

当今的人工智能(AI)系统虽然功能强大,但大多仍是黑箱。这种黑箱特性引发了人工智能开发者的担忧——“我们如何才能以科学的方式(scientifically)构建和理解人工智能?”,以及人工智能用户面临的挑战——“我们如何才能信任我们不理解的系统?”。本论文旨在尝试解决黑箱问题。
运用科学构建白箱(人工智能的科学,Science for AI):目前人工智能领域的主流范式——“规模化就是一切(scaling is all you need)”——侧重于扩展现有模型。然而,这种方法往往会导致系统既不透明也不高效。我认为,科学原理为设计更透明、更高效的人工智能系统提供了新的视角。这可以通过受数学启发的柯尔莫哥洛夫-阿诺德网络(Kolmogorov-Arnold Networks,KANs)、基于物理直觉的泊松流生成模型(Poisson Flow Generative Models,PFGM)以及从神经科学中汲取灵感的类脑模块化训练(brain-inspired modular training,BIMT)等来证明。
打开黑箱(人工智能科学, Science of AI):现代人工智能模型展现出一系列令人费解的行为——例如“理解"(grokking)、神经缩放定律和涌现表征学习——其潜在机制仍然知之甚少。我采用简化的“球形牛”模型,从相变的角度研究这些现象。我将证明,“理解”是超参数空间中的一个特殊阶段,可以被控制和消除。理解之后学习到的算法也展现出不同的阶段,被称为时钟算法或披萨算法。
人工智能在科学中的应用(AI for Science):随着可解释性的增强,人工智能系统可以开始像“人工智能科学家(AI Scientists)”一样运作,能够从数据中(重新)发现深层的科学结构。这些内容包括守恒定律(conservation laws)、隐藏对称性(hidden symmetries)、可积系统(integrable systems)、拉格朗日和哈密顿形式(Langrangian and Hamiltonian formulations)、模块化结构以及高精度解。
我相信我的研究工作有助于人工智能与科学这一新兴的跨学科领域的发展。基于本论文奠定的基础,我展望未来,科学将引导人工智能走出当前的“炼金术”时代,迈向真正的科学理解时代。

作者:Liu, Ziming
类型:2025年博士论文
