

自然演化用了数亿年,才构建出了今天的蛋白质世界。催化反应、传递信号、识别病原体,几乎所有精密生命过程的背后,都有蛋白质在“工作”。但癌症、阿尔茨海默病、气候变化等挑战,并不会给人类留下再等待几百万年的时间。
于是,一个非常直接的问题摆在面前:我们能否不再停留在天然蛋白质的“修修补补”,而是从零开始,主动设计出全新的蛋白质?
这正是从头蛋白质设计的出发点。它不以天然蛋白为模板,而是直接从功能出发,用计算方法同时构建全新的结构和序列。这个方向已发展近 30 年,而过去 5 年,随着深度学习的加入,进展明显提速。
刚刚,诺贝尔化学奖得主、华盛顿大学教授 David Baker 团队在一篇发表在权威科学期刊 Nature 上的系统性综述中,全面回顾了这一领域的发展历程,包括过去、现在和未来。

论文链接:https://www.nature.com/articles/s41586-026-10328-7
更值得关注的是,Baker 团队判断,未来 5-10 年,蛋白质设计有望从“造分子”迈向“造机器”,并在医学、技术和可持续发展等领域展现超越天然蛋白的巨大潜力。
过去:从物理法则出发
从头蛋白质设计最早要回答的问题,其实很基础:人工写出的氨基酸序列,能不能稳定折叠成预期结构?
1988 年,Regan 和 DeGrado 设计出可以自组装成螺旋束的多肽,证明人工序列的确能够编码特定结构。但那时的突破还主要停留在二级结构层面。真正决定这个领域命运的问题是:人类能不能从零设计出一个可以稳定折叠、而且在自然界中不存在的全新蛋白?
