
2026年3月,上海第二工业大学计算机与信息工程学院与重庆大学药学院等单位的研究人员在《Drug Discovery Today》期刊发表综述论文,题为“Large language models for molecular design: bridging the gap between chemical syntax and biological semantics”。该研究系统梳理了大语言模型(LLMs)在分子设计中的应用进展,重点探讨其如何连接“化学语法”与“生物语义”,并推动药物研发从传统计算走向自动化闭环体系。

化学及生物建模基础
从化学语法到生物语义
分子设计的核心挑战在于如何将“可写的分子结构”与“具有生物功能的分子”联系起来。化学语法指的是分子表示的规则体系,例如价态、环结构及SMILES表达的合法性;而生物语义则关乎分子在生物系统中的作用,如结合活性、毒性及通路调控。
在大语言模型框架下,这种语义对齐可分为三个层面:结构语义(涉及三维构象与结合位点匹配)、功能语义(对应活性与药效等表型特征)以及知识语义(来源于文献与数据库的生物医学知识)。模型通过多模态预训练,将化学结构、生物序列与文本信息映射到统一空间,从而实现跨领域理解。
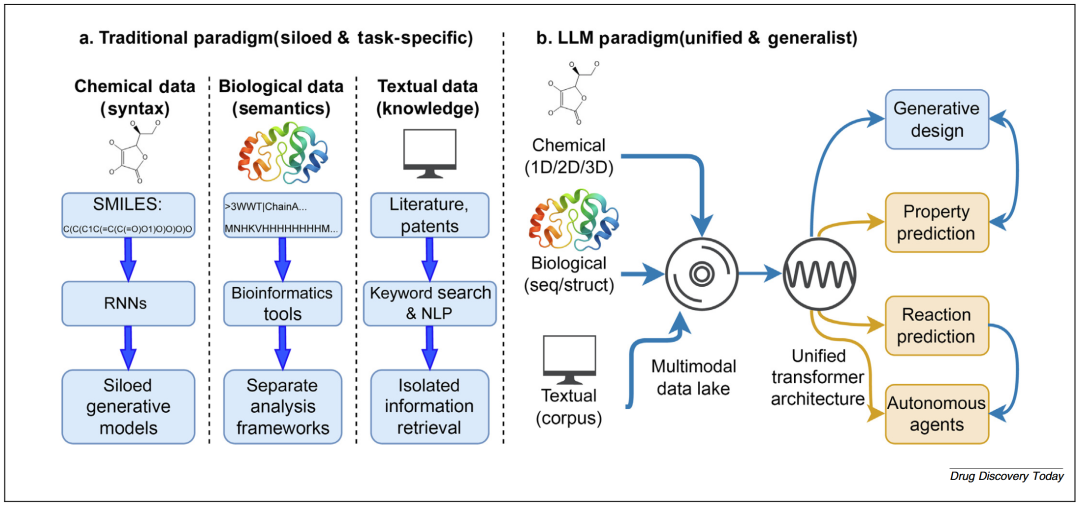
图1 从传统“孤立模型”到LLM统一框架的转变
分子表示与模型架构演进
在分子表示方面,SMILES仍是最常用形式,但其对语法错误敏感。SELFIES等新型表示方法通过设计保证100%语法合法性,但会带来序列长度增加等问题。进一步地,片段级表示与图结构表示能够更好地保留化学结构信息,提高可解释性与可合成性。
蛋白质则通常以氨基酸序列表示,这种“生物语言”隐含了三维结构与功能信息。将蛋白序列作为条件输入,可以实现针对特定靶点的分子生成。