学校:Massachusetts Institute of Technology(美国麻省理工学院)
免费下载链接:
https://pan.baidu.com/s/1_OresiMC1v4fhW0beIy8UA?pwd=nwka
请索引第132篇博士论文
 |  |
引言
1.1 人工智能的黑箱问题
毋庸置疑,人工智能 (AI) 正在推动深刻的科学和技术变革——从生成式内容创作 [1] 到掌握围棋等游戏 [2],再到蛋白质折叠 [3] 和天气预报 [4] 的突破。尽管拥有这些卓越的能力,现代人工智能系统在很大程度上仍然是黑箱。这种缺乏透明度带来了诸多挑战。对于人工智能设计者而言,缺乏系统性的理解限制了我们设计、控制和改进人工智能系统的能力。对于人工智能用户而言,信任成为一个问题——如何才能信任一个内部决策或生成过程不透明的系统?
重要的是,人工智能的“黑箱”特性所带来的影响会因具体情况而异。以AlphaFold为例:对于只关心蛋白质最终折叠状态的用户来说,该模型无疑是成功的。但对于那些对蛋白质折叠动力学感兴趣的用户而言,AlphaFold内部运作机制缺乏可解释性,可能会让他们感到非常失望。
人们常常认为黑箱行为是一种特性而非缺陷——为了获得更高的能力,我们必须牺牲可解释性。我持有一种不受欢迎但却乐观的观点:人工智能系统可以兼具强大的能力和可解释性。然而,可解释性是一个微妙的概念,需要加以澄清。我提出以下几个层次:
• 0 级 - 无可解释性:我们完全放弃可解释性。
• 1 级 - 网络级可解释性:我们将整个网络视为一个单一函数,并分析其输入输出行为。
• 2 级 - 模块级可解释性:我们将网络分解为模块,并研究每个模块的功能。
• 3 级 - 神经元级可解释性:我们的目标是理解系统中每个神经元的作用。
尽管目前大多数研究都集中在第0层或第1层,但我认为第2层可解释性已经存在于现有模型中——包括大型语言模型——只是通常是隐式的。如何显式地识别和提取这些功能模块仍然是一个尚未解决的难题。至于第3层,我认为它在当今的系统中基本缺失,只有少数例外,例如“法语神经元”[5]。要实现真正的神经元级可解释性,可能需要全新的架构和训练范式,这很可能需要多学科的共同努力——融合数学、物理学、神经科学、计算机科学、哲学以及其他领域的思想。
本论文的目标是朝着解决黑箱问题迈出谦逊的第一步。
1.2 科学在人工智能中的作用
