

新智元报道
新智元报道
【新智元导读】DeepSeek V4,1.6万亿参数,Codeforces人类第23,KV缓存砍到1/10。同一周Kimi K2.6万亿MoE开源,也在推国产芯片混合推理。中国AI的底座和芯片,同时动了。
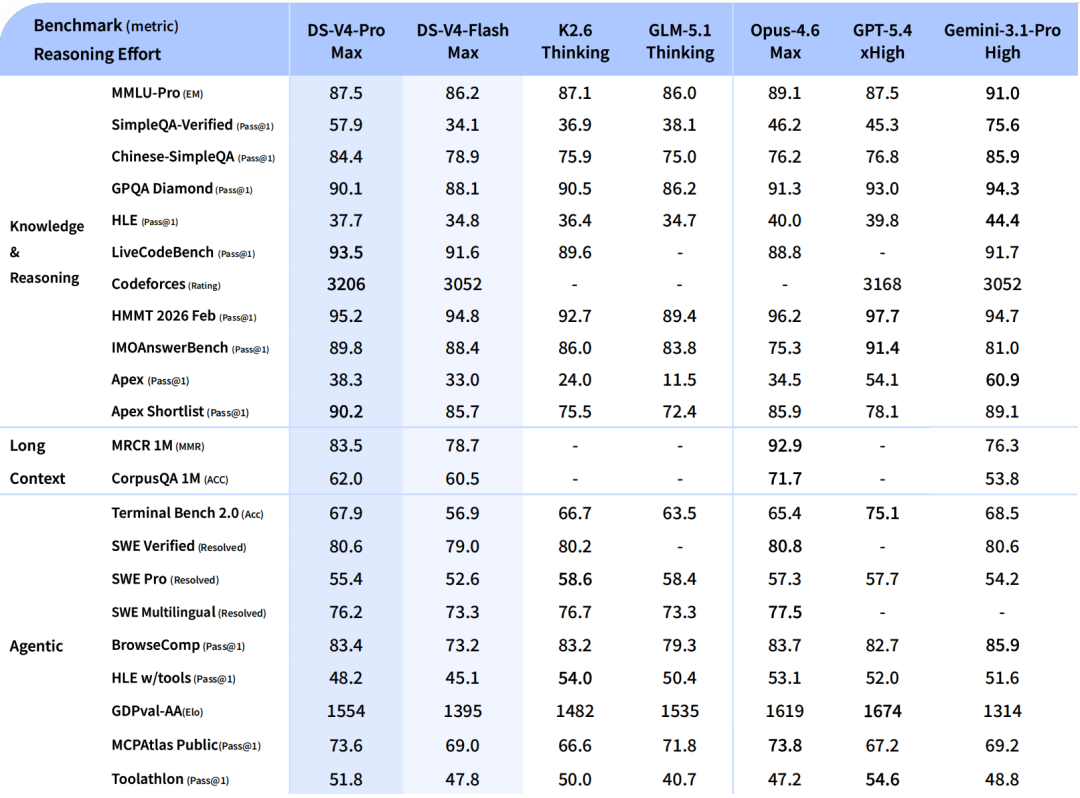
DeepSeek V4,炸了!
1.6万亿参数,百万token上下文KV缓存砍到前代的十分之一,Codeforces评分3206直接超过GPT-5.4,在人类选手中排第23。
开源权重、API、近60页技术报告一起扔出来,社区已经开始拆了。

但我们翻完技术报告准备收工的时候,突然反应过来一件事。
这周一,Kimi K2.6刚刚开源。万亿参数MoE模型,支持300个子Agent协同,OpenRouter调用量直接冲到全球第一。
等等。
同一周,两个万亿参数中国开源模型先后落地?真的不是约好的吗?

