

近年来,视觉生成模型(visual generation models)在照片级真实感、排版、指令跟踪和交互式编辑方面取得了显著进展,但在空间推理(spatial reasoning)、持久状态(persistent state)、长时程一致性(long-horizon consistency)和因果理解(causal understanding)方面仍存在不足。我们认为,该领域应超越外观合成,转向智能视觉生成(intelligent visual generation):基于结构(structure)、动态、领域知识和因果关系的逼真视觉效果。为了构建这一转变框架,我们引入了一个五级分类体系:原子生成(Atomic Generation)、条件生成(Conditional Generation)、上下文生成(In-Context Generation)、智能生成(Agentic Generation)和世界建模生成(World-Modeling Generation),从被动渲染器逐步发展到交互式、智能且感知世界的生成器。我们分析了关键的技术驱动因素,包括流程匹配、统一的理解与生成模型、改进的视觉表征、训练后处理、奖励建模、数据管理、合成数据提炼和采样加速。我们进一步指出,当前的评估方法往往过分强调感知质量,而忽略了结构、时间以及因果关系方面的缺陷,从而高估了进展。通过结合基准审查、实际压力测试和专家约束案例研究,该路线图提供了一个以能力为中心的视角,用于理解、评估和推进下一代智能视觉生成系统。

论文:Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling Quantification
单位:清华、南洋理工、港大、新加披国立、滑铁卢大学、StepFun、MiroMind、百度、复旦、香港科大、港科广、LMMs-Lab
发布日期:2026年2月
https://github.com/EvolvingLMMs-Lab/Evolving-Visual-Generation
请索引第87篇论文
 |  |
告别“唯美主义”:视觉生成如何迈向真正的“智能时代”?
如果理查德·费曼所说的“我不能创造的,我也不理解”是正确的,那么当前最顶尖的AI绘画模型,究竟是真的“理解了”这个世界,还是仅仅在进行一场高级的“像素级cosplay”?
过去三年,我们见证了文生图模型(如Stable Diffusion、FLUX、GPT-Image等)在画质、审美和指令遵循上的狂飙突进。只要提示词够好,它们就能画出媲美摄影大师的作品。然而,在这片虚假的繁荣之下,隐藏着一个尴尬的现实:现有的模型本质上只是“被动的渲染器”。
它们虽然能创造出惊艳的视觉效果,却在面对简单的拼图复原、多轮身份保持、流体物理规律时频频“翻车”。这不禁让人发问:视觉生成的下一个突破口到底在哪里?
