

据劳伦斯伯克利国家实验室估计,由于人工智能的爆炸式增长,到 2028 年,数据中心将消耗美国总用电量的 12%。作为 AI 工作负载的主要加速器,图形处理器(GPU)已成为功耗的主要来源,其热设计功耗(TDP)在最新的 NVIDIA H100 和 GB200 中分别达到 700W 和 1200W。在能源挑战日益严峻的背景下,针对 AI 工作负载快速估计 GPU 的功率与能耗变得至关重要。
功耗模型通常需要硬件利用率信息作为输入,用以表征 GPU 各模块(如 DRAM、Tensor Core)的使用强度,因为动态功耗与模块活动程度成正比。现有方法主要通过两种途径获取这些信息:其一是指令级仿真器,通过逐周期模拟 GPU 执行来推导模块利用率,但即使对于中等规模工作负载,这种精细仿真也需要数小时;其二是运行时性能分析(profiling),但这不仅带来较高的分析开销,还依赖可用的硬件资源。
这一背景下,来自 MIT 和 MIT-IBM 沃森人工智能实验室的研究人员构建了一个面向 AI 工作负载的快速 GPU 功耗估计框架 EnergAIzer,可在无需昂贵仿真或性能分析的情况下,直接为功耗模型提供硬件利用率信息。该新框架平均仅需 1.8 秒即可完成端到端功耗估计,在 NVIDIA Ampere GPU 上,EnergAIzer 实现了约 8% 的功耗误差,与依赖复杂周期级仿真或硬件性能分析的传统模型具有竞争力。
研究人员还展示了 EnergAIzer 在频率扩展与架构配置探索方面的能力,包括对 NVIDIA H100 功耗的预测,其误差仅为 7%。总体而言,EnergAIzer 为 AI 工作负载提供了快速且准确的功耗预测能力,数据中心运营商可以利用这些估算结果,在多个人工智能模型和处理器之间有效地分配有限的资源,从而提高能源效率。
相关研究成果以「EnergAIzer: Fast and Accurate GPU Power Estimation Framework for AI Workloads」为题,已发布预印本于 arXiv。
研究亮点:
* 借助新框架只需几秒钟即可生成可靠的功耗估算值,而传统的建模技术则可能需要数小时甚至数天才能得出结果