回顾人工智能的发展历程,科学在其发展过程中扮演了至关重要的角色。从1956年的达特茅斯会议(约翰·麦卡锡在会上提出了“人工智能”一词)开始,人工智能的第一波(20世纪60年代至70年代)和第二波(80年代)浪潮主要由符号系统主导。这些所谓的专家系统基于逻辑、推理和人工编码的知识,高度依赖于数学、计算机科学和特定领域专业知识等科学基础。
20世纪90年代,人工智能开始从符号推理转向统计和概率方法,其标志模型包括决策树、支持向量机和隐马尔可夫模型。这一时期也见证了霍普菲尔德网络[6]和玻尔兹曼机[7]的出现——它们是现代神经网络的前身——以及反向传播等训练算法的进步。物理学和神经科学在这一发展过程中发挥了核心作用,启发了网络架构和训练动态。2010年代的深度学习革命,以AlexNet[8]等突破性成果为导火索,继续借鉴这些学科:扩散模型[9-11]的灵感来源于热力学过程,而Transformer模型[12]中的注意力机制则源于认知科学。
自2020年以来,神经缩放定律[13]的发现催生了一种务实却又颇具争议的观点:我们或许只需扩展模型、数据和计算能力,就能实现通用人工智能(AGI),而无需更深入的科学理解。尽管这种“扩展即一切”的观点推动了快速发展,但我认为它终究是短视的。缩放定律的饱和迹象开始显现,而最先进的人工智能系统仍然无法完成对人类而言轻而易举的任务,例如视觉推理[14]和物理理解[15]。这些失败模式表明,我们仍然缺乏构建真正智能系统所需的关键洞见。是时候重新戴上科学家的帽子了。
需要明确的是,采用科学方法并不意味着回归手工编写的符号人工智能。惨痛的教训[16]和“天下没有免费的午餐”定理[17]都提醒我们,硬编码的归纳偏差仅在数据匮乏的情况下或构建狭义的专业系统中才有用。相反,这呼吁我们投入更多精力去理解和解决当今人工智能系统的基础性局限性,并孵化新的范式,而不是将所有资源都用于追求当前的扩展极限。
尽管规模化叙事占据主导地位,但我绝非唯一倡导以更科学的方式研究人工智能的人。然而,我的物理学背景赋予了我独特的视角——一种平衡实验与理论的视角。我研究现有的人工智能系统并设计新的系统,其方式与物理学家研究和构建物理系统的方式非常相似:始于实验观察,终于实验观察,同时运用建模来系统地指导发现过程。
