

目前,自主科学实验(autonomous scientific experimentation)的实现受限于LLM模型难以理解生物学实验方案(biological protocols)所需的严格程序逻辑和精确性。为了应对这一根本性挑战,我们提出了 BioProBench,一个用于生物学程序推理的综合资源。BioProBench 基于 BioProCorpus,这是一个包含 27,000 份人工编写的实验方案的基础数据集。我们基于该语料库系统地构建了一个包含超过 550,000 个任务实例的数据集,从而提供了一个大规模的训练资源和一个具有创新指标的严格基准。通过评估 10 种主流LLM模型,我们发现,尽管总体理解能力较高,但在需要深度推理、定量精确性和安全意识的任务上,性能会显著下降。为了展示 BioProCorpus 在缓解这些问题方面的价值,我们开发了 ProAgent。ProAgent 基于我们的语料库,显著提升了现有技术水平。 BioProBench 提供了一个严谨的诊断基准,并为开发下一代可靠的科学人工智能(scientific AI)提供了基础资源。

请索引第88篇论文
 |  |
实验总翻车?Nature子刊Protocol看不懂?大模型也救不了你!北大最新BioProBench无情扒下10大主流LLM的“底裤”
各位在实验室里“搬砖”的科研狗们,晚上好!👋
做湿实验的痛,谁懂?🤒
对着一篇《Nature Protocols》一步步往下做,结果要么试剂剂量没看清,要么两步顺序搞反了,最后得到的不是预期条带,而是一团“western blot 糊糊”。
于是,你想到了最近火遍全网的AI大模型,心想:“AI这么牛,能不能让它帮我读protocol,甚至直接指导我做实验?”
残酷的真相是:目前的主流大模型,在严谨的生物实验协议面前,大概率会带你走向“实验毁灭”的深渊。
为什么?因为大模型本质上是个“概率预测机”,它们擅长写诗、写公文、做摘要,但极度缺乏对严谨科学程序(Procedural Logic)的理解能力。
近日,北京大学团队联合多家机构,发布了一项重磅研究——BioProBench。这不仅是一个包含了近2.7万个真实生物协议、55万条结构化数据的大规模基准测试集(Benchmark),更是对目前市面上10款主流大模型在生物实验领域的一次“地毯式扒皮”。📊