回看过去15个月,DeepSeek和Kimi的瞄准的技术方向和发布时机,对齐到让人怀疑是约好的。
2025年1月,DeepSeek-R1推理模型和Kimi K1.5多模态思考模型同日上线,相隔仅两小时。OpenAI 的Paper 也指出他们两家是最早复现o1思维链的团队。
2025年2月,两家前后脚发论文,都在改造Transformer注意力机制。DeepSeek的NSA做原生稀疏注意力,Kimi的MoBA做混合块注意力,
2025年4月,Kimi推出 Kimina-Prover Preview数学推理专项模型没多久,DeepSeek-Prover-V2 也发布,都走了「自验证」路线来证明数学定理。
2026年初,DeepSeek用mHC流形约束超连接来改造深度学习网络中的「残差连接」。到了3月,Kimi放出新技术「注意力残差」,直接将Transformer的核心原理「注意力」应用到「残差连接」上,引发Karpathy、马斯克等大神称赞。
2026年4月,万亿开源模型 Kimi K2.6和DeepSeek V4同周上线。
多次「相遇」的表面之下,是一个更微妙的现象,两家公司的技术在互相加持。
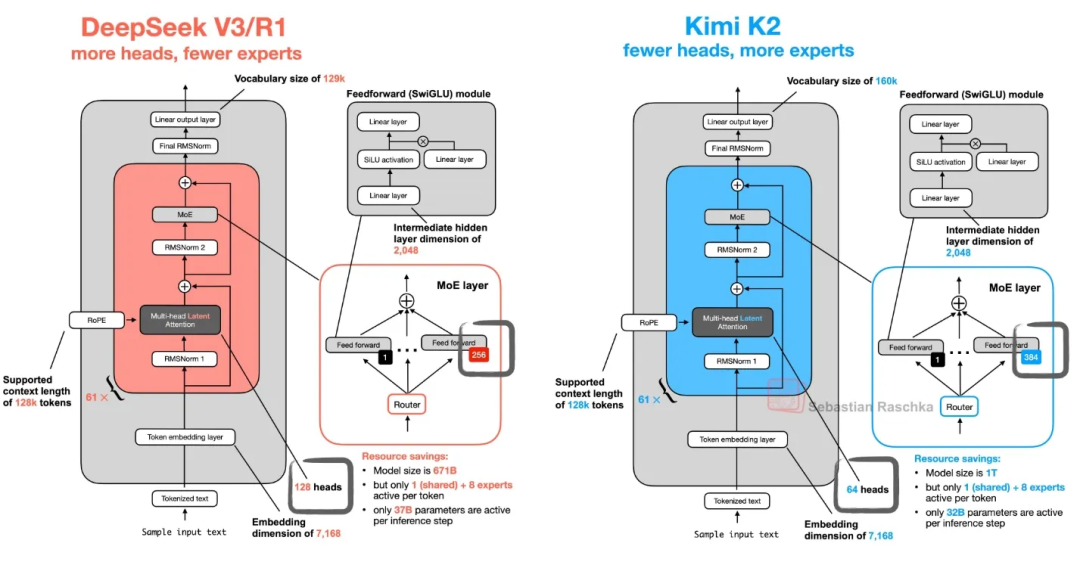
Kimi K2的注意力机制采用了DeepSeek首创的MLA(Multi-head Latent Attention)。
传统多头注意力需要为每个注意力头单独存储Key和Value,上下文越长KV缓存越大。
MLA的做法是把Q/K/V压缩到一个低秩的latent向量中,推理时只需缓存这个压缩向量再解压,KV缓存量大幅缩减。
在这套注意力机制上,K2扩展到了万亿参数的MoE模型。
反过来,DeepSeek V4采用了Muon优化器。
主流的AdamW对每个参数独立做自适应缩放,Muon则对整个梯度矩阵做Newton-Schulz正交化,让更新方向在矩阵空间中更均匀。
Muon最初由Keller Jordan等人提出,但只在小模型上验证过。
2025年初,Kimi团队的Moonlight论文中首次把Muon扩展到大规模训练,实验显示相同算力下Muon的计算效率约为AdamW的两倍。
2025年中,在万一参数的K2模型上,进一步开发出MuonClip,加入QK-clip来控制注意力logits的数值范围,实现了15.5万亿token预训练全程零loss spike。

