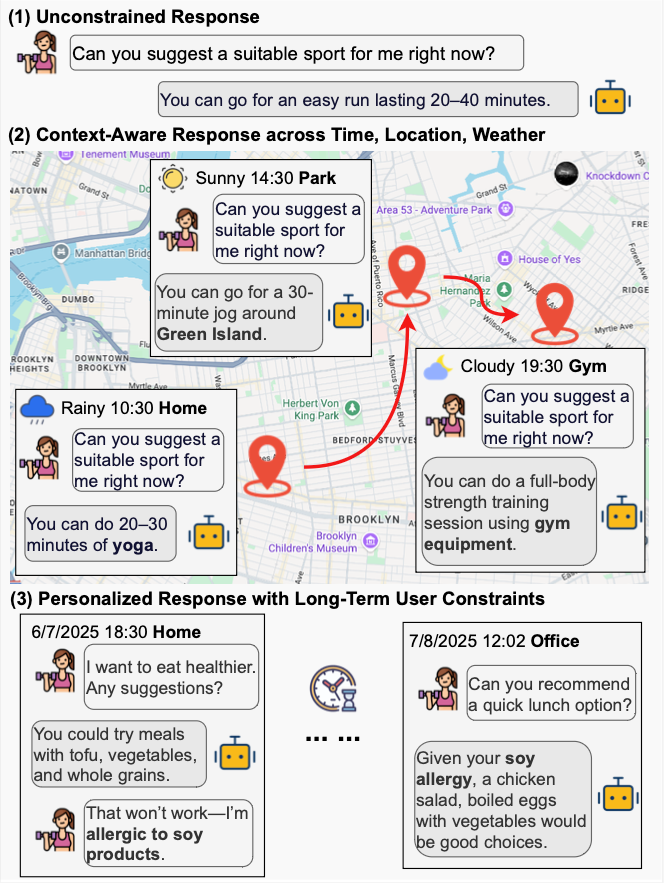
图1 :基于长程时空上下文的个体行为轨迹模拟示意。 个体行为由动态环境驱动并随时间演化,同时体现稳定的内在特质。模型需要融合当前情境与历史信息,对个体状态进行持续推断,以生成跨事件、跨时间的一致性行为序列。
02
LifeSim 框架设计
整体架构
LifeSim 是一个面向虚拟人构建的长程个体生活模拟框架,整体上由四个核心部分组成:
个体画像;
基于信念 - 愿望 - 意图(Belief-Desire-Intention, BDI)的认知引擎;
基于环境约束的事件引擎;
用户行为引擎
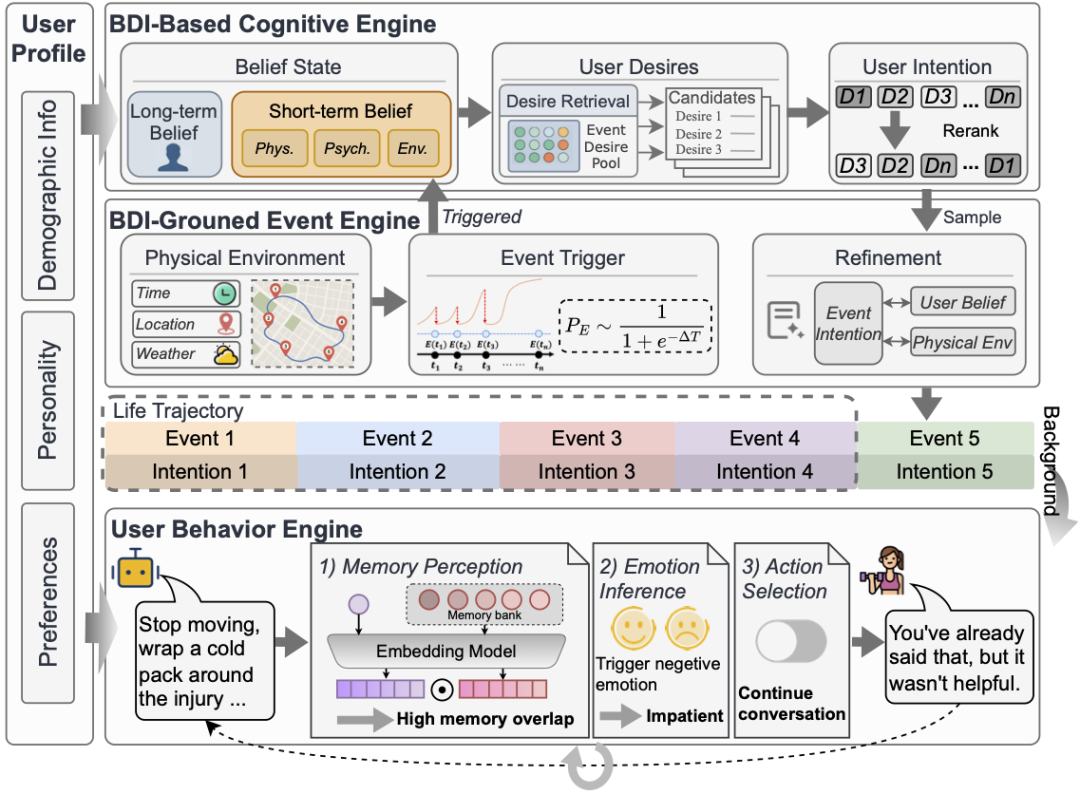
图2:LifeSim 框架概览。针对每个目标个体,其画像包含人口统计学属性、人格特质与长期偏好,这些要素共同构成长期信念状态。基于BDI模型的认知引擎与事件引擎相结合,将主观信念状态与物理环境进行融合,共同生成个体交互意图与生活事件序列。随后,个体行为引擎通过对记忆感知、情绪推理与行为选择进行建模,生成对话内容。
个体画像
为了支持虚拟人多样性,LifeSim 构建了一个百万级画像池。每个画像主要包含三个层面:
- 人口学统计特征,如年龄、性别、教育背景等;
- 人格特征,基于大五人格理论建模;
- 长期偏好,反映日常生活和交互中的稳定倾向。
这些信息共同构成个体的长期信念状态,为后续意图生成与行为模拟提供基础。
认知建模:基于BDI的意图生成
为了模拟个体的内部认知过程,LifeSim 引入了经典的信念 - 愿望 - 意图模型。其中:
- 信念表示当前决策相关的认知状态,包括长期画像与当前情境下的短期认知;
- 欲望表示在当前状态下可能被激发的需求;
- 意图则表示最终形成、准备付诸行动的意图。
在具体实现中,LifeSim会结合画像、近期生活经历以及当前环境,生成合理的事件假设,再进一步推断出目标个体在当下情境中最可能形成的意图。
环境与生活轨迹建模
为了让交互意图不再脱离现实环境,LifeSim在物理环境中生成生活轨迹,并将时间、地点、天气等因素纳入建模过程。论文中使用Foursquare数据集中真实出行轨迹作为环境基础,共收集了3374条出行轨迹、覆盖251个POI。在模拟过程中,事件引擎会根据当前环境和认知状态,逐步生成连贯的生活事件序列,使个体需求能够在合理的生活背景中自然涌现。实验结果表明,LifeSim不仅能够更准确地还原真实生活事件的时间分布规律,还能生成与用户特征一致、逻辑连贯且更具真实感的行为轨迹。