2003 年,Kuhlman 等人借助 Rosetta 设计出了 Top7,一个没有天然同源结构的全新折叠。它的重要性不在于“又多了一个蛋白”,而在于它证明了一件事:从头创造蛋白质,不只是概念,而是可以真正做到。
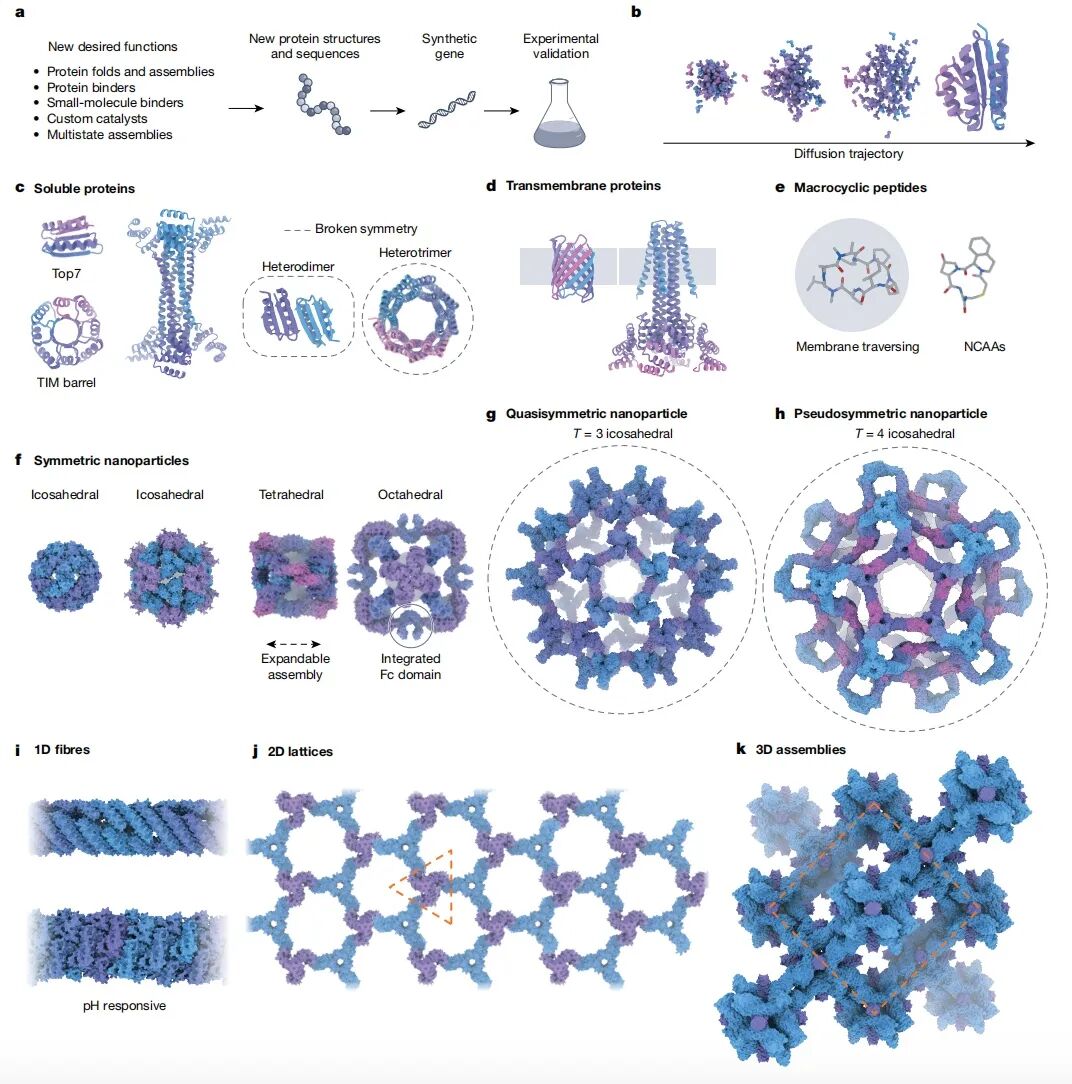
图|蛋白质设计的主要挑战,以及蛋白质折叠体和组装体的设计
此后近 20 年,Rosetta 基本定义了这一领域的方法学框架。研究者陆续做出了 TIM barrel、重复蛋白、跨膜蛋白、纳米颗粒等多种新结构,蛋白质设计也从“能不能做”走向“能做多复杂”。跨膜蛋白、孔道、离子通道乃至具有构象切换能力的转运体,都已经进入可设计范围;设计空间也不再局限于二十种天然氨基酸,而是开始扩展到非天然侧链、非天然骨架以及具有口服潜力的大环体系。
不过,这条路线的局限也始终明显。Rosetta 依赖物理能量函数和预设的构象采样,擅长在已有框架内优化,却不擅长大范围探索复杂结构空间。换句话说,它能精修,但不太有“想象力”。这一点在酶设计上尤其突出:要让催化残基在三维空间中精确排布,以稳定反应过渡态,远比“做出一个能折起来的蛋白”困难得多。面对高极性界面、动态构象和内在无序区域,传统方法也常常力不从心。
现在:正被生成式AI改写