在模型架构上,研究主要集中在三类:一是编码器模型(如ChemBERTa)用于表征学习与性质预测;二是解码器模型(如MolGPT)用于分子生成;三是编码器-解码器模型用于反应预测与逆合成分析。此外,MoE(专家混合)结构与统一Transformer框架进一步提升了多任务能力。
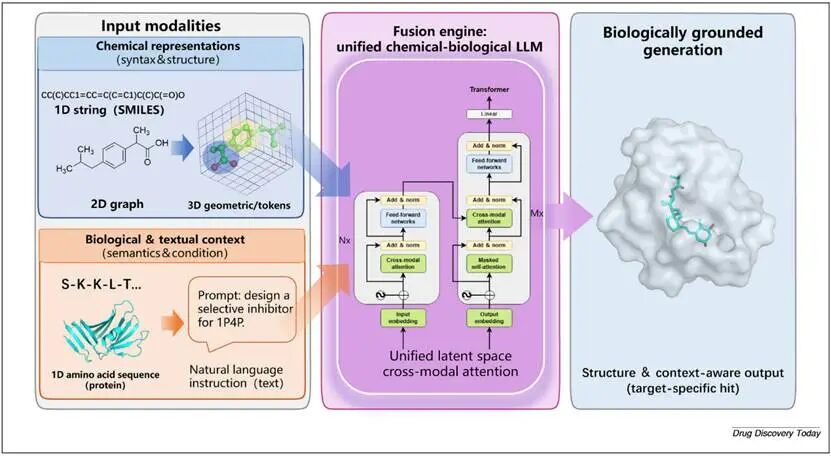
图2 多模态表示体系,从1D序列、2D图结构到3D几何信息,并结合蛋白序列与文本知识,在统一模型中实现融合。
基于序列属性驱动设计
在分子设计的早期阶段,大语言模型主要依赖序列信息(如SMILES或SELFIES)进行分子生成与优化。这种“序列驱动”的设计范式本质上是将分子看作一种语言,通过学习其语法规则与统计分布来生成新结构。随着模型规模扩大与训练策略改进,这类方法逐渐从简单的随机生成转向“可控生成”,即通过提示词或条件输入对分子属性进行精细调控。
在这一框架下,研究者可以通过自然语言或结构化指令直接指定目标性质,例如“提高水溶性”“降低脂溶性”或“避免心脏毒性”。模型在生成过程中将这些约束映射到潜在空间,从而生成符合要求的分子。这种能力显著降低了传统药物设计中依赖经验规则与反复试错的成本,使得分子优化从“人工调参”转向“语言驱动”。
进一步地,序列模型还可以结合外部评估工具形成反馈机制,例如通过对接评分、QSAR模型或ADMET预测结果,对生成分子进行实时筛选与再优化。这种闭环式优化使模型能够在多目标之间寻找平衡,例如在活性与溶解性之间进行权衡。然而,由于序列表示本身缺乏空间信息,这类方法在处理结构复杂或依赖三维构象的任务时仍存在局限。
结构感知的多模态架构
随着研究深入,单纯基于序列的建模逐渐难以满足药物设计对空间结构与生物语义的需求,多模态架构成为新的发展方向。这类方法通过融合化学结构、蛋白质信息以及文本知识,实现对分子行为的更全面理解。
