
在金融研报、行业分析、企业报告等场景中,大量关键信息隐藏在图表中。然而,传统RAG系统主要依赖OCR提取文本,只能“读文字”,难以理解图表中的结构与数据关系,导致问答结果不完整甚至错误。
为解决这一问题,澜舟推出面向图表理解的多模态RAG技术,实现从“读文本”到“读图表”的能力升级。在FinRAGBench-V数据集上,系统准确率从69.6%提升至90.7%,提升超过21个百分点。
传统RAG在处理文本信息时表现出色,但在面对真实世界中的复杂文档时仍存在明显局限,本质问题不在于“模型能力不足”,而在于“信息建模方式过于单一”。
具体表现为:
缺乏对图表的结构化语义建模能力,无法有效抽取关键数据、图表类型及语义信息;
检索机制单一,缺乏对图表内容与文本上下文的联合建模,难以精准召回图表级证据;
图表理解依赖“看图即答”,缺乏基于图像操作的多步推理能力,复杂场景下易出错;
答案生成仅依赖文本,缺乏图文融合表达,结果可读性与可验证性不足。
为此,澜舟提出面向图表理解的多模态RAG技术,将系统能力从“文本检索”升级为“跨模态理解与推理”,并将核心能力统一抽象为“建模-检索-推理-生成”的四阶段闭环,重点实现以下四个核心能力跃迁:
1. 图表语义建模:从“非结构化图像”到“结构化语义表示”
基于视觉语言模型与多模板驱动机制,对图表进行细粒度解析,抽取关键数据、趋势关系及元信息(如图表类型、坐标语义等),构建统一的结构化图表语义表示。
2. 跨模态检索:从“单通道文本检索”到“图文融合检索”
融合文档级检索与图文检索机制,引入视觉语言模型进行跨模态相关性建模与证据筛选,实现图表内容与文本上下文的联合召回与精排。
3. 图表推理增强:从“看图即答”到“基于图像操作的多步推理”
引入Thinking-with-images推理范式,通过图像裁剪、缩放等可执行操作,逐步完成复杂图表中的数据定位、关系分析与数值推断,提升复杂场景下的推理准确性。
4. 图文融合生成:从“单一文本生成”到“图文协同表达”
融合图表证据、图像内容与文本上下文进行统一生成,在答案中动态插入图表内容,实现图文交织的表达形式,提升结果的可读性与可验证性。
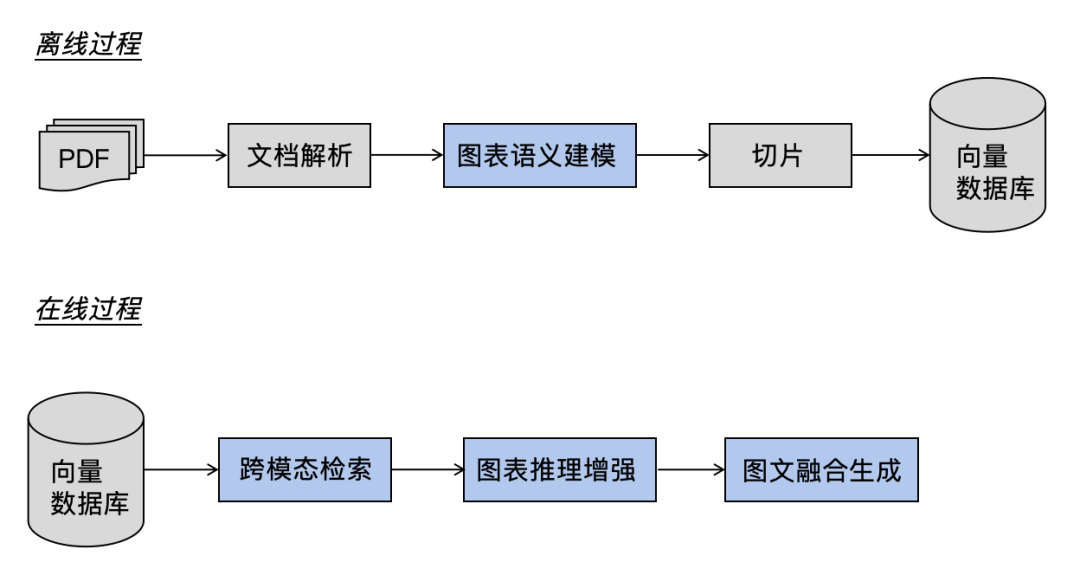
