

当前科学 Agent 的一个核心问题是,许多科学任务并不适合只通过语言推理来完成。
时间序列、表格、结构化观测值,通常更适合交给专门的基础模型处理;但现有 Agent 系统往往还是先把这些输入转成文本,再交给大语言模型(LLM)推理。这种模式的不足在于,结构信息会丢,token 成本会上升,即使 LLM 能够遵循指令并满足格式要求,但也未必真正完成了底层的领域专用数值计算。
针对这一问题,伊利诺伊大学厄巴纳-香槟分校(UIUC)团队提出了异构 Agent 框架 Eywa,将以语言为中心的系统扩展到了更广泛的科学基础模型类别。

论文链接:https://arxiv.org/abs/2604.27351v1
Eywa 既可作为单 Agent 流水线的即插即用替代方案(EywaAgent),也可通过将传统 Agent 替换为专用 Agent 的方式集成到现有多 Agent 系统中(EywaMAS)。此外,他们还推出了一种基于规划的编排框架 EywaOrchestra,其中规划器动态协调传统 Agent 与 Eywa Agent,从而跨异构数据模态解决复杂任务。
在涵盖物理、生命与社会科学等多个科学领域的实验结果表明,Eywa 提升了涉及结构化和领域专用数据任务的性能,同时通过与专用基础模型(FM)的有效协作,降低了对纯语言推理的依赖。
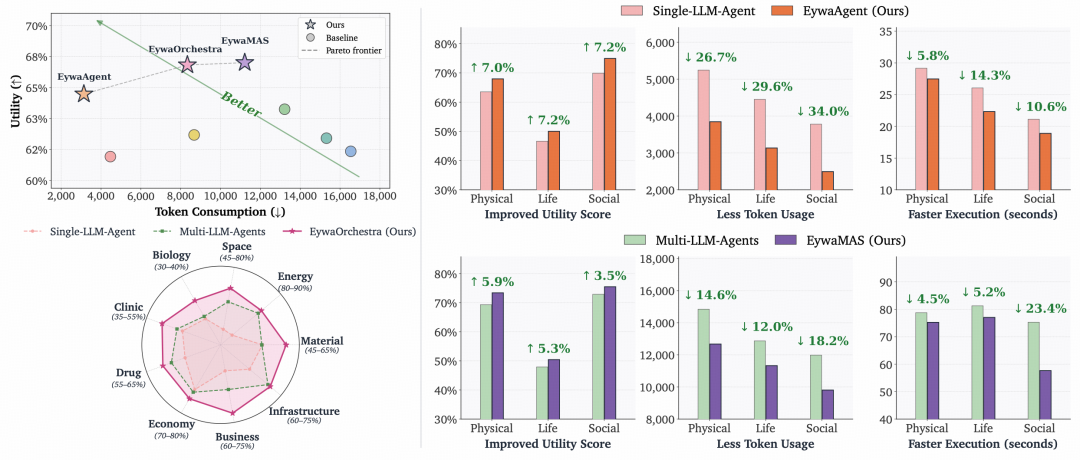
