

中药-症状相互作用(HSI)预测对于理解中药治疗的多靶点机制以及实现数据驱动的精准中医至关重要。现有的计算方法主要采用图神经网络(GNN)来模拟生物网络中的中药-症状关系。然而,这些方法仅限于低阶成对关联,无法捕捉中药的高阶和间接调控效应。此外,由于标注不完整,从未观测到的中药-症状对中进行随机负抽样常常会导致假阴性结果。为了克服这些局限性,本研究提出了一种新型的超图学习框架——MHGNN,它将HSI建模为一个多重超图,整合了蛋白质-蛋白质相互作用(PPI)以及高阶的中药-蛋白质和症状-蛋白质关系。 MHGNN采用分层消息传递机制聚合多种边类型的高阶特征,并采用基于网络的负采样策略,选择人类蛋白质互作组中距离较近的草药-症状对作为负样本,以减少假阴性偏差。在两个公开的中药数据集上的综合实验表明,与13个最先进的基线模型相比,MHGNN始终表现出更优的预测性能,凸显了其在推进机制感知建模和实现精准中药方面的潜力。

论文:MHGNN: Multiplex Hypergraph Neural Networks for Predicting Herb–Symptom Interactions
单位:川大、重庆医科大、重庆中医药大学
发布日期:2026年3月
请索引第83篇论文
 |  |
顶刊预警|川大团队出手了!用“多路超图”破解中药黑箱,预测药效准确率超92%
这是一篇计算机+中医药交叉领域的硬核论文解读。
来自四川大学和重庆医科大学的团队刚刚在IEEE Transactions on Neural Networks and Learning Systems(中科院一区顶刊)上发表最新成果。
如果你正苦于生物网络建模太复杂、GNN论文创新点难找,或者实验数据不好挖,这篇推文一定要看完。
在中医(TCM)现代化研究中,有一个核心难题:“一味药为什么能治这个病?”