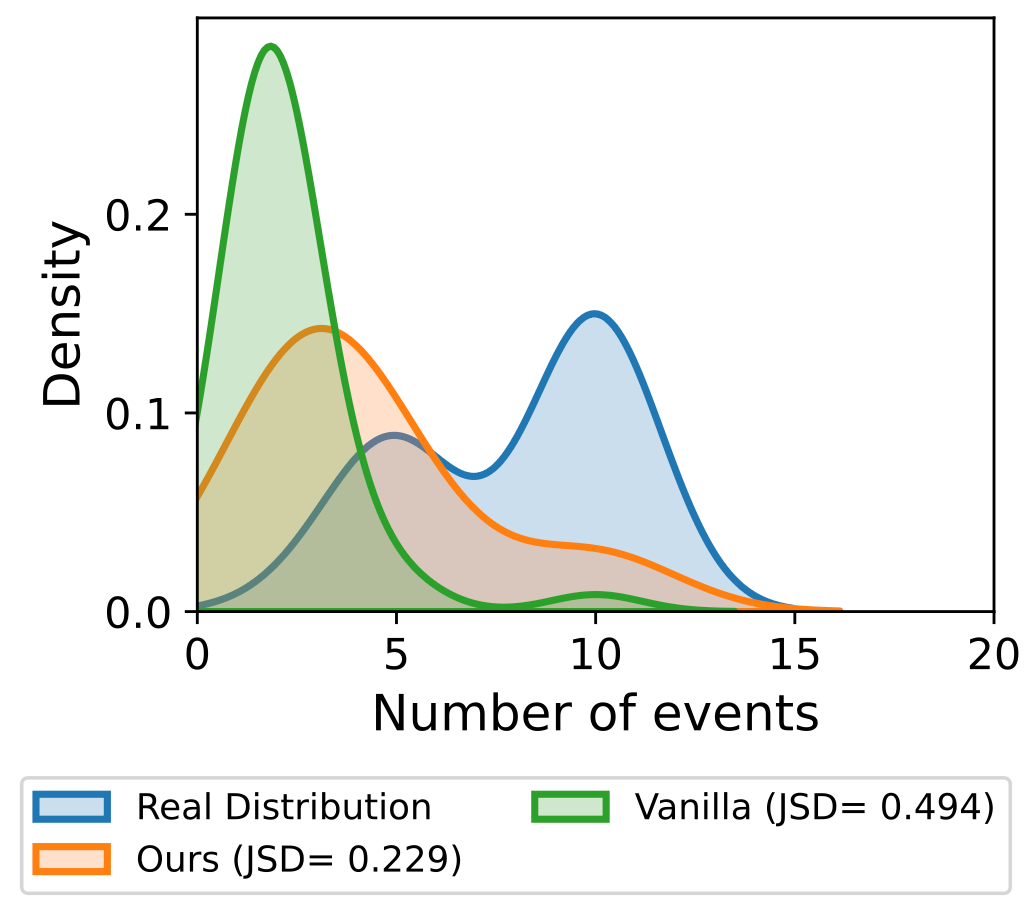
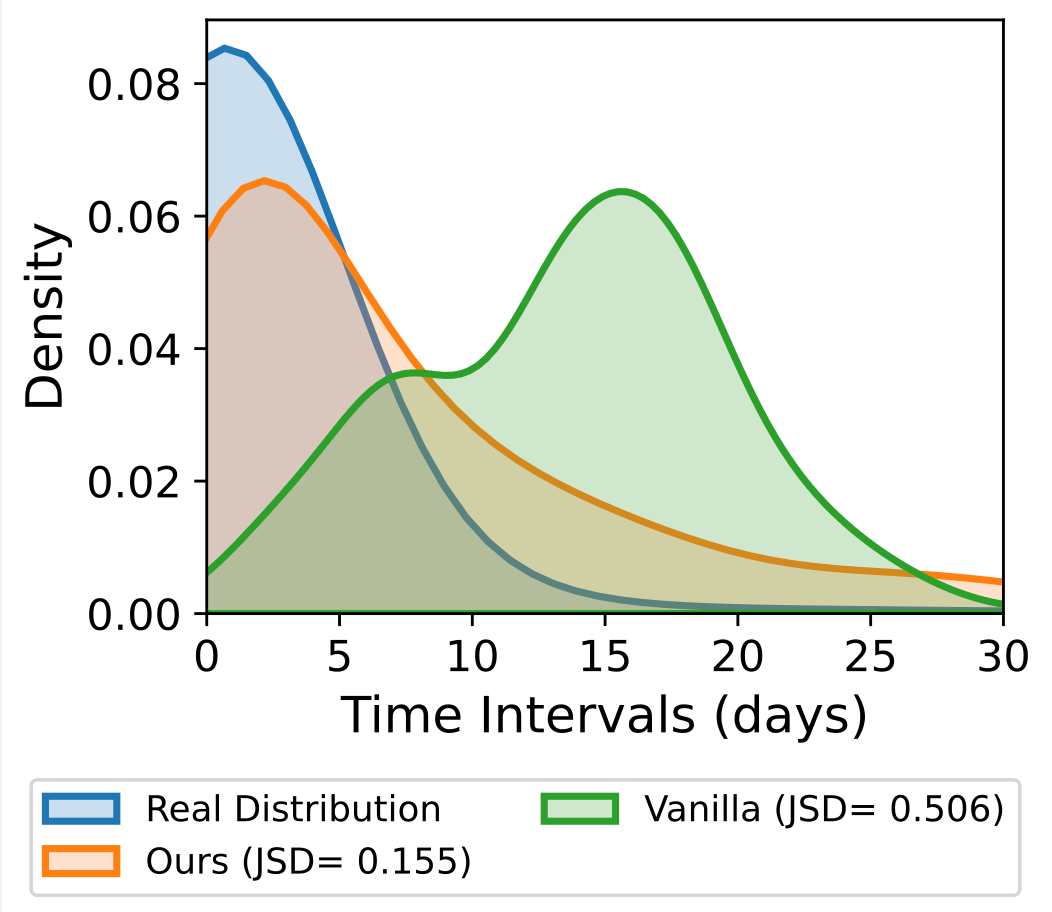

图3(左):不同方法生成的生活事件序列的时间特征分布对比。表1(右):各方法下生活事件序列生成结果的语义一致性与逻辑合理性评估。
个体行为引擎
在给定画像、环境背景与当前意图后,LifeSim的行为引擎会进一步模拟虚拟人在多轮交互中的表现。该模块会综合考虑:
- 对历史对话的记忆感知;
- 当前情绪状态;
- 下一步交互动作选择。
最终生成的回复既需要与画像保持一致,也要符合当前事件背景与对话上下文。论文中的自动评测和人工评测结果都表明,该行为引擎在意图一致性、画像一致性、上下文相关性和自然度等方面都具有较高质量。
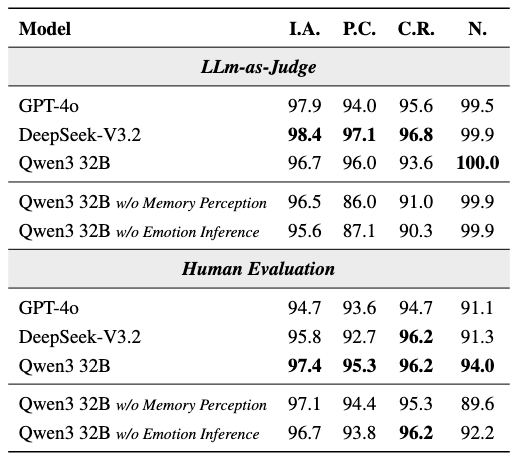
表2:基于不同模型基座的用户行为引擎在四个维度上的性能表现。加粗数值表示最高分。
03
LifeSim-Eval设计
评测目标
基于LifeSim,我们进一步提出了其下游应用:LifeSim-Eval,用于评测模型在长期个性化服务中的核心能力。与传统只关注“是否答对当前问题”的评测方式不同,LifeSim-Eval更关注如下问题:
- 模型能否识别并满足用户的显性与隐性意图;
- 模型能否根据交互历史重建用户画像;
- 模型生成的回复是否真正符合用户画像并保持一致性。
数据构建与任务设置
LifeSim-Eval利用LifeSim构建了120个用户,每个用户对应10个事件序列,共构成1200个评测场景,均匀覆盖 8 个常见生活领域。论文同时设置了两种评测模式:
单场景设置:模型不访问历史交互,只基于当前场景与用户画像完成多轮对话,每个场景最多20轮。这里的隐性意图主要来自场景上下文和用户画像本身。
长时程设置:模型需要结合更长的历史交互记录进行当前场景响应。我们选择其中100个用户构造了从1到10个事件场景的历史对话,最长上下文长度超过14K token,并对所有历史与评测场景进行了人工核验,以确保时间和逻辑一致性。
显性/隐性意图建模
LifeSim-Eval 的一个关键特点,是明确区分了显性意图和隐性意图。
- 显性意图是用户在当前对话中直接表达的需求;
- 隐性意图则需要模型结合用户画像、场景背景和长期偏好进行额外推断。
这使得 LifeSim-Eval 不再只测试模型“能否听懂表面要求”,而是进一步考察它是否真正理解了用户没有明说、但对个性化回复至关重要的潜在需求。