图|EywaAgent、EywaMAS 和 EywaOrchestra 相较于纯语言基线在更低 token 消耗下实现了更高的效用(左);同时在物理、生命与社会科学任务中,在效用、token 效率和执行时间上取得了一致性提升(右)。
Eywa:一个3层递进式框架
研究团队设计了一套 3 层递进式框架:EywaAgent(推理增强的专家模型)、EywaMAS(即插即用的异构多 Agent 系统)和 EywaOrchestra(动态编排各领域专家的“指挥官”)。
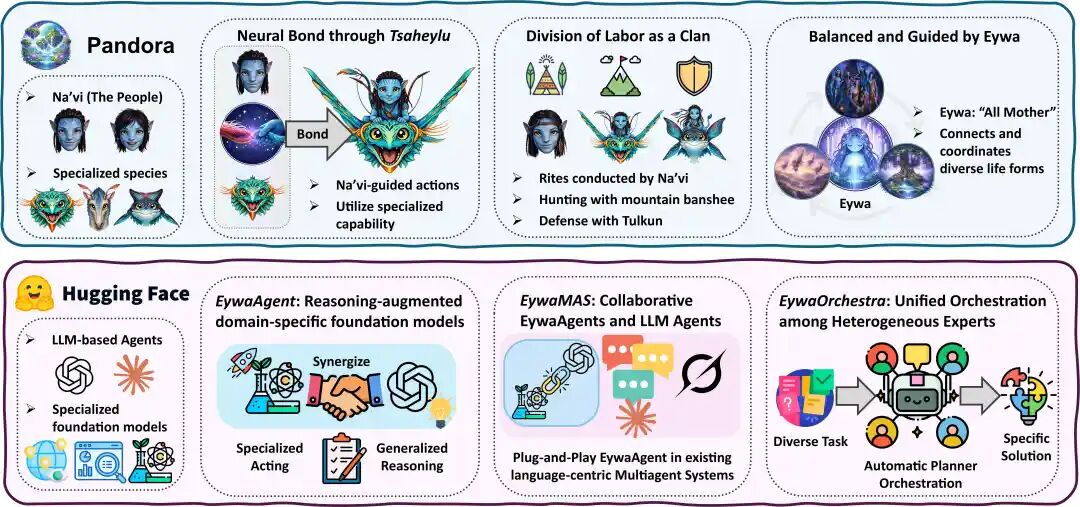
图|Eywa 框架概述。
1.EywaAgent:先解析任务,再调用专家模型
Eywa 的核心思想类似于《阿凡达》中的“Tsaheylu”(神经连接)。它负责把当前任务状态编译成模型可执行的结构化调用,再把模型输出转换回 LLM 可继续处理的上下文。这样一来,LLM 不再直接对文本化后的结构化数据做近似推断,而是先完成任务解析、参数配置和输出约束管理,再把核心计算交给领域模型。
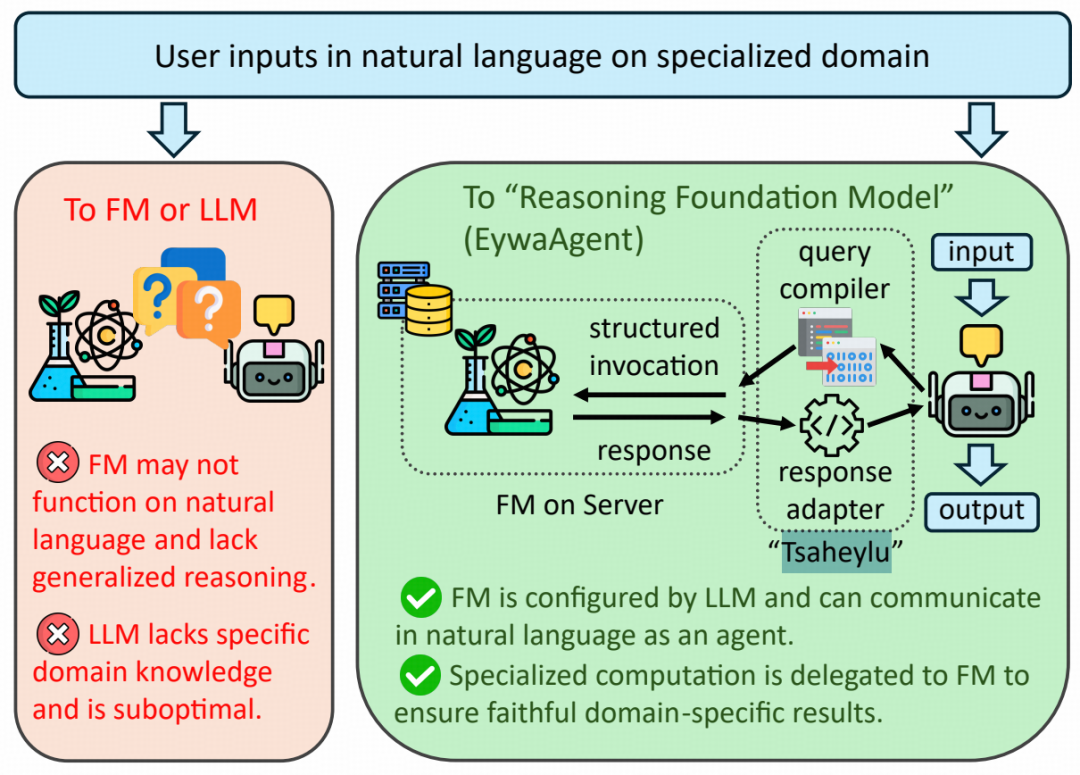
图|EywaAgent 通过 Tsaheylu 同时实现了通用推理能力和专门化执行能力