传统方法往往只能看到“草药-症状”这种简单的点对点关系(Pairwise),但实际上,草药是通过调节多个蛋白质靶点,形成复杂的生物网络来发挥作用的。
现有的图神经网络(GNN)很难捕捉这种“一对多”、“多对多”的高阶关系,而且训练数据中的“假阴性”(没发现的药效被当成无效数据)严重干扰模型训练。
针对这些痛点,研究团队提出了 MHGNN (Multiplex Hypergraph Neural Networks) —— 多路超图神经网络。
01 核心思想:把中药网络变成“多路超图”
传统的图(Graph)一条边只能连两个节点,但在生物学里,一个草药通常对应几十个蛋白,一个症状也由多个蛋白异常引起。
这就需要用到超图(Hypergraph)——一条边(Hyperedge)可以连接任意数量的节点。
这篇论文的精髓在于构建了一个三层复用的多路超图结构:
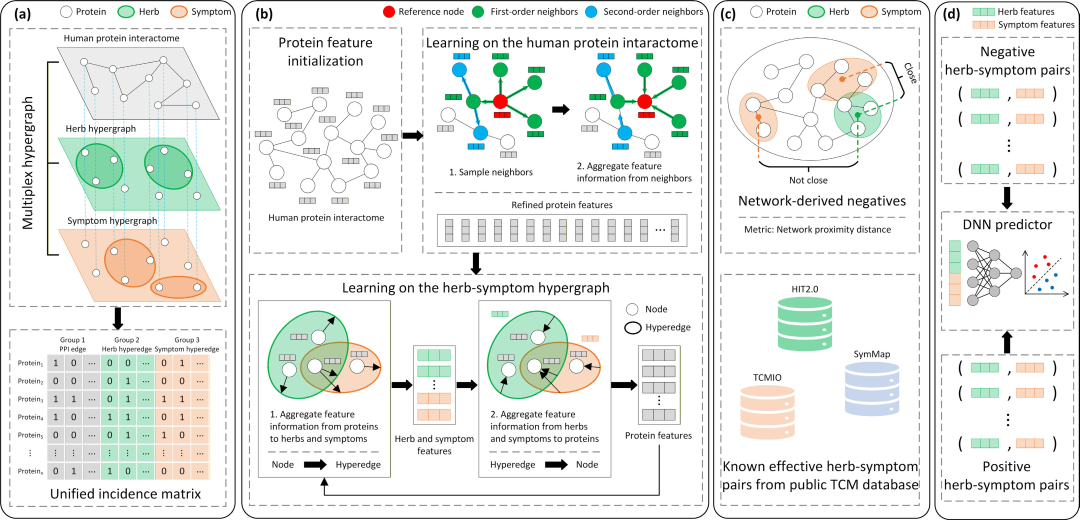
图1:MHGNN 模型架构。左侧利用DeepWalk初始化蛋白特征;中间上层利用固定邻居采样学习人类蛋白质互作组(PPI);中间下层利用双阶段卷积学习草药和症状的高阶特征;右侧展示了基于网络邻近度的负采样策略。
如图1所示,模型将人类蛋白质互作网络(PPI)、草药-蛋白关系、症状-蛋白关系融合进一个统一的框架中。
这样做的好处是,模型不仅能看到草药直接作用的蛋白,还能通过PPI网络看到间接调控的通路(Indirect Regulatory Effects)。
02 两大创新点:解决“算力浪费”和“样本噪声”
1. 分层消息传递(Hierarchical Message Passing)
为了避免大规模PPI网络带来的计算爆炸,作者设计了一种固定邻居采样策略。