V4技术报告里引用 Kimi 的Muon优化器论文,写得很明确,对大部分参数使用Muon优化器,带来更快的收敛和更好的训练稳定性。

底层技术上的同频还不止于此,至少还有三条线在平行推进。
KV缓存。
Kimi的Mooncake把KV缓存做了分离式存储和调度,DeepSeek V4设计了异构KV缓存结构,把压缩KV和滑动窗口KV分开管理并支持磁盘级存储。都在解决同一个工程瓶颈。
长上下文。
Kimi 2024年做了百万上下文的模型实验,是国内最早把「长文本」从技术概念变成用户记忆点的公司,但当时成本还没降下来。
长上下文真正的难点从来都在成本端,读得越长,账单越难看,延迟越难控,KV缓存越堆越高。读得起、读得稳、读完还能干活,才是产品化门槛。
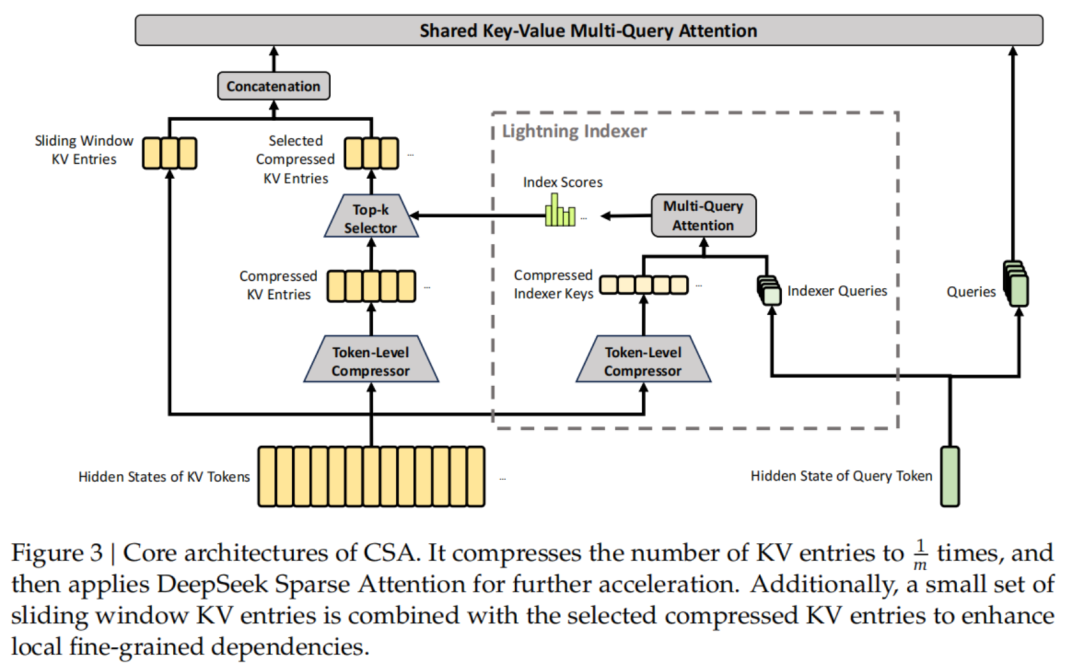
DeepSeek V4这次接过了这根棒,设计了CSA(压缩稀疏注意力,每4个token的KV合并后再做top-k选择)和HCA(重压缩注意力,压缩率128倍但保持全局稠密计算)交替堆叠,推理算力降到V3.2的27%,KV缓存只剩十分之一。
 | 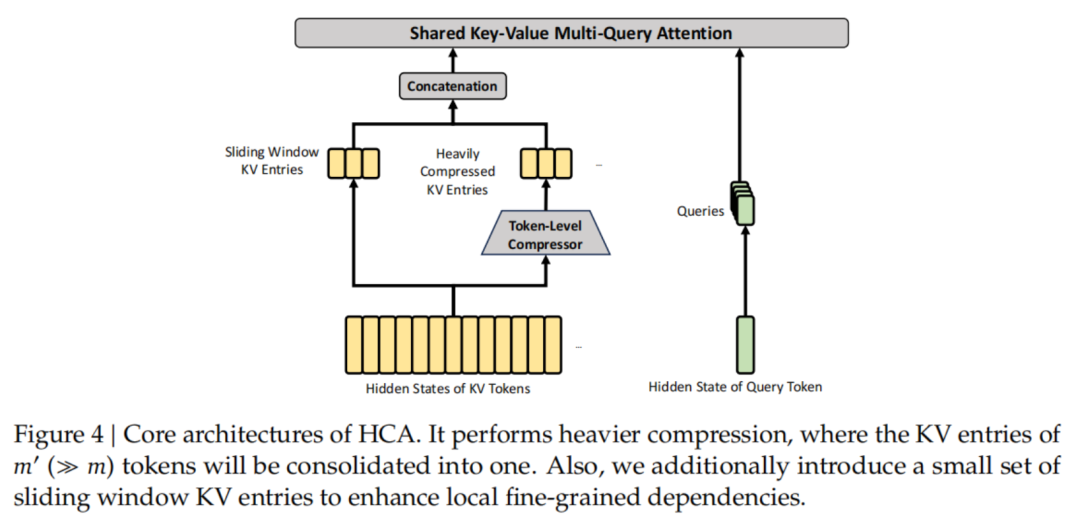 |
注意力架构的下一步。
DeepSeek押稀疏注意力,核心假设是长序列中大部分KV条目对当前query贡献极小,可以安全跳过。
Kimi下一代模型探索线性注意力,核心假设是注意力计算本身可以被重新表述为线性形式,把复杂度从序列长度的平方降到线性。
一个在筛选哪些token值得看,一个在改写「看」这个动作本身的计算规则。
殊途同归,都在往Transformer最要命的成本结构里动刀。