澜舟的多模态RAG系统在离线阶段完成图表语义建模与索引构建,在在线阶段依次执行跨模态检索、推理增强与图文融合生成,形成完整的多模态问答闭环。
具体流程如下:
离线阶段(数据构建)
文档解析(基础能力):从PDF中解析出文本和表格的内容,识别出图像与矢量图表的位置坐标,导出为点位图入库。
图表语义建模:抽取图表的结构化语义信息(如图表类型、关键数据、趋势关系及上下文语义),形成图表的摘要。
切片:将文本段落与图表按照层级树进行组织,将全文按照层级进行切片,作为最小可检索粒度。
向量化存储:对分片和图表摘要分别进行向量化表示,写入向量数据库,支持跨模态检索。
在线阶段(问答推理)
跨模态检索:联合文档级检索与图文检索,召回相关文本与图表内容,基于视觉语言模型对召回的图表做进一步筛选。
图表推理增强:通过图像操作与多步推理机制,抽取支撑回答的关键证据。
图文融合生成:融合图表证据与文本上下文,生成图文交织的最终答案。
图表语义建模
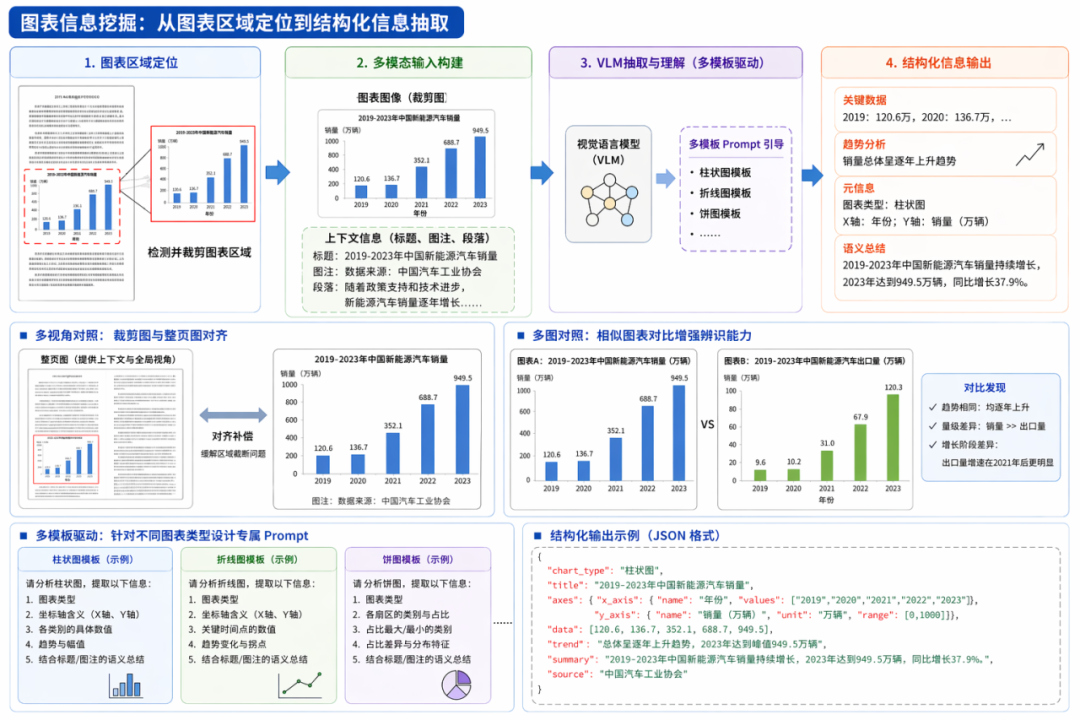
在离线阶段完成图表区域的识别与定位,并构建图表图像及其上下文信息。基于视觉语言模型(VLM)对图表进行结构化语义建模,统一抽取关键数据、趋势关系及元信息,显著提升多模态问答对图表内容的理解能力。
具体而言,图表语义建模能力可以从多模态信息抽取、多模板驱动以及多图对照与上下文增强三个方面实现:
多模态信息抽取:将裁剪得到的图表图像及其上下文(标题、图注、段落)输入视觉语言模型(VLM),联合建模图像与文本信息。自动抽取图表中的关键数据(数值、趋势)、元信息(图表类型、坐标轴含义)及语义,生成格式化的描述。
多模板驱动:针对不同图表类型(如柱状图、折线图、饼图等),设计专属 Prompt 模板,引导模型聚焦对应的结构特征与信息要素。
多图对照与上下文增强:引入多视角对照机制:一方面将裁剪图与整页图进行对齐,补偿文档解析中可能存在的区域截断问题;另一方面对相似图表进行对比建模,增强模型对细粒度差异的辨识能力。
跨模态检索
传统检索方式存在一定局限:仅采用文档级检索会对整段内容进行统一建模,图表信息容易被淹没在大量文本中;而仅依赖图文检索则只关注图表本身,对上下文与文档语义利用不足,且对相似图表的区分能力有限。为此提出融合式跨模态检索策略,兼顾全局语义与图表细粒度信息。
