

由多层超材料构成的片上计算元系统有望成为下一代计算硬件,具备光速处理能力和低功耗,但目前的设计范式限制了其发展。迄今为止,无论是数值方法还是解析方法,都无法在设计过程中兼顾效率和精度。为了解决这一问题,我们提出了一种受物理启发的深度学习架构——电磁神经网络(EMNN),以实现高效、可靠且灵活的逆向设计范式。EMNN 由两部分组成:EMNN Netlet 作为局部电磁场求解器;Huygens-Fresnel Stitch 用于连接局部预测结果。它能够基于任意变化和非固定尺寸结构的输入场,直接、快速、准确地预测全波场。借助 EMNN,我们设计了能够执行手写数字识别和语音命令识别的计算元系统。与解析模型相比,EMNN 的设计速度提高了 17,000 倍,与数值模型相比,建模误差降低了两个数量级。通过将深度学习技术与基本物理原理相结合,EMNN 展现出超越传统网络的卓越可解释性和泛化能力。此外,它创新了一种兼顾高效性和高保真的设计范式。更重要的是,这种灵活的范式可应用于前所未有的、极具挑战性的大规模、高自由度、功能复杂的片上光学衍射网络器件的设计,从而进一步推动计算元系统的发展。
论文:Reliable, efficient, and scalable photonic inverse design empowered by physics-inspired deep learning
单位:清华大学
发布日期:2025年1月
请索引第84篇论文
 |  |
清华团队放大招:AI+光子学“王炸”组合,把逆向设计速度飙升17000倍!
各位科研打工人,你是否也曾在“慢如蜗牛”的数值仿真中怀疑人生?
当你为了优化一个微小的光子器件,让FDTD(时域有限差分法)转得服务器冒烟,等出结果已是三天后……这种痛,做集成光子学和超构表面的同学都懂。
最近,一篇发表在《Nanophotonics》(中科院一区顶刊)上的论文彻底打破了这一僵局。
来自清华大学等团队的研究人员,创新性地将“物理启发的深度学习”引入光子逆向设计,提出了一套名为 EMNN(Electro-Magnetic Neural Network,电磁神经网络) 的全新架构。
简单来说:它不仅把设计速度提高了17000倍,还将建模误差降低了两个数量级!
这项技术到底有何过人之处?它又是如何解决困扰学界已久的“效率与精度不可兼得”的痛点?今天,我们就来为大家硬核拆解这篇佳作,看看顶尖团队是如何做交叉创新的。
01 科研痛点:光子逆向设计的“鱼和熊掌”
在深入了解EMNN之前,我们先来看看为什么光子器件的逆向设计这么难?
随着ChatGPT等大模型对算力需求的爆炸式增长,传统的电子计算逐渐触及瓶颈。于是,人们将目光投向了光计算(Optical Computing)——利用光子代替电子进行计算,具备光速处理、低功耗和高并行度的天然优势。
其中,由多层超材料(Metamaterials)构成的片上计算超系统(Computing Metasystems),更是被视为下一代计算硬件的“天选之子”。然而,要设计出这样高集成度、多层级的复杂光子芯片,传统的设计范式集体翻了车:
数值方法(如FDTD、FEM):精度极高,堪称电磁仿真界的“金标准”。但它的计算成本极其昂贵,内存消耗大、耗时极长。面对大规模、高自由度的多层超构表面优化,简直就是“杀鸡用牛刀”,效率低到让人绝望。
解析方法(如角谱法 ASM):速度很快,但它是基于物理近似简化得来的。在处理复杂的多层耦合时,误差会逐层累积,导致最终设计出来的芯片在实际流片后性能大打折扣。
传统纯数据驱动的深度学习:虽然能加速,但本质上是个“黑盒”。缺乏物理可解释性,泛化能力差,稍微改动一下器件尺寸就得重新训练,难以应对真实场景中的变量。
一句话总结:慢的太慢,快的太糙,聪明的又太死板。
面对这个死局,清华团队给出了一个极具洞察力的解法:为什么不把物理定律直接“塞”进神经网络里呢?