* 新预测工具可应用于各种硬件配置,甚至包括尚未部署的新兴设计
* 该工具可以帮助算法开发者和模型提供商在部署新模型之前评估其潜在的能耗

论文地址:
https://arxiv.org/abs/2604.20105
数据集:覆盖多种主流算子类型与张量形状
在所有实验中,研究人员均基于 NVIDIA A100-40GB-PCIE 与 A10 GPU 构建离线内核数据库,覆盖多种主流算子类型与张量形状,用于训练 EnergAIzer,详见下表:
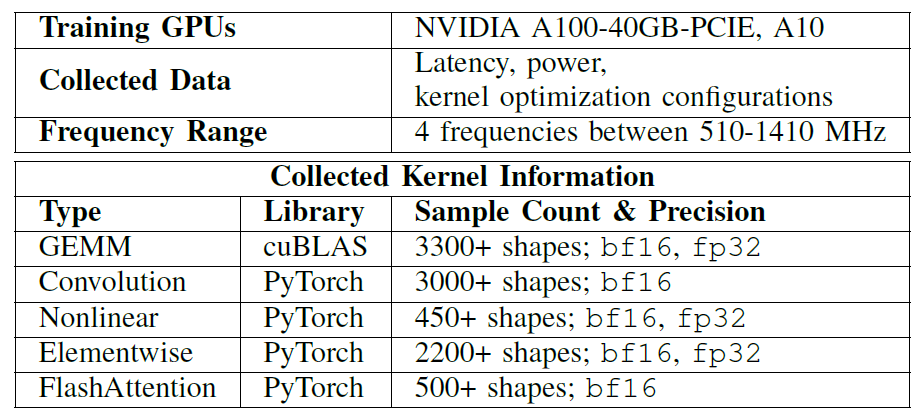
用于实验的离线数据库
包括:
* GEMM类矩阵计算
* Convolution
* Nonlinear
* Elementwise
* FlashAttention
研究人员提供了 EnergAIzer 的实验资源,包括估计框架的源代码、用于经验拟合的预先收集数据库,以及用于验证预测结果的真实测量数据,其资源包含用于复现实验的脚本,可生成单个内核级功耗与延迟估计结果,以及 AI 工作负载的端到端估计结果。
三大步骤构建 EnergAIzer 内核级预测模型
ENERGAIZER 的核心是一个内核级预测模型,研究人员通过三个步骤构建该模型。首先,建立工作负载表示,诸如分块(tiling)、线程块调度和流水线等软件优化策略,会形成结构化的执行模式,这些模式构成性能模型的基础;其次,构建性能模型,以这些模式为支架进行经验数据拟合;最后,功耗模型利用预测得到的利用率来估计动态功耗。
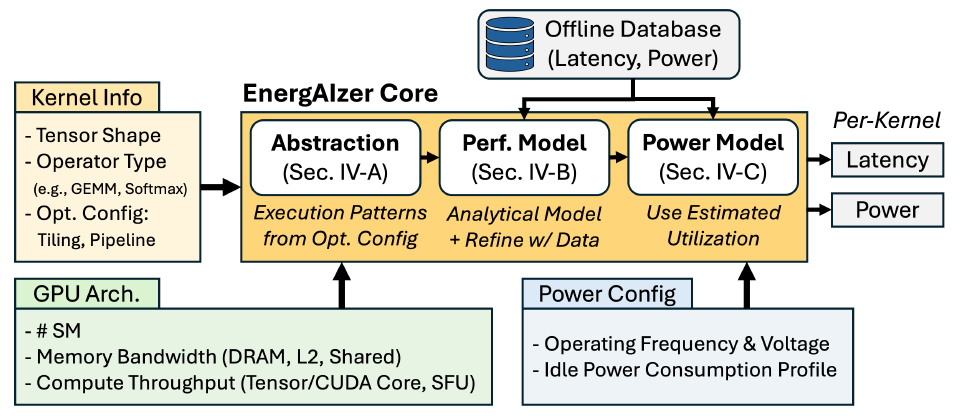
EnergAIzer 的内核级预测框架概览
工作负载结构建模层
优化策略
张量在 GPU 执行的各个层级上被分层划分为数据块(tile)。线程块重排(threadblock swizzling)会将访问相同输入 tile 的线程块调度到相邻的 SM 上,从而提升 L2 缓存复用率;软件流水线(software pipelining)则在时间迭代中将数据传输与计算重叠。流水线结构决定了可暴露的延迟,这是性能建模中的关键因素。
超越 GEMM
