
DRUGONE
视网膜疾病导致的视力损伤仍然是全球范围内的重要致残原因。光学相干断层成像(OCT)作为一种三维无创成像技术,能够精细刻画视网膜微结构,在临床诊断中具有核心地位。然而,现有计算方法往往忽略OCT数据的三维结构信息,同时难以整合其他眼底影像模态。
针对这些挑战,研究人员提出了OCTCube-M,一个三维多模态基础模型框架,用于联合分析3D OCT与二维眼底影像(如红外和自发荧光图像)。该框架通过多模态对比学习方法,实现不同模态之间的对齐与融合。在此基础上,研究人员构建了三种模型:单模态的OCTCube、双模态的OCTCube-IR以及三模态的OCTCube-EF。实验表明,该方法在多种视网膜疾病预测、跨设备泛化以及临床试验任务中均取得领先性能,并在地理性萎缩进展预测中显著提升准确性。整体而言,该研究展示了三维多模态基础模型在医学影像分析中的巨大潜力。

视网膜疾病如青光眼、糖尿病性黄斑水肿以及年龄相关性黄斑变性,是导致视力损失的重要原因。随着成像技术的发展,多种眼底影像方法被用于临床评估,其中OCT因其三维结构解析能力而成为核心工具。
然而,当前机器学习方法在分析OCT数据时存在两个关键问题。首先,大多数方法基于二维切片进行分析,忽略了三维结构中的空间连续性与组织关联。其次,临床实践中通常需要结合多种影像模态进行综合判断,但现有模型难以实现跨模态融合。
与此同时,基础模型在计算机视觉和医学影像领域取得了显著进展,通过大规模自监督学习能够学习通用表示。然而,大多数现有模型仍集中于二维图像,缺乏对三维医学数据的有效建模能力。
因此,研究人员提出,需要一种能够同时建模三维结构并融合多模态信息的基础模型框架,以提升医学影像分析的准确性与泛化能力。
方法
OCTCube-M框架由两个核心组成部分构成:三维OCT基础模型OCTCube以及多模态对比学习模块COEP。