EywaAgent 不是简单的“LLM + 工具”,而是一个耦合的 Agent 单元:LLM 作为控制器,基础模型作为计算模块,系统在每一步决定继续走语言路径,还是切换到基础模型路径。如果任务主要涉及解释、规划、整合和格式整理,就由 LLM 继续处理;如果任务涉及时间序列预测或表格回归,则调用对应的基础模型。
2.EywaMAS:把专家能力接入多 Agent 系统
在单 Agent 之上,研究团队进一步提出了 EywaMAS。它并不重写既有多 Agent 系统(MAS)的通信机制,而是直接将部分语言 Agent 替换为 EywaAgent。原有的 planner-worker-summarizer 结构、顺序式拓扑或辩论式拓扑都可以保留,但其中负责结构化子任务的节点,不再只依赖语言模型,而是引入领域专家能力。
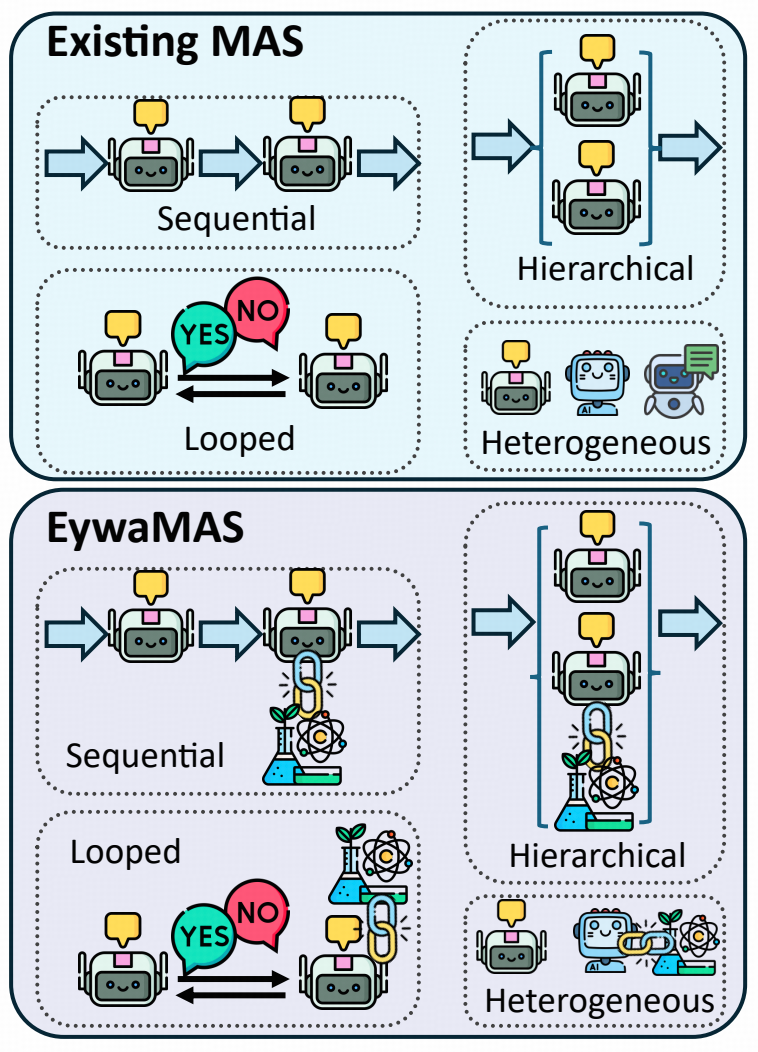
图|EywaMAS 对现有多 Agent 系统进行泛化。
这里的关键不在于单纯增加语言 Agent 的数量,而在于将领域特定基础模型纳入统一协作框架;结果表明,对于科学任务,跨模态异质性比单纯组合异构语言模型更为关键。
3.EywaOrchestra:按任务动态选择系统配置
在 EywaMAS 的基础上,研究团队又增加了一个 conductor,构建了 EywaOrchestra。这一层不直接参与底层求解,而是先给出任务的执行方案:是否启用 EywaAgent、选用哪个 LLM 骨架、接入哪个基础模型、采用什么通信拓扑。在工程实现上,Eywa 通过 MCP 将基础模型部署为独立服务。