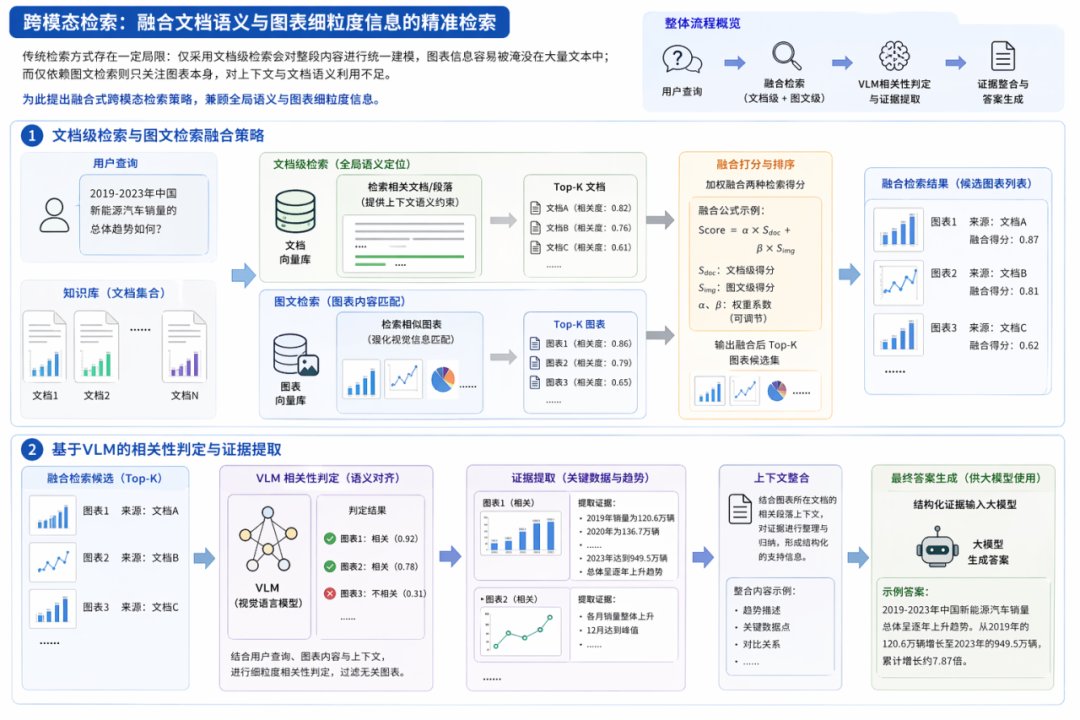
文档级检索与图文检索融合策略:同时引入文档级检索与图文检索两种机制,对候选结果进行联合建模与打分融合。文档级检索负责从全量内容中定位相关段落,提供上下文语义约束;图文检索聚焦图表内容,强化对视觉信息的匹配能力。通过融合两者得分,实现对相关段落的更准确召回与排序。
基于VLM的相关性判定与证据提取:在检索之后,引入视觉语言模型对候选图表进行细粒度相关性判定,结合用户查询与图表内容进行语义对齐,过滤掉语义相似但与问题无关的图表。对于判定为相关的图表,进一步从中抽取能够支撑回答的问题证据(如关键数据点、趋势描述、对比关系等),并结合上下文进行整理,供后续大模型进行最终答案生成。
检索效果展示,Recall@k表示检索topk图表的召回率,Acc表示相关性判定后保留的图表准确率:

图表推理增强

在图表信息挖掘与证据提取阶段,“读图即答”难度高、易出错,引入基于图像操作的推理增强机制,提升复杂图表中关键信息抽取的准确性:
基于图像交互的推理方式:针对复杂图表中元素定位与数值读取困难的问题,不再依赖一次性读图或纯文本推理,而是引入Thinking-with-images的多步推理方式。在证据提取过程中,模型通过逐步分析图表结构,完成区域定位、关系判断与关键数据识别。
可执行图像操作与工具调用:在沙盒环境中运行 Python 代码,对图像进行缩放、裁剪、切分及绘制辅助线等操作,辅助模型精确定位目标区域并读取数值信息。通过“生成代码—执行—输出图片—反馈”的方式,将图像操作纳入推理链路,降低数值估算误差。
推理能力训练(SFT + RL):通过监督微调与强化学习相结合的方式,训练模型在多步推理过程中合理调用图像操作工具,学习稳定的分析路径与错误纠正策略。重点提升模型在复杂图表场景下的逐步推理能力与结果可靠性。
图文融合生成

基于检索与证据抽取结果,构建图文融合的答案生成机制:
多源信息融合生成:将图表中提取出的证据、相关图片,以及检索得到的文本段落一并输入大模型进行统一生成。模型在生成过程中同时利用图像信息与文本上下文,对问题进行综合推理,输出完整答案。
图文交织表达:在生成答案时,根据内容引用位置,将对应的图表图片以链接形式插入到文本中,实现图文交织展示。图片通常出现在相关论述或数据解释处,使答案既包含文字说明,又保留图表作为直观支撑。