近日,由清华大学、南洋理工大学、香港大学等多家顶尖机构联合发表的重磅综述《Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling》(2026年2月),为这个困局提供了一份极具前瞻性的答卷。这篇论文没有停留在对现有技术的罗列,而是直接抛出了一套颠覆性的“视觉智能五级分类法”,宣告了视觉生成“唯美主义”时代的终结,“智能主义”时代的正式到来。
今天,我们就来为大家深度硬核解读这篇路线图式的重磅论文,看看学界大牛们是如何规划下一代视觉生成系统的!
01 核心理论创新:如何衡量一个AI的“视觉智商”?
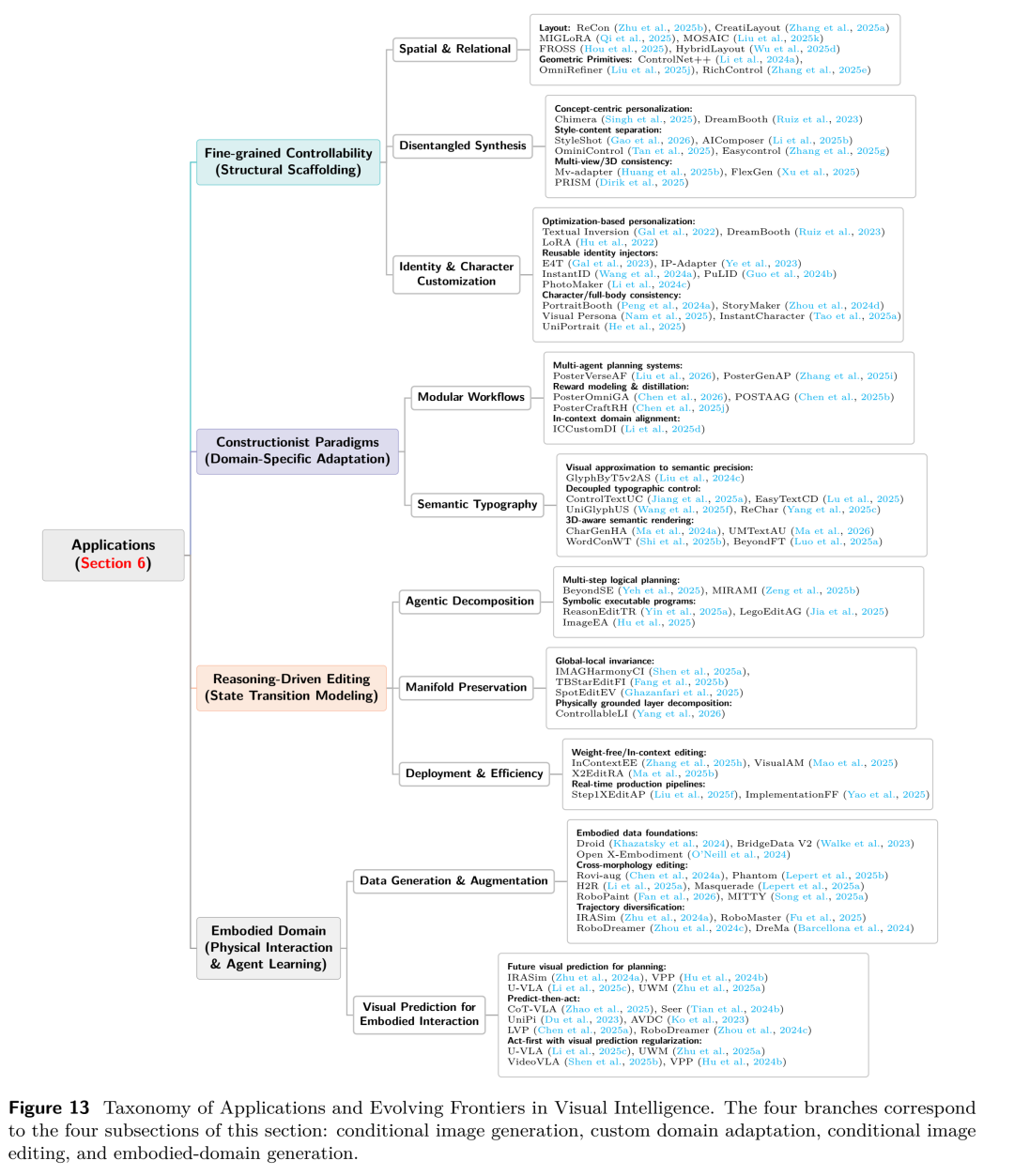
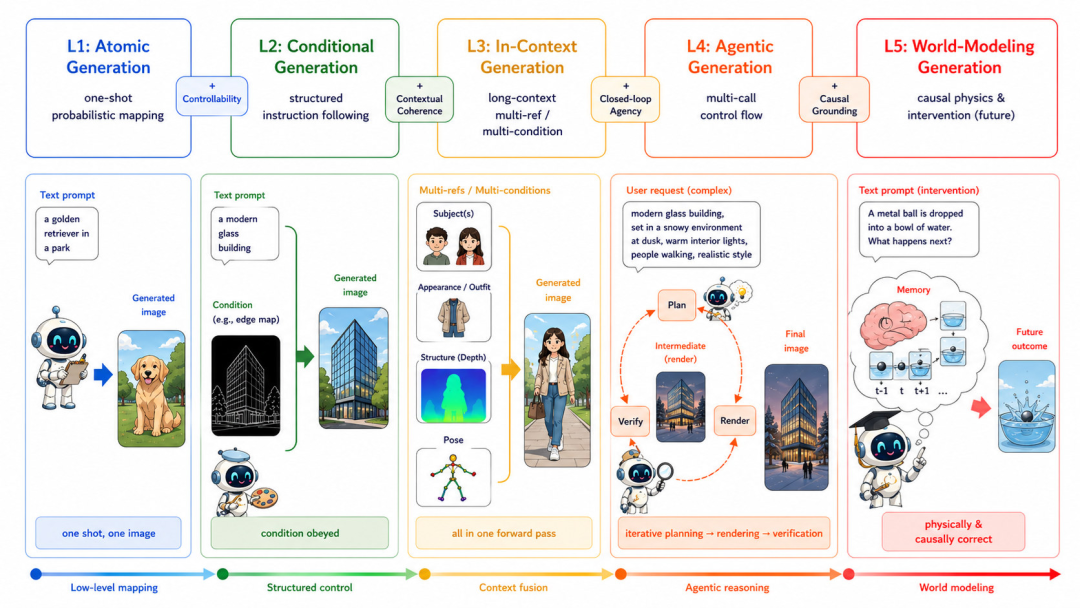
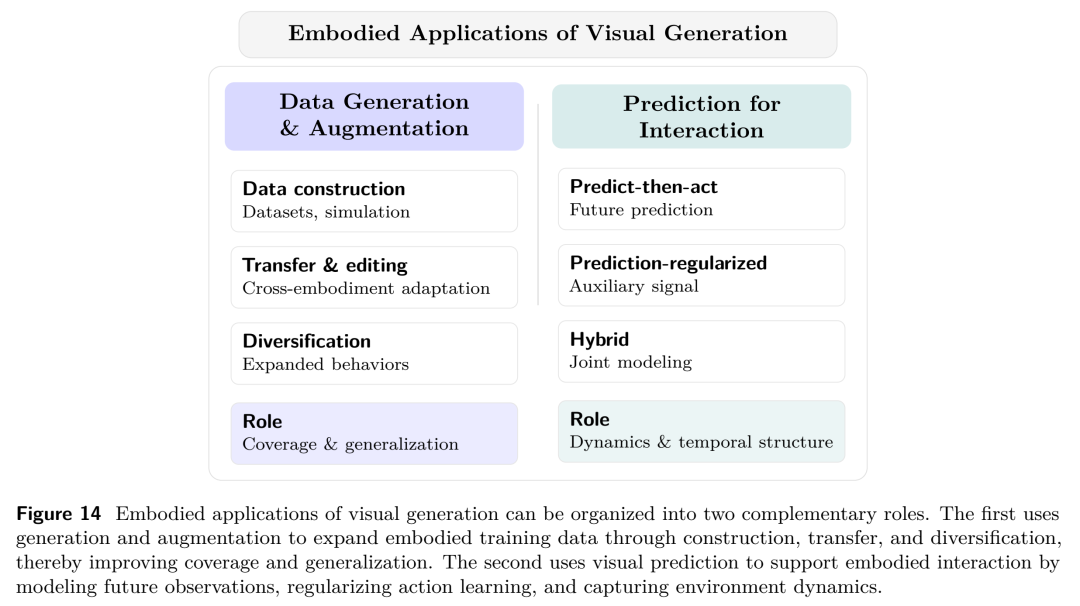
如果我们不能量化一个模型的“智能”,就无法指引它进化。论文最核心的贡献之一,就是借鉴了自动驾驶和AGI的发展思路,提出了视觉生成能力的五级分类法(L1-L5)。这不仅是技术的分级,更是模型认知能力的跃升。
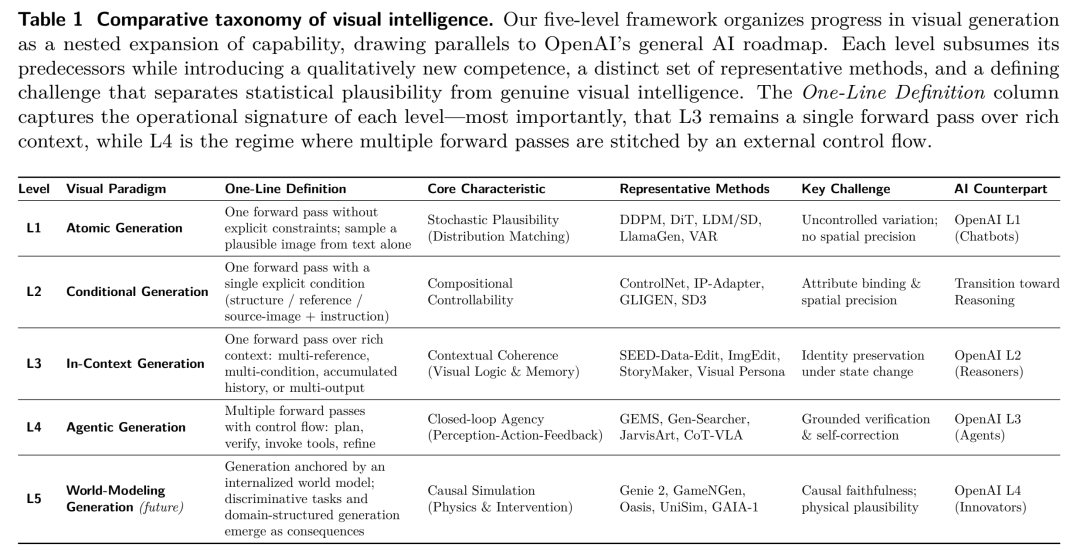
论文提出的视觉智能五级分类法。清晰地展示了从L1到L5,模型在输入复杂度、记忆机制、交互方式和核心能力上的质的飞跃。
让我们沿着这座金字塔,一层层揭开视觉智能进化的神秘面纱:
🟢 L1:原子生成 (Atomic Generation) —— “凭空捏造的盲盒”