02 核心创新:揭秘 EMNN 的双引擎架构
这篇论文的灵魂,就在于作者提出的 EMNN(电磁神经网络)。它不是凭空生成的AI,而是一个“懂物理的AI”。整个架构由两个核心部分组成:EMNN Netlet(局部求解器)和 Huygens-Fresnel Stitch(全局拼接策略)。
让我们一层一层剥开它的神秘面纱。
创新点一:EMNN Netlet —— “懂物理”的局部波前预测器
传统的神经网络处理电磁波时,往往把电场和磁场的实部和虚部分开计算。但作者深知,电磁波是复数形式的矢量场,其传播有着严格的物理规律。
如图1(b)和(c)所示,EMNN Netlet 采用了一种极为精巧的双输入物理启发架构:
输入1:结构参数(如超表面的几何形状、折射率),通过网络的非线性变换提取物理特征。
输入2:入射波前,通过复数权重层进行处理。
输出:预测的出射波前。
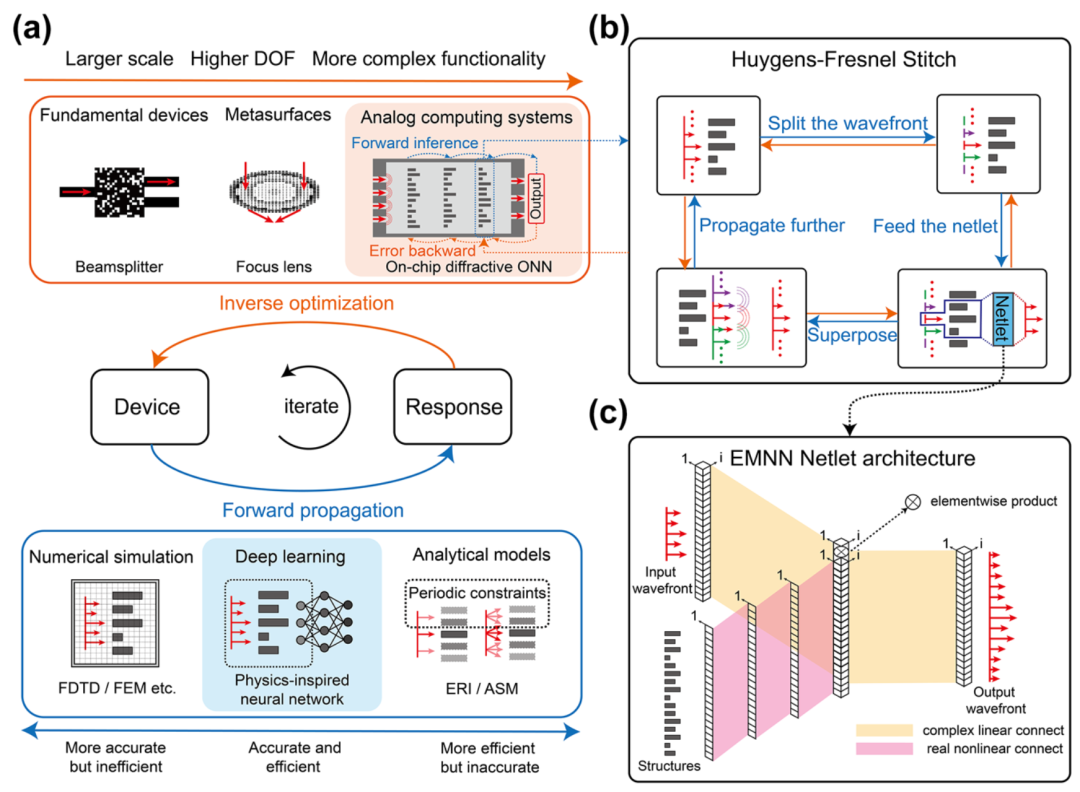
图1:传统逆向设计(a)面临精度与效率的权衡;而EMNN(b, c)通过物理启发的Netlet和拼接策略,实现了高精度、高效率且可扩展的设计。