对系统在图表理解与多模态问答场景下的能力进行系统性评估,涵盖数据构建与结果评判两个方面:
评测数据集
采用 FinRAGBench-V 作为基础数据集,该数据集为面向多模态检索增强生成(RAG)的 benchmark。选取其中中文图表相关子集,问题类型覆盖图表信息提取、图表数值计算以及图表时效性查询。在此基础上,针对流程图、架构图等非结构化图形,人工构建补充测试样本,扩展数据覆盖范围。最终形成包含 270 条样本的评测集。
评估标准
采用基于大模型的三分量表(0–2 分)进行自动评估,其中 2 分表示回答完全正确。具体评分标准如下:
• 2 分(正确):最终答案与标准答案一致,关键事实完整且准确,不包含影响结论的错误信息。
• 1 分(部分正确):回答存在一定偏差,但整体接近正确结论,包含以下情况之一:
○ 仅覆盖部分关键事实;
○ 结论方向基本正确,但关键细节存在偏差;
○ 在非严格数值场景下,数值、时间、对象、排序或比较关系存在轻微误差;
○ 表达不够精确,无法完全确认与标准答案一致。
• 0 分(错误):回答错误、矛盾或无法判定为正确,包含以下情况之一:
○ 最终结论与标准答案不一致;
○ 关键事实错误;
○ 在严格数值场景下,数值、比例、百分比、排名、日期或数量不一致;
○ 存在编造信息或无依据推断;
○ 未回答问题或回答内容与问题无关。
当前效果
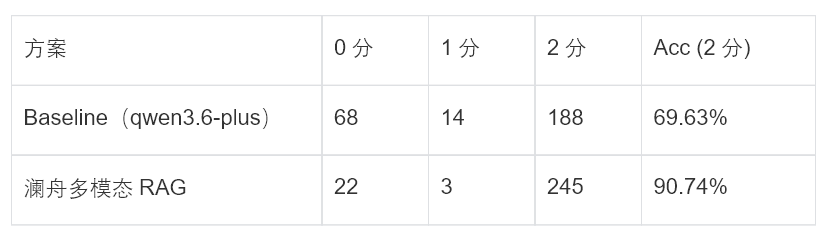
提升幅度:准确率(2 分)从 69.63% 提升至 90.74%(+21.11pp),提升幅度明显。
多模态问答技术可广泛应用于以下场景:
1. 金融研报分析
○ 自动解读图表趋势
○ 辅助投资决策
2. 企业知识库(如澜舟智库)
○ 支持图文混合问答
○ 提升知识检索准确率
3. 政策/行业报告解读
○ 自动提取关键数据
○ 生成分析结论
为直观展示多模态RAG在复杂图表场景下的能力,我们选取澜舟智库中的典型问答案例进行说明。
案例一:复杂图表趋势分析
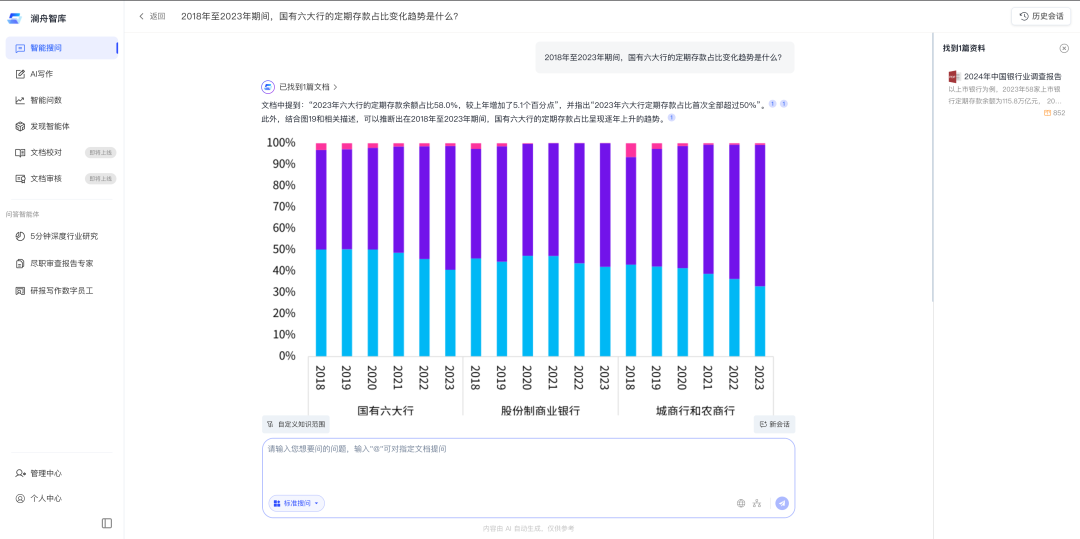
用户问题:
2018年至2023年期间,国有六大行的定期存款占比变化趋势是什么?