特征:最基础的文本到图像映射(如早期的DALL-E 1、GAN)。
局限:模型只是在做统计分布上的曲线拟合。你永远无法精确控制画面中物体的空间位置和属性绑定。就像一个盲盒,看起来很美,但不受控制。
🟡 L2:条件生成 (Conditional Generation) —— “带着镣铐跳舞”
特征:引入了深度图、边缘线、姿态或身份特征等显式约束(代表技术:ControlNet、IP-Adapter)。
局限:虽然实现了初步的可控性,但每一次生成依然是孤立的“单次交易”,模型无法在多次生成间保持状态的连贯性。
🟠 L3:语境生成 (In-Context Generation) —— “有了短期记忆的画师”
特征:单次推理中可以吸收丰富的上下文,如多参考图或累积的编辑历史。代表技术如多轮对话式编辑(SEED-Data-Edit)和故事绘本生成(StoryMaker)。
局限:尽管能处理多轮输入,但它依然是没有外部控制器的“单体模型”,随着编辑轮次的增加,极易出现“静默漂移”(Silent Drift),导致早期设定好的特征发生不可控的衰减。
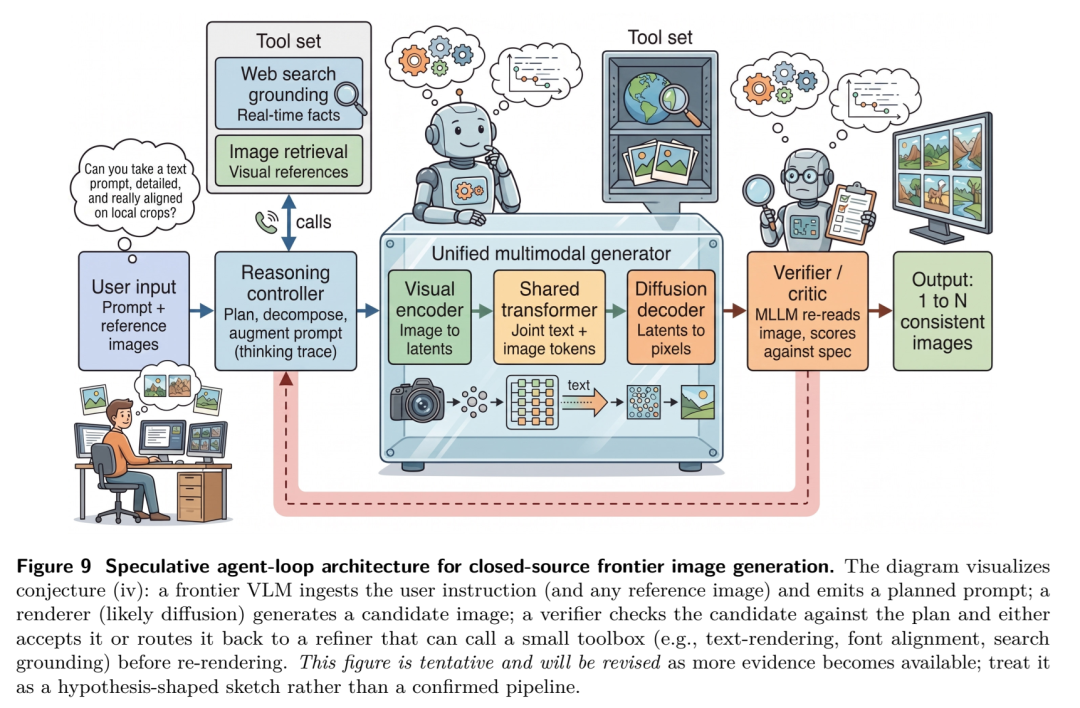
🔴 L4:代理生成 (Agentic Generation) —— “指哪打哪的视觉特工”(当前前沿)
特征:生成不再是终点,而是“感知-决策-执行-验证”闭环中的一环。