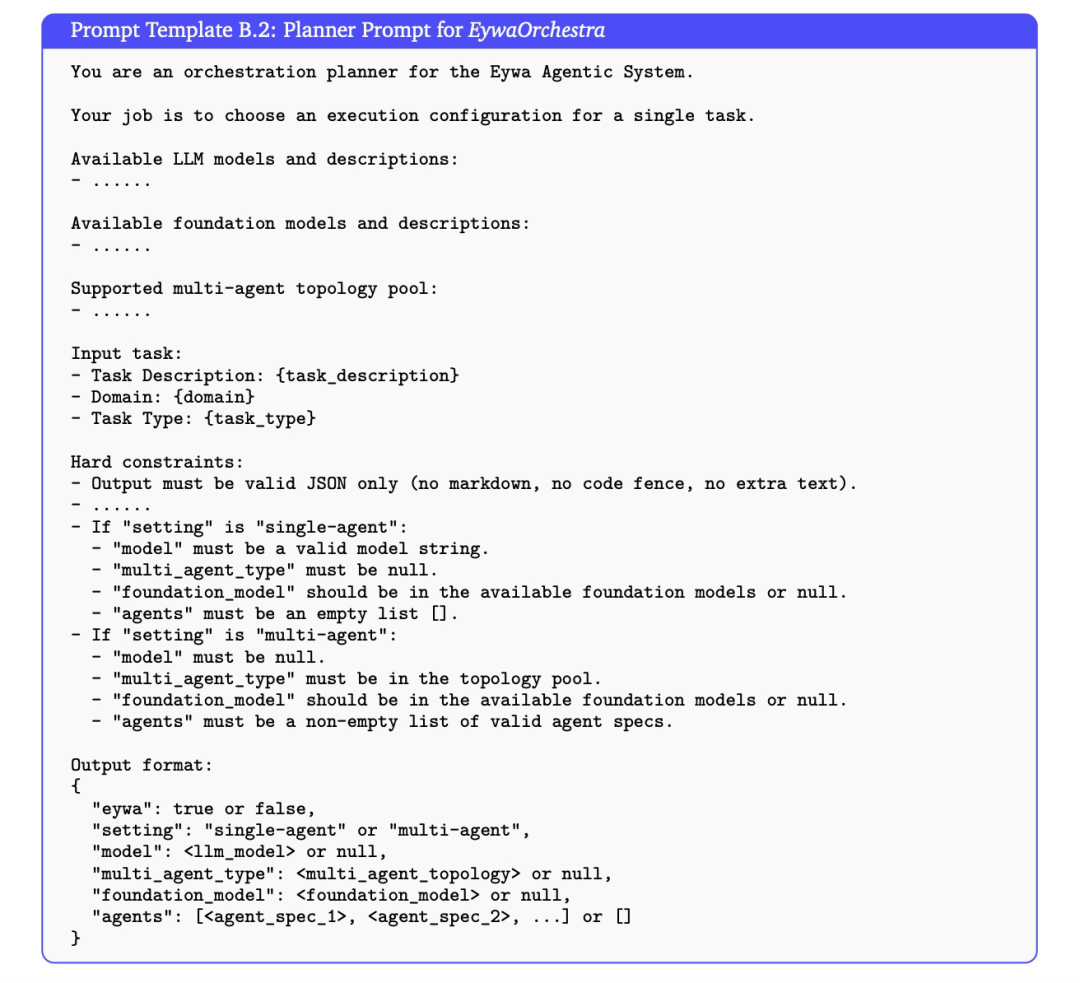
图|EywaOrchestra 使用的规划器提示词模板。给定任务描述、领域和任务类型后,规划器会输出一个结构化的 JSON 配置,用于指定是采用单 Agent 还是多 Agent 执行、是否启用 Eywa、调用哪个基础模型,以及如何实例化参与的智能体。
更少token、更强性能
在评估方面,研究团队构建了涵盖物理科学、生命科学和社会科学的 EywaBench,任务模态包括自然语言、时间序列和表格。在默认实验中,语言模型骨架使用 gpt-5-nano。主要结果如下:
1.EywaAgent 在相同骨干模型下同时提升了质量与效率
与对应的单 Agent 基线相比,EywaAgent 将平均效用提升了 6.6%,同时通过将任务委托给领域专用基础模型,将延迟降低、token 使用量削减近 30%。
2.EywaMAS 在科学场景下优于同构多 Agent 基线
EywaMAS 取得了 SOTA 整体效用,超越了所有同构多 Agent 基线。与 Refine 相比,EywaMAS 的效用显著更强;与 Debate 相比,EywaMAS 不仅效用更高,在相同辩论拓扑下所需 token 数量也更少。
3.仅靠 LLM 的异构性不足以应对科学任务
异构纯语言模型多 Agent 方法在 EywaBench 上并未始终优于强同构多 Agent 基线。这表明,对于科学类任务,跨模态的异构性比单纯组合异构语言模型更为关键。