得益于丰富的数学工具和科学理论,我们无需从零开始创造一切。相反,我们通常可以将现有的理论——或许稍作修正——与观察到的现象相匹配。毕竟,爱因斯坦并非黎曼几何的发明者;他的天才之处在于认识到黎曼几何可以为广义相对论提供合适的数学框架。这需要对几何学和物理理论都有深刻而直观的理解。
打个比方:如果人工智能是今天的广义相对论,我们尚未找到它的“黎曼几何”。但只要找到正确的科学视角,我们或许就能找到。
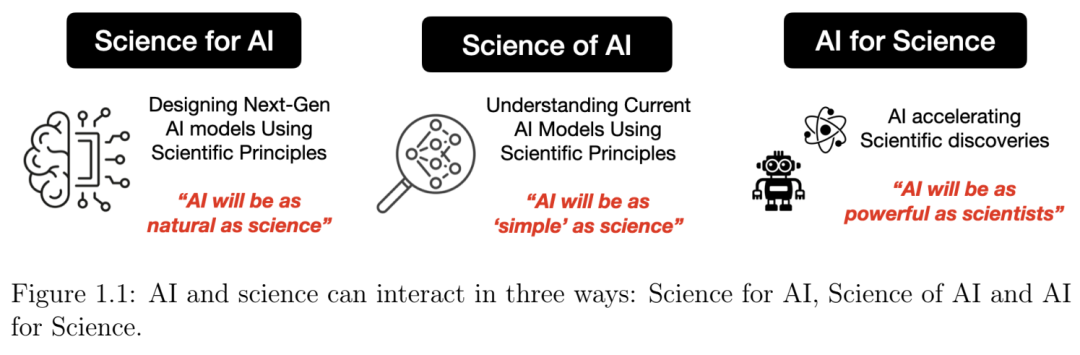
1.3 路线图
既然我已经(希望)说服了各位,科学是解决人工智能黑箱问题的关键要素,那么现在就该更具体地阐述科学如何助力这一问题的解决。总的来说,解决问题有两种方法:要么直接面对,要么找到规避的方法。因此,我们可以从两个互补的角度来解决人工智能黑箱问题:
• 通过打开黑箱并分析其内部机制——我称之为人工智能科学,或者
• 通过设计与当前黑箱模型功能一样强大,但更易于解释和控制的白箱系统——我称之为人工智能科学。
即使在解决“黑箱”问题上取得部分进展——尤其是在特定的科学领域——也能使人工智能系统更加值得信赖、透明,并在那些可解释性和理解性至关重要的领域中发挥更大的作用。这就引出了第三个交互维度:人工智能服务于科学——即可解释的人工智能系统能够帮助推动科学发现本身的发展。
总而言之,人工智能与科学可以通过三种基本方式协同作用(图 1.1):科学服务于人工智能、科学服务于人工智能以及人工智能服务于科学。
1.3.1 人工智能的科学基础
解决黑箱问题的一种方法是构建受科学启发的白箱模型。科学学科本身就具有可解释性,并且比人工智能拥有更悠久的历史,这意味着它们在指导人工智能发展方面大有可为。在本部分,我将展示如何利用科学原理来启发可解释人工智能模型的设计——借鉴数学(第2章)、物理学(第3章)、神经科学(第4章)和计算机科学(第5章)的理论。
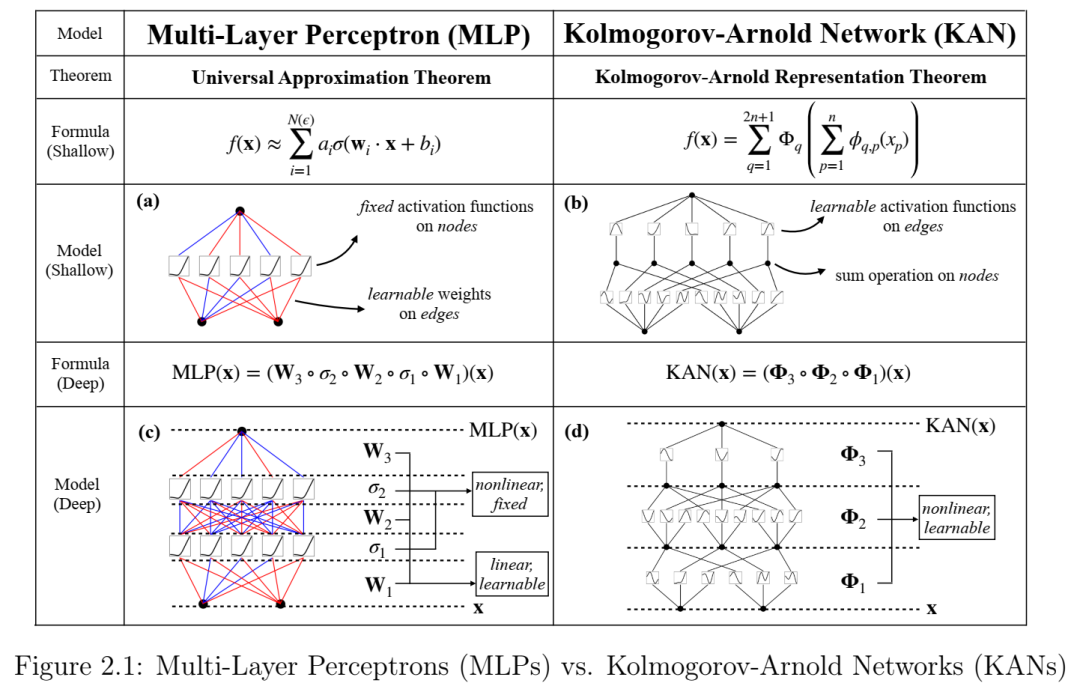
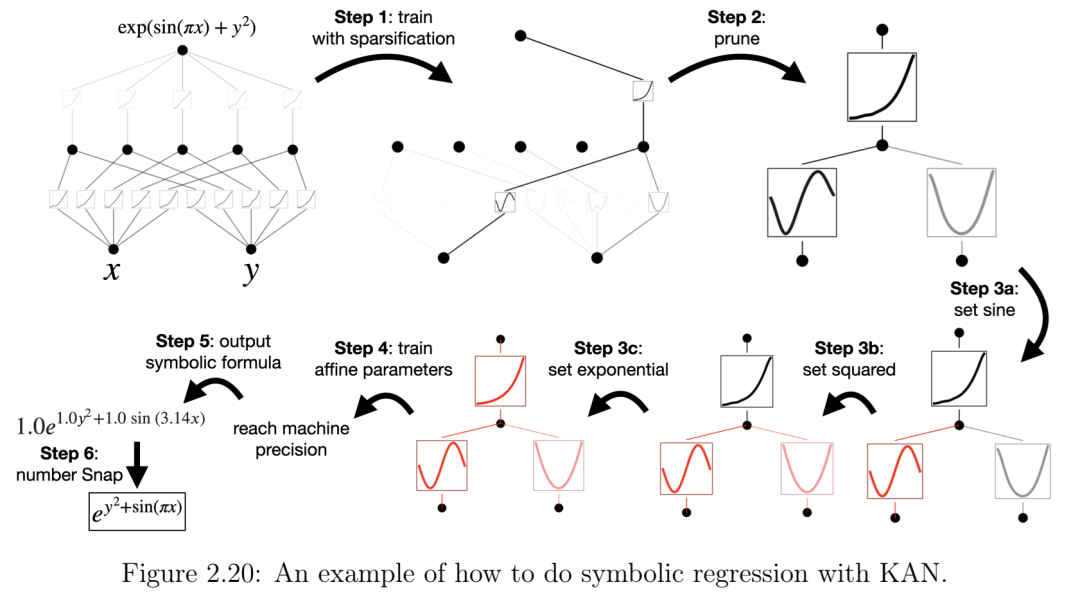
第2章题为“KAN:柯尔莫哥洛夫-阿诺德网络”,介绍了一种新型神经网络,作为流行的多层感知器(MLP)的替代模型。受柯尔莫哥洛夫-阿诺德表示定理的启发,KAN 比 MLP 更能表示符号公式的组合结构,从而提供更好的可解释性和更快的神经网络扩展规律。KAN 在图像拟合和偏微分方程求解方面也优于 MLP。我的贡献是领导该项目——提出最初的想法,完成大部分数值实验,并撰写论文的大部分内容。本章以口头报告的形式发表于 2025 年国际学习表征会议(ICLR 2025)[18]。