在OCTCube中,研究人员采用三维掩码自编码器(MAE)进行预训练。具体而言,将OCT体数据划分为多个小立方块,并随机遮蔽大部分区域,通过编码–解码结构重建缺失部分,从而学习高质量三维表示。这一过程使模型能够捕捉视网膜在空间上的整体结构特征。
在多模态融合方面,COEP通过对比学习将不同模态映射到统一嵌入空间。模型鼓励来自同一只眼的不同模态图像在嵌入空间中靠近,而来自不同样本的图像则被拉远,从而实现跨模态对齐。
在此基础上,研究人员分别构建了单模态、双模态和三模态模型,实现从三维结构建模到多模态融合的统一框架。
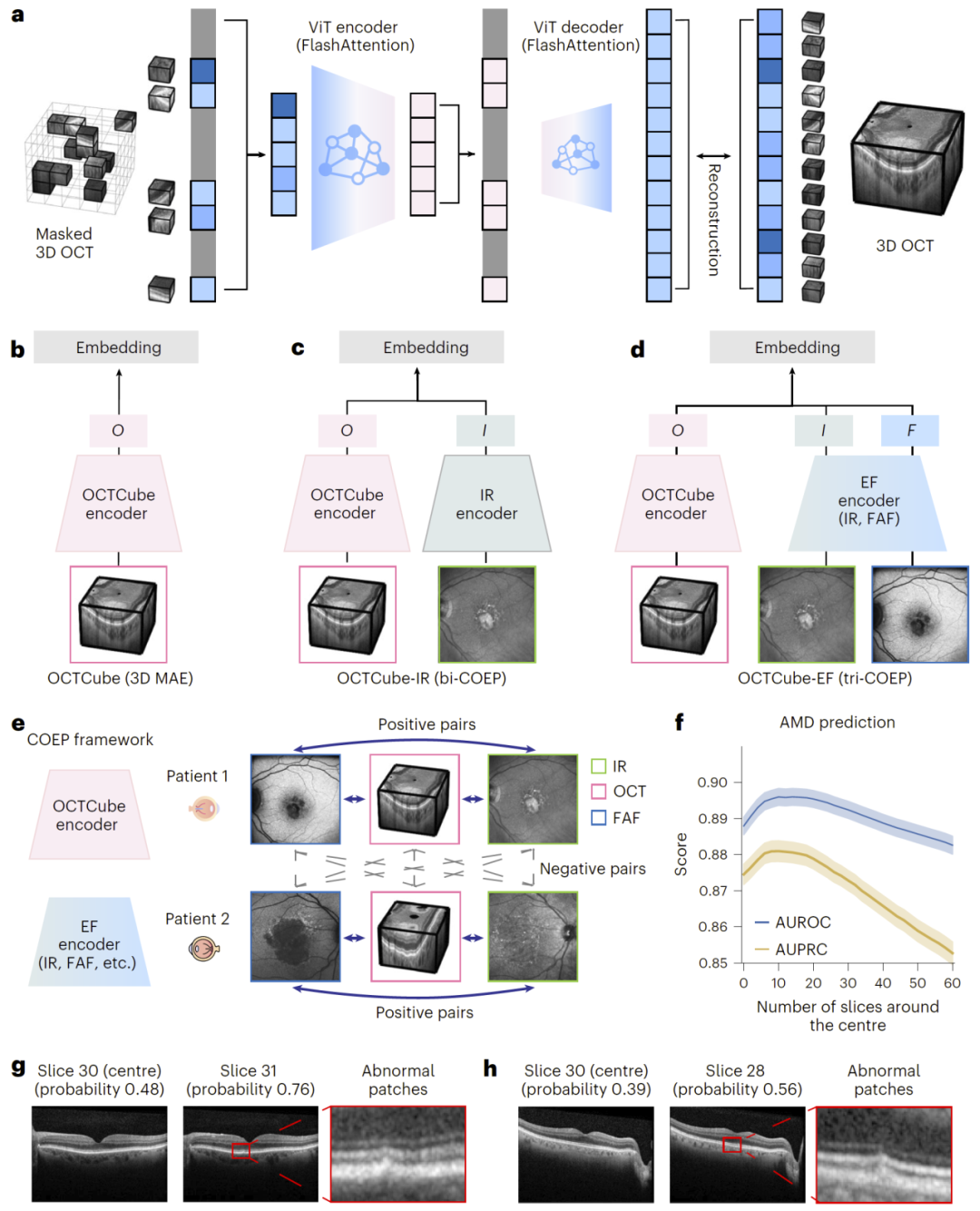
图1:OCTCube-M整体架构与多模态框架。
结果
研究首先展示了模型整体结构,包括3D MAE预训练流程以及多模态对齐机制。结果表明,该框架能够在统一表示空间中整合不同影像模态,同时保留三维结构信息。
三维建模相对于二维方法的优势
研究人员通过分析不同切片之间的相似性发现,OCT体数据中相邻切片具有高度相关性,这意味着仅依赖单一切片会丢失关键信息。