4.并非每个领域都能从更重的多 Agent 计算中获得同等收益
在经济与商业等领域,单智能体 EywaAgent 已具备强竞争力,这说明一味使用复杂的多 Agent 拓扑并不总是最优选择。这一观察结果促使研究团队探索根据任务和领域特性进行自适应编排。
5.EywaOrchestra 以更低成本和更高自动化程度接近 EywaMAS 的性能
EywaOrchestra 无需专家配置,而是由指挥者自动为每个样本构建系统。尽管如此,EywaOrchestra 的效用仍接近专家设计的 EywaMAS,甚至在若干子领域上实现超越。与此同时,相较于固定多 Agent 系统,动态编排在延迟和 token 消耗两个维度上均降低了推理成本。
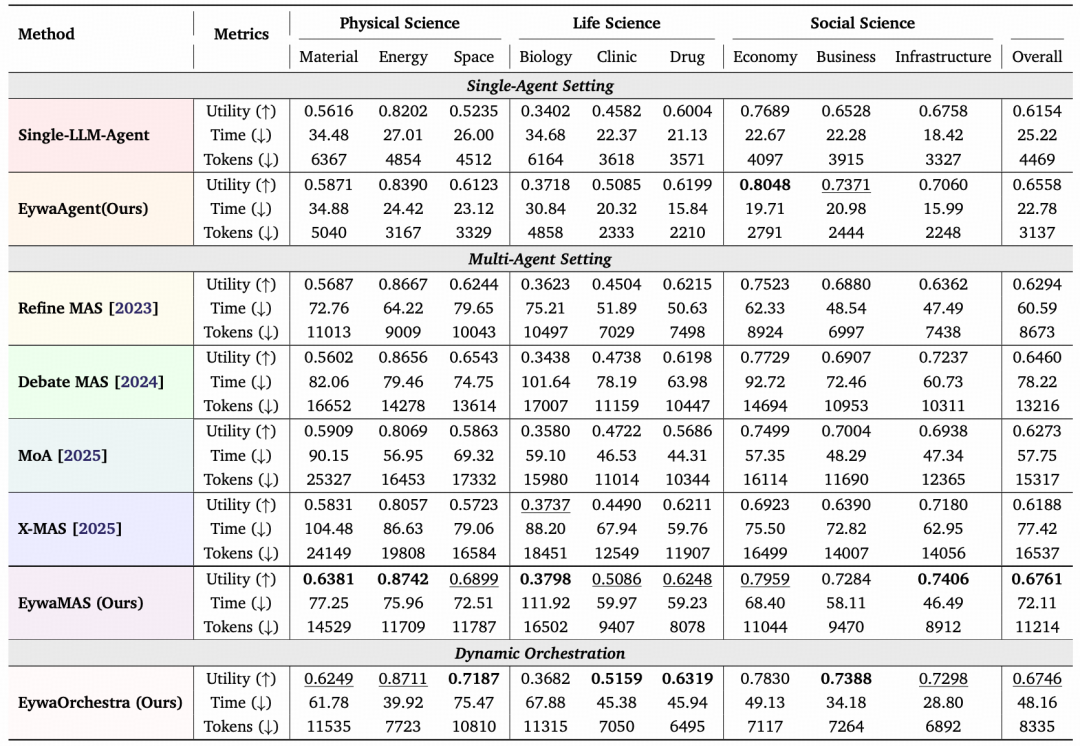
图|EywaBench 上各科学领域的整体性能对比。研究团队从 3 个维度对所有方法进行了比较,包括效用、推理时间和 token 消耗。SOTA 结果以粗体标注,次优结果以下划线标注。
进一步的实验分析表明,Eywa 的性能提升并不来自更长的语言推理链,而是来自把结构化计算交还给保留原生归纳偏置的领域模型。EywaAgent 在提升效用的同时降低了 token 和时延,说明科学 Agent 的主要瓶颈并不总是 LLM 不够强,很多时候是系统让 LLM 去承担了不适合它完成的结构化计算。