评测指标
LifeSim-Eval 从多个维度对模型进行系统评测,核心包括:
1. 意图识别(Intent Recognition):评估模型能否识别用户的显性和隐性意图;
2. 意图完成度(Intent Completion):评估模型能否在多轮交互中真正完成这些意图;
3. 偏好重建(Preference Recovery):评估模型能否从交互中恢复用户的长期偏好;
4. 画像对齐(Persona Alignment):评估模型回复是否与用户画像保持对齐。
此外,论文还进一步考察了回复的自然度与连贯性。
04
实验结果与关键发现
我们在多类主流 LLM 上进行了系统评测,涵盖 GPT-5、GPT-4o、Claude Sonnet 4.5、DeepSeek-V3.2、DeepSeek-V3.2 Thinking,以及 Qwen、Gemma、Llama、gpt-oss 等多个开源/闭源模型族。实验揭示出以下几个核心结论:
1. 显性意图较强,隐性意图明显更难
在单场景设置中,大多数模型在显性意图识别上表现较好,但在隐性意图识别上普遍存在超过 20 分的性能差距。这说明当前模型已经较擅长处理用户直接表达的需求,但对于需要结合上下文和用户状态推断出的潜在需求,能力仍明显不足。此外总体来看,除 DeepSeek 外,闭源模型在多数指标上通常优于开源模型,尤其在隐性意图识别与完成上更具优势。同时,更大的模型规模通常也会带来更好的整体表现。
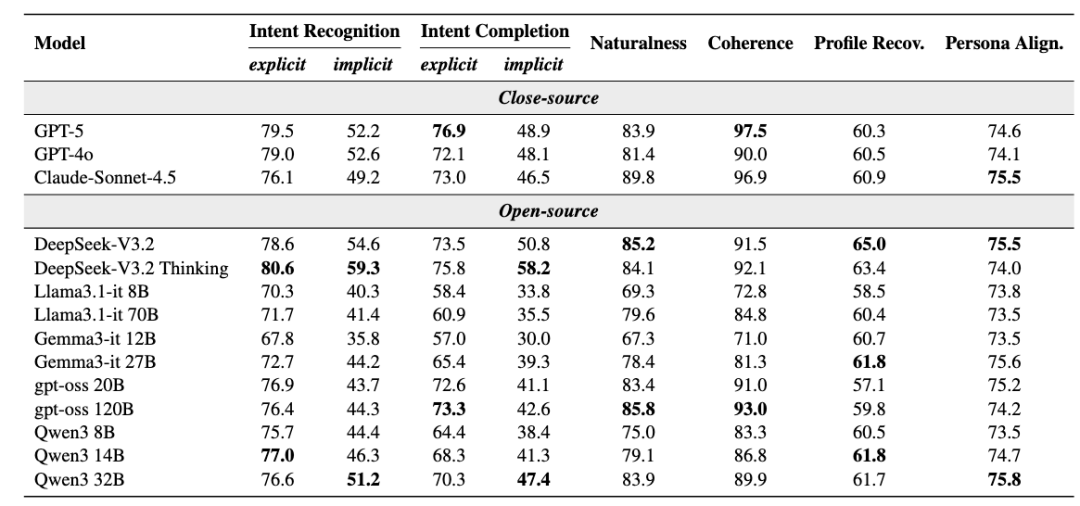
表3:开源大模型与闭源大模型在 LifeSim-Eval 上的评测结果,评测维度包括意图识别与完成度、回复质量,以及基于个性化回复的用户建模能力。所有数值均线性归一化至 [0,100] 区间。加粗数值表示在开源或闭源模型中得分最高。
2. 长程对话会进一步放大隐性意图处理难度
在长时程设置中,模型对显性意图的完成率相对稳定,但对隐性意图的完成能力明显更弱,且会随着历史长度增加而进一步下降。这表明现有模型虽然能够在长上下文中维持对表层任务的处理能力,但一旦需要基于长期证据进行用户状态与偏好推理,就会出现明显退化。
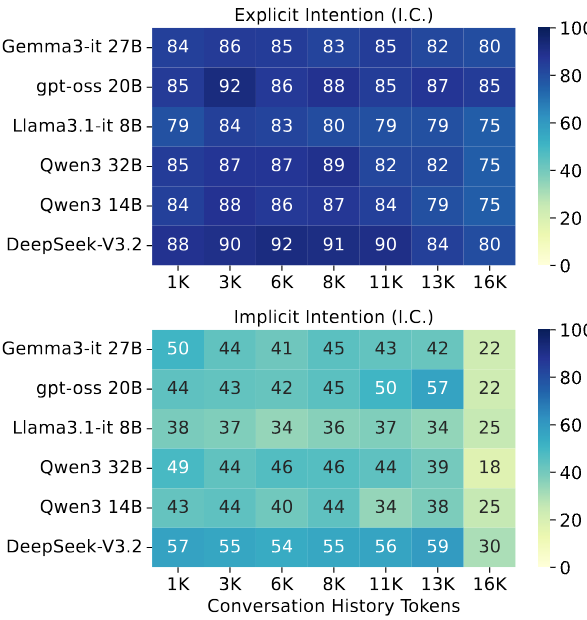
图4:不同助手模型的长时序意图完成性能。热力图展示了意图完成度(I.C.) 得分随对话长度的变化情况。
3. 简单记忆机制收益有限