实验进一步表明,在疾病预测任务中,结合多个切片可以显著提升性能,而简单的二维模型难以有效利用这些信息。相比之下,OCTCube能够在三维空间中整合这些特征,从而实现更准确的预测。
案例分析显示,一些关键病变仅在非中心切片中可见,传统方法容易漏检,而三维模型能够捕捉这些信号。
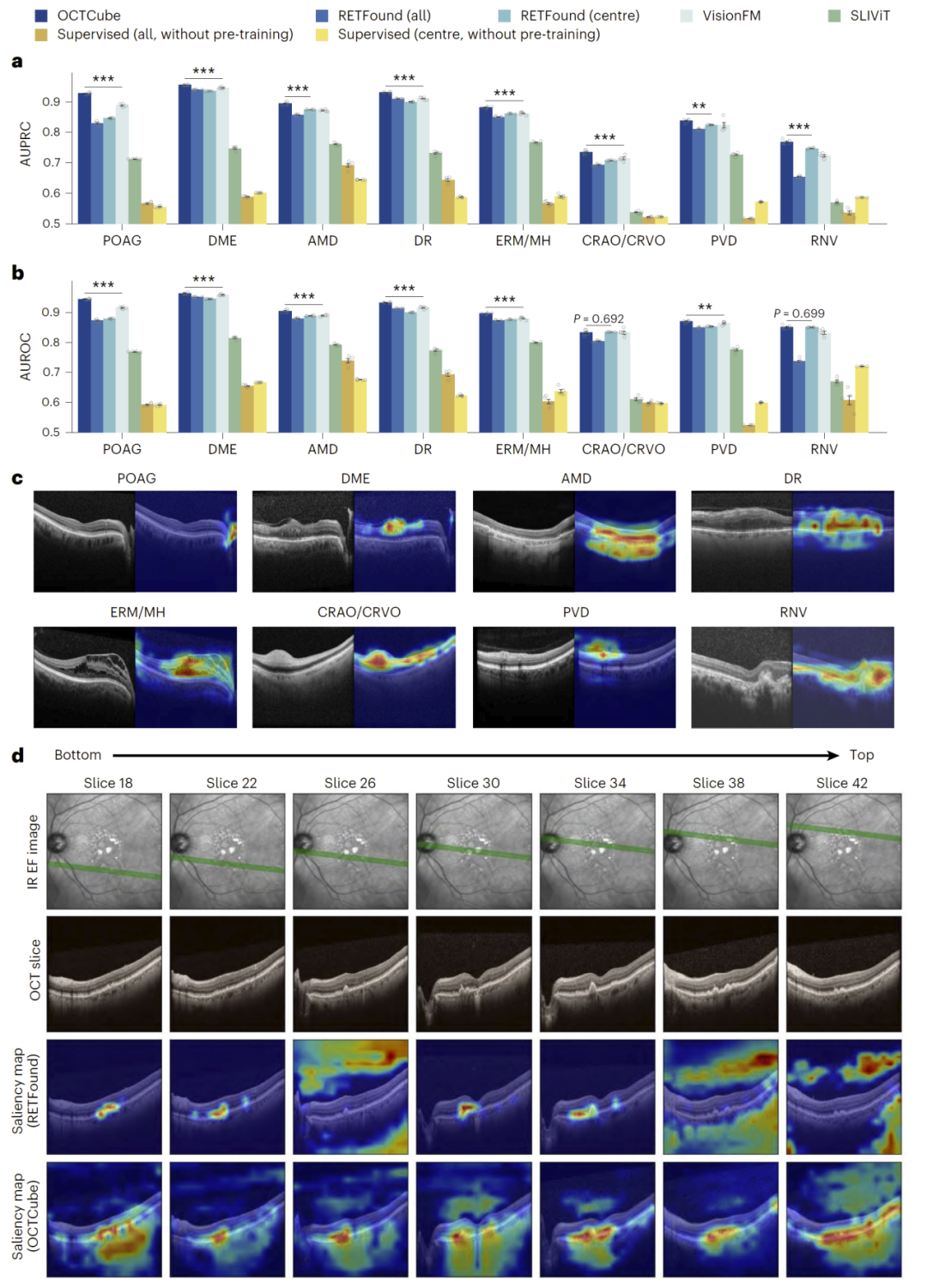
图2:3D建模优势分析。
视网膜疾病预测能力
在八种视网膜疾病预测任务中,OCTCube显著优于传统监督模型和二维基础模型,在AUPRC和AUROC指标上均取得提升。
特别是在青光眼等需要全局结构信息的任务中,性能提升更加明显,说明三维建模能够捕捉跨区域结构变化。
可视化分析进一步表明,模型能够准确定位病变区域,并在不同切片间保持一致性,这体现了其对三维结构的理解能力。
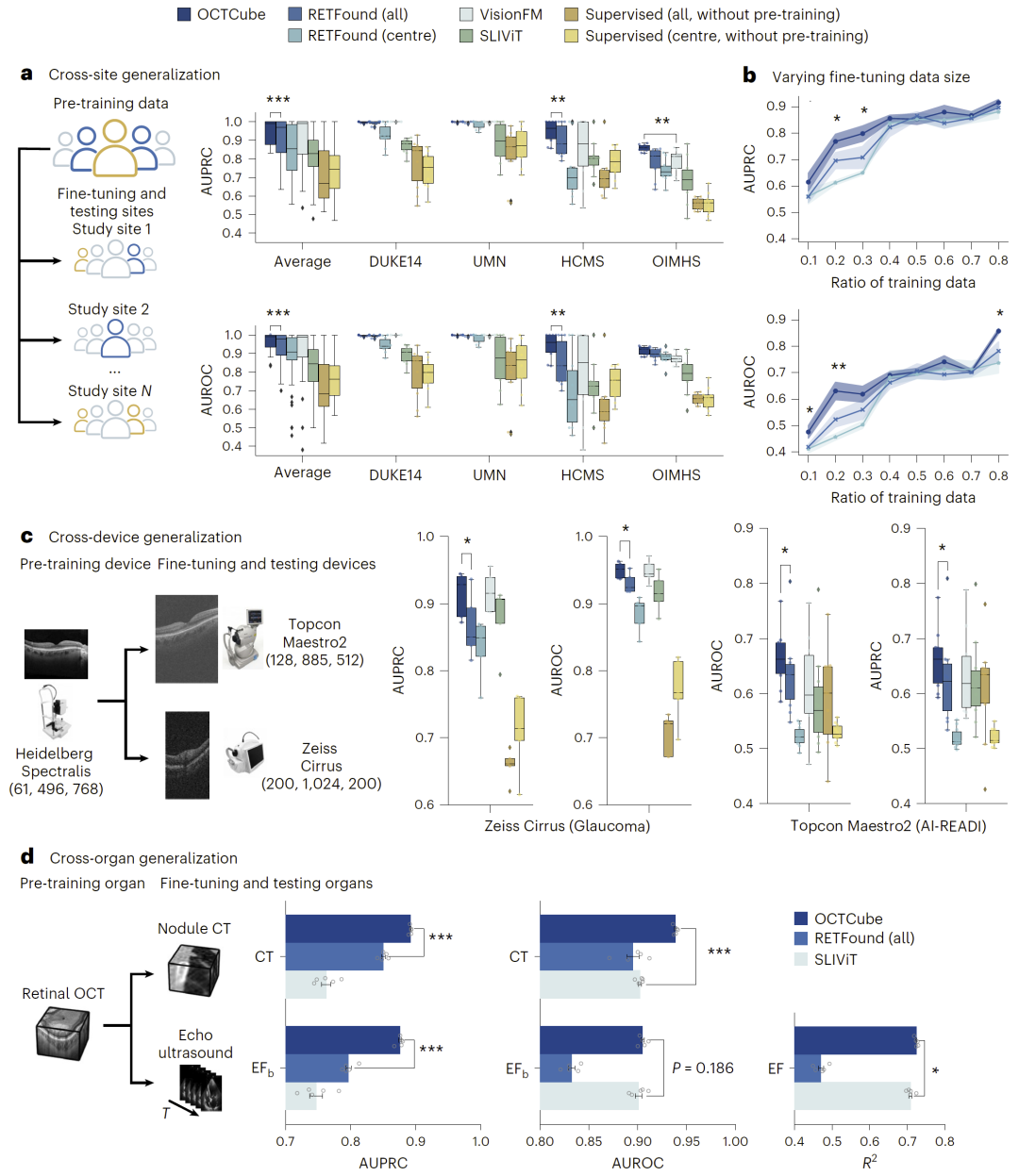