对于每一个蛋白节点,不再无差别聚合所有邻居,而是采样固定数量(k=10)的邻居进行聚合。
结果:在保证信息不丢失的前提下,极大降低了计算复杂度,让模型能适应大规模的动态生物网络。
2. 基于网络邻近度的负采样(NP-based Sampling)
这是论文中最“骚”的操作。
以往训练AI,是把“未知的草药-症状对”随机当作负样本(没记录=无效)。但现实中,很多没记录是因为没被发现(False Negatives)。
作者提出:在PPI网络上距离越远的草药和症状,越不可能有相互作用。
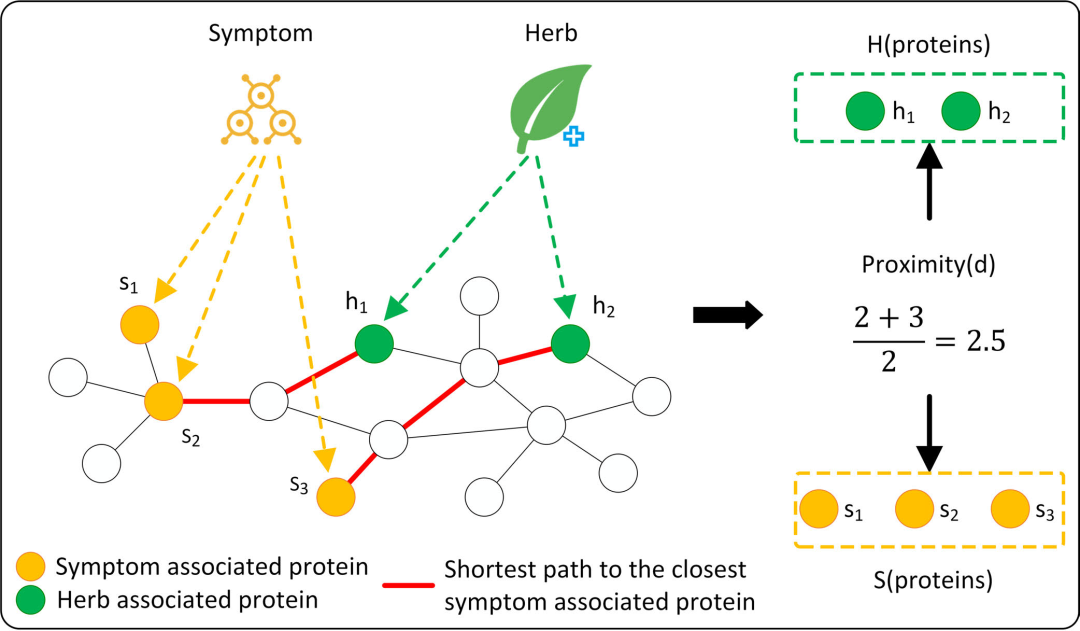
图2:左图为随机选择负样本,容易混入潜在的真阳性;右图为基于NP距离选择,优先选择在网络上距离较远的配对,有效减少假阴性。
如图2所示,模型通过计算草药相关蛋白集和症状相关蛋白集之间的最短路径距离,专门挑选那些“八竿子打不着”的配对作为负样本。实验证明,这招大幅提升了模型的判别能力。
03 实验数据:碾压13个SOTA基线
为了验证效果,团队在两个公开的中药数据库(HIT 和 TCMIO)上进行了测试。
数据集详情如下:
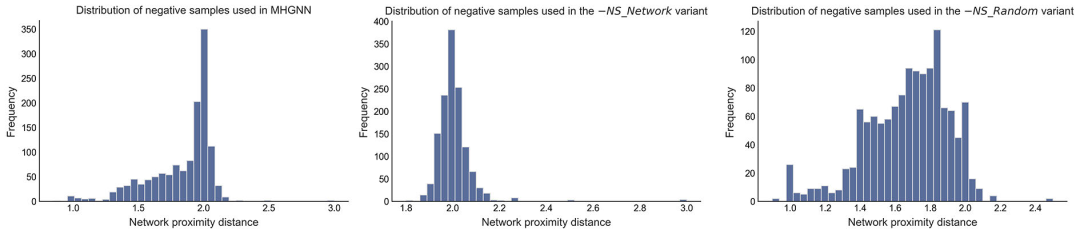
表1:数据集包含数百种草药、数万种蛋白以及数万条关联关系。
对比结果堪称“屠杀”:
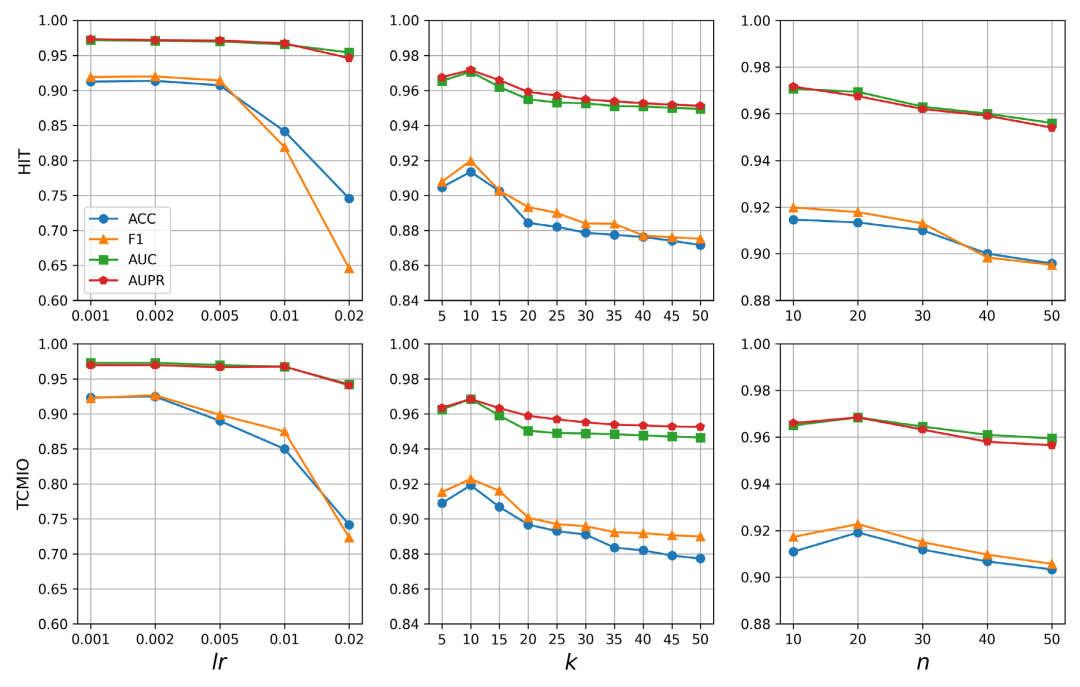
表2:在两个数据集上,MHGNN 在 ACC、F1、AUC、AUPR 四项指标上全面超越13种现有模型。
从表2可以看出,MHGNN 的 AUC 达到了 0.973(近乎完美),比之前最好的模型(KHGNN)提升了1%以上。
对于做生信和AI交叉的同学来说,这种提升幅度已经非常显著了。
04 案例解读:为什么“川贝”能治“咳嗽”?