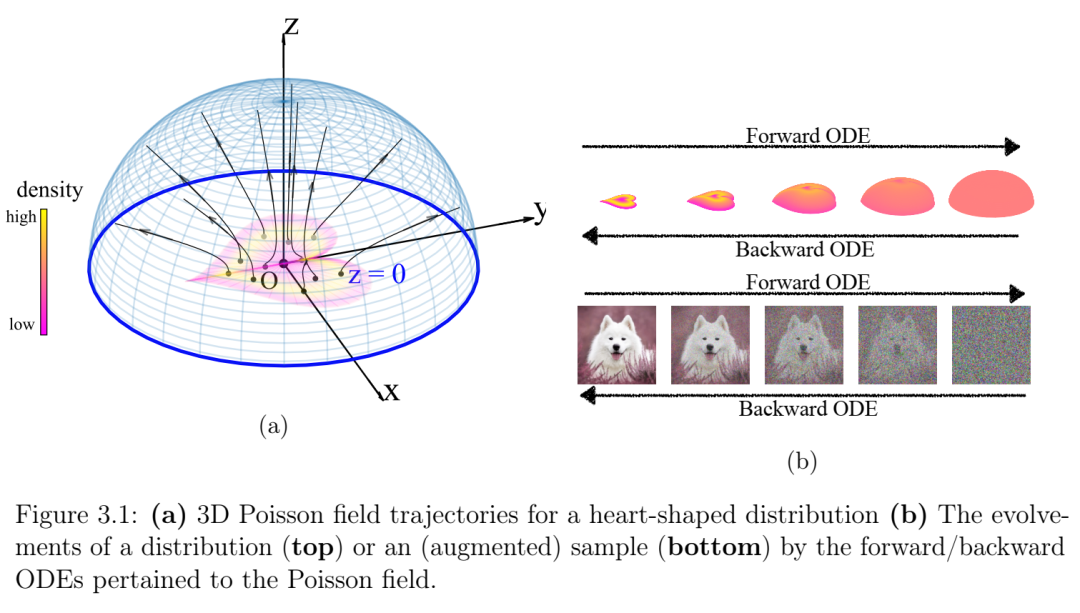
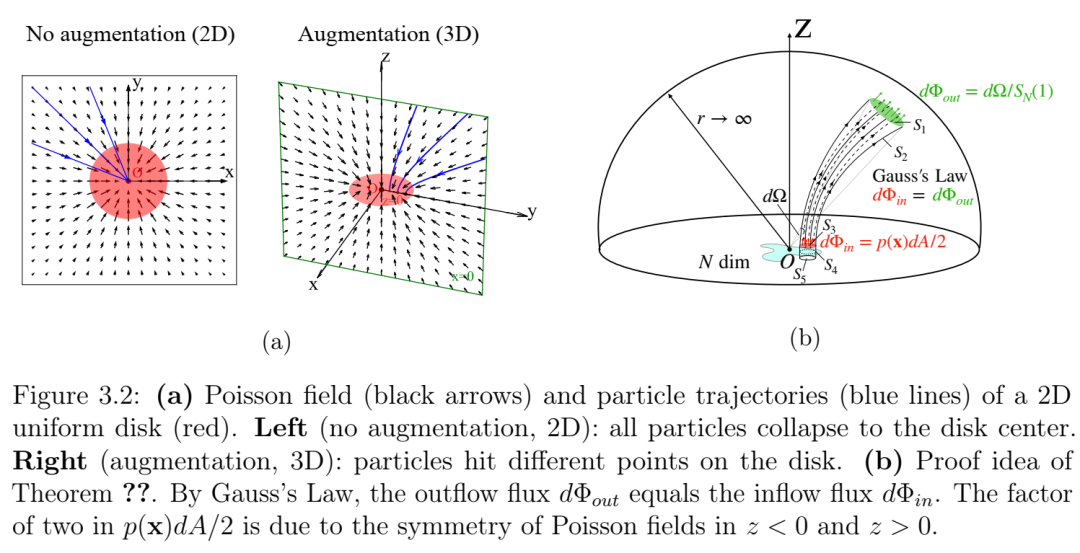
第3章题为“泊松流生成模型”,介绍了一种受物理学启发的新型生成模型。尽管扩散模型取得了成功,但我们发现扩散过程本身并无特殊之处,完全可以用静电场(泊松场)来替代。将干净的数据点视为点电荷,这些点电荷产生的电场将数据分布与大球面上的均匀分布联系起来。这一观察结果构成了泊松流生成模型的基础:可以通过在大球面上初始化一个随机点来生成样本,然后让样本沿着电场线演化,直到到达数据流形。我的贡献在于提出了最初的想法,进行了概念验证的玩具实验,并撰写了论文的模型部分。本章发表于神经信息处理系统会议(NeurIPS 2022)[19]。
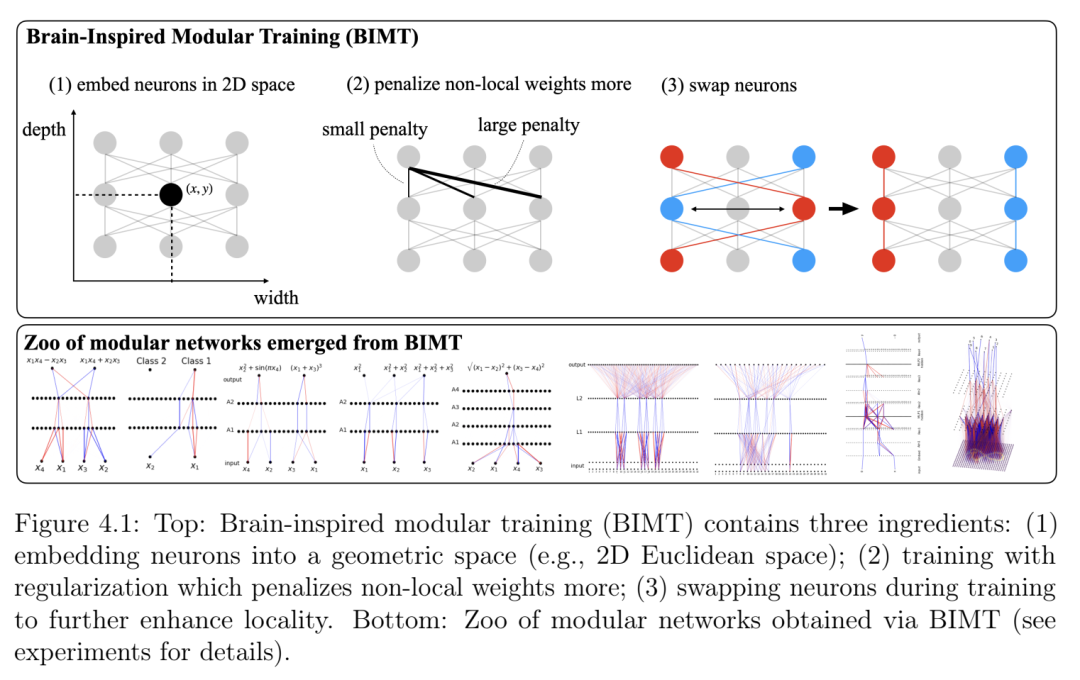
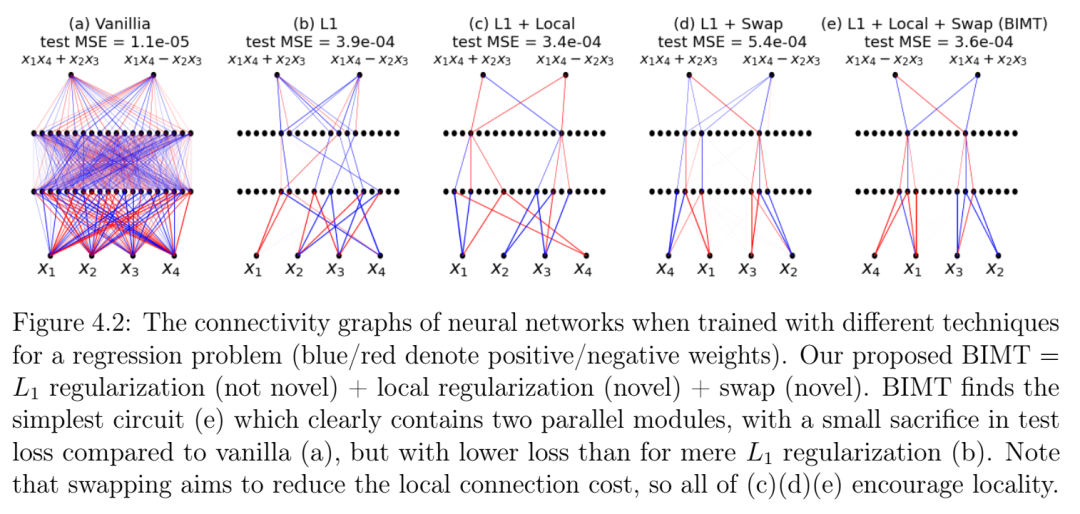
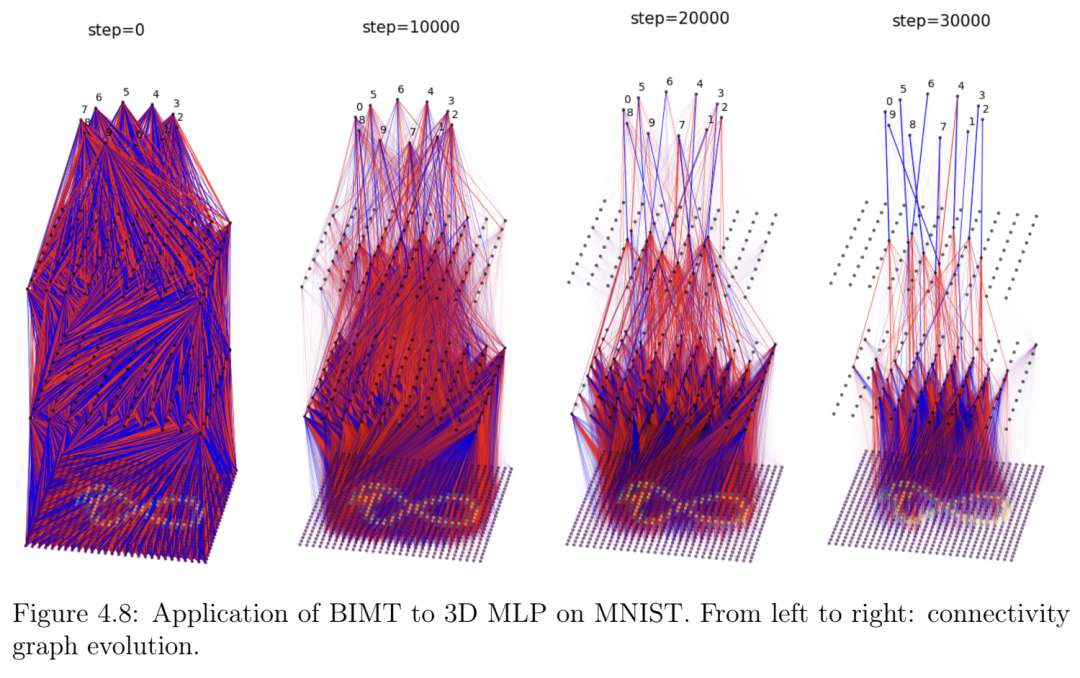
第4章题为“眼见为实:用于机制可解释性的脑启发式模块化训练”,介绍了脑启发式模块化训练(BIMT),这是一种使神经网络更具模块化和可解释性的方法。受大脑启发,BIMT 将神经元嵌入几何空间,并利用与每个神经元连接长度成正比的成本来增强损失函数。我们证明 BIMT 能够发现适用于多种任务的实用模块化神经网络。我的贡献在于提出原始思路、运行大部分数值实验以及撰写论文的大部分内容。本章发表于 Entropy (2024) [20]。
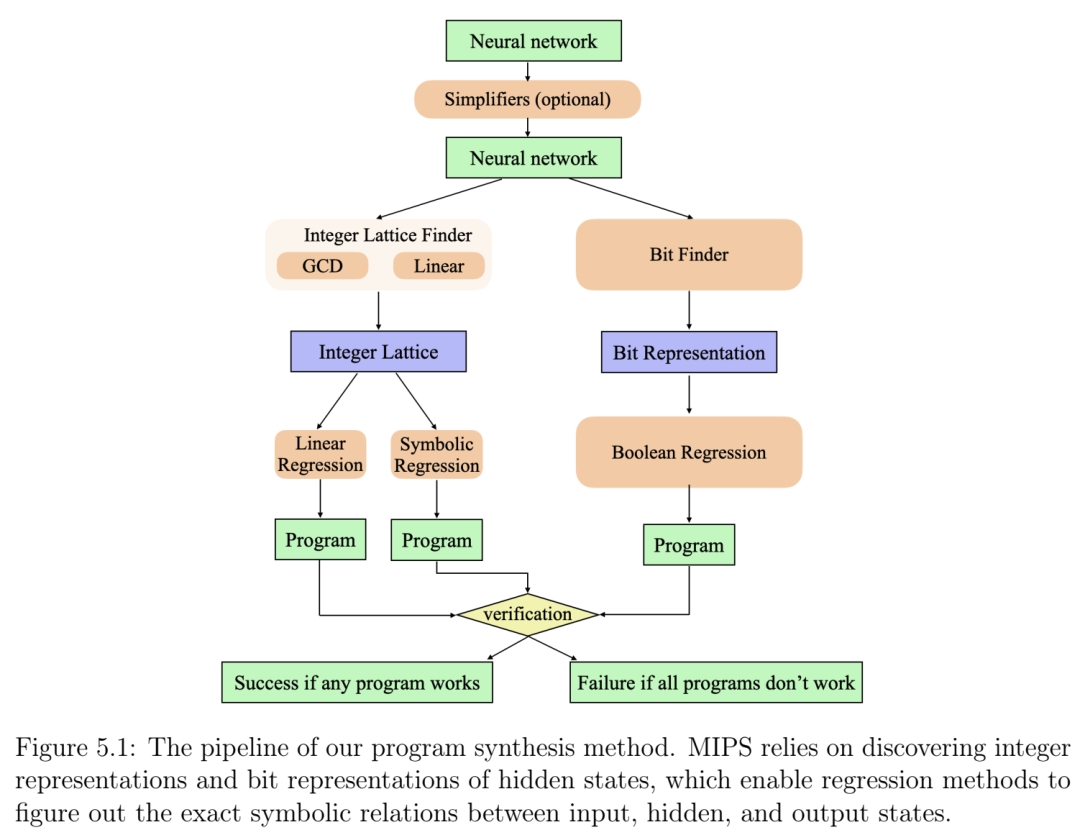
第5章题为“打开 AI 黑匣子:基于机制可解释性的程序合成”,介绍了一种名为 MIPS 的新型程序合成方法。该方法基于神经网络的自动机制可解释性,这些神经网络经过训练以执行所需任务,并将学习到的算法自动提炼为 Python 代码。我们使用包含 62 个可由 RNN 学习的算法任务的基准测试集测试了 MIPS,发现它与 GPT-4 高度互补:MIPS 解决了其中的 32 个任务,包括 GPT-4 无法解决的 13 个任务(GPT-4 也解决了 30 个任务)。 MIPS 使用整数自编码器将 RNN 转换为有限状态机,然后应用布尔或整数符号回归来捕获学习到的算法。我的贡献包括符号回归和布尔回归的数值实现以及相应部分的编写。本章发表于 Entropy (2024) [21]。
