
DRUGONE
大语言模型常常会生成看似合理但实际上错误的信息,这种现象被称为“幻觉”,严重影响其在高可靠性场景中的应用。尽管已有大量方法用于缓解这一问题,例如检索增强、工具调用、自一致性验证以及基于人类反馈的强化学习,但幻觉现象在当前最先进模型中依然普遍存在。
研究人员指出,这一问题不仅来源于模型本身,还源于训练目标与评估机制的共同作用。首先,在预训练阶段,基于“下一个词预测”的目标,即使在完全无噪声的数据下,也会对模型产生统计上的幻觉倾向。其次,在后续训练与评估中,以“准确率”为核心的评价指标,反而鼓励模型在不确定时进行猜测,而不是承认不确定性。
为了解决这一问题,研究人员提出重新设计评估机制,引入“开放评分标准”(open rubric),明确规定错误与不作答的评分方式,从而改变模型的行为激励。研究表明,通过调整评估方式,可以显著减少幻觉,并推动模型更合理地表达不确定性。这一工作将幻觉问题从模型缺陷转化为激励机制问题,为提升模型可靠性提供了新的思路。

在实际应用中,大语言模型往往会像人类考试中的学生一样,在面对不确定问题时倾向于“猜答案”,而不是承认不知道。这种行为导致模型输出大量自信但错误的信息。
传统观点认为,幻觉主要来源于训练数据中的错误或知识缺失,但研究人员指出,即使训练数据完全正确,这一问题仍然不可避免。原因在于模型的训练目标是最大化语言概率,而不是保证事实正确性。
进一步地,语言模型在学习过程中更容易掌握重复出现的模式,例如语法规则或常见事实,而对于一次性出现或稀有信息(如具体生日等),则难以准确学习。这种结构性差异导致模型在某些任务上天然更容易出错。
与此同时,当前主流评估体系以准确率为核心指标,并将“不作答”视为错误,这使得模型在优化过程中更倾向于输出猜测结果,从而加剧幻觉问题。
因此,研究人员提出,需要从训练目标与评估机制两个层面重新理解幻觉问题,而不仅仅是通过模型改进来解决。
方法
研究人员从计算学习理论出发,提出了一种统一分析框架,将语言生成问题转化为一个“有效性判断”任务,即判断模型生成的内容是否正确。
在这一框架中,模型不仅需要生成文本,还隐式地进行“是否有效”的分类判断。通过这一转化,研究人员能够利用经典学习理论分析模型的误差来源,并推导出幻觉产生的下界。
同时,研究人员系统分析了当前评估体系的激励机制,特别是二元评分(正确或错误)如何导致“猜测优于不作答”的策略。
在此基础上,提出“开放评分标准”的评估方法,即在问题中明确告知评分规则,例如错误是否会被惩罚,从而使模型能够根据不同情境调整行为。
该方法不仅改变了评估方式,也间接改变了模型优化目标,使其更加符合实际应用需求。
结果
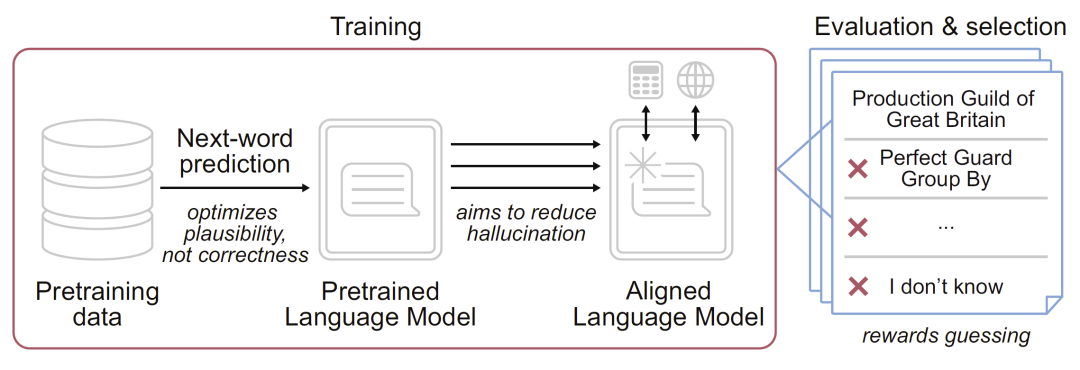
图1 占位:幻觉产生机制示意。
图1展示了幻觉在训练与评估过程中的产生路径:预训练阶段的概率建模引入幻觉倾向,而后续以准确率为导向的评估进一步强化了这一行为。模型在整个流程中逐渐形成“优先猜测”的策略,而不是表达不确定性。
预训练阶段的幻觉来源
研究人员通过理论分析表明,即使在理想情况下,语言模型也不可避免地产生幻觉。这一结论源于有限数据下的统计学习限制。
对于重复出现的知识(如语法规则或常见事实),模型能够较好学习并保持低错误率;但对于稀有或一次性信息,由于缺乏模式,模型难以泛化,从而产生较高的错误率。
例如,在图2中可以看到,拼写等规则性任务表现良好,而涉及具体事实(如生日)的任务则更容易出现错误。这说明幻觉并非单一原因造成,而是由数据分布与学习机制共同决定。