在此基础上,研究人员系统性地将分析扩展至 AI 中所有主流内核类型(包括非线性、逐元素以及融合内核),目标是推导模块级利用率以服务功耗建模。
验证
通过分析方法,研究人员推导了共享内存、L2 缓存和 DRAM 的总加载流量,并与 NVIDIA A100-40GB-PCIE GPU 上通过 NCU 性能分析获得的硬件计数器数据进行对比。在超过 790 个 GEMM 内核、70 个 Softmax 内核以及 380 多个 FlashAttention 内核上,均观察到接近完美的相关性,从而验证了分块参数与理想线程块重排能够决定内存流量。
性能模型层
时间线构建
性能模型构建了一个由粗粒度操作组成的执行时间线,其中分块(tiling)决定操作的粒度(例如数据加载/存储量、计算指令数量),而 pipelining 则根据依赖关系决定这些操作的重叠方式。该时间线构成了分析支架,并用于揭示模块级利用率,如下图 :
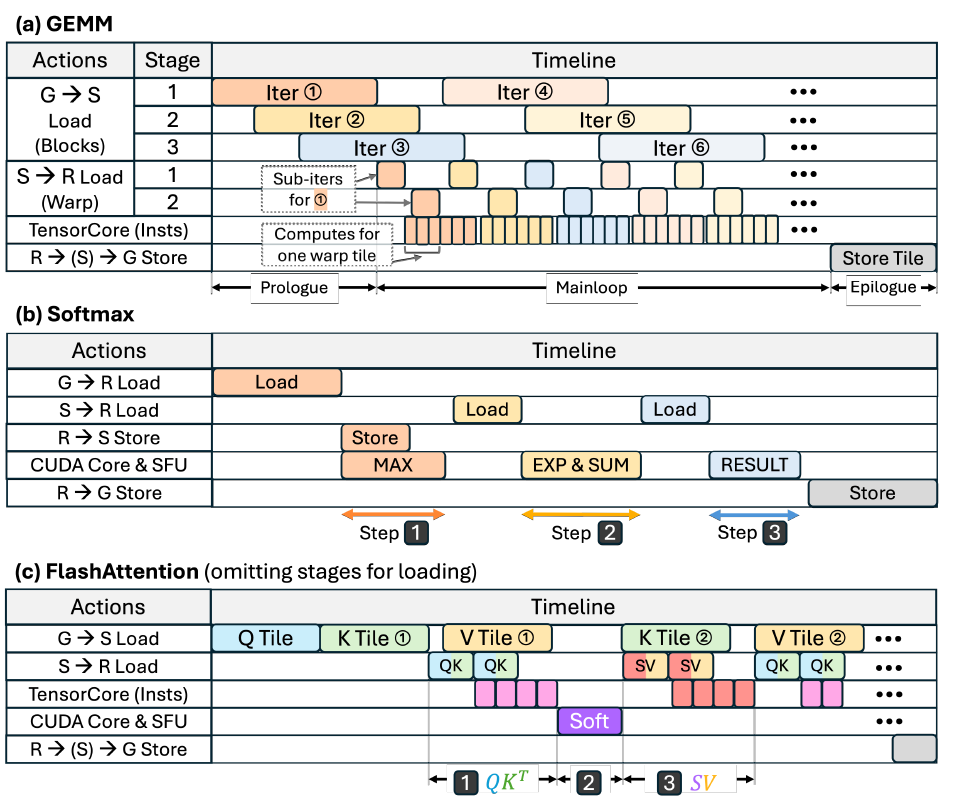
(a)GEMM,(b)Softmax,以及(c)FlashAttention 内核的时间线示意图
延迟预测
在建立时间线结构后,描述如何计算各操作的延迟;随后,这些单个操作的延迟被组合成整体执行时间,并体现流水线的影响。
利用率推导
基于构建的时间线,提取六类关键模块的利用率:DRAM、L2 cache、共享内存、Tensor Core、CUDA Core(用于常规浮点运算)以及 Special Function Unit(用于指数及其他非线性函数)。对于每个模块,其利用率定义为该模块活跃时间占总内核执行时间的比例。
功耗模型层
基于性能模型得到的模块级利用率,研究人员使用标准动态功耗公式进行估计。该方法在形式上与传统功耗建模一致,但关键区别在于利用率 α 的获取方式不同。由于离线数据库覆盖多个运行频率下的功耗测量数据,通过拟合 C 系数使其在整个频率范围内误差最小,从而支持在推理阶段无需额外测量即可在任意频率下进行功耗估计。
平均每个工作负载仅需 1.8 秒即可完成延迟与功耗联合估计
研究人员通过实验评估了 EnergAIzer 的预测能力及其在探索多种设计选择中的应用:
AI 工作负载的延迟与功耗估计精度
