
底物特异性酶设计正在快速进入生成式人工智能时代。近年来,蛋白质语言模型、扩散模型与等变图神经网络等方法的发展,使研究者能够直接面向酶序列、骨架结构和功能位点生成候选酶,而不再局限于从天然酶库中筛选或对少数位点进行定向突变。然而,现有多数生成方法主要关注“生成一条合理序列”或“生成一个可折叠骨架”,对于酶真正发挥催化功能时所依赖的底物结合口袋,以及口袋残基与底物原子之间的细粒度匹配关系,仍缺乏充分建模。如何让模型在生成过程中同时理解酶功能、底物信息与结合口袋环境,成为底物特异性酶设计中的关键问题。

该研究提出了一种基于口袋条件建模的底物特异性酶生成模型 EnzyPGM(Pocket-conditioned Generative Model for Substrate-specific Enzyme Design)。EnzyPGM 将酶功能先验、底物信息和结合口袋信息纳入统一框架,通过 Residue Function Fusion(RFF)融合 EC 编号与保守功能位点等功能先验,并利用 Residue-atom Bi-scale Attention(RBA)显式建模口袋残基与底物原子之间的相互作用。与此同时,研究构建了 EnzyPock 数据资源,用于支撑酶、底物、功能注释与结合口袋的联合建模。实验结果表明,EnzyPGM 在底物结合能力、结构有效性、泛化能力和案例分析中均展现出较强的酶设计潜力。
这项工作值得关注的地方,并不仅仅是它在若干指标上超过了现有方法,而是它将“结合口袋”从后验评估对象前移为生成过程中的核心条件。过去许多方法更像是在学习如何生成一个可能具有某种功能的蛋白,而 EnzyPGM 则进一步尝试学习如何围绕给定底物形成合理的空间结合环境。对于面向生物制造、药物合成和绿色催化的可控酶设计,这种范式具有较强的启发意义。
研究背景