更绝的是,作者在训练这个网络时,没有盲目依赖海量数据,而是将物理约束(如麦克斯韦方程组的线性响应特性)编入了损失函数中(类似于PINN物理信息神经网络的理念)。
这就好比你在教一个学生学习物理,不仅告诉他答案,还逼着他理解了牛顿定律。结果就是,这个网络不仅预测精准,而且泛化能力极强。
如图2(e)和(f)所示,在面对复杂的波前调制任务时,传统的非物理启发网络已经开始“胡言乱语”,而EMNN的预测结果与严苛的FDTD仿真几乎完全重合,完美拿捏了振幅和相位的变化。
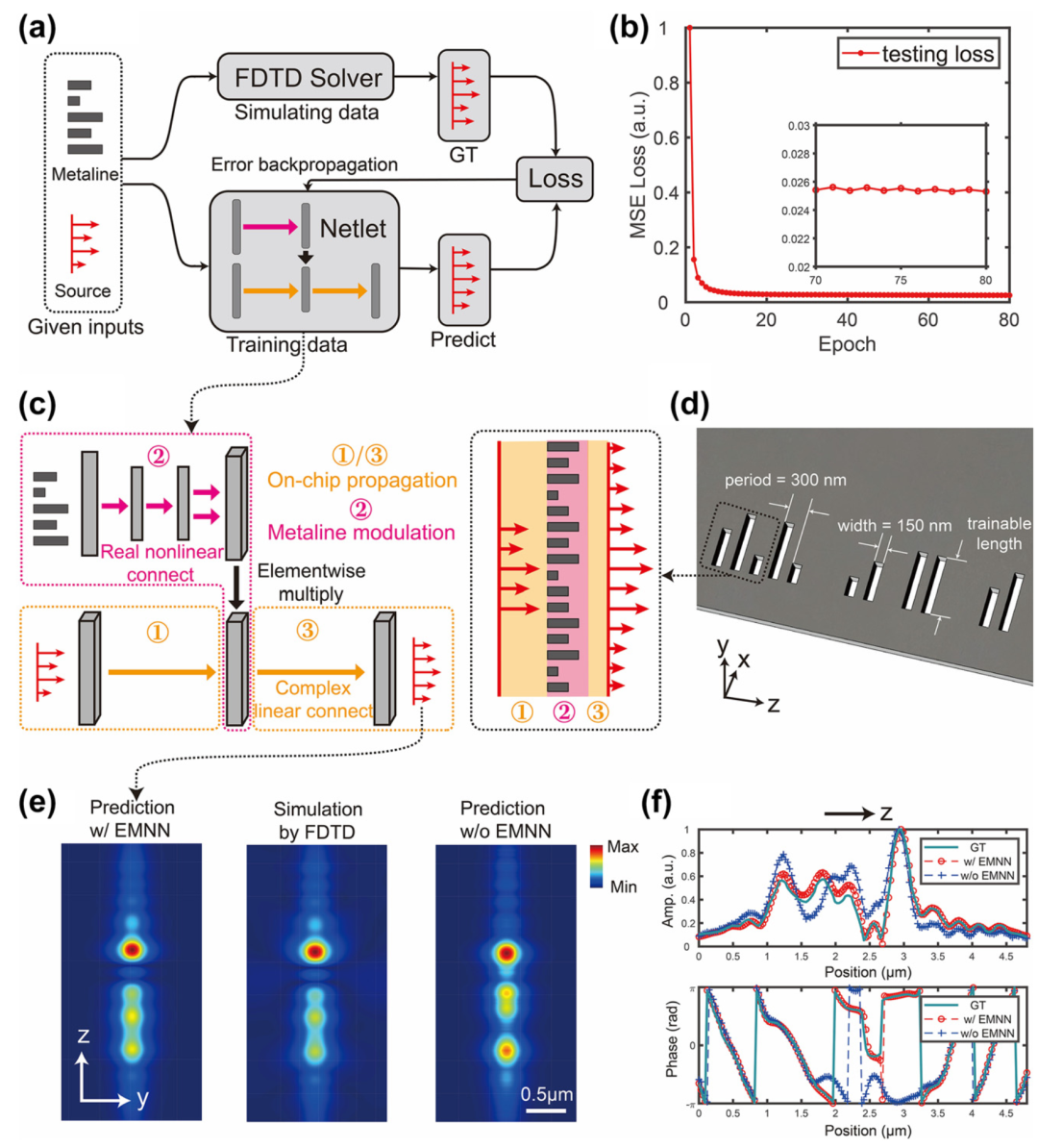
图2:(a)Netlet结构;(b)训练收敛曲线;(e)波前轮廓对比;(f)振幅与相位的量化对比。EMNN(蓝线)几乎与FDTD真值(红线)完全重合。
创新点二:Huygens-Fresnel Stitch —— 打破尺寸限制的“任意门”
前面提到,Netlet 只能处理宽度为 0.9 μm 的局部区域。但实际的光子芯片动辄几百微米,难道要把网络扩大几千倍重新训练吗?