论文进一步测试了画像记忆机制:在每个场景后,让模型总结或更新用户偏好,并提供给后续场景使用。结果显示,虽然这种做法对用户偏好的重建有一定帮助,但整体收益并不稳定,甚至有些模型几乎没有提升。这说明长期个性化能力的瓶颈并不只是“记不住”,更在于模型是否具备稳定的长期偏好推理能力。
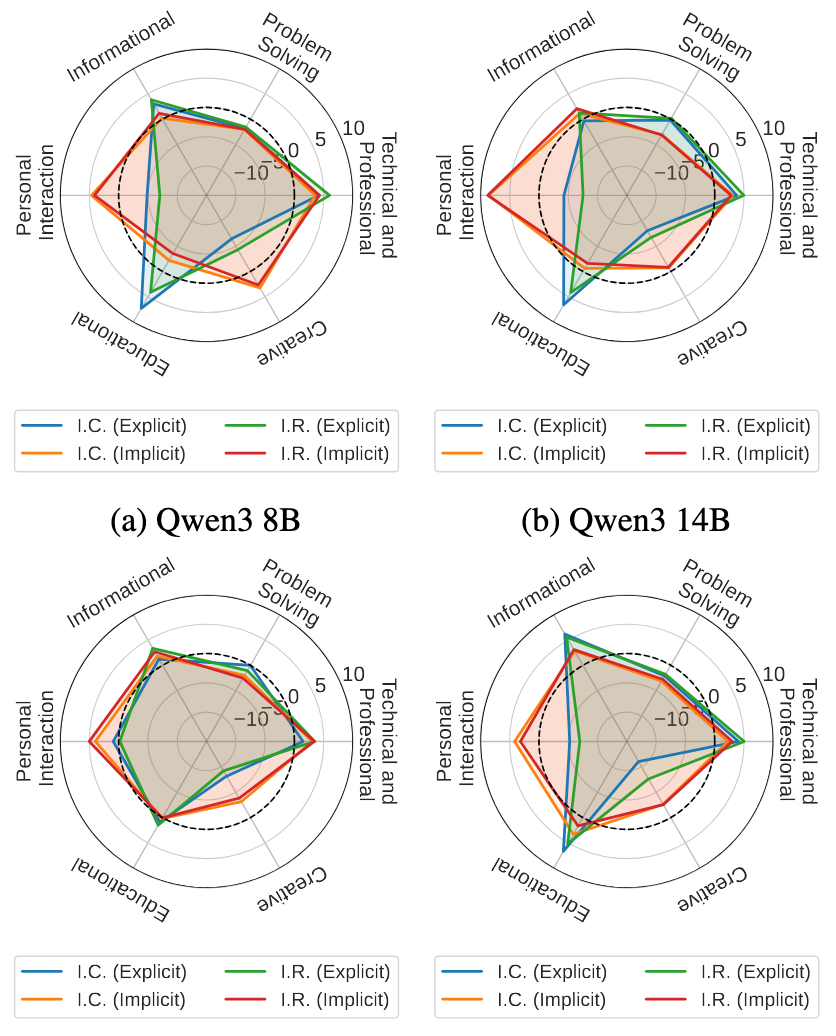
图5:生活事件序列中用户偏好还原的性能。虚线表示通过线性回归拟合得到的回归曲线。
4. 不同意图类型和主题上的表现并不均衡
论文还分析了不同意图类别和事件主题的结果差异。在以显式、任务驱动需求为主的场景,与需要隐式、情感推理的场景之间,模型在显隐性意图任务的性能存在明显差异。这种异质性表明,当前模型在不同服务领域的鲁棒性参差不齐,需要我们在个性化助手设计中进行更细粒度的优化。
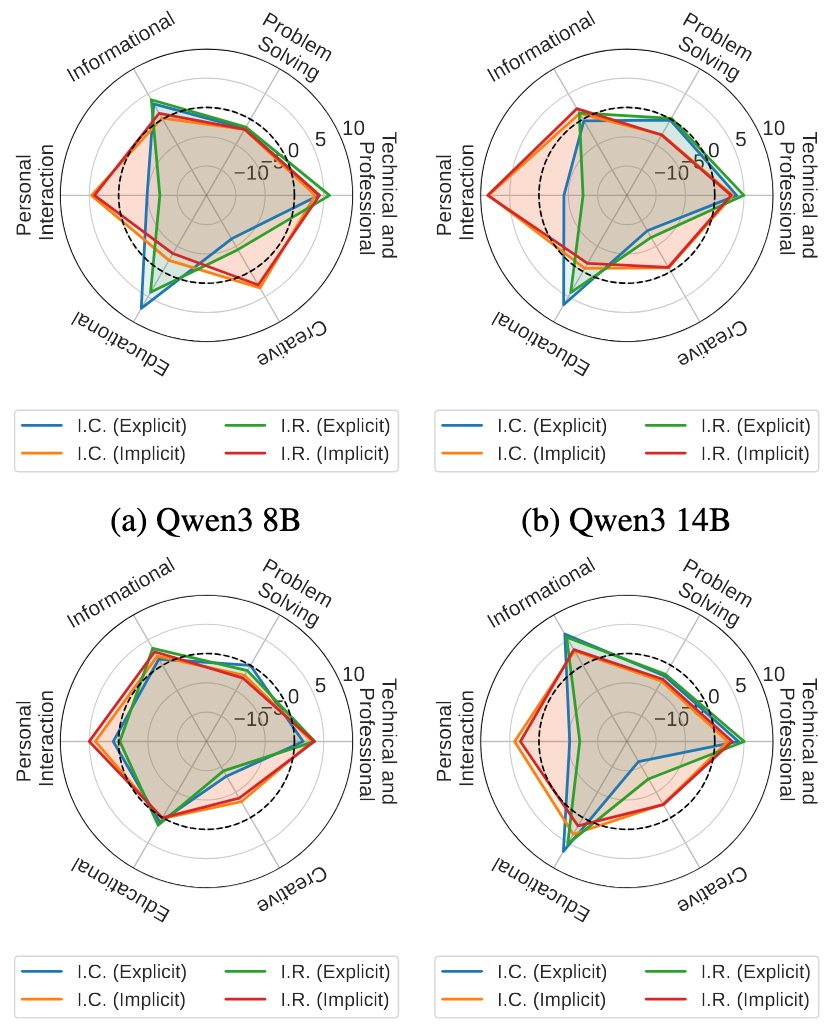
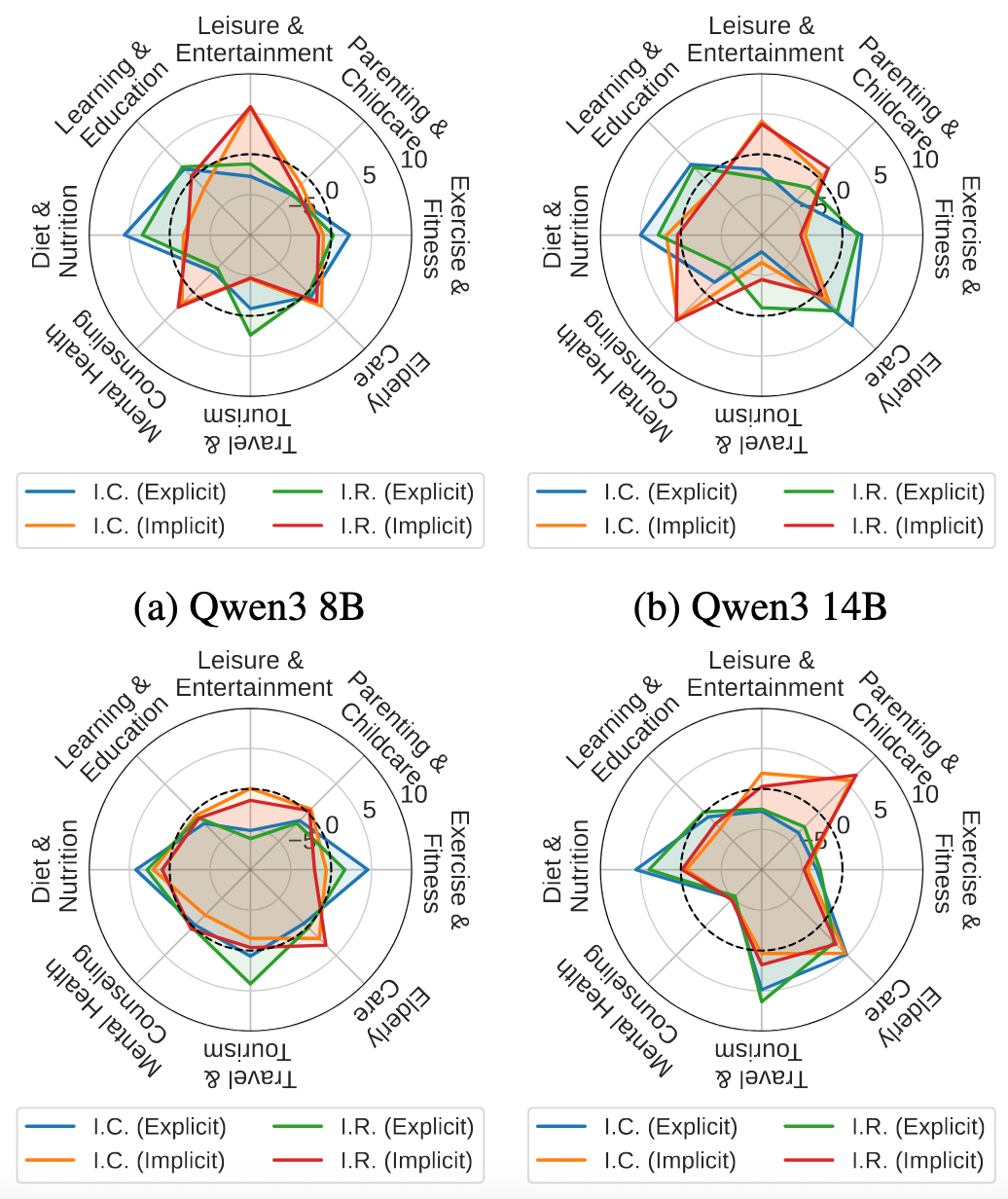
图6(左):不同意图类型下的模型相对性能。图6(右):不同意图主题下的模型相对性能。
5. 模型存在三类典型问题
通过案例分析,我们总结出当前模型在长期个性化助手任务中常见的三类问题:
- 推理僵化:模型容易固守最初的解决路径,面对用户新增约束时缺乏动态调整;