下图展示了在多种语言模型(BERT-Large、GPT-2、OPT-1.3B、Qwen2-1.5B)以及视觉模型(ResNet101、ViT、MobileViT)上的端到端延迟与功耗估计结果:
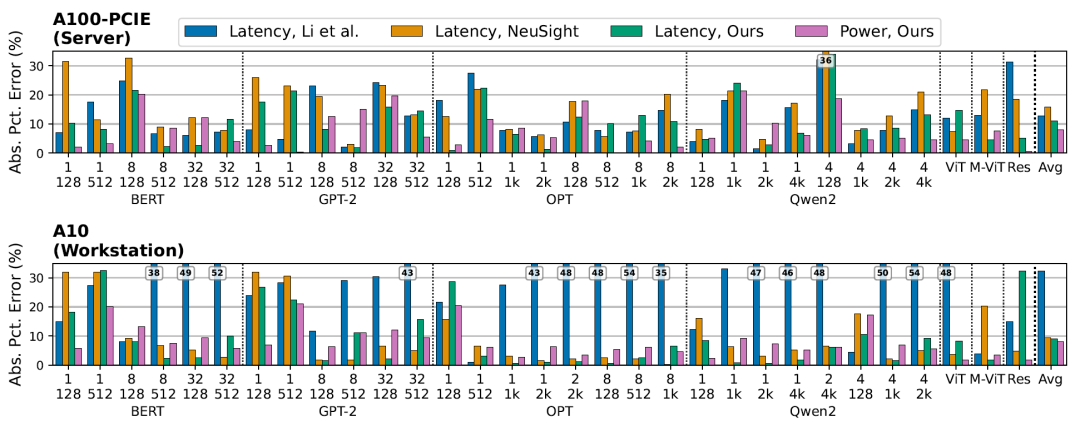
在 NVIDIA A100-40GB-PCIE 与 A10 GPU 上的端到端延迟与功耗估计误差,运行频率为 900 MHz
EnergAIzer 在服务器级 GPU(A100-40GB-PCIE)上实现了平均 11.0% 的延迟误差与 8.0% 的功耗误差,在工作站级 GPU(A10)上分别为 8.8% 与 8.2%。这些结果均在所有工作负载上取平均。在延迟预测方面,EnergAIzer 与最先进的轻量级性能模型(Li et al.、NeuSight)相比具有竞争力,同时还额外提供了这些模型无法提供的功耗估计能力。
EnergAIzer 平均每个工作负载仅需 1.8 秒即可完成延迟与功耗联合估计。对于语言模型,单次预测耗时在 1.1–2.8 秒之间。相比之下,使用 NCU 进行硬件计数器采集需要 452 至 8192 秒,因此实现了 317× 到 3856× 的加速。
探索电压-频率调节
电压-频率调节是一种常用的能耗管理技术,它可以从跨不同运行点的精确功耗预测中受益。研究人员评估了 EnergAIzer 在 A100-40GB-PCIE 上对不同频率(510–1410 MHz)功耗的估计能力。在实验中仅调整 EnergAIzer 的功耗配置输入参数,包括目标频率、电压以及该频率下的空闲功耗,下图展示了真实测量值与预测功耗的对比结果:
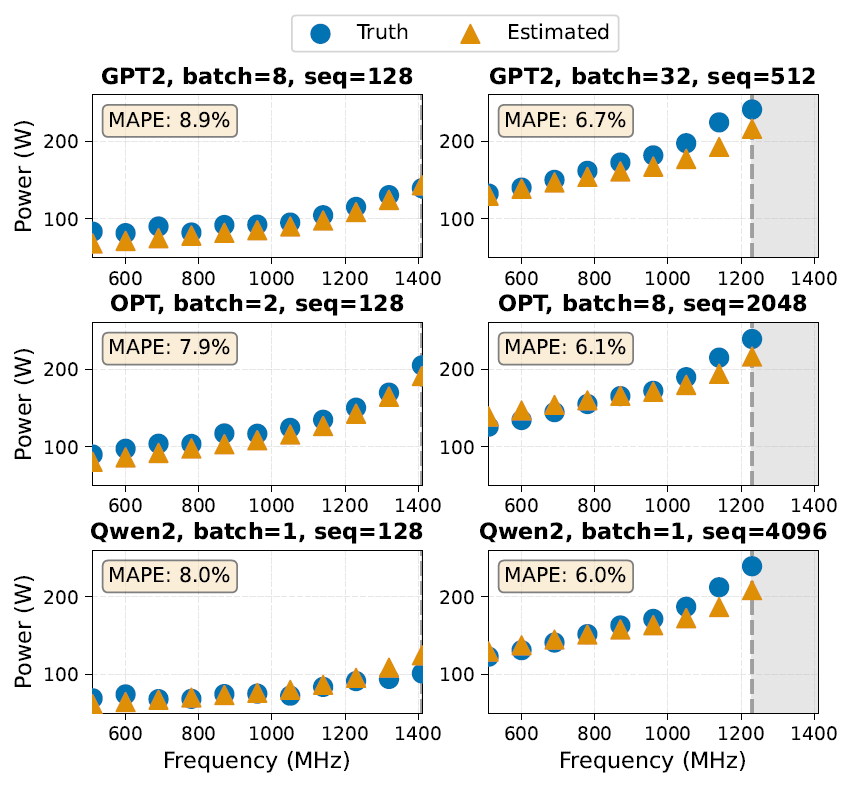
在 A100-40GB-PCIE 上,频率范围 510–1410 MHz 内的功耗估计结果
EnergAIzer 框架能够捕捉不同负载类型的典型缩放行为:低利用率工作负载(小 batch/序列,左图)与功率受限工作负载(大 batch/序列,右图),在不同频率下的平均绝对百分比误差(MAPE)为 6%–9%。
探索 GPU 架构配置
