
论文标题:Diverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification 论文链接:https://arxiv.org/abs/2012.00317 代码链接:https://github.com/youngwanLEE/VoV3D 作者单位:韩国电子通信研究院 3D 时间建模新架构,由时间one-shot聚合(T-OSA)模块和深度分解因子D(2 + 1)D组成,表现SOTA!性能优于X3D、SlowFast和TEA等,代码刚刚开源!
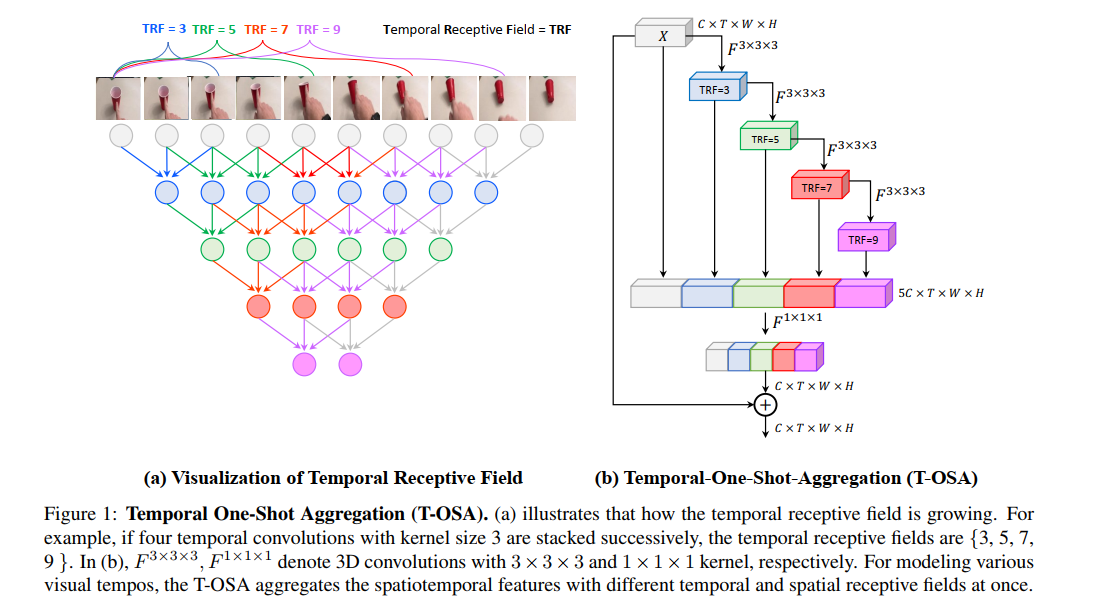
最近引起关注的视频分类研究是时间建模和3D高效架构的领域。但是,时间建模方法效率不高,或者3D高效架构对时间建模的兴趣较小。为了弥合它们之间的差距,我们提出了一种高效的时间建模3D架构,称为VoV3D,该架构由时间one-shot聚合(T-OSA)模块和深度分解因子D(2 + 1)D组成。 T-OSA被设计为通过聚合具有不同时间感受野的时间特征来构建特征层次。堆叠此T-OSA,使网络本身无需跨任何外部模块即可跨帧对短时和长时关系进行建模。受内核分解和通道分解的启发,我们还设计了一个深度时空分解模块D(2 + 1)D,该模块将3D深度卷积分解为两个空间和时间深度卷积,以使我们的网络更轻便高效。通过使用提出的时间建模方法(T-OSA)和有效的因式分解分量(D(2 + 1)D),我们构造了两种VoV3D网络,即VoV3D-M和VoV3D-L。由于其时间建模的效率和有效性,VoV3D-L的模型参数减少了6倍,计算量减少了16倍,在Something-Something和Kinetics-400上都超过了最新的时间建模方法。此外,VoV3D与最新的高效3D架构相比,具有更好的时间建模能力,X3D具有可比的模型容量。我们希望VoV3D可以作为有效视频分类的基准。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