酶是自然界中最重要的生物催化剂之一,广泛参与生物医药、精细化工、绿色制造和环境治理等场景。对于一个目标底物而言,酶是否有效,并不只取决于整条蛋白序列是否“像天然蛋白”,更取决于其三维结构中是否形成了能够识别、容纳并稳定底物的结合口袋。口袋的位置、残基类型、空间构象以及与底物的几何关系,都会直接影响底物结合能力和后续催化效率。
这也是底物特异性酶设计区别于一般蛋白生成任务的核心难点:模型不仅要生成稳定、可折叠的蛋白,还要生成能够围绕目标底物形成有效相互作用的局部催化环境。图 1 展示了几类典型失败情形,包括缺少结合口袋、口袋残基预测错误以及底物姿态不合理等。这些情况说明,如果缺少口袋—底物相互作用建模,生成结果即使在整体结构上看起来合理,也可能无法真正服务于底物特异性催化。
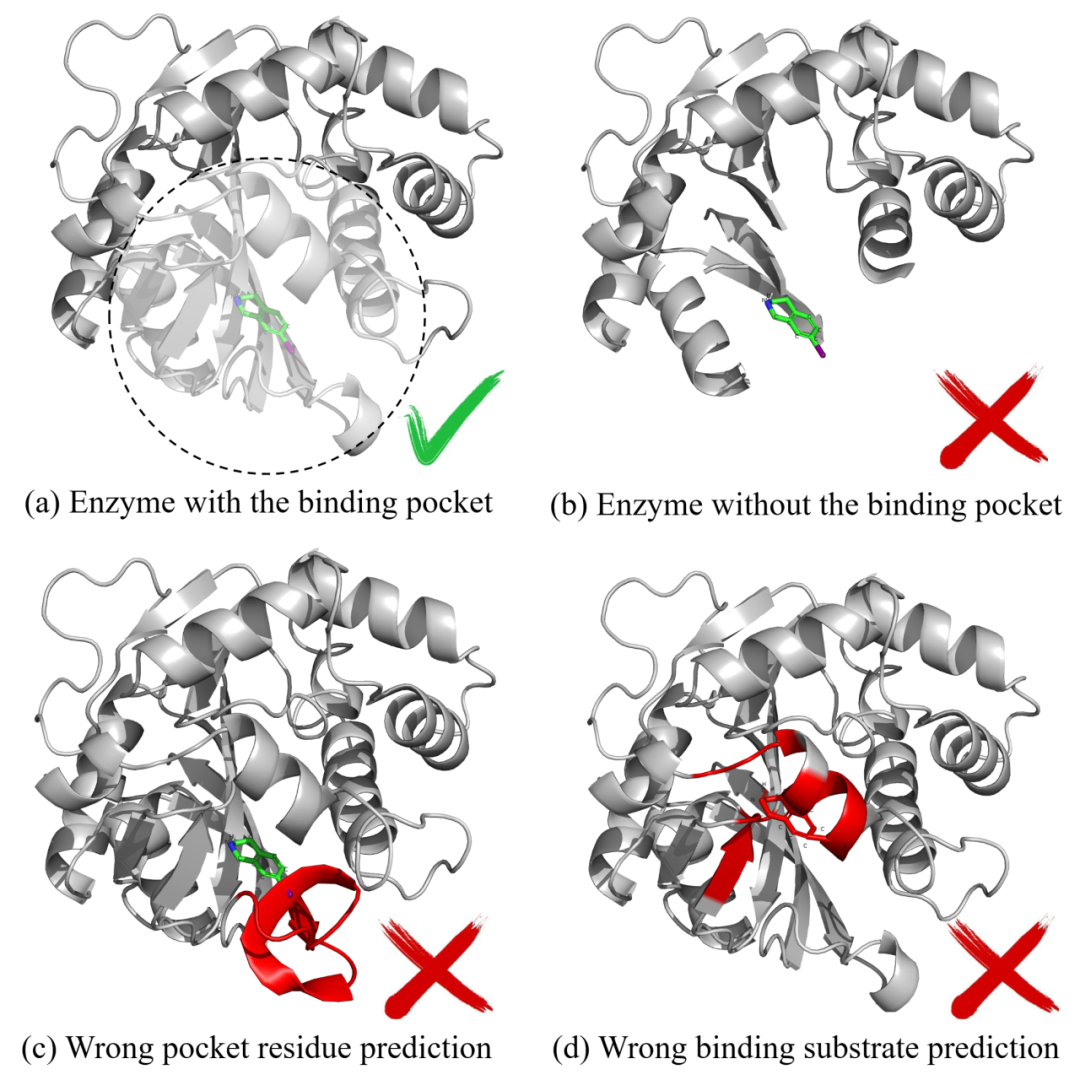
图 1: 酶设计任务中的底物结合口袋问题。只有同时关注酶结构、结合口袋和底物位置,生成结果才更可能具备有效结合能力。
方法概述
围绕上述问题,论文提出 EnzyPGM,将底物特异性酶设计表述为一个带有功能先验与底物条件的生成任务。给定 EC 编号、底物分子以及功能保守位点,模型需要生成完整酶序列及其与底物匹配的结合口袋。换言之,模型的目标并不是单独生成蛋白,而是联合建模“酶—口袋—底物”三者之间的关系。
从整体框架看,EnzyPGM 主要由两个核心模块组成:RFF 用于把酶功能信息注入残基表示,并结合空间邻域更新残基特征与坐标;RBA 则进一步聚焦口袋区域,同时建模残基—残基关系和残基—底物原子关系,从而在局部空间中增强口袋生成能力。
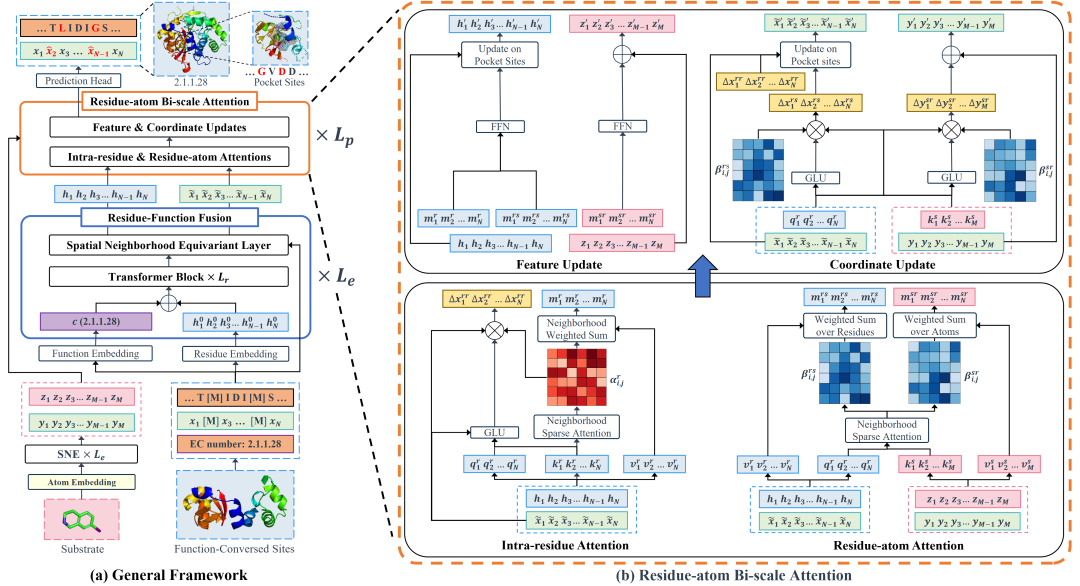
图 2: EnzyPGM 整体框架与核心模块。模型以功能保守位点、EC 编号和底物信息为条件,通过 RFF 与 RBA 预测完整酶及其结合口袋。