1.3.2 人工智能科学
尽管深度神经网络在当前的人工智能革命中发挥了核心作用,但我们对它们的科学理解仍然有限。这些模型可能会出现意想不到的失败——即使是对人类来说轻而易举的任务——并且会表现出一系列令人费解的行为。值得注意的现象包括“理解”(grokking)或延迟泛化(第7章和第8章),以及多样化算法的涌现(第9章)。
第6章题为“理解理解:表征学习的有效理论”,旨在理解“理解”现象,即模型在过拟合训练集很久之后仍然能够泛化。我们提出了基于有效理论的微观分析,以及描述学习性能随超参数变化的相图的宏观分析。我们发现,泛化源于结构化表征,在玩具模型环境中,我们的有效理论可以预测这些表征的训练动态及其对训练集大小的依赖性。我们通过实验观察到四个学习阶段:理解、理解、记忆和困惑。我们发现表征学习仅发生在记忆和困惑之间的“黄金地带”(包括理解和领悟)。我的贡献在于运行了大部分实验,进行了有效的理论分析,并撰写了论文的大部分内容。本章以口头报告的形式发表于神经信息处理系统会议 (NeurIPS 2022) [22]。
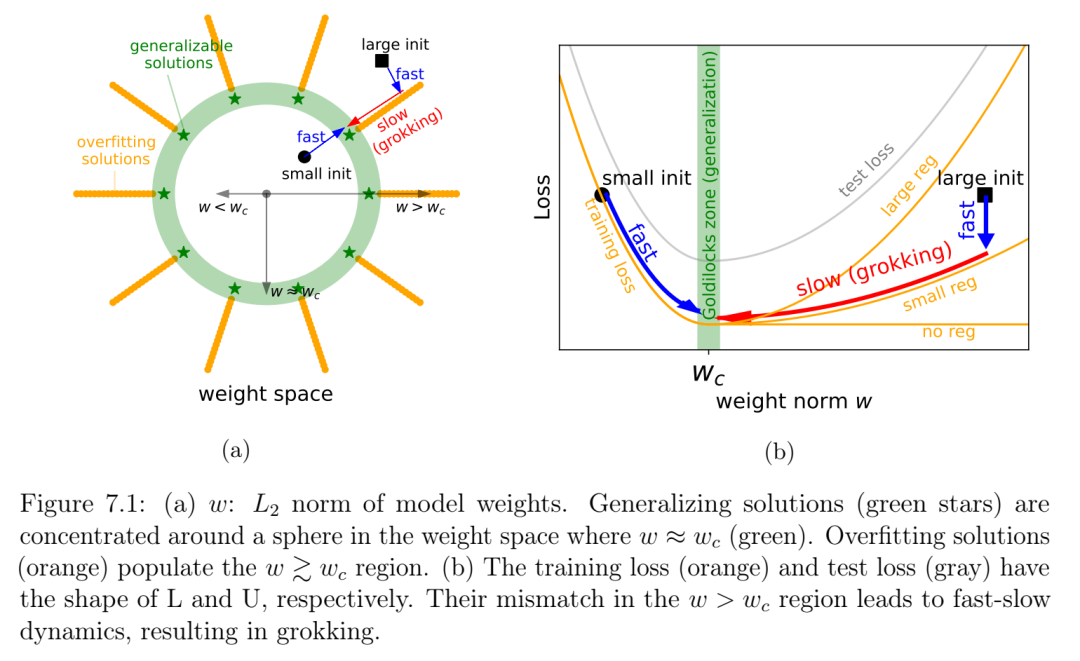
第7章题为“Omnigrok:超越算法数据的领悟”,旨在通过分析神经网络的损失曲线来理解领悟,并将训练损失和测试损失之间的不匹配识别为领悟的根源。我们将其称为“LU机制”,因为训练损失和测试损失(相对于模型权重范数)通常分别类似于“L”和“U”。这种简单的机制可以很好地解释领悟的许多方面:数据规模依赖性、权重衰减依赖性、表征的涌现等等。在这一直观的指导下,我们能够在涉及图像、语言和分子的任务中诱导领悟。反过来,我们能够消除算法数据集的理解过程。我们将算法数据集理解过程的显著特点归因于表征学习。我的贡献包括最初的概念化、运行大部分实验以及撰写论文的大部分内容。本章作为亮点发表于国际表征学习会议 (ICLR 2023) [23]。
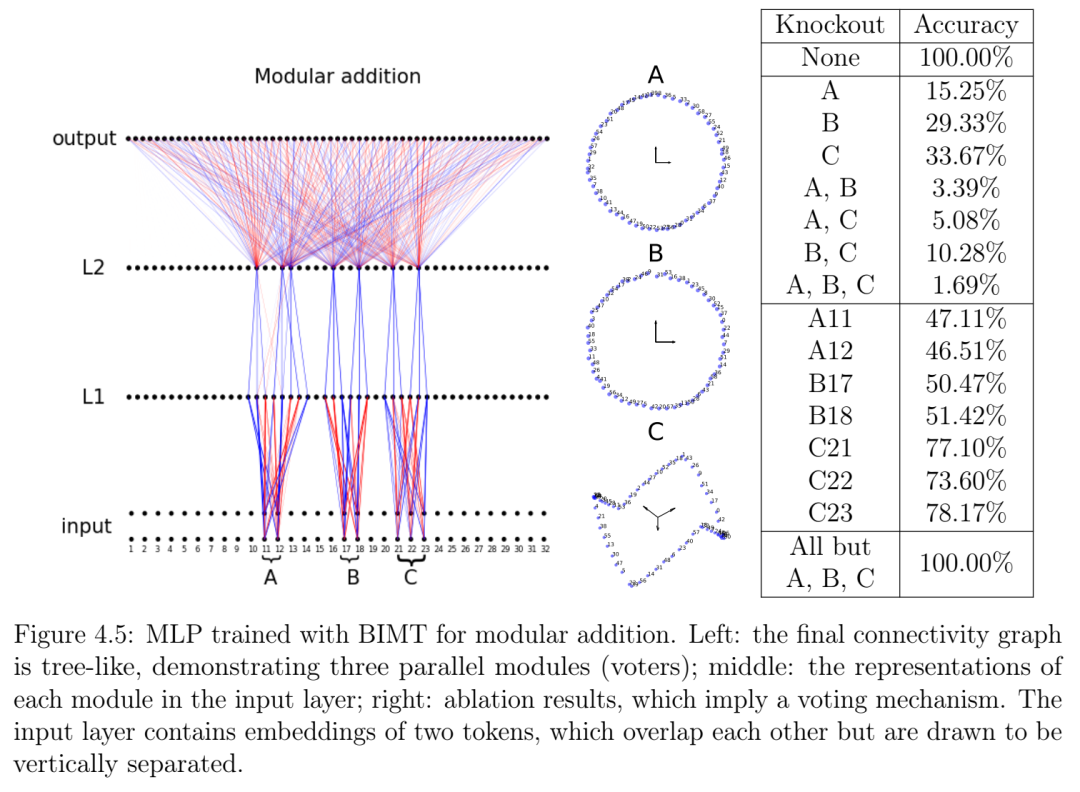
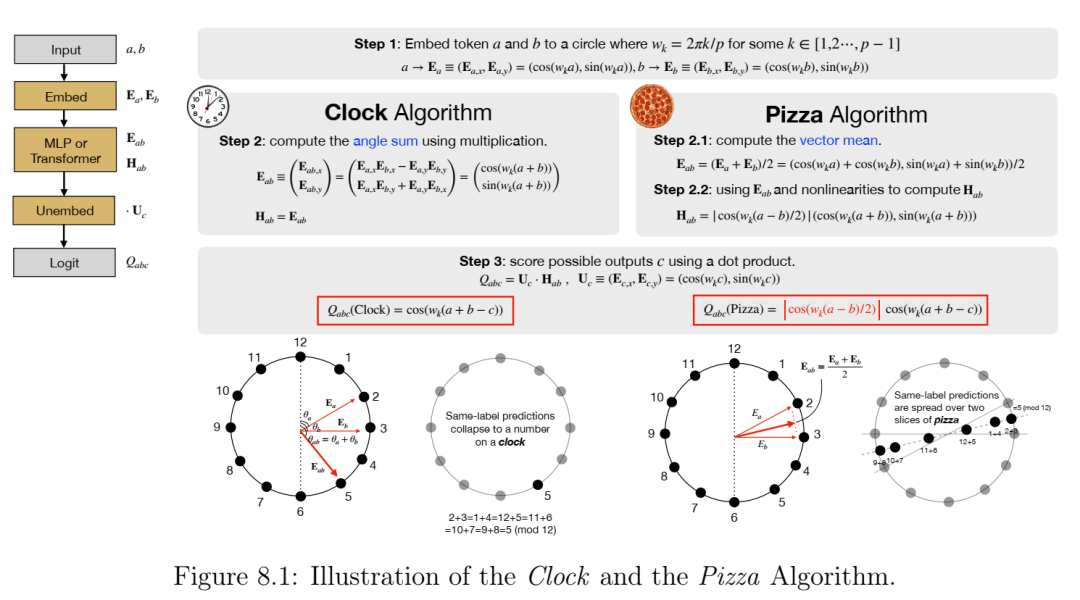