今天,我们就来为大家深度硬核拆解这篇论文,看看大模型到底是怎么在生物协议上“翻车”的,以及这项研究将如何改变未来的自动化科学生态。👇
💣 痛点直击:为什么大模型搞不定生物Protocol?
很多同学可能会问:现在不是有很多Bio-medical的AI模型吗?比如BioBERT、BioGPT之类的。
确实,但这些传统模型和基准测试(如BioASQ、PubMedQA)大多只关注陈述性知识(比如根据文献回答某个基因的功能是什么)。它们根本不懂“操作”!
生物实验协议是高度结构化的、带有强因果约束的。一步错,步步错。以往的指标(比如BLEU、ROUGE)只能看出大模型生成的文本像不像人话,却看不出它有没有漏掉关键步骤,或者把离心转速搞错了一个数量级。
为了解决这个卡脖子问题,北大团队提出了BioProBench,其整体架构如下图所示,包含了一个庞大的底层语料库(BioProCorpus)和一个严密的多任务评测体系:
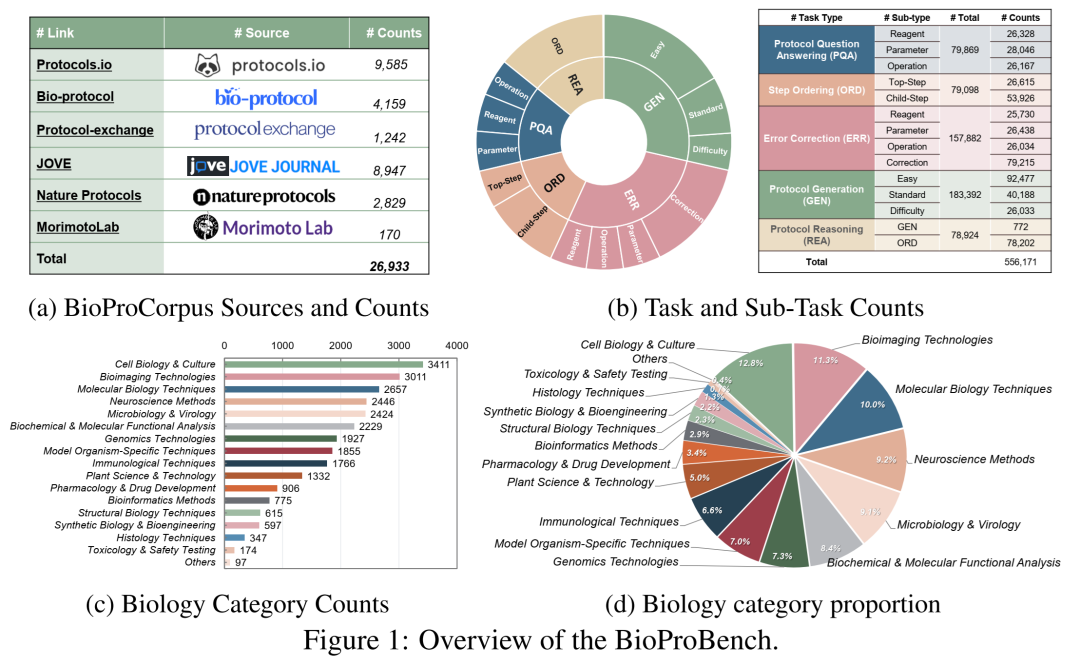
BioProBench 整体概览。它不仅汇聚了海量的人类专家级生物协议,还设计了多维度的任务和评估指标,专门用于拷问大模型的“实验操作智商”。
🧬 看点一:硬核“军火库”——BioProCorpus 是如何炼成的?
要考倒大模型,首先得有顶级的题库。
研究团队从 Bio-protocol、JOVE、Nature Protocols 等6个权威数据库中,疯狂抓取了 26,933 份全真实验协议,覆盖了基因组学、免疫学、合成生物学等16个主流生物子领域。
但这仅仅是原始数据。为了让机器能看懂,团队设计了一套精密的两阶段处理流水线(Pipeline):
清洗去噪:用正则表达式干掉HTML标签等脏数据。
层级化解构:保留协议原有的层级逻辑(比如大步骤1下面包含小步骤1.1、1.2),解析出标题、关键词和操作步骤。
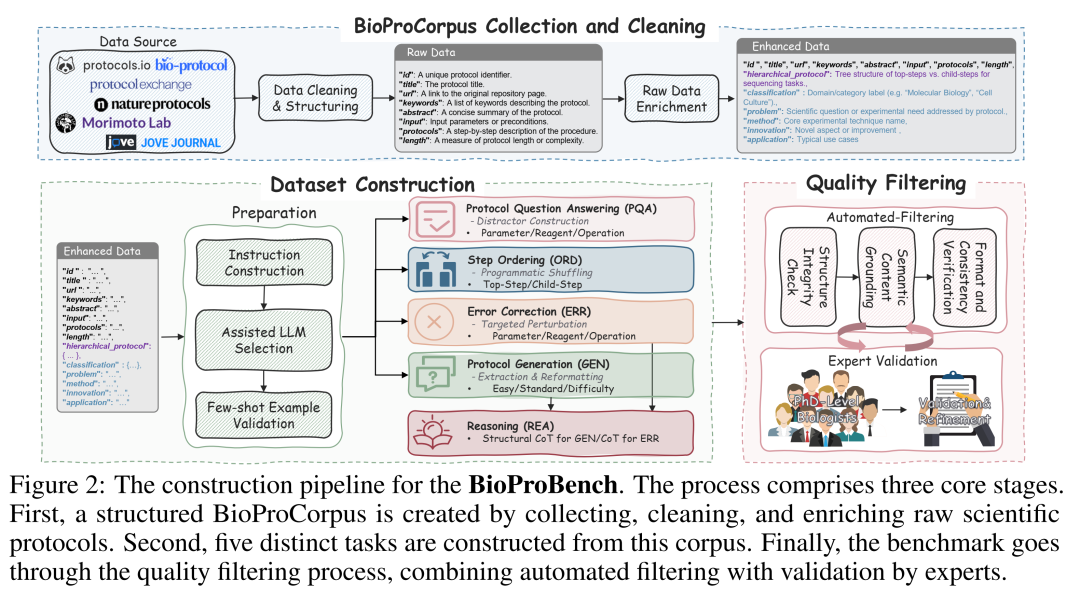
BioProBench 的数据处理流水线。从原始文本到结构化数据,这一步步的解析是后续构建复杂任务的基础。
最终,他们成功构建了包含 556,171 个结构化实例的超大规模数据集。为了保证质量,专家们甚至手动抽查了5.5万个样本!这才是做 Benchmark 该有的严谨态度。💪

数据集的详细统计分布。可以看到数据涵盖了极其广泛的生物学细分领域,且任务类型分布均衡。
⚔️ 看点二:五大“地狱级”任务,刀刀见血