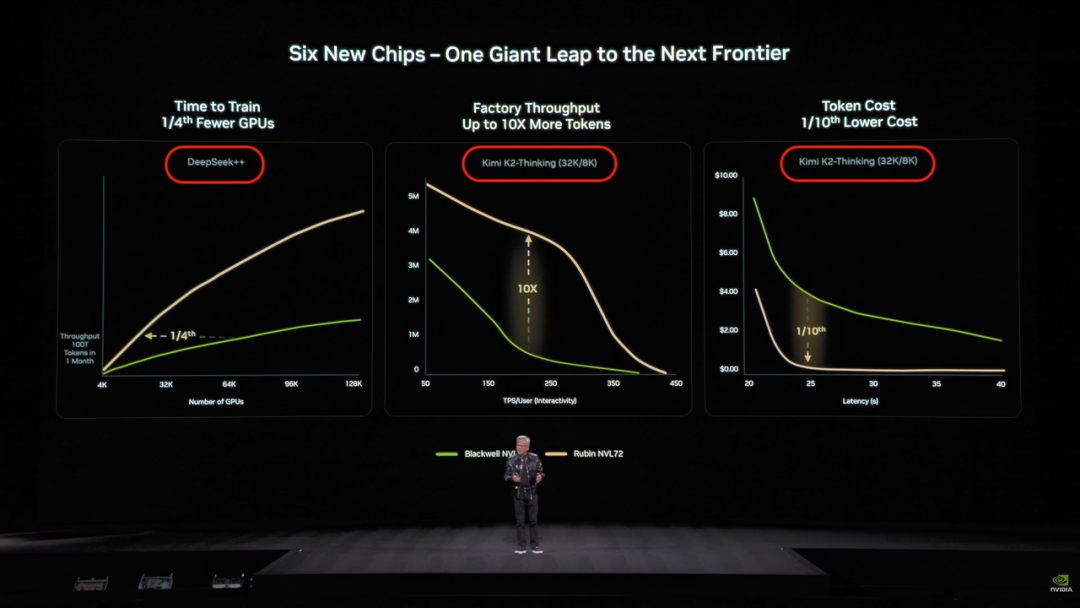
2026年初的CES大会上,黄仁勋展示Rubin NVL72性能的slide里,训练基准用的是DeepSeek,推理吞吐和token成本基准用的是Kimi K2-Thinking。
同一张PPT,两个中国开源模型。
Meta的Muse Spark官方Blog里也出现了类似的画面。
在代码困惑度对比图中,用来对标的外部模型,就是Llama 4 Maverick、DeepSeek-V3.1 Base和Kimi-K2 Base。
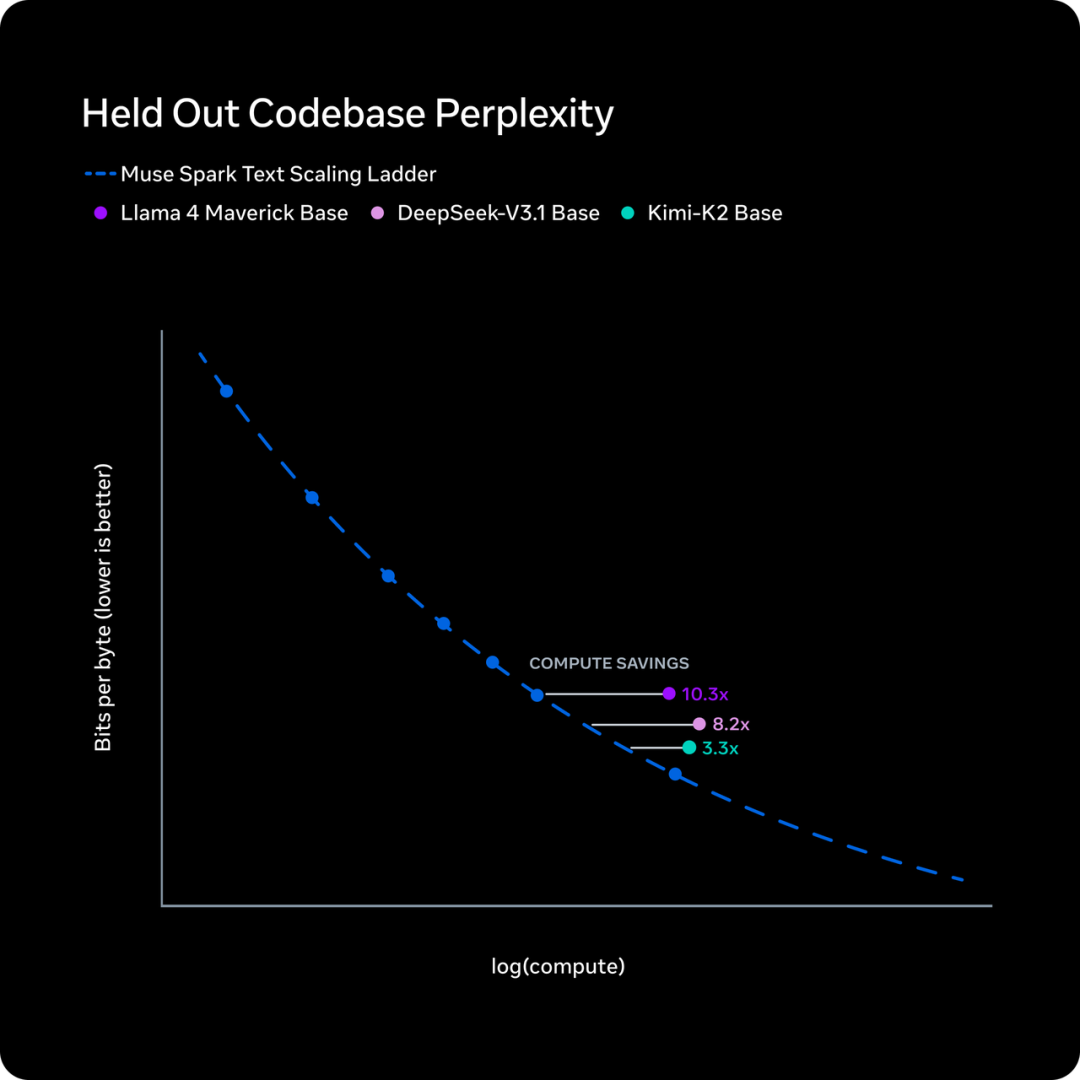
衡量模型在未见过的代码库上的理解能力,越低越好