突破:模型配备了外部控制器(Planner/Verifier),能够自主调用工具、进行自我修正。它不仅能画画,还能通过“视觉思维链”(Visual CoT)在脑海里先规划再下笔。
⚫ L5:世界建模生成 (World-Modeling Generation) —— “造物主级别的模拟器”(终极目标)
特征:生成模型完全内化了物理定律和因果逻辑。
突破:这是一个可交互、可预测的终极世界模拟器。你告诉它“把铁球扔进水里”,它不仅能画出涟漪,还能精确计算出铁球下沉的轨迹和浮力变化。
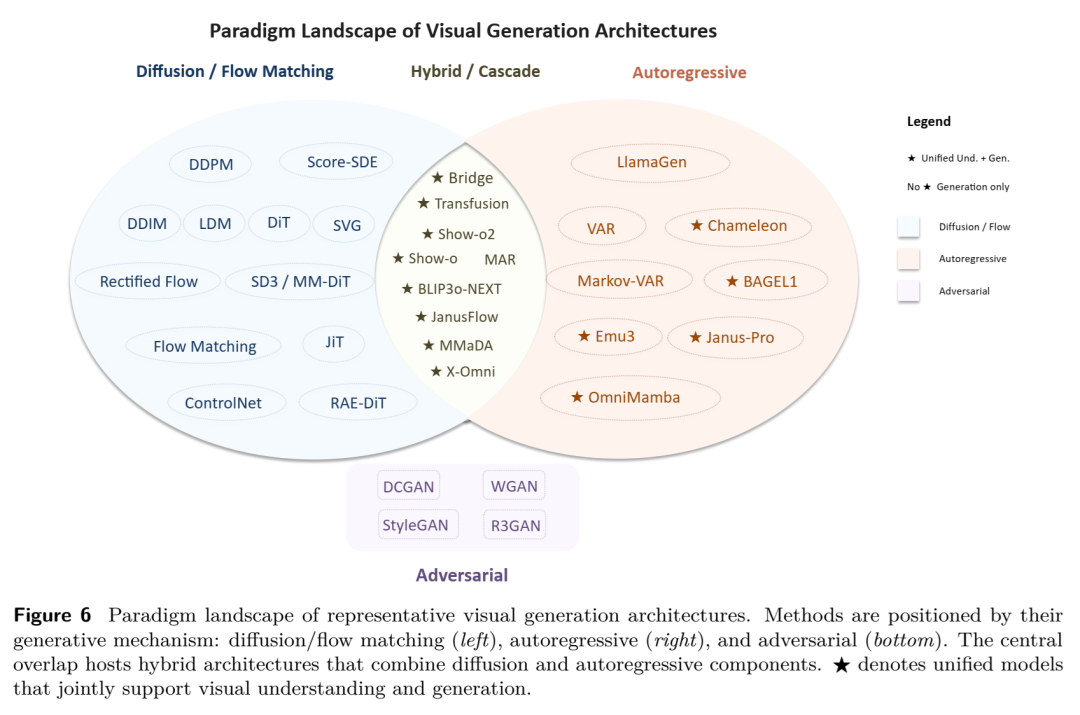
02 揭穿皇帝的新衣:为什么现在的SOTA模型依然“很笨”?
在读到L4和L5时,你可能会反驳:“不对啊,现在的GPT-Image和Nano Banana明明已经很强了,不仅能精准改图,还能保持极高的美学质感。”
这篇论文最犀利的地方,在于它没有看这些模型“平均分”有多高,而是通过一系列极端的“野外压力测试(In-the-Wild Stress Tests)”,精准地戳中了它们的死穴。
论文中对现有模型进行的多维度压力测试框架(Dimension I - VIII)。为了探究模型真正的能力边界,作者设计了从空间结构、物理推理到多轮编辑等八大维度的极端拷问。
以下是论文中几个堪称“降维打击”的测试用例:
空间逻辑的彻底溃败(拼图与地铁路线图)
当要求模型复原一张被打乱的几何拼图时,即便是当前最强的模型,也会为了迎合整体的“语义合理性”而牺牲局部的“几何刚性”,产生严重的视觉幻觉。在生成复杂的地铁路线图时,模型更是无法理解拓扑结构,频繁出现逻辑断裂。