在结构感知框架中,分子不再只是线性序列,而是以图结构甚至三维坐标形式参与建模。模型通过图神经网络或几何深度学习模块提取空间特征,再与语言模型的语义表示进行融合,从而在同一模型中同时处理“结构”和“语义”。这种融合带来的关键优势在于能够显式建模分子与蛋白口袋之间的空间匹配关系。模型不仅能够生成化学上合理的分子,还能考虑其是否能够“嵌入”目标蛋白的结合位点,从而提升设计结果的实际有效性。同时,多模态模型还可以整合生物医学文献中的知识,使分子设计具备更强的生物学解释能力。从发展趋势来看,这类架构正在向统一基础模型演进,即在一个模型中同时处理2D结构、3D构象、蛋白序列与文本信息。这种统一表示为复杂任务(如蛋白-配体共设计)提供了新的可能性。
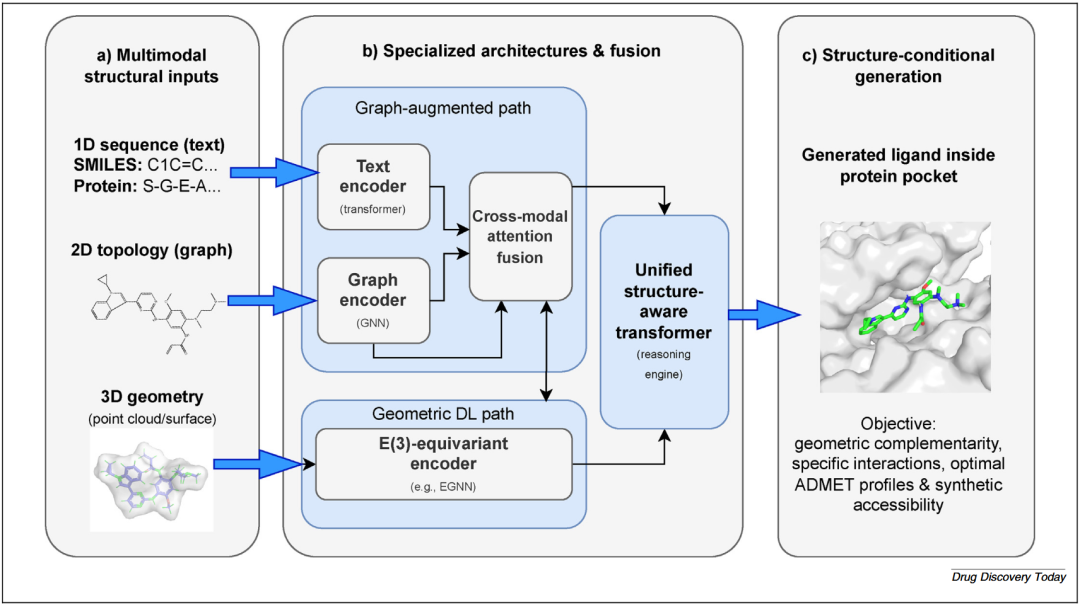
图3 结构感知框架,包括多模态输入(序列、图结构、3D坐标)、融合架构(GNN与Transformer结合)以及结构条件生成(针对蛋白口袋设计配体)。
通过自动化智能体实现闭环发现
大语言模型的真正潜力不仅体现在生成能力上,更体现在其作为智能体参与完整科研流程的能力。在药物研发中,这种能力体现为对设计-合成-测试-分析(DMTA)全过程的自动化控制。
在这一体系中,模型不再只是生成分子,而是作为决策核心,协调多个工具与模块完成复杂任务。例如,在设计阶段生成候选分子后,模型可以自动调用分子对接程序评估结合能力,再通过毒性预测模型筛选安全性,随后根据结果调整设计策略。更进一步,模型还可以参与逆合成规划,将目标分子转化为可执行的化学反应路径,并生成实验控制代码,实现与自动化实验设备的联动。这种从“虚拟设计”到“真实实验”的贯通,使药物研发从传统的人机协作模式转向高度自动化的闭环系统。当实验结果反馈回模型后,系统能够基于真实数据进行迭代优化,从而逐步逼近最优分子。这种自我强化机制使得药物研发不再依赖线性流程,而成为一个动态、自适应的探索过程。