功能先验:让模型知道“要做什么反应”
酶通常具有明确的功能类别,EC 编号可以描述其催化反应类型,而功能保守位点往往直接参与催化或维持结构稳定。EnzyPGM 将 EC 编号编码为功能嵌入,并结合多序列比对得到的保守位点信息,使模型在生成时不只是依赖序列统计模式,而是能够感知目标酶家族的功能约束。
口袋建模:让模型知道“底物应该放在哪里”
在论文中,结合口袋被定义为与底物空间距离小于一定阈值的残基集合。EnzyPGM 显式关注这些口袋残基,并通过残基—底物原子注意力捕捉局部几何和化学关系,使模型能够学习底物附近哪些残基更应该被更新、如何调整其表示与坐标,以及如何形成更合理的结合环境。
双尺度注意力:同时看全局结构和局部相互作用
RBA 模块中的 intra-residue attention 关注酶内部残基之间的邻域关系,帮助保持整体结构一致性;residue-atom attention 则关注口袋残基与底物原子之间的跨模态关系,帮助模型学习细粒度结合模式。二者结合,使模型既不会只盯着局部口袋而破坏整体结构,也不会只生成整体合理但与目标底物不匹配的酶。
数据集构建与实验设置
为了支撑酶、底物、结合口袋和功能注释的统一建模,论文构建了 EnzyPock 数据资源。数据构建流程整合了蛋白—配体复合物、PDB 到 UniProt 的映射、EC 编号注释、基于四级 EC 家族的 MSA 保守位点识别,以及基于空间距离的结合口袋提取。对于多链蛋白,论文保留首个具有 EC 注释的链,以降低多链拼接对同源分析和训练成本的影响。
数据划分上,论文对 PDB 条目按照 70% 序列一致性阈值进行聚类,并确保训练、验证和测试集合之间的 cluster 不重叠,以降低数据泄漏风险。最终数据包含 84,336 组酶—底物样本,覆盖 1,036 个四级 EC 功能家族和 17,404 个 PDB 条目,其中训练集包含 83,062 组样本。