BioProBench 没有去测那些虚无缥缈的闲聊能力,而是针对生物实验的实际需求,设计了5个极具针对性的任务:
🔍 协议问答 (PQA - Protocol Question Answering)
考什么:考眼力,更考细心。比如问“这个试剂加多少毫升?”或“离心机设多少转速?”
难点:选项里会有故意设置的干扰项(比如把10分钟改成10小时)。
🔀 步骤排序 (ORD - Step Ordering)
考什么:考逻辑。把正确的步骤打乱,让大模型重新排好。
难点:不仅要懂先后,还要懂因果。先加A液还是先加B液,是有严格的化学逻辑的。
🚨 错误纠正 (ERR - Error Correction)
考什么:考排雷能力。在正确的协议里故意埋几个坑(比如漏掉一步高温灭菌),看模型能不能揪出来。
难点:有些错误很隐蔽,稍不注意就会引发实验室安全事故。
📝 协议生成 (GEN - Protocol Generation)
考什么:考综合实力。给定一些关键信息,让模型写出完整的实验步骤。
难点:不仅步骤要全,逻辑要顺,连试剂用量都要精准。
🧠 协议推理 (REA - Protocol Reasoning)
考什么:考“元认知”。在生成或纠错之前,强制要求模型先写出它的思考过程(Chain-of-Thought)。
难点:防止模型瞎蒙,必须让它“把道理讲明白”。
📏 看点三:拒绝“糊涂账”——全新领域专属评估指标
传统的 NLP 指标(比如 ROUGE-L)在这里完全不够用。比如说,模型生成的协议和参考答案字面重合度很高,但它漏掉了“在通风橱内操作”这个致命步骤怎么办?
北大团队引入了两组极为硬核的新指标:
1. 关键词指标 (Keyword Metrics)
利用 KeyBERT 提取核心实体(如特异性抗体名称、关键仪器),计算关键词的精确度 (Precision)、召回率 (Recall) 和 F1 分数。这直接反映了模型有没有抓准实验的核心要素。
2. 基于嵌入的步骤指标 (Embedding-Based Structural Metrics)
这是一记绝杀。利用 SentenceTransformer 将步骤转化为向量,设定一个相似度阈值(δ=0.7),专门计算:
步骤召回率 (Step Recall, SR):必做的关键步骤,模型生成了吗?
步骤精确率 (Step Precision, SP):模型生成的步骤,是不是一堆废话或冗余操作?