2026年3月19日,估值500亿美元的AI编程工具Cursor发布「自研」模型Composer 2。
结果还不到一天,就被开发者在API日志中扒出了模型ID「kimi-k2p5-rl-0317-s515-fast」。
也就是说,Composer 2的底座就是Kimi K2.5。
Cursor创始人承认「没在博客里提到Kimi基座是我们的疏忽」,并表示「基于困惑度评估,Kimi K2.5是我们测试过的最强基座模型」。


无独有偶,日本乐天同月发布的Rakuten AI 3.0,底座也被社区发现是DeepSeek V3。
开发者端的数据也印证了这个趋势。
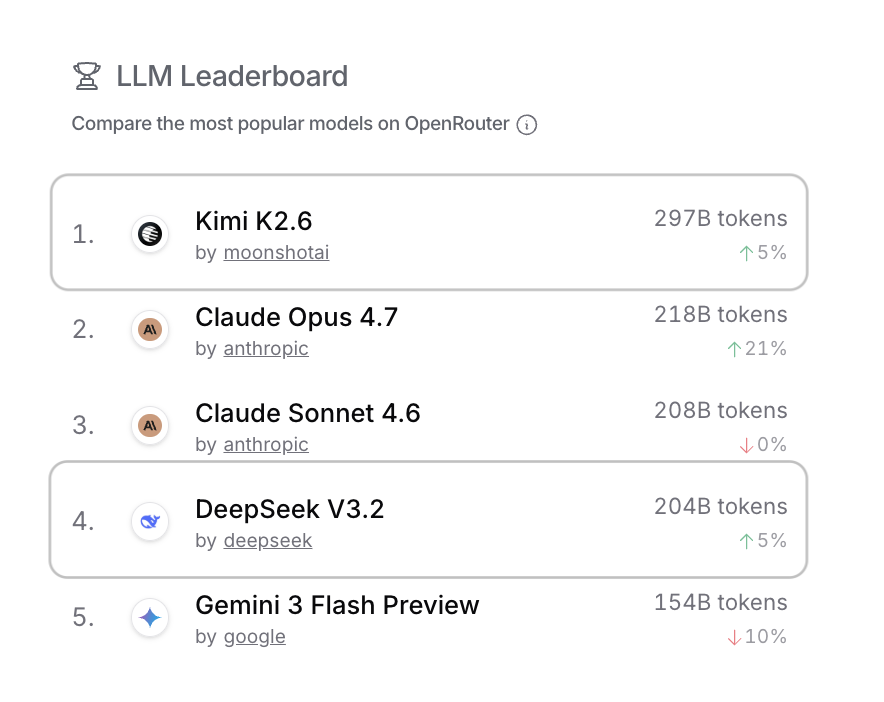
今天的OpenRouter调用量排行榜上,Kimi K2.6以297B tokens排名第一,DeepSeek V3.2以204B tokens排名第四。
前五名里两个中国模型,中间夹着Claude。