第8章题为“时钟与披萨:神经网络机制解释中的两个故事”,以模加法为原型问题,我们展示了神经网络中的算法发现有时比预期的要复杂得多。对模型超参数和初始化的微小改变可以从固定的训练集中发现性质截然不同的算法,甚至可以并行实现多个此类算法。一些训练用于执行模加法的网络实现了熟悉的时钟算法;另一些网络则实现了之前未描述过的、不太直观但易于理解的程序,我们称之为披萨算法,或者各种更复杂的程序。我们的研究结果表明,即使是简单的学习问题也能存在令人惊讶的多种解决方案,这促使我们开发新的工具来表征神经网络在其算法相空间中的行为。我的贡献包括提出研究相变的原创想法、命名披萨/时钟算法以及对项目的技术指导。本章以口头报告的形式发表于神经信息处理系统会议 (NeurIPS 2023) [24]。
1.3.3 人工智能在科学领域的应用
由于可解释性和理解性在科学界备受重视,人工智能模型必须具备一定程度的可解释性,才能在科学领域中被视为有用且值得信赖。通过将科学归纳偏差恰当地融入模型架构和/或训练目标中,人工智能系统可以有效地解决一系列科学问题。特别是,人工智能模型已展现出(重新)发现守恒定律(第9、10和11章)、隐藏对称性(第12章)和非保守动力学(第13章)的能力。
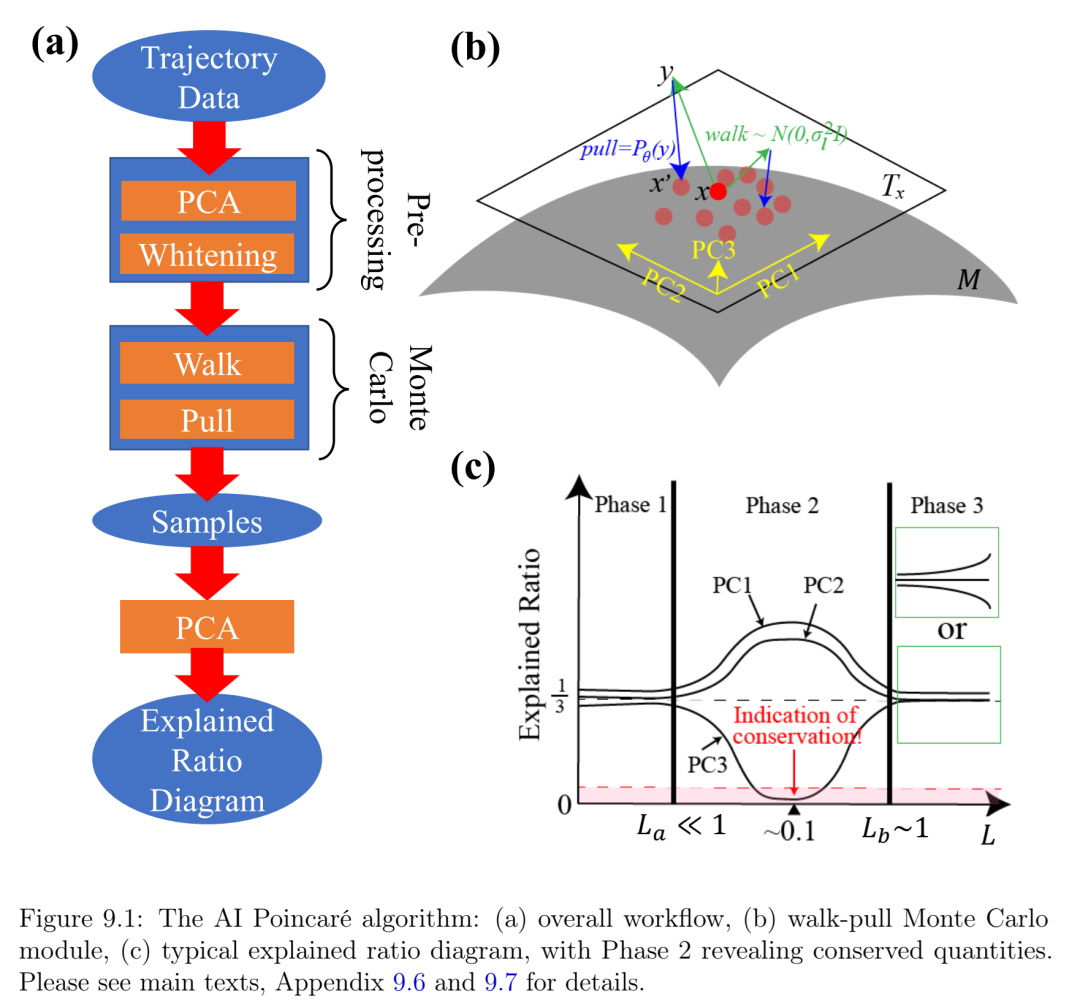
第9章题为“基于轨迹的机器学习守恒定律”,介绍了一种利用未知动力系统的轨迹数据自动发现守恒量的机器学习算法。我们对五个哈密顿系统(包括引力三体问题)进行了测试,发现它不仅能发现所有精确守恒量,还能发现周期轨道、相变以及近似守恒律的失效时间尺度。我的贡献在于设计算法、运行所有数值实验以及撰写初稿。本章作为编辑推荐发表于《物理评论快报》(Physical Review Letters) (2021) [25]。
第10章题为“基于微分方程的机器学习守恒律”,提出了一种机器学习算法,该算法能够从微分方程中发现守恒律,既可以数值地(参数化为神经网络)也可以符号地进行,并确保其函数独立性(线性独立性的非线性推广)。我们的独立性模块可以看作是奇异值分解的非线性推广。我们的方法可以轻松处理守恒律的归纳偏置。我们用包括三体问题、KdV方程和非线性薛定谔方程在内的例子验证了该方法的有效性。我的贡献包括算法设计、运行大部分数值实验以及撰写论文。本章发表于《物理评论E》(2022)[26]。