系统能力展示:
系统从研报中自动定位相关图表,并结合文本与图表信息进行综合分析,给出结论:
• 文本信息表明:2023年定期存款占比约为58.0%,较上年提升约7.5个百分点,且首次整体超过50%
• 图表信息进一步验证:自2018年以来,各年份占比呈持续上升趋势
系统通过融合文本结论与图表趋势,实现对数据变化的完整理解与交叉验证。
案例二:时间序列走势判断
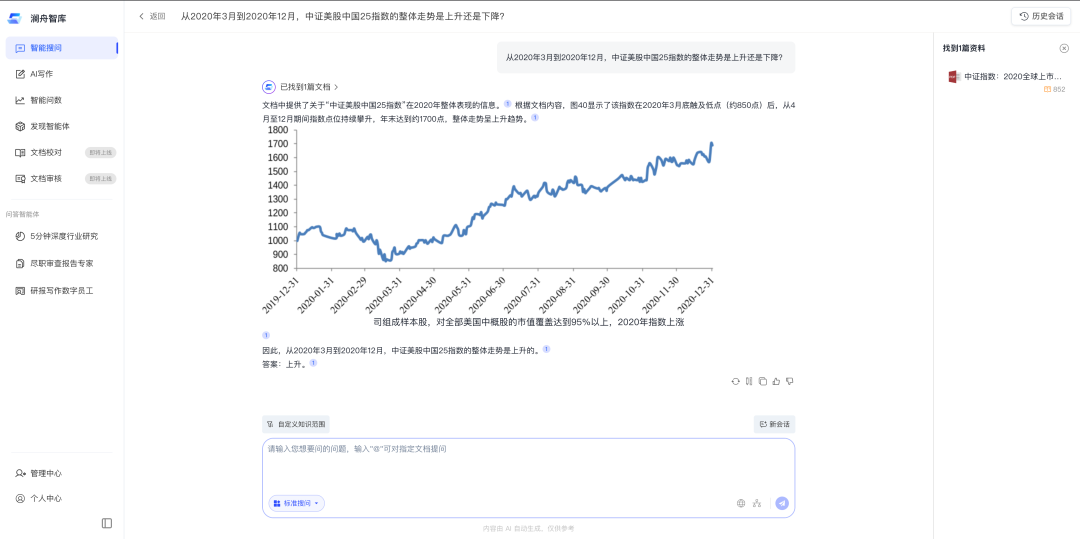
用户问题:
从2020年3月到2020年12月,中证全指指数的整体走势是上升还是下降?
系统能力展示:
系统定位到对应折线图,并分析得出:
• 指数在2020年3月底触及低点(约850点)
• 此后持续震荡上行,至年底接近1700点
• 整体趋势为明显上升
在该类问题中,模型不仅需要“看图”,还需要进行时间序列分析与趋势判断。
澜舟多模态RAG技术,通过图表解析、语义理解、跨模态检索与可执行推理等关键创新,实现了AI从“读文本”到“读图表”的能力跃迁,让AI不仅能“看见”,更能“理解”和“推理”。
未来,多模态技术将进一步向更强的结构化理解与跨模态对齐能力发展,包括更精细的图表解析、更高效的多模态检索与推理机制,以及统一的端到端模型架构,以减少人工规则与模块间误差传递,提升系统在复杂真实文档场景下的泛化能力与稳定性。
扫码即可体验
澜舟智库多模态RAG能力

往期文章推荐
”
澜舟科技官方网站
澜舟科技公众号

期待您的关注!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