而在芯片这条暗线上,两家也在同一个方向推进。
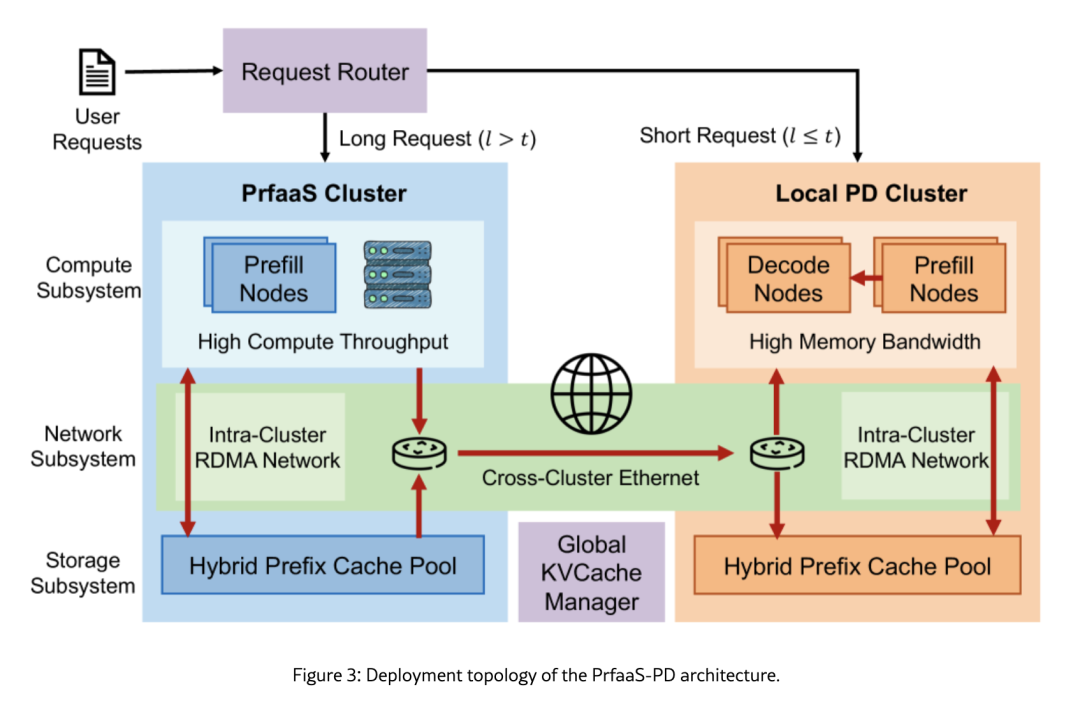
V4技术报告明确写到,细粒度专家并行方案同时在NVIDIA GPU和华为Ascend NPU上完成了验证。Kimi新论文《Prefill-as-a-Service》则引入分离式架构,推进国产芯片的混合推理方案。

值得一提的是,梁文锋和杨植麟都先后参加了总理座谈会,都是中国AI领域被点名的代表。
两家公司都在2023年起步,两年多时间成长为中国AI创业公司中最受关注的两家,也是业内公认人才密度最高的团队。
 |  |

如果只有一家,可以说是个例。
但同一周两个万亿参数开源模型同时落地,背后的技术还在互相渗透,被GTC和Meta选为性能基准,被Cursor和Rakuten拿去当底座。

当某些闭源模型之间还在互相猜忌的时候,这两家已经在论文里互相引用、在代码里互相复用了。
这大概就是开源最硬的复利。
https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