论文最精彩的部分是可解释性分析。AI不仅预测准,还得知道为啥准。
作者拿“川贝(Fritillaria unibractata)”和“咳嗽(Coughing)”做了案例分析。
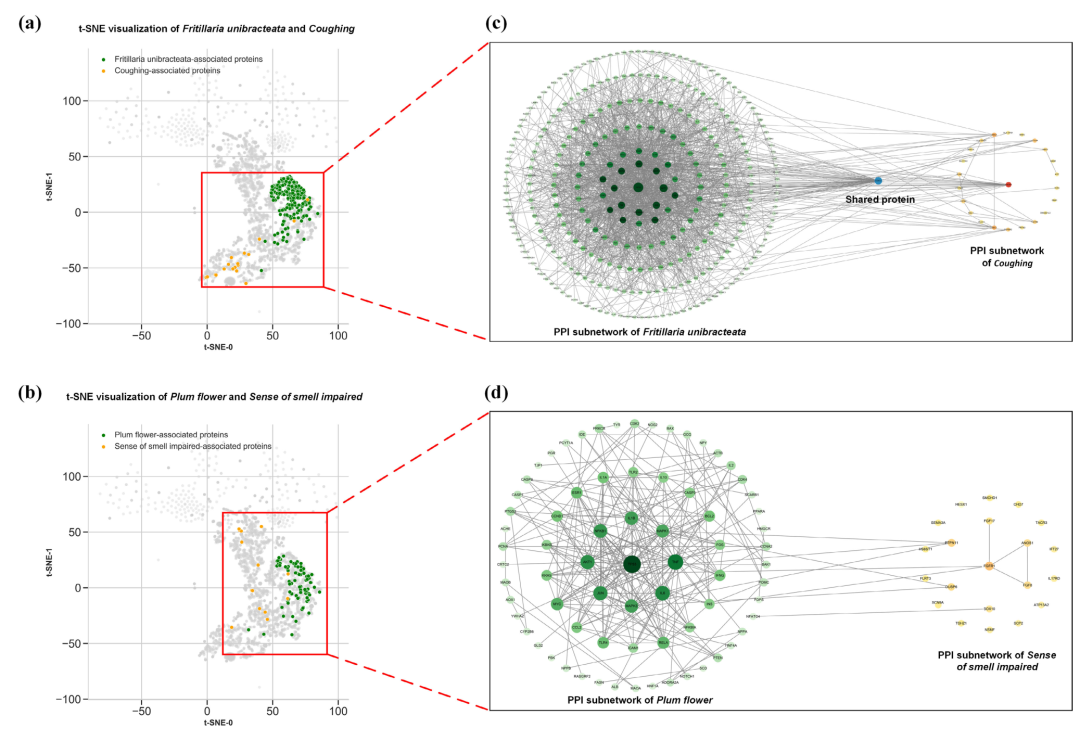
图7:(a)(b) 是蛋白在隐空间的聚类;(c)(d) 是实际的PPI网络。
如图7所示:
聚类紧密度:川贝相关的蛋白和咳嗽相关的蛋白在特征空间中聚得非常近(图7a),说明它们高度相关。
通路验证:模型发现两者共享关键蛋白 STAT3。药理实验证实,川贝中的生物碱正是通过抑制 STAT3 通路来缓解气道炎症的。
这意味着,MHGNN 成功捕捉到了中药背后的分子机制,而不仅仅是拟合数据。
此外,模型还能模拟中医的“证型”。比如“肺热证”包含咳嗽、发热、痰多等症状,MHGNN 能将这些症状映射到同一个蛋白集群中,揭示它们的共同病理基础(见图8)。