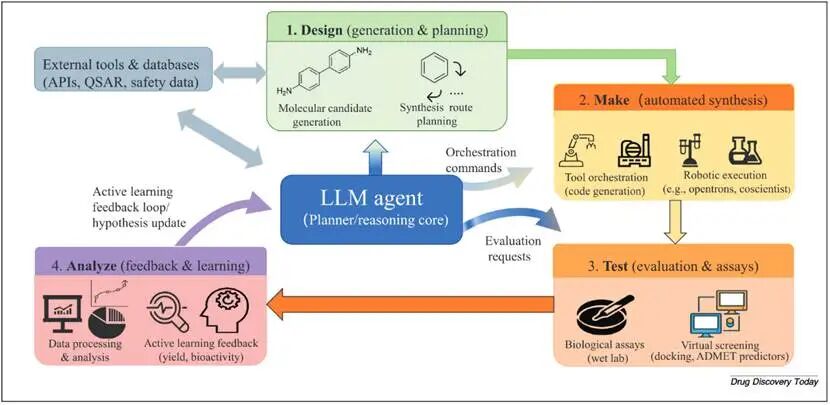
图4 完整DMTA(设计-合成-测试-分析)闭环,LLM作为核心控制器,实现从虚拟设计到真实实验的自动优化。
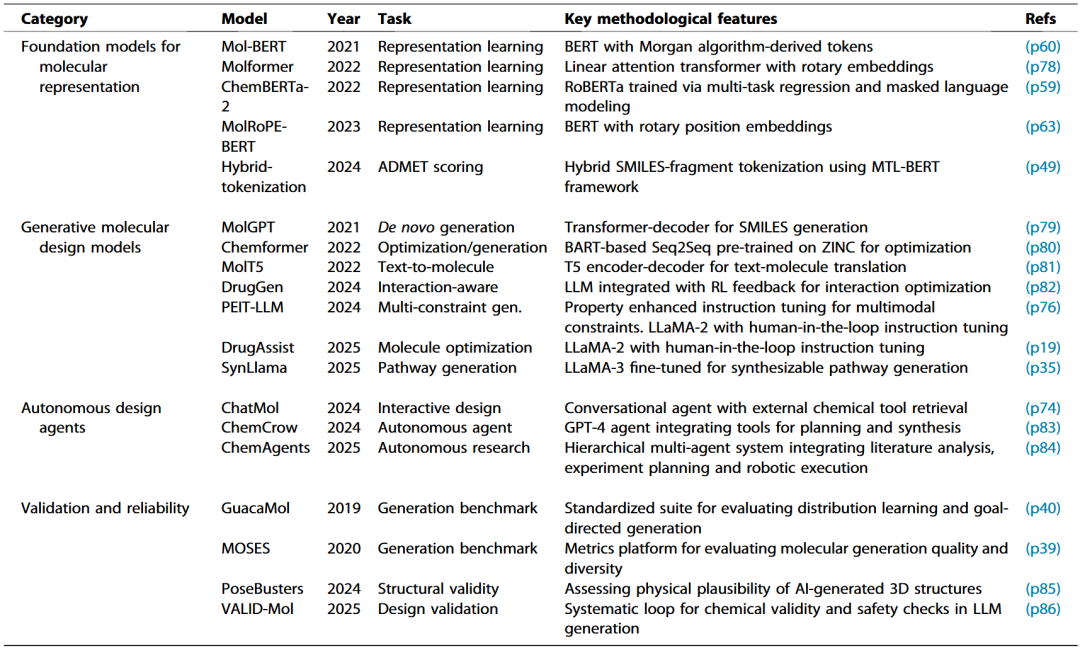
表1 当前主流模型与框架
评估指标
与自然语言任务不同,分子生成的评估涉及多个维度,且每一维度都直接影响其实际应用价值。传统评估通常从化学合法性出发,确保生成分子满足基本化学规则,例如价态正确、结构闭合等。在此基础上,新颖性与多样性成为衡量模型探索能力的重要指标。高新颖性意味着模型能够跳出训练数据的限制,而高多样性则有助于覆盖更广泛的化学空间,提高命中潜在候选分子的概率。
然而,仅依赖这些统计指标难以反映实际药物开发需求。更高层次的评估需要引入药物相关性质,如QED评分、logP、分子量及Lipinski规则等,以判断分子的“药物相似性”。对于结构驱动设计,还需要考虑结合能、构象合理性及空间匹配程度。
近年来,评估体系逐渐从单一指标转向综合评价框架,将化学可行性、生物活性与合成难度纳入统一体系。这种转变反映了从“生成好分子”到“生成可用药物”的目标升级。
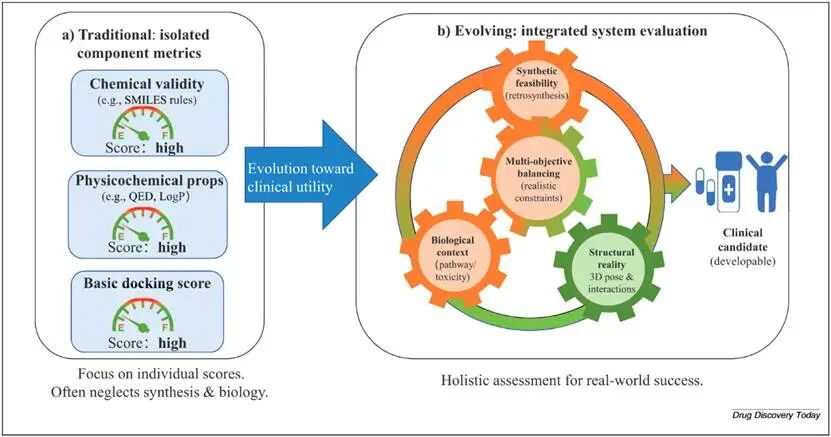
图5 从孤立指标评估向综合系统评估的转变,强调合成可行性、生物相关性与结构合理性的协同。
当前限制
尽管大语言模型在分子设计中展现出巨大潜力,但其在实际应用中仍面临多方面挑战。首先是化学合理性问题,即模型可能生成在语法上正确但在物理上不稳定或不可行的分子。这类“化学幻觉”在复杂结构中尤为常见。其次是合成可行性不足。许多生成分子虽然理论上合理,但在现实中缺乏可行的合成路径,或者需要极其复杂的反应条件,这限制了其实际价值。