转折发生在 2020 年前后。AlphaFold 和 RoseTTAFold 的出现,改变的并不只是“结构预测更准了”,而是整个设计问题的提法。过去的设计更像是在寻找低能量结构;现在的设计越来越像是在采样“高概率的序列-结构对”。前者只关心某个结构本身是否稳定,后者则隐含地考虑了这个序列会不会更倾向于折叠成别的构象。对设计来说,这种约束更强。
在这一转变之上,生成式 AI 开始运用于蛋白质设计。最有代表性的方法是 RFdiffusion。它把扩散模型引入蛋白主链生成,从随机噪声出发,逐步“去噪”,生成满足几何与功能约束的新蛋白骨架。随后,再由 ProteinMPNN 为固定骨架设计序列,用 AlphaFold 一类工具做结构回判和筛选。今天,这套“骨架生成 + 序列设计 + 结构验证”的流程,已经成为许多设计任务的主流框架。
早期还有一类被称为“hallucination”的方法,直接在序列空间优化模型输出。它们证明了深度学习模型里确实蕴含了可用于设计的信息,但也暴露出一个问题:模型“看起来像”,并不等于蛋白真的能稳定折叠。后续研究发现,给这些骨架重新配上 ProteinMPNN 设计的序列,成功率会明显提高。当前主流程,正是在这轮筛选中逐渐稳定下来的。
除了结构生成,蛋白语言模型也在迅速进入这条路线。受 BERT、GPT 这类模型启发,研究者已经能用掩码语言模型、自回归模型,甚至序列-结构协同生成模型来学习和生成蛋白序列。它们还未完全取代现有主流程,但已经成为从头设计的重要补充。