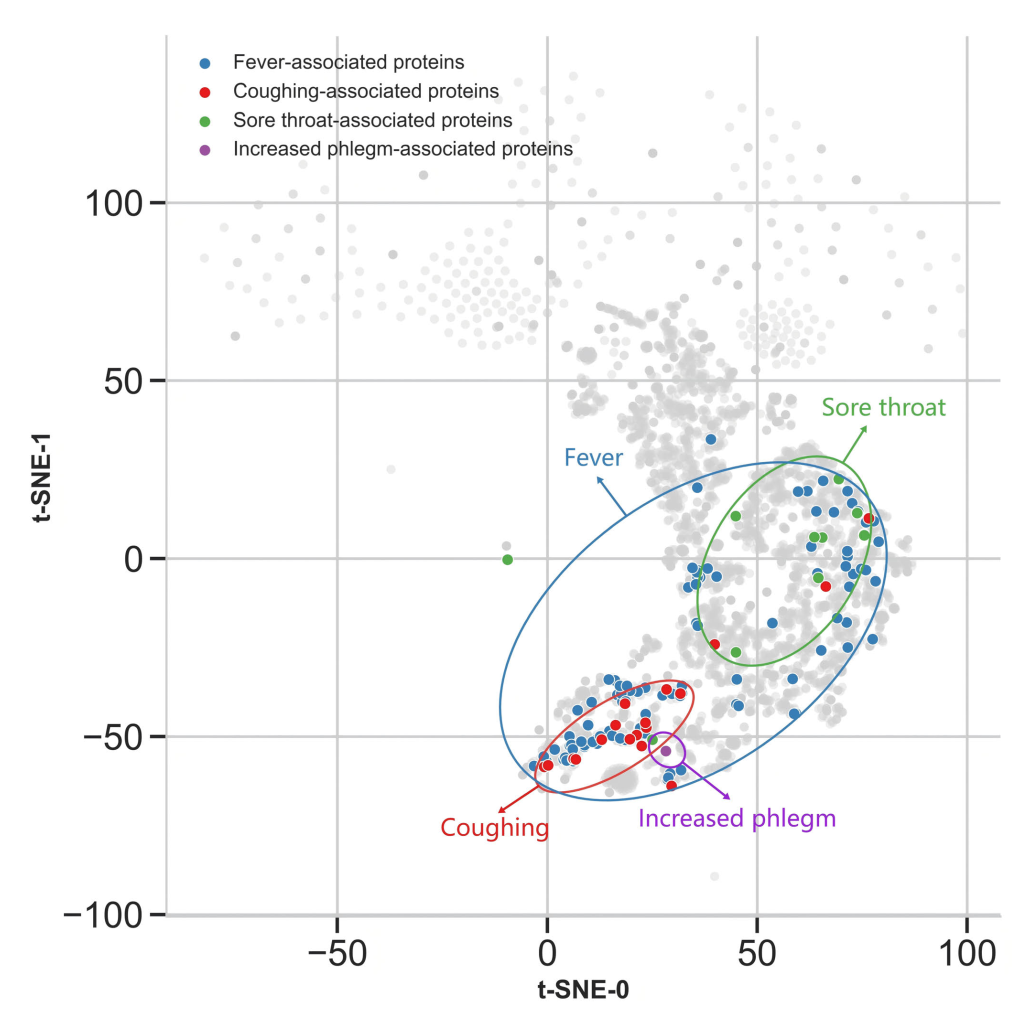
图8:肺热证下的四个症状(咳嗽、发热、咽痛、痰多)对应的蛋白在特征空间中形成了紧密的簇,验证了中医“同证异病”的理论基础。
05 写在最后:给科研狗的启发
这篇论文给我们做AI+Bio的同学们几点重要启示:
数据结构很重要:当你的数据存在“多对多”关系时,别死磕普通GNN,试试超图(Hypergraph),创新点瞬间就出来了。
负采样是突破口:在生物医药领域,数据标注极不完整。基于先验知识(如PPI距离)设计采样策略,往往比堆砌模型层数更有效。
可解释性是王道:顶刊越来越看重模型能不能讲清楚“为什么”。结合 t-SNE 可视化和通路富集分析,能让你的论文档次提升一个Level。
👇 你怎么看?你认为AI能完全破解中医药的黑箱吗?欢迎在评论区聊聊。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