作者在这里展现了极其深厚的物理直觉。他们想到了光学中的惠更斯-菲涅耳原理(Huygens-Fresnel Principle):波前上的每一个点,都可以看作是一个新的次级球面波的源。
于是,他们发明了 Huygens-Fresnel Stitch 拼接算法:
把实际的大尺寸波前切成许多个 0.9 μm 的小块(必要时补零)。
把每个小块的波前和对应的结构参数送入训练好的 EMNN Netlet,得到局部的输出波前。
把这些局部输出看作是次级波源,按照物理规律进行相干叠加。
最终,完美的全局波前 reconstruction(重建)就完成了!
这个策略简直是神来之笔! 它意味着 EMNN 现在可以处理任意尺寸、任意输入波前变化的器件,而完全不需要重新训练网络。这直接解决了AI在光子学设计中最大的痛点——“缺乏灵活性”。
03 硬核实测:17000倍的飞跃,误差暴降两个数量级
光说不练假把式。为了验证EMNN的战斗力,作者把它拉出来和当前的各路豪杰进行了一场“神仙打架”式的对比。
如表1所示,这场对决的参赛选手包括:
FDTD:精度天花板,但速度极慢。
ASM(角谱法):常用的解析模型,速度快但精度差。
FCNN / VAE / GAN:传统深度学习模型。
擂台赛结果(见表1):
EMNN 不仅在准确率(Accuracy)上以压倒性优势击败了所有传统深度学习模型,更在速度上实现了惊世骇俗的突破——比解析模型(ASM)快 17,000 倍! 同时,相比高精度的数值模型(FDTD),其建模误差足足降低了两个数量级。
这是什么概念?
原来需要用超级计算机算上一个星期的复杂光子芯片设计,现在用 EMNN,几秒钟就能搞定,而且设计出来的结构在实际加工后几乎没有任何性能衰减!
04 实战演练:从手写数字到语音指令的精准识别
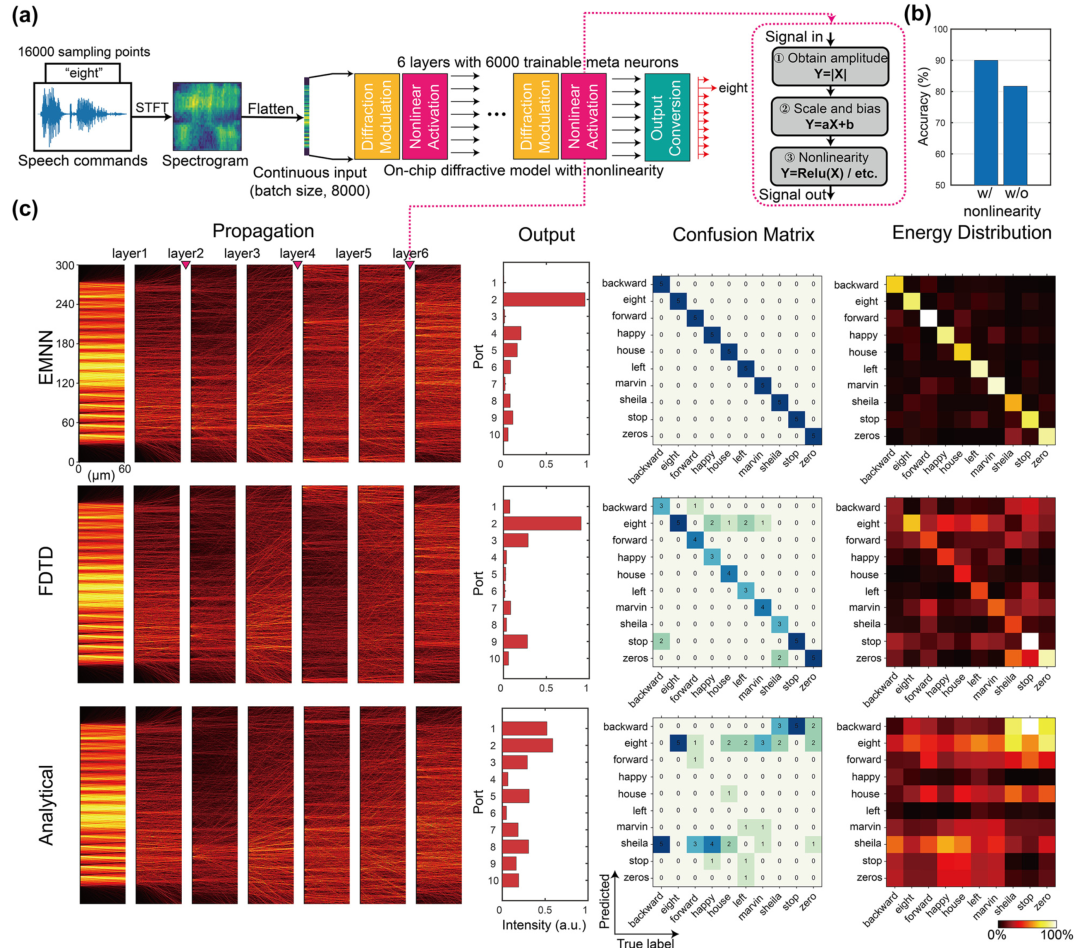