物理因果的“无知”(浮力与流体实验)
在动作条件的视频生成中,如果要求模型生成“把一个原本漂浮的木头换成铁块”,画面虽然依然高清,但铁块在水面上的碰撞反应依然像木头一样。模型懂画面,但不懂牛顿力学。
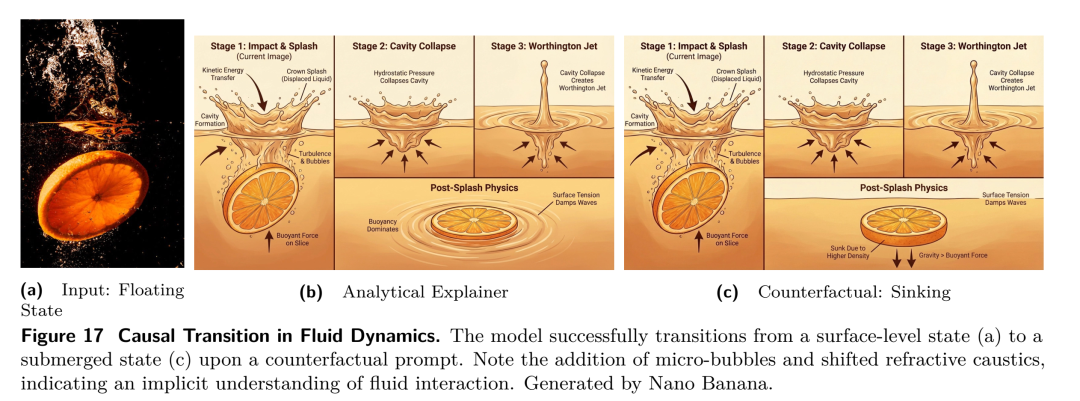
多轮编辑的“静默漂移”(累计退化)
在对一张图片进行长达5轮的精细化编辑后(比如不断更换背景、微调发色),模型的输出质量会发生断崖式下跌,最初锁定的身份特征(Identity)也会悄然改变。
这些测试残酷地证明了一点:目前我们引以为傲的SOTA模型,大多还徘徊在L2到L3的边缘。它们只是统计学上的“概率缝合怪”,远未达到结构化和因果化的“视觉智能”。
03 破局之道:通往L5的“四大技术引擎”
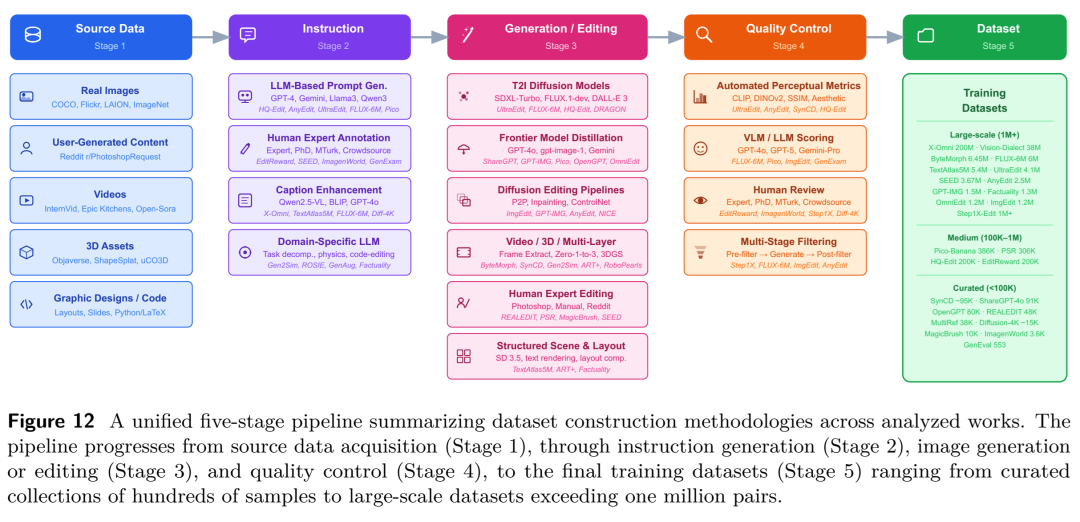
既然发现了病根,该如何对症下药?论文在梳理了400多篇前沿文献后,归纳出了推动视觉生成向“智能主义”演进的四大核心驱动力:
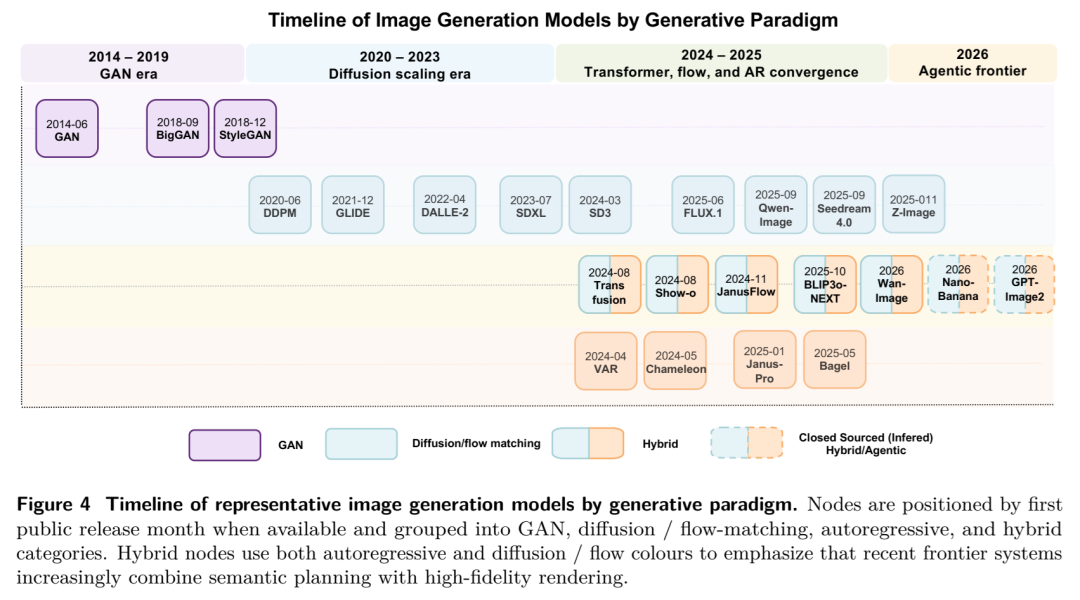
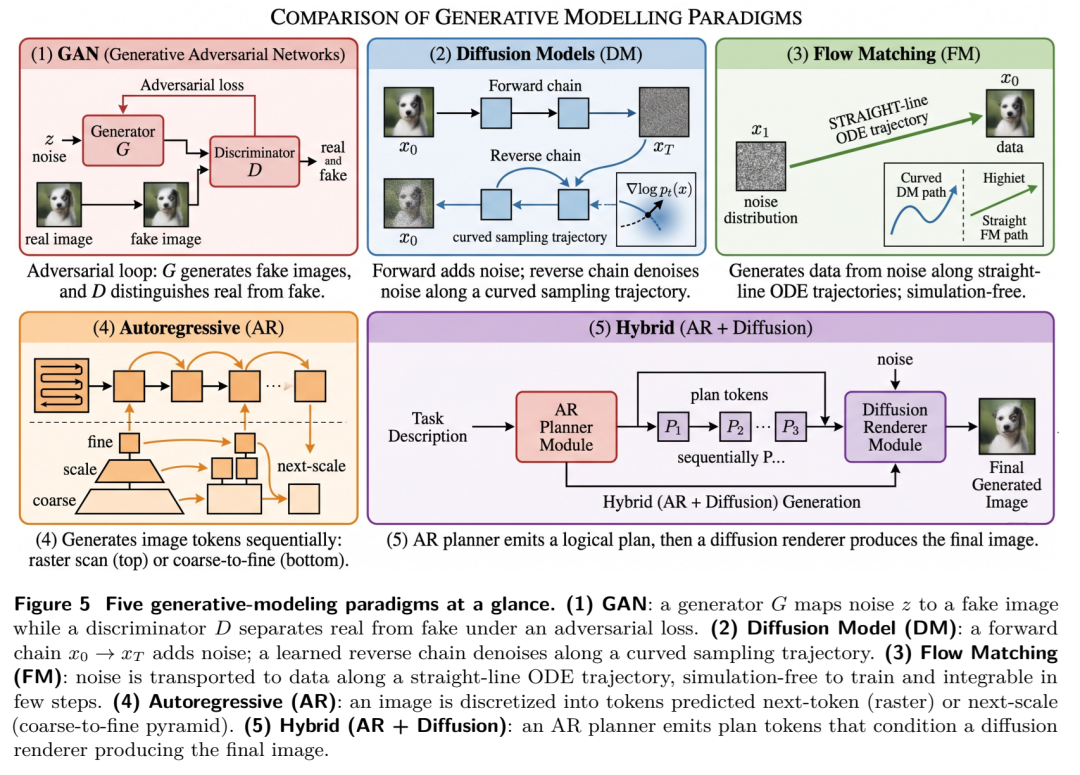
范式的洗牌:从扩散(Diffusion)到流匹配(Flow Matching)
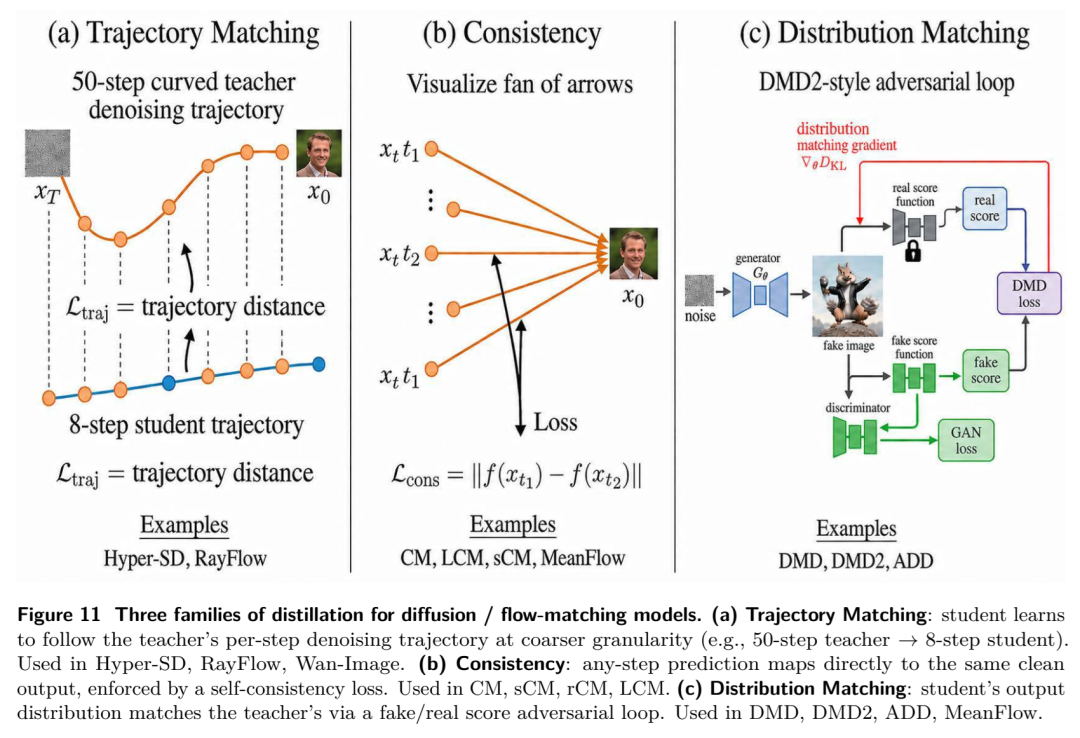