本框架还支持通过调整 GPU 架构参数(如 SM 数量、内存带宽和计算吞吐量)作为输入,从而探索不同 GPU 架构配置。这使得在无需目标硬件数据采集的情况下,也能预测新架构的功耗。研究人员评估了两种场景:同一 GPU 架构世代内的探索,以及跨架构世代的探索,目标 GPU 配置总结见下表:
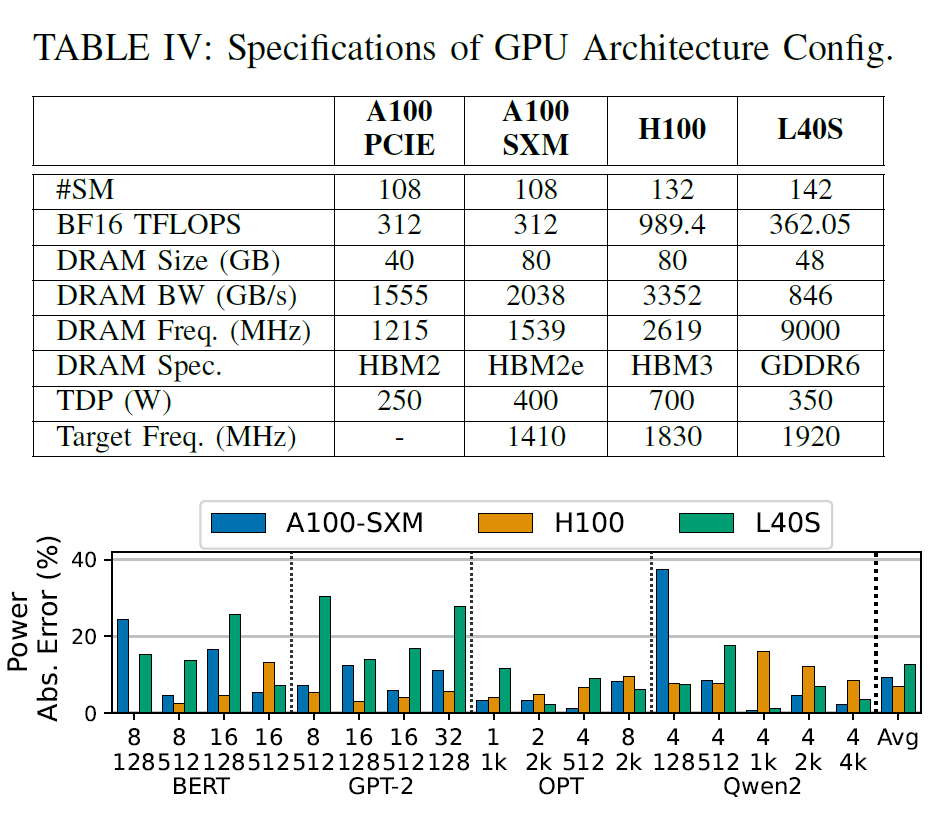
针对新 GPU 配置进行预测时的功耗估计误差
首先,在 Ampere 架构内部,研究人员仅使用从 A100-40GB-PCIE 收集的数据库来预测 A100-80GB-SXM 的功耗,平均误差为 9.1%;其次,在跨世代场景中,使用 Ampere 架构的数据库预测 Hopper(H100)与 Lovelace(L40S)的功耗,分别获得 6.7% 与 12.7% 的误差。
总体而言,EnergAIzer 为 AI 工作负载提供了快速且准确的功耗预测能力。
结语
对于数据中心运营者而言,EnergAIzer 可以快速评估不同 GPU 配置、频率策略以及资源调度方案的能耗表现,从而支持更精细化的资源编排与能效优化;对于 AI 模型开发者,这一框架则提供了一种新的“硬件感知”工具。在模型设计阶段,就可以评估不同精度、不同算子实现所带来的性能与功耗权衡,从而避免在部署阶段才暴露能耗问题。
当然,当前框架仍存在一定局限,例如对多 GPU 协同计算、通信开销以及非规则稀疏计算的建模能力仍有待增强。但从方法路径上看,EnergAIzer 已经展示出一种清晰趋势:GPU 功耗建模正在从“重度依赖测量”的离线分析工具,演进为“轻量级、可嵌入”的在线决策能力。在 AI 算力持续扩张、能耗约束日益收紧的背景下,这类技术的价值正在快速放大。未来,随着模型复杂度与硬件异构程度进一步提升,类似 EnergAIzer 的框架,很可能不再只是一个研究工具,而是成为 AI 基础设施中不可或缺的一部分。
参考文献
https://news.mit.edu/2026/faster-way-to-estimate-ai-power-consumption-0427
https://arxiv.org/pdf/2604.20105
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