为了进一步证明这套架构的实用性,作者用 EMNN 逆向设计了两款具有不同复杂度的片上光计算系统,直接拿现实任务做测试。
战绩一:手写数字识别(线性系统)
MNIST 手写数字识别是AI界的“Hello World”。
作者设计了一个包含三层超表面的线性光学神经网络(ONN),将 16 个波导输入的信号通过 300 μm 宽的网络进行传播,最终在 10 个输出端口检测光强来进行分类。
如图3所示,利用 EMNN 作为正向代理模型进行梯度优化,最终得到的能量矩阵与FDTD真值高度吻合。这意味着,用 EMNN 设计的线性光芯片,其计算精度直逼理论极限。
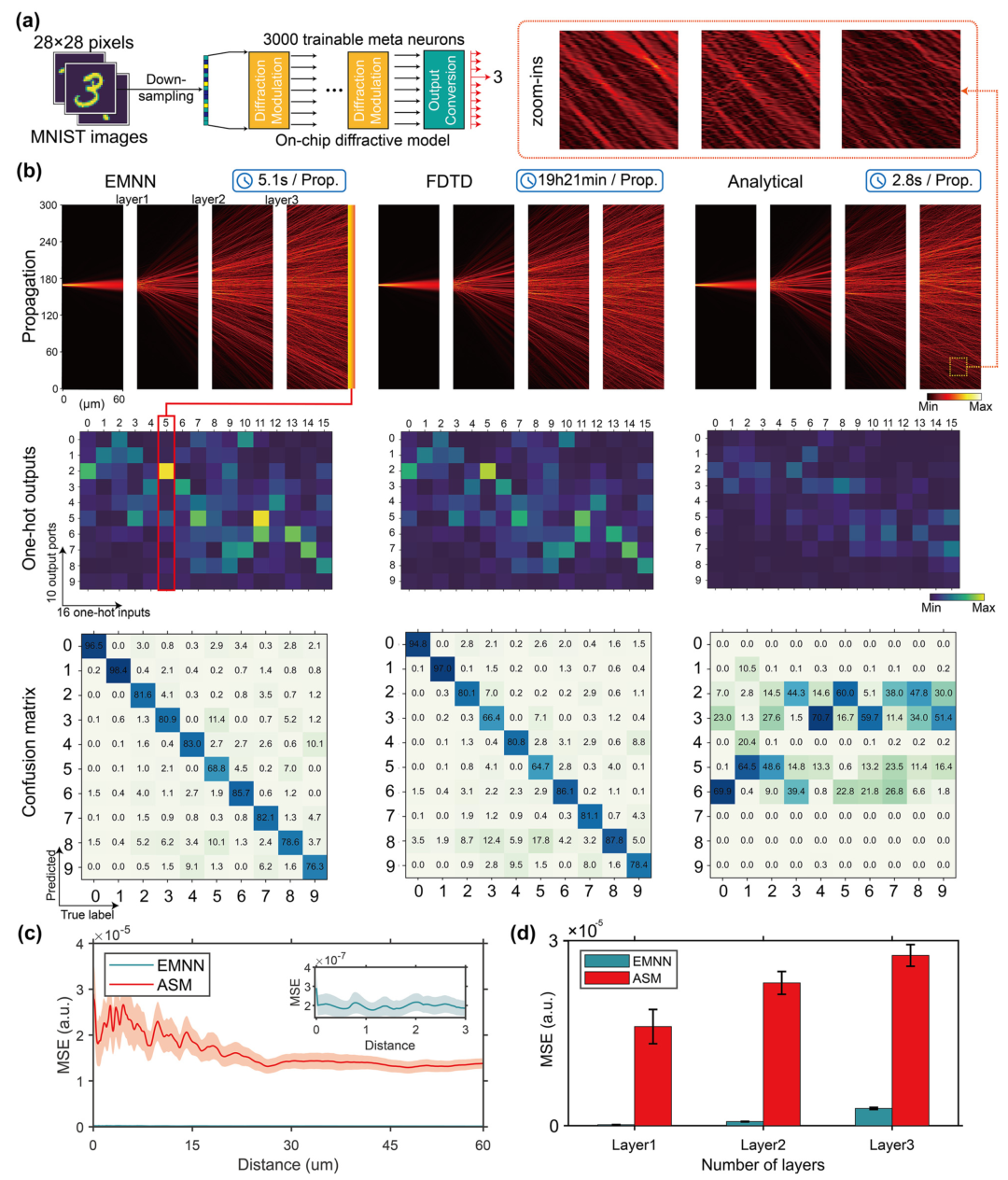
图3:(a) 网络结构;(b) 不同方法预测的10个输出端口强度对比。EMNN(蓝)与FDTD真值(红)几乎重叠,远超ASM(黄)。
战绩二:语音指令识别(非线性系统)
单纯的线性系统还不够。现实世界的智能计算必然需要引入非线性。
作者在设计中加入了非线性激活层(如利用材料的非线性克尔效应或探测器平方律),构建了一个更深层的网络来处理 Speech Commands Dataset(语音指令数据集)。
实验结果再次印证了 EMNN 的强大。即便在引入非线性、网络层级加深的情况下,EMNN 依然保持了极高的正向预测精度和逆向设计成功率,完美攻克了大规模、高复杂度光计算系统的设计难题。
05 研途深思:AI for Science 的正确打开方式
在过去几年里,AI 疯狂涌入自然科学领域,但很多所谓的“AI+物理”不过是拿物理数据去喂黑盒模型,缺乏可解释性,也难以泛化。而清华团队的这项 EMNN 研究,给出了一个完美的示范:
真正的 AI for Science,不应该是AI取代物理,而是AI与物理定律的深度融合(Physics-inspired / Physics-informed)。