传统的扩散模型就像是在迷雾中一点点摸索出图像,步数多且速度慢。而流匹配技术(如SD3、FLUX所采用的Rectified Flow)通过在噪声和数据点之间建立直接的直线连接,不仅训练更稳,推理步数更少,更为构建大规模Transformer原生的生成器铺平了道路。
架构的统一:理解与生成的“双修”
过去,我们看到的图像生成模型(如SD)和图像理解模型(如LLaVA)是割裂的。如今的趋势是将它们统一在同一个多模态空间中(如X-Omni、BLIP3o等)。“看”与“画”不应分离,只有让模型在生成像素的同时进行语义推理,才能从根本上提升其逻辑对齐能力。
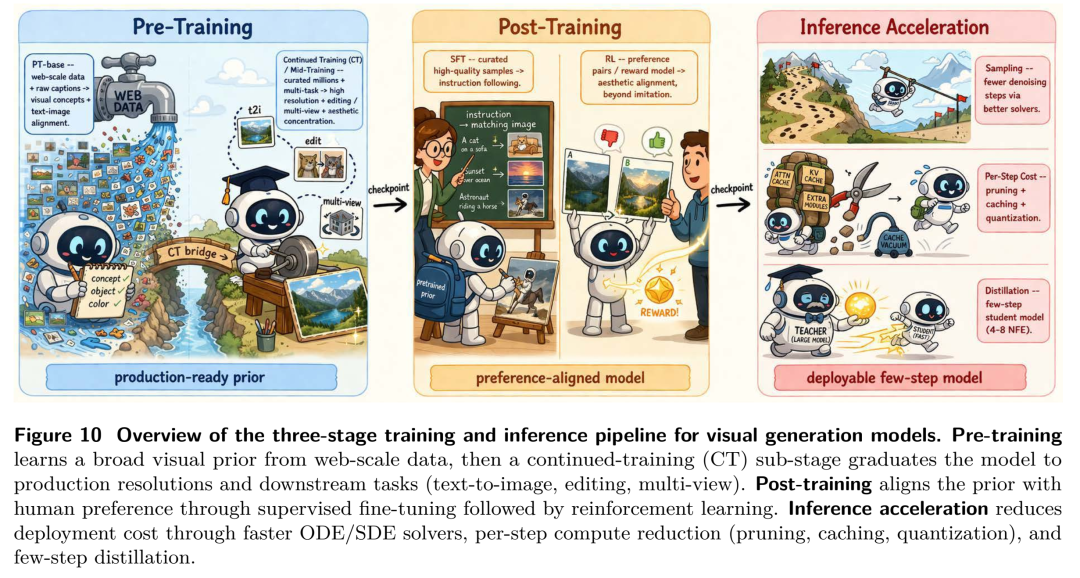
训练的转型:后训练(Post-training)的崛起
堆参数已经进入了边际效应递减的死胡同。现在的决胜局在精细化数据策展、基于人类偏好的对齐(如DPO/GRPO算法)以及奖励模型(Reward Modeling)。说白了,就是要让模型学会“什么是人类真正想要的逻辑”,而不是一味地拟合训练数据。
评估的革命:从“看脸”到“验逻辑”
传统的FID、CLIP分数只会“看脸”,导致很多画质平庸但逻辑严密的模型被埋没。学界正在转向使用强大的视觉语言模型(VLM)作为评判员(VLM-as-a-Judge),对生成结果的指令遵循度、属性绑定进行细粒度的“逻辑审查”。
04 科研启示录:这片新蓝海给我们留下了哪些机会?