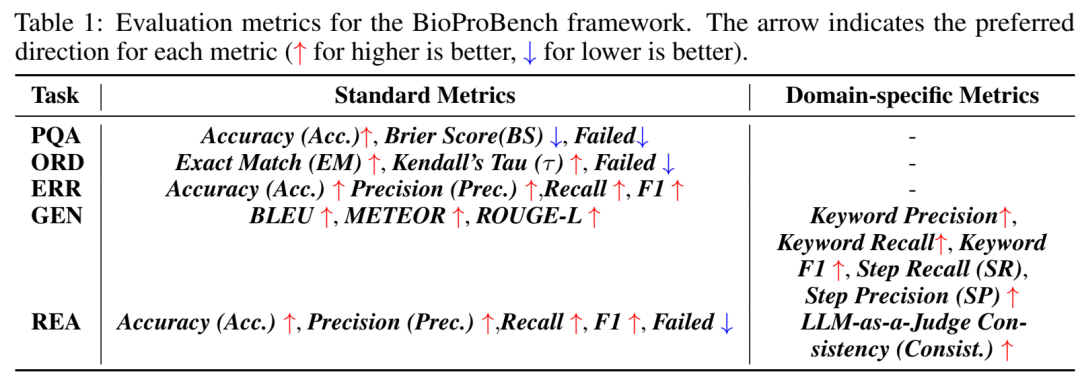
BioProBench 针对不同任务定制的全套评估指标体系。兼顾了传统NLP指标与专门针对科学程序设计的领域指标。
😱 看点四:主流大模型“期中考试”成绩单大曝光!
重头戏来了!研究团队拉来了 10 位目前市面上最能打的 LLM 选手(包括 OpenAI 的 o3-mini、GPT-4o,Anthropic 的 Claude 3.7 Sonnet,Google 的 Gemini 系列,以及开源界的明星 Deepseek-R1/V3、Qwen 等)进行闭卷考试。
结果可谓惨不忍睹,但也发人深省。
(1) 找茬能手,但算数白痴 (PQA & ERR)
在找错误(ERR)的任务中,大模型们普遍表现得像个保守的老学究——精确度(Precision)很高,但召回率(Recall)极低。也就是说,它们能确定的绝对不错,但不确定的就干脆不管。
而在问答(PQA)中,模型们对付定性问题(如“这一步是干嘛的”)游刃有余,但一旦涉及定量问题(如“具体参数是多少”),准确率直线跳水。📉
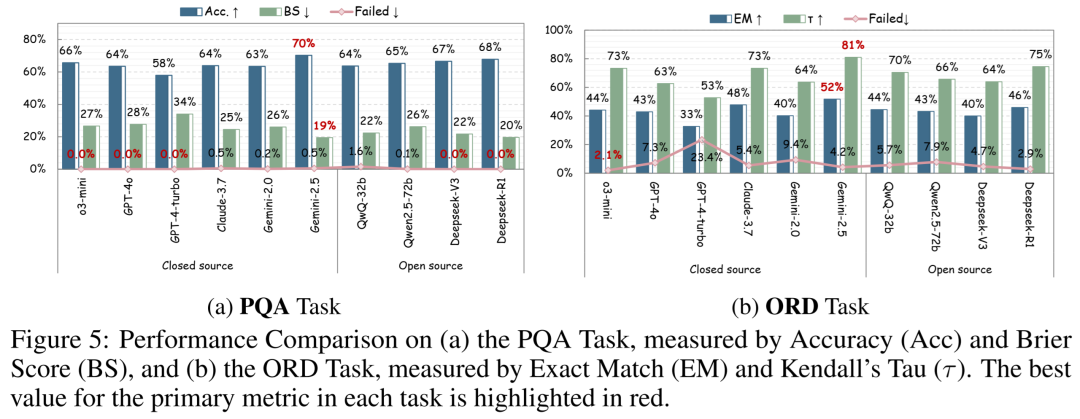
各大模型在 PQA(协议问答)和 ORD(步骤排序)任务上的详细表现。可以看出,即使是顶尖模型,在特定维度上也漏洞百出。
(2) 逻辑碎一地,结构全崩溃 (ORD & GEN)
在步骤排序(ORD)中,几乎所有模型的 Exact Match(完全匹配)得分都低得可怜(最高不到52%)。这意味着它们根本无法从全局上把握一个实验的宏观脉络。
而在协议生成(GEN)中,指标更是难看到爆炸。低得离谱的 Step Recall (SR) 表明,大模型在写实验步骤时,会莫名其妙地丢掉一半以上的核心操作。这要是真照着去做,实验室估计得炸几次。💣