在这套新方法推动下,几类任务进展尤其快。
第一类是结构和组装。今天,从单体蛋白到跨膜蛋白、宏环肽、纳米颗粒、蛋白纤维、二维晶格、三维晶体,设计方法已经能在很大范围内稳定工作。“做出一个自然界没有的新结构”这件事,已经接近不再是最难的问题。更重要的是,组装体不再只是“漂亮结构”。基于二十面体设计纳米颗粒的路线,已经走向真实疫苗平台,并催生 SKYCovione 这样的实际产品;类似思路也正在与 mRNA 递送、蛋白材料和细胞工程结合。
第二类是蛋白质结合剂。过去几年,这个方向进展非常快,靶标已经覆盖病毒蛋白、蛇毒毒素、免疫检查点、细胞因子受体等多个体系。原文不只讨论了“能结合”,还系统展开了几类应用:抗病毒、抗毒素、受体激动剂与拮抗剂、跨血脑屏障递送、促进内吞与溶酶体降解,乃至细胞内靶标降解。部分抗病毒案例中,设计蛋白在动物模型中的效力已可与抗体相当,甚至更强;其中,部分 IL-2 类似物已进入人体临床试验,其他不少案例仍处于临床前阶段。
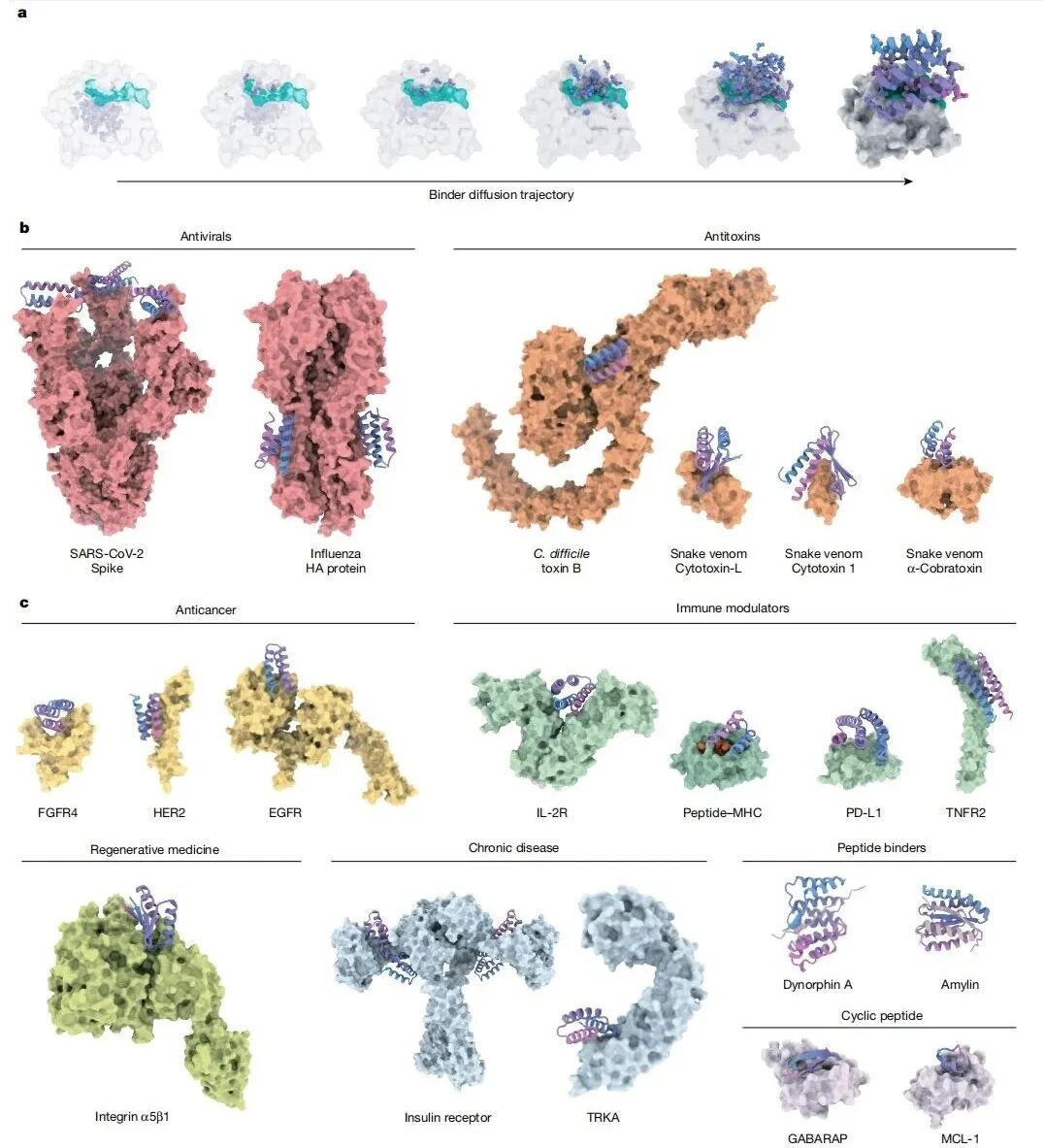
图|针对蛋白质靶标的结合设计
第三类是小分子结合与传感。这个方向还谈不上“已经解决”,但工具箱已经成形。研究者已经能围绕目标小分子直接生成结合口袋,并据此构建新的结合蛋白和传感器。Digoxigenin、甲氨蝶呤、Apixaban、胆酸、皮质醇、芬太尼等分子都已有实验验证。它们不仅能用于检测,还能被做成“治疗性海绵”、化学诱导二聚化系统,甚至进一步接到纳米孔平台上,把分子识别变成可读出的信号。