图3:多疾病预测性能对比。
跨数据集、设备与器官的泛化能力
在跨数据集和跨设备测试中,OCTCube表现出显著优势,即使训练与测试设备不同,模型仍能保持高性能。这说明其学习到的表示具有较强的通用性。
更进一步,在跨器官任务中,模型能够迁移至肺部CT和心脏超声数据,实现良好的性能表现。这一结果表明,该模型不仅适用于眼底影像,还具备跨医学影像领域的潜力。
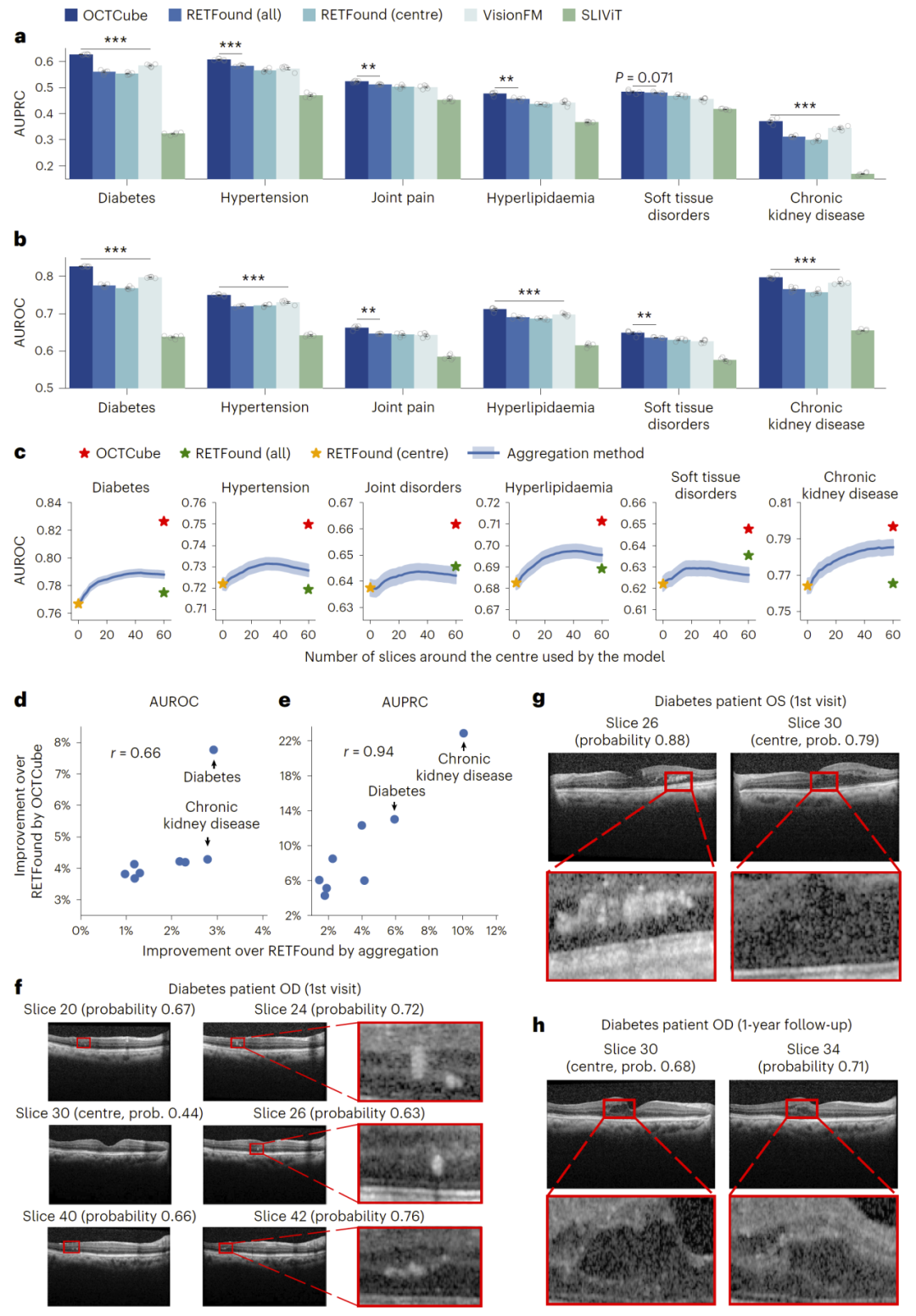
图4:泛化能力评估。
系统性疾病预测能力
研究人员进一步探索了利用OCT预测全身性疾病的能力。结果表明,模型能够从视网膜结构中推断如糖尿病、高血压等疾病状态。
案例分析显示,即使中心切片未显示明显病变,模型仍能通过其他切片识别关键特征,实现更早期的疾病检测。这一能力对于临床筛查具有重要意义。
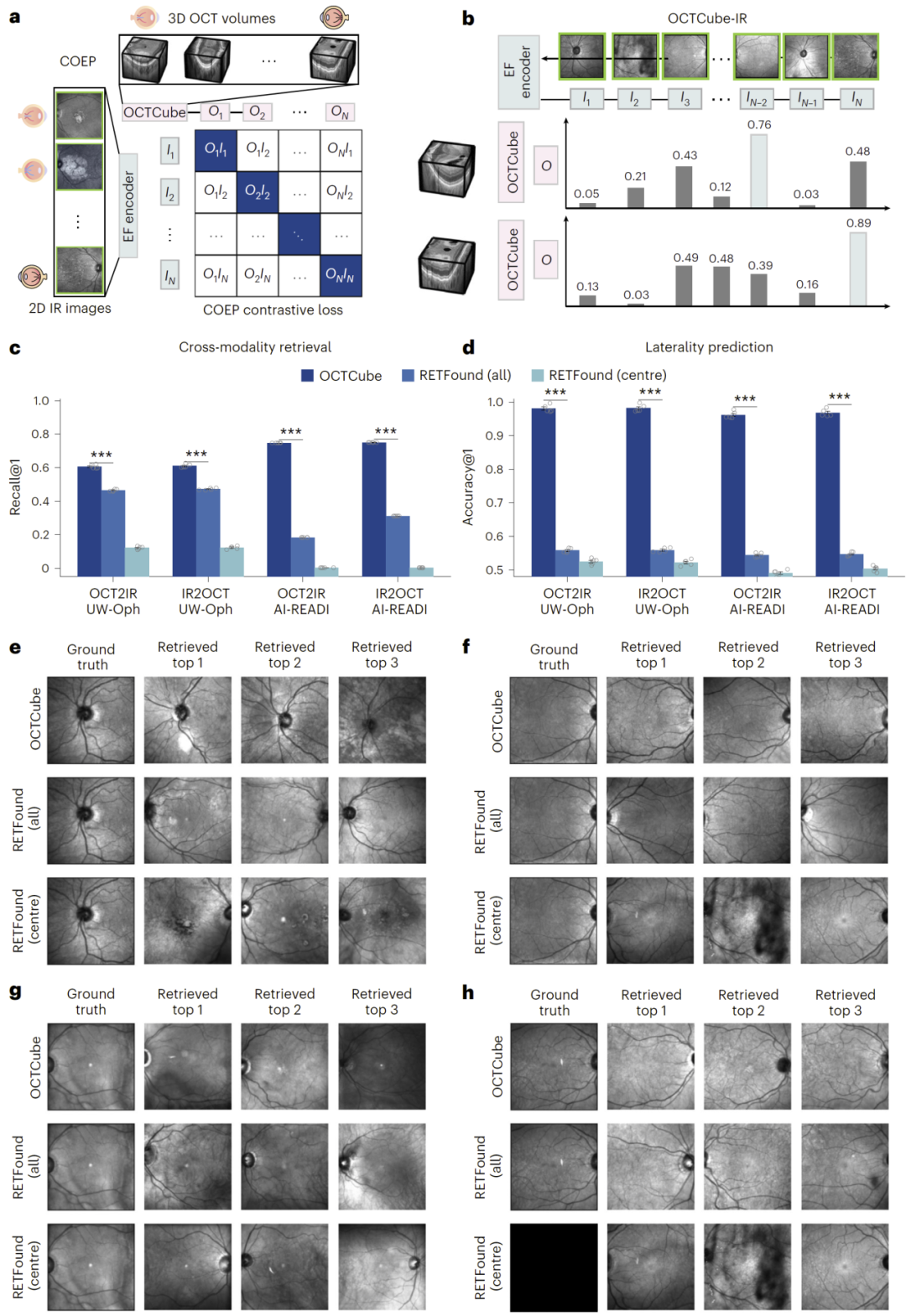