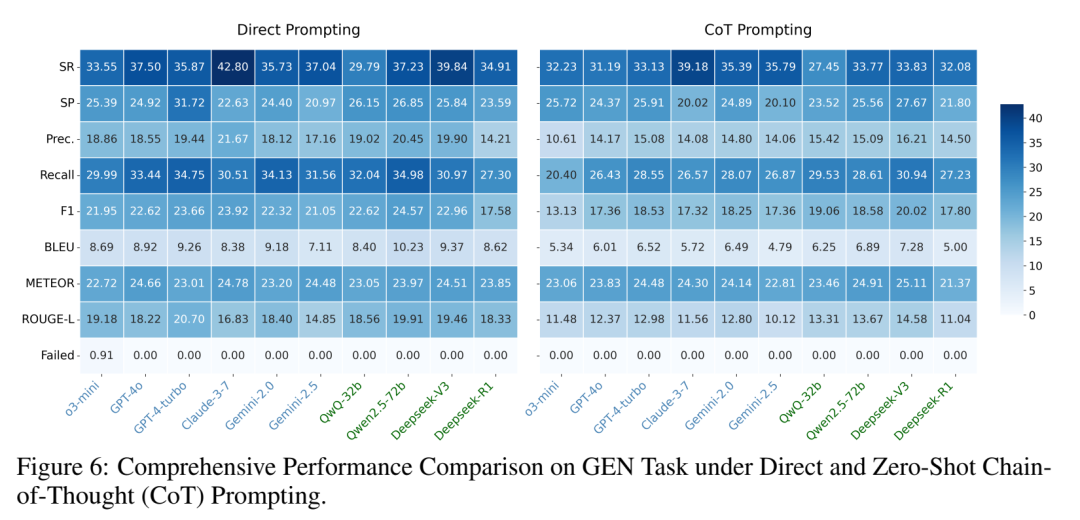
协议生成(GEN)任务的表现。传统的 BLEU 等指标掩盖了深层次的科学缺陷,而新的 Step Recall (SR) 和 Step Precision (SP) 指标无情揭示了模型在结构保真度上的全面溃败。
(3) “嘴强王者”现象 (REA)
在强制要求给出推理过程(REA)后,研究人员发现了一个惊天大瓜:很多时候,模型给出的答案是对的,但它的推理逻辑完全是胡说八道(Reasoning Consistency 极低)!这说明大模型在很大程度上依然是在进行高级的“随机鹦鹉”式拼凑,而非真正的理解。
🛡️ 破局者:ProAgent 登场
发现问题不是为了吐槽,而是为了解决问题。
为了证明 BioProCorpus 这套庞大语料库的价值,研究团队基于检索增强生成(RAG)技术,开发了一个名为 ProAgent 的协议智能体基线模型。
ProAgent 的核心思路非常聪明:不做无源之水,一切从实际出发。
它内置了一个任务自适应检索器(Task-Adaptive Retriever),遇到事实类问题(如查参数),就去精细颗粒度的数据库里找确切答案;遇到流程类问题,就去拿上下文丰富的长文本。
实验证明,得益于高质量的底层语料,ProAgent 在各项指标上都实现了对原有大模型的降维打击,极大地提高了回答的可靠性和步骤的完整性。
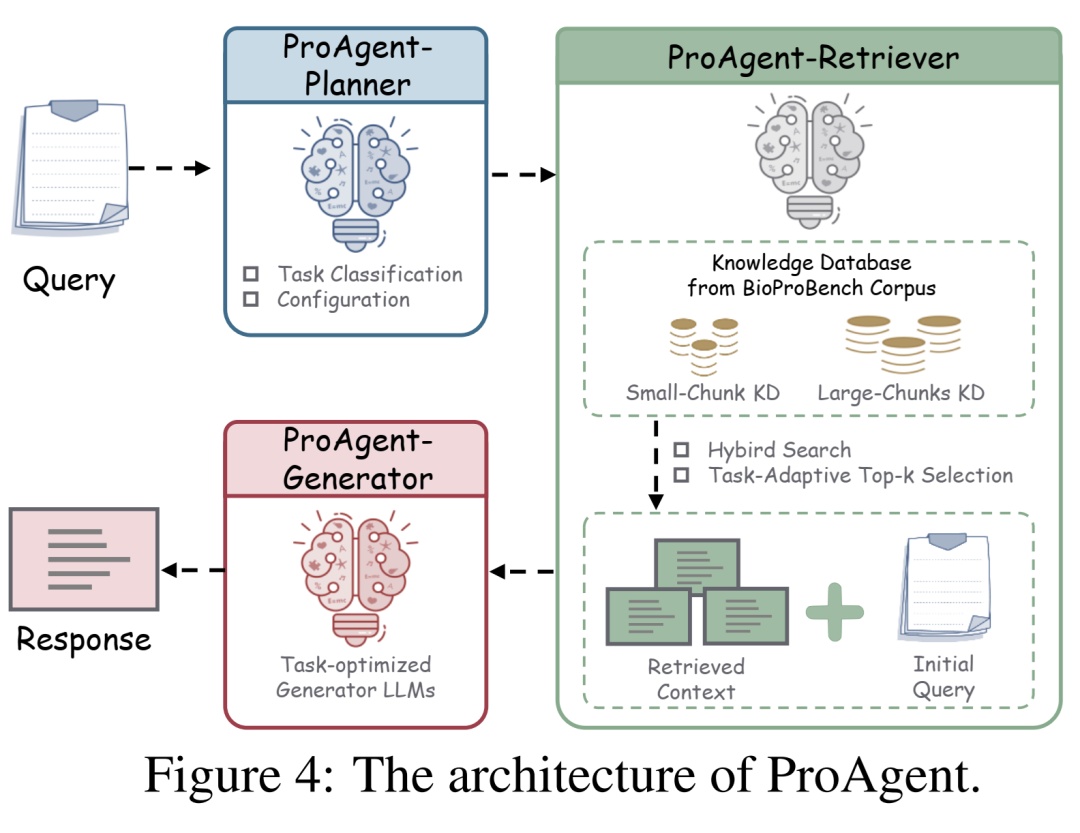
ProAgent 架构图。通过任务分类器和自适应检索器的配合,实现了对不同类型协议问题的最优解答路径规划。
💡 实验室寄语:我们可以从这篇论文中学到什么?
同学们,读完这篇长达十几页的论文解读,不知道你们作何感想?