- 主动追问不足:即便关键信息尚不明确,模型也常直接给出建议,而不是主动澄清用户需求;
- 用户画像利用不足:虽然拿到了用户画像,但模型往往只能知道有这些信息,却不能真正把它们融入回复策略中。
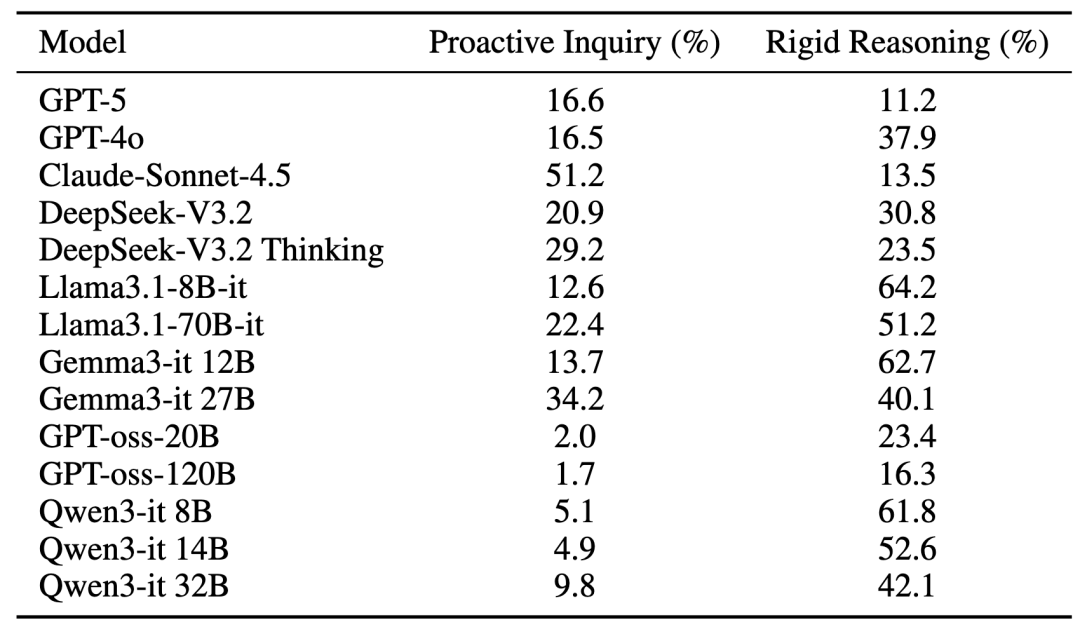
表4:各模型的主动询问占比与僵化推理占比
05
总结
本研究提出了LifeSim,系统性地将个体模拟从静态画像与短期对话扩展到面向真实生活轨迹的长程动态交互建模。与传统方法相比,LifeSim不仅通过引入基于BDI的认知建模刻画用户长期信念与决策过程,还进一步融合时间、地点、天气与生活事件等动态环境因素,实现认知与环境的耦合驱动,从而更真实地模拟个体在复杂现实情境中的连续行为与意图演化。基于LifeSim,我们构建了下游应用LifeSim-Eval,对主流模型的个性化服务能力进行系统评估,揭示了当前模型在隐性意图理解与完成上的短板,以及长期个体建模能力的不足。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区袁天凡、慧敏校园C栋

点击“阅读原文”跳转至论文主页
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