第三是生物语义理解不足。模型往往依赖数据驱动的统计关系,而缺乏对分子与生物系统之间因果机制的深入理解,导致在新靶点或复杂疾病场景中表现不稳定。此外,模型在三维空间建模方面仍存在明显短板。由于大多数LLM基于一维序列,其对空间结构、分子构象及相互作用的理解仍然有限。最后,评估与现实应用之间存在明显差距。模型在基准测试中表现优异,但在实验验证中成功率较低,表明当前评估体系尚未完全反映真实需求。同时,安全性与监管问题也逐渐凸显,包括潜在毒性分子生成与数据透明性不足等。
未来发展方向
面向未来,大语言模型在分子设计领域的发展将围绕“更真实、更可靠、更自动化”展开。首先,神经符号融合将成为重要方向,通过将化学规则与逻辑约束嵌入模型,减少生成错误并提高可解释性。这种方法有望从根本上解决化学幻觉问题。其次,多模态统一模型将进一步发展,将化学结构、蛋白信息与文本知识整合到同一框架中,从而实现真正的跨领域推理能力。这将显著提升模型在复杂生物系统中的泛化能力。在空间建模方面,引入物理约束与三维表示将成为关键。通过结合几何深度学习与扩散模型,未来系统有望直接在三维空间中生成分子,并准确预测其构象与相互作用。此外,检索增强生成技术将提高模型的知识利用能力,使其能够动态调用数据库与实验数据,从而提升设计结果的可靠性与可追溯性。最终,随着自动化实验平台的发展,闭环系统将成为主流。模型将不仅参与设计,还将直接驱动实验执行与结果分析,实现真正意义上的“自驱动实验室”。在这一模式下,药物研发将从依赖人工经验的过程,转变为数据与智能驱动的持续优化系统。
参考链接:
https://doi.org/10.1016/j.drudis.2026.104634
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