对于每天忙于跑胶、养细胞、写代码的我们来说,这篇由北大团队带来的 BioProBench 绝不仅仅是一篇普通的 Arxiv 预印本。它实际上向我们揭示了一个冰冷但真实的趋势:通用大模型的时代正在褪去光环,垂直领域、具备严谨逻辑推理能力的专业化 AI 才是未来的王道。 🌟
这项研究的伟大之处,不在于它证明了现有的大模型有多么笨,而在于它极其敏锐地捕捉到了制约 AI 进军自然科学的最后一道壁垒——对“过程”和“逻辑”的绝对掌控。
对于我们本硕博学生而言,BioProBench 的诞生其实是一记响亮的警钟,也是一份珍贵的科研方法论范本:
告别调包侠,深耕真痛点。不要为了发文章而堆砌复杂的模型架构。去看看你所在领域的真正瓶颈是什么?是数据不够干净?还是现有的评估方式太粗糙?像北大团队一样,去构建一个能“卡别人脖子”的高质量数据集,这才是科研界最硬的通货。
严谨,是科研人的底线。当所有人都在欢呼大模型无所不能时,敢于站出来用最严苛的指标去揭露它们的短板,这需要极大的学术勇气。我们在做研究时,也应该有这种“吹毛求疵”的精神。
未来已来。或许在不久的将来,我们真的可以拥有一个不会看错 protocol、不会算错浓度、时刻把实验室安全挂在嘴边的 AI 超级博士后。而通往那个未来的阶梯,正是由像 BioProBench 这样扎实、厚重、直击本质的研究一块块铺就的。🧗♂️
那么你呢?你认为大模型目前在你所在的学科领域,最大的短板是什么?欢迎在评论区留下你的“血泪史”,我们一起聊聊!👇
如果觉得这篇文章对你有帮助,别忘了点赞、在看并分享给你的实验室同门,让我们一起追踪最前沿的 AI4Science 动态!



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