值得注意的是,纯 LLM 异构多 Agent 基线并未稳定优于强同构基线。科学任务中的关键异构性,不在于并置多个不同 LLM,而在于让语言模型与领域模型共同参与求解。
不足与未来方向
当然,这项研究也存在一些局限。
目前系统性能直接依赖底层模型质量,包括 LLM 的任务解析与路由能力、基础模型的预测质量、接口的稳定性。实验覆盖的专家模型仍然有限,接入的模型也主要是 Chronos 和 TabPFN,主要集中在时间序列和表格任务。
当前,EywaOrchestra 仍建立在有限拓扑池上,距离真正可学习、可扩展的开放式编排还有差距。异构协作本身也会引入部署、通信与调度开销,这部分成本还需要通过更高效的编排、选择性专家调用与自适应停止机制继续压缩。
对此,研究团队也给出了几个未来研究方向:扩大可接入的科学基础模型生态;从 prompt 驱动的 planner 走向数据驱动的编排策略;以及探索比 MCP 更好的 FM-LLM 耦合方式,如表示对齐、记忆机制和跨步骤证据传递。
整体来看,Eywa 提供的不是又一个多 Agent 变体,而是一种更适合科学任务的系统分工方式。对于需要处理结构化科学数据的任务而言,这一路线显然比“先全部翻译成语言,再交给 LLM 统一处理”更接近可扩展的方向。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