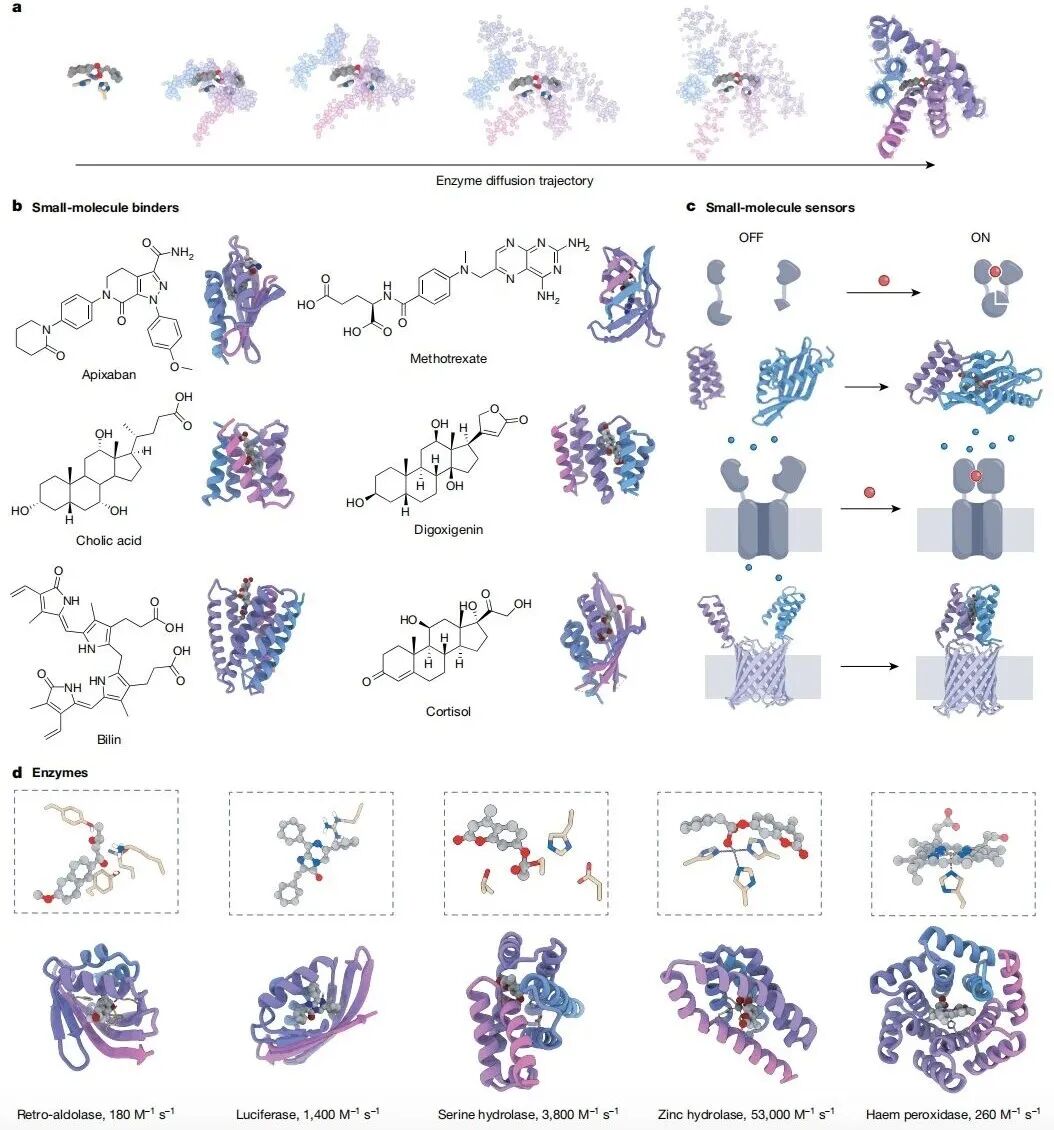
图|小分子结合蛋白与酶的设计
第四类是酶。这里进展很大,但难题也最集中。新的生成方法已经能从原子级活性位点几何出发“长出”支架,再配合 PLACER 等方法评估活性位点的预组织能力。丝氨酸水解酶和金属水解酶都已经出现了比过去强得多的案例。但整体而言,成功仍主要集中在机理相对简单、能垒较低的反应。真正困难的地方在于:催化不是“能结合就行”,而是要在过渡态那一瞬间,把多个关键官能团放到几乎不能出错的位置上。
未来:边界清楚了,难题更集中了
Baker 团队认为,蛋白质折叠、组装,以及相当一部分蛋白质结合剂设计,已经接近“主要问题不再是会不会设计,而是该设计什么”的阶段。真正困难的问题,主要集中在更高一层的整合上。
第一,是高活性酶设计。要把结合、定位、电荷组织和过渡态稳定全部做到位,仍然很难。今天的进步是真实的,但距离天然酶在复杂反应中的表现,仍有明显差距。
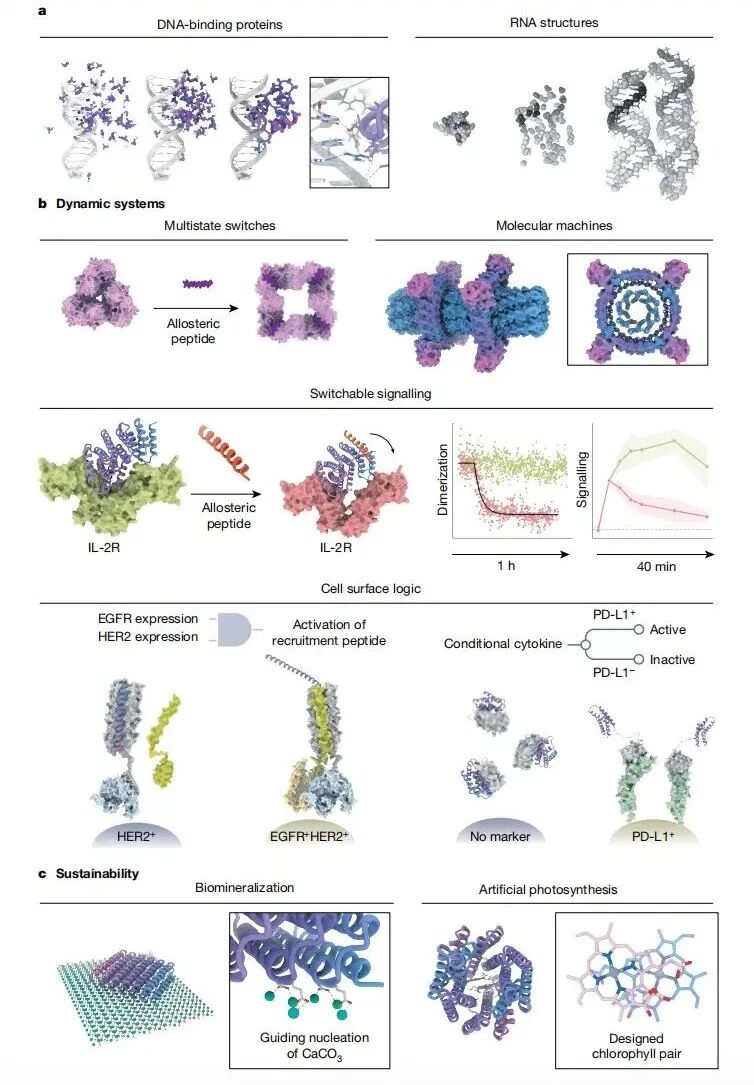
图|具有新功能的蛋白质设计
第二,是动态多状态系统和分子机器。如果说今天的设计蛋白已经越来越会“站住”和“抓住”,那它们距离真正“动起来、循环起来、持续做功”还有很长距离。论文里提到的轴-转子组装体、可切换装配体、LOCKR 逻辑系统,都说明这个方向已经起步;但要把结合、构象变化、催化和能量耦合整合成一个像 ATP 合酶或核糖体那样的系统,今天仍有明显差距。