图2 :有效性分类与错误来源。
评估机制如何加剧幻觉
研究人员发现,在当前主流评估体系中,模型若选择不作答通常被视为错误,而猜测则有一定概率得分。因此,从期望收益角度来看,“猜测”始终优于“放弃”。
这一现象在多个基准测试中普遍存在,大多数评估采用二元评分体系,缺乏对不确定性的合理处理。这种设计使得模型在训练和选择过程中逐渐偏向生成内容,而不是保持谨慎。
研究人员通过系统分析多个主流评测基准发现,绝大多数评估方法都在无意中强化了这种行为模式。
开放评分标准的效果
在引入开放评分标准后,模型行为发生显著变化。研究人员在多个前沿模型上进行实验,结果显示,在明确错误惩罚的情况下,模型更倾向于在不确定时选择不作答,从而减少幻觉。
此外,当评分规则允许或鼓励猜测时,模型又能够恢复猜测行为。这表明模型具备根据激励机制调整策略的能力。
更重要的是,在开放评分体系下,降低幻觉不再以牺牲准确率为代价,从而解决了传统评估中的核心矛盾。
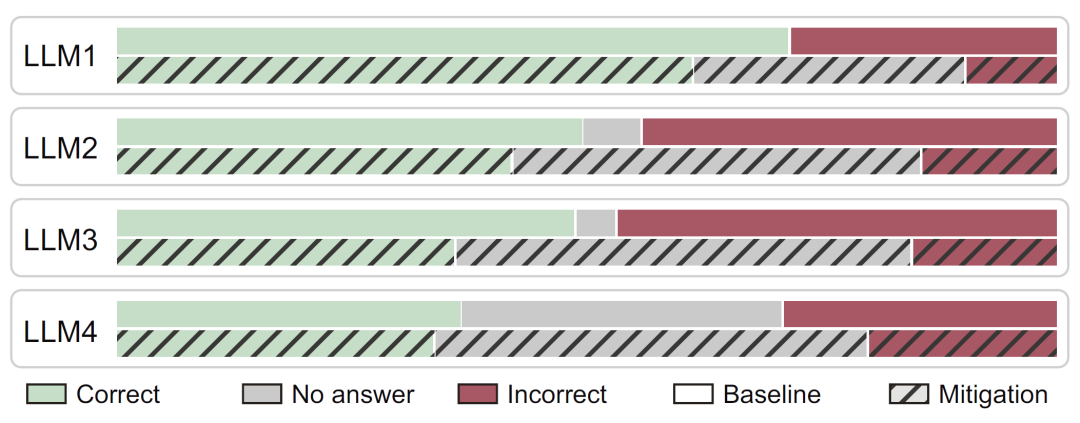
图3:开放评分机制实验结果。
讨论
该研究从全新的角度重新审视了大语言模型的幻觉问题,将其归因于训练目标与评估机制的不匹配,而非单纯的模型能力不足。
研究人员指出,当前评估体系将模型置于类似“考试模式”的环境中,迫使其在不确定时做出猜测。这种机制不仅影响模型行为,还在模型开发过程中持续强化这一偏好。
通过引入开放评分标准,研究人员展示了一种简单而有效的解决方案,使模型能够根据不同场景合理调整行为。这种方法不仅适用于现有模型,也为未来评估体系的设计提供了重要参考。
总体而言,该研究表明,提高大语言模型可靠性的关键,不仅在于构建更强大的模型,还在于设计更合理的评估与激励机制。这一视角为人工智能系统的可靠性研究提供了新的方向。
整理 | DrugOne团队
参考资料
Kalai, A.T., Nachum, O., Vempala, S.S. et al. Evaluating large language models for accuracy incentivizes hallucinations. Nature (2026).
https://doi.org/10.1038/s41586-026-10549-w

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