图5:系统性疾病预测结果。
多模态融合与临床应用
在多模态模型中,OCTCube-IR能够实现OCT与红外图像之间的检索与对齐,而OCTCube-EF进一步整合三种模态,在地理性萎缩进展预测中显著提升性能。
在多中心临床试验数据中,该模型能够更准确预测疾病进展,并提高统计分析的精度,从而在临床研究中具有重要应用价值。
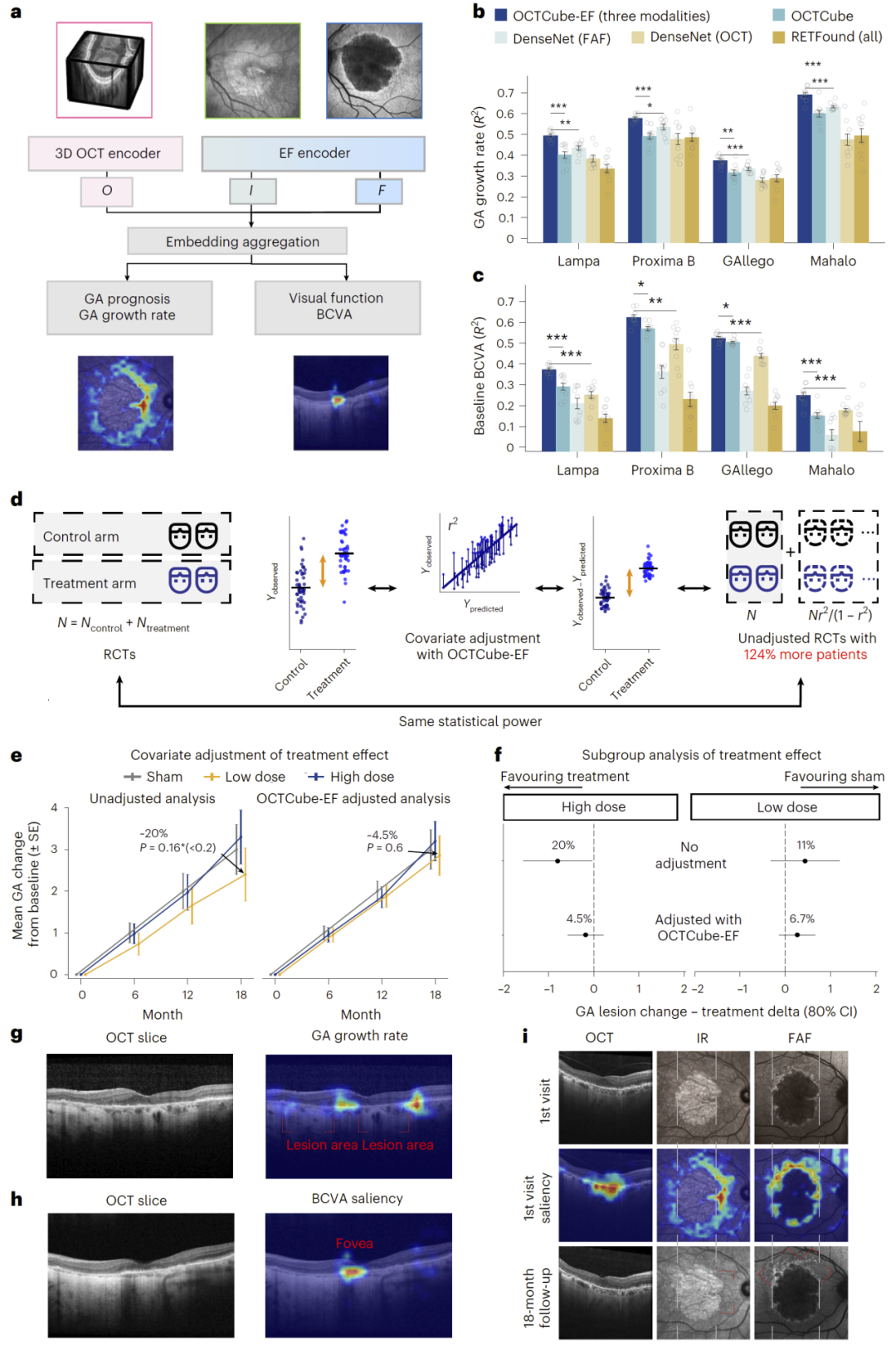
图6:多模态融合与临床试验应用。
讨论
该研究提出的OCTCube-M框架标志着医学影像分析从二维模型向三维多模态基础模型的重要转变。通过结合三维结构建模与多模态对齐,该方法显著提升了模型性能与泛化能力。
其核心优势在于能够直接利用原始三维数据,避免信息丢失,同时通过对比学习实现不同模态之间的统一表示。这种设计不仅提升了疾病预测能力,还拓展了模型在临床试验和系统性疾病分析中的应用。
此外,该框架展示了跨器官迁移能力,表明基础模型有望成为统一医学影像分析的通用平台。
然而,该方法仍面临一定挑战,例如对大规模数据的依赖以及多模态数据获取的复杂性。未来,通过引入更多模态信息和优化训练策略,有望进一步提升模型性能。
总体而言,该研究为构建“通用医学影像基础模型”提供了重要路径,并推动AI在临床诊断与精准医疗中的应用迈向新阶段。
整理 | DrugOne团队
参考资料
Liu, Z., Xu, H., Woicik, A. et al. A three-dimensional multi-modal foundation model for optical coherence tomography. Nat. Biomed. Eng (2026).
https://doi.org/10.1038/s41551-026-01662-2

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