通读这篇论文,我们不仅惊叹于其性能的提升,更应从中汲取做研究的灵感。对于每天在实验室里苦苦寻找创新点的本硕博们,这篇论文简直是一本教科书级别的“交叉学科创新指南”:
痛点即风口,拒绝“为了深度学习而深度学习”
现在很多同学做AI4S(AI for Science),喜欢套用最新的大模型、GAN网络,以为堆参数就能出好结果。但这篇论文告诉我们:在自然科学领域,物理可解释性永远是第一位的。 作者没有选择花哨的Transformer,而是老老实实地把麦克斯韦方程和惠更斯原理“揉”进网络架构里。结果,一个简单的MLP网络爆发出了惊人的威力。
化整为零的降维打击思维
遇到大规模问题,不要硬刚。作者巧妙地将“大尺寸波前预测”拆解成“小尺寸Netlet预测 + 物理法则拼接”。这种分治法(Divide and Conquer)不仅解决了内存瓶颈,还赋予了模型极大的灵活性(Handling arbitrary sizes)。这在处理高自由度优化问题时,是非常值得借鉴的思路。
扎实的实验设计,自底向上建立信任
论文的图2先用基础波形证明了Netlet的物理一致性;图3用手写数字证明了线性系统的有效性;最后用语音识别和非线性系统封神。逻辑层层递进,让人读来心服口服。我们在做研究汇报时,也应避免一上来就抛出宏大叙事,而是要一步步用扎实的数据建立审稿人的信任。
结语
计算超构系统被认为是突破摩尔定律的明日之星。而 EMNN 的出现,犹如为其装上了一台“超级引擎”。它不仅极大地缩短了光子芯片的研发周期,更重要的是,它向我们展示了物理学与深度学习深度融合的无限可能。
或许在不久的将来,我们设计复杂的光子集成电路(PIC),真的可以像今天训练一个ResNet那样轻松快捷。
👇 【互动话题】
你在做仿真或者逆向设计时,最头疼的问题是什么?是FDTD跑得太慢,还是模型总是不收敛?欢迎在评论区吐吐槽,我们一起交流避坑!



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