第三,是核酸识别与调控。原综述把这一点放进了展望:DNA 结合蛋白已可以设计,RFdiffusion 也已扩展到 RNA 和蛋白-RNA 三维结构设计。这一方向有望为基因调控和合成生物学带来新的工具。
第四,是可持续发展相关应用。设计蛋白不仅可以用来做药,还可能参与无机材料模板、生物矿化、人工光合作用和可再生能源体系的构建。也就是说,从头蛋白质设计未来不只是医药平台,也可能成为材料与能源技术的平台。
若要真正走向应用,现实问题也绕不过去。免疫原性当然重要,但并不是唯一问题。大规模制造、低成本生产、新的实验检测与高通量筛选体系,以及生成式设计工具带来的生物安全问题,都会决定这个领域能走多远。
这篇综述最重要的信号,不是“蛋白质设计已经完成”,恰恰相反,它说明这个领域终于走过了“证明能不能做”的阶段,开始进入“挑哪些真正值得做的问题”的阶段。结构设计、组装设计和结合剂设计,正在越来越接近工程问题;而高效催化、动态切换、分子机器,以及核酸、材料和制造层面的拓展,仍然是下一阶段最核心的挑战。
从这个角度看,从头蛋白质设计最激动人心的地方,也许不是它已经完成了什么,而是它终于把问题边界画清楚了。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