第11章题为“发现新的可解释守恒律作为稀疏不变量”,提出了稀疏不变量检测器(SID),一种能够从微分方程中自动发现守恒律的算法。其算法的简洁性保证了所发现守恒量的鲁棒性和可解释性。我们证明,SID能够在各种系统中重新发现已知的守恒律,甚至发现新的守恒律。在流体力学和大气化学的两个例子中,SID分别发现了14个和3个守恒量,而此前领域专家仅知道其中的12个和2个。我的贡献包括算法设计、将算法应用于合作者提供的例子以及撰写论文的大部分内容。该论文发表于《物理评论E》(2023)[27]。
第12章题为“机器学习中的隐藏对称性”,提出了一种自动寻找隐藏对称性的方法。隐藏对称性被定义为仅在需要发现的新坐标系中才会显现的对称性。其核心思想是将不对称性量化为对某些偏微分方程的违反,并在所有可逆变换的空间(参数化为可逆神经网络)上数值最小化这种违反。例如,我们的方法重新发现了著名的古尔斯特兰-潘列夫度规,该度规在非旋转黑洞的史瓦西度规中展现了隐藏的平移对称性,以及哈密顿性、模性和其他一些传统上不被视为对称性的简化特征。我的贡献是实现该算法、运行所有数值实验并撰写论文初稿。本章作为编辑推荐发表于《物理评论快报》(2022)[28]。
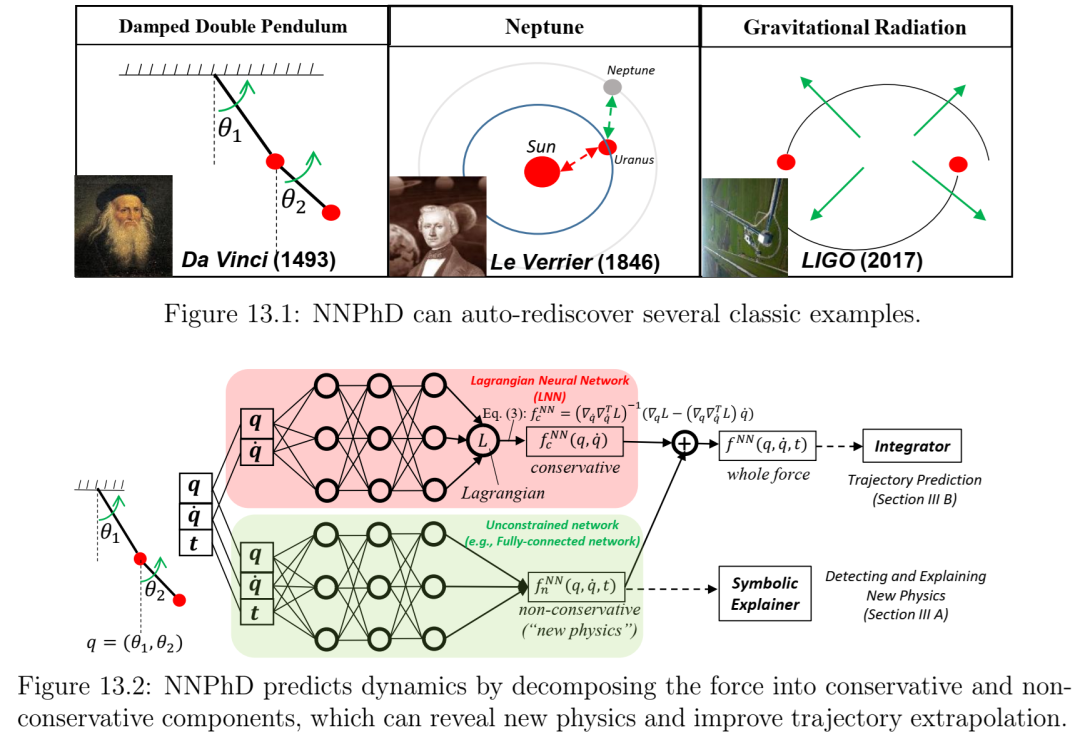
第13章题为“用于新物理探测的机器学习非保守动力学”,介绍了一种名为神经新物理探测器(NNPhD)的算法。该算法旨在通过将力场分解为保守力和非保守力分量来探测新物理。保守力和非保守力分量分别由拉格朗日神经网络(LNN)和通用逼近器网络(UAN)表示,训练目标是最小化力恢复误差加上一个常数λ,该常数λ是预测的非保守力的大小。我们证明,对于任意力,在λ = 1处都会发生相变。我们通过简单的数值实验证明,NNPhD成功地发现了新物理,例如从阻尼双摆中重新发现了摩擦力(1493),从天王星轨道中发现了海王星(1846),以及从螺旋轨道中发现了引力波(2017)。我们还展示了 NNPhD 与积分器结合使用时,在预测阻尼双摆的未来运动方面优于以往的方法。我的贡献包括提出该想法、运行所有实验以及撰写论文初稿。本章发表于《物理评论 E》(2021)[29]。













内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