对于奋斗在科研一线的本硕博学生们来说,这篇路线图不仅是一篇综述,更是一份寻宝图。它明确地指出了当前领域内的几个高价值洼地:
告别“刷点”,去啃“多模态推理”的硬骨头。
如果你的研究还在纠结如何用更复杂的模块组合来提升0.5个FID分数,那可能要走入死胡同了。未来的爆款论文,一定会聚焦于如何解决模型的空间拓扑推理、物理常识注入以及长程状态一致性。
关注“视觉思维链”(Visual CoT)与工具调用。
让模型学会在生成图像前,先在隐空间中用文本或草图进行多步规划(Thinking Before Rendering),或者让模型学会自主调用外部的物理引擎(如Blender)来辅助验证生成结果,这都是极具潜力的新兴方向。
投身“世界模型”(World Models)的构建。
无论是用于具身智能(Embodied AI)的机器人训练,还是可玩的开放世界游戏引擎,能够从单帧图片演进到4D时空联合建模的“神经引擎”,将是未来几年学术界和工业界争夺的绝对高地。
05 结语
正如这篇论文所言:“我们不能创造的,我们也并不理解。” 当AI能够真正理解重力、因果和空间,并能够将这些知识应用到每一次像素的渲染中时,真正的通用人工智能(AGI)或许就已经在我们眼前了。
视觉生成的下半场,不属于那些只会调色画画的“画师”,而属于那些能够构建世界、推演逻辑的“造物主”。你,准备好入场了吗?






内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