核心结果速览
实验结果
在 EnzyPock 主实验中,EnzyPGM 在氨基酸恢复率、底物结合能力和结构有效性等维度表现突出。具体而言,EnzyPGM 在 EnzyPock 上取得 0.77 的 AAR 和 -7.12 的 Vina score,相比 EnzyGen 将平均结合能进一步降低 0.47 kcal/mol,同时在 scRMSD 和 scTM 上也取得更好的结构设计质量。这说明,显式建模结合口袋不仅有助于提高底物亲和力,也有助于生成更稳定、更合理的候选酶结构。
从不同 EC 家族的结果看,EnzyPGM 在多个酶家族上保持了较稳定的结合能力和结构置信度。对于实际应用而言,这一点很重要,因为真实酶设计任务往往并不局限于单一反应类型,而是需要面对不同底物、不同家族和不同功能约束下的生成需求。
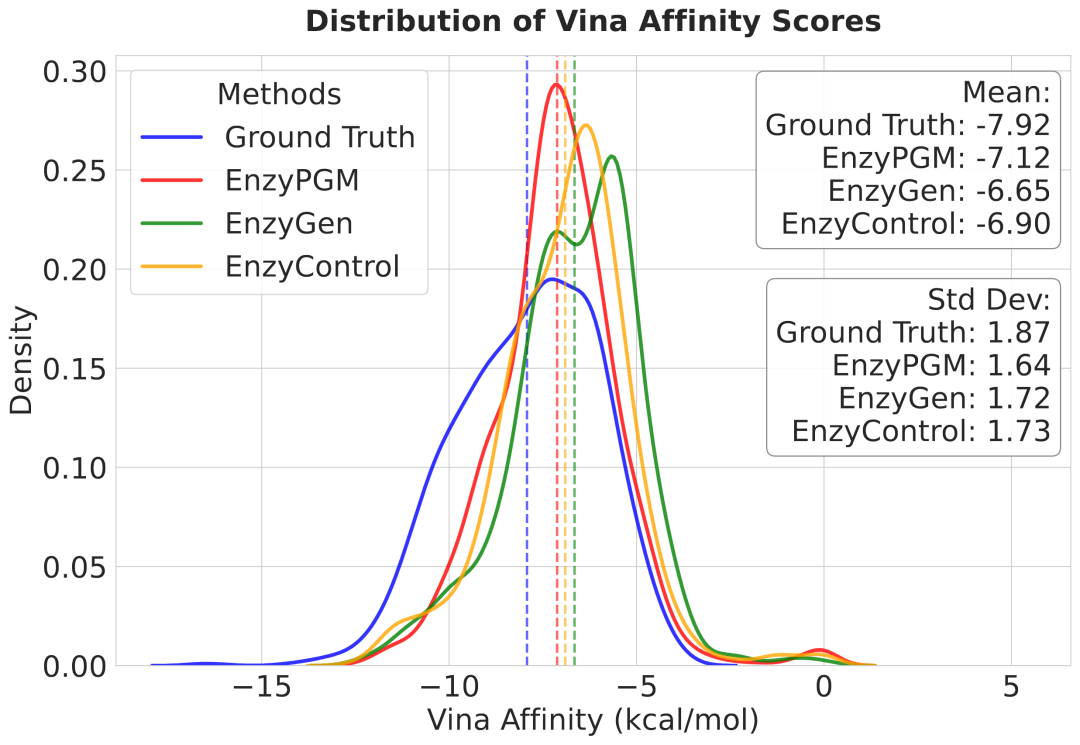
图 3: 不同方法的结合亲和力分布对比。EnzyPGM 的 Vina score 分布更接近真实样本,说明其生成结果在底物结合能力方面更加稳定。
案例分析
除了整体指标,论文还通过具体案例展示了 EnzyPGM 生成结果的结构特征。图 4 对比了真实结构、EnzyPGM 生成结果以及两个基线方法的结果。可以看到,EnzyPGM 生成的结合口袋能够围绕底物形成更丰富的氢键、π-cation、π-π stacking 和盐桥等相互作用,并在案例中表现出更有竞争力的结合能。
这说明 EnzyPGM 并不只是生成一条看起来合理的序列,而是在尝试生成能够围绕目标底物形成有效结合环境的候选酶。对于底物特异性酶设计而言,这种“从底物出发、回到口袋结构”的生成方式,比单纯追求序列相似性或整体折叠合理性更贴近真实应用需求。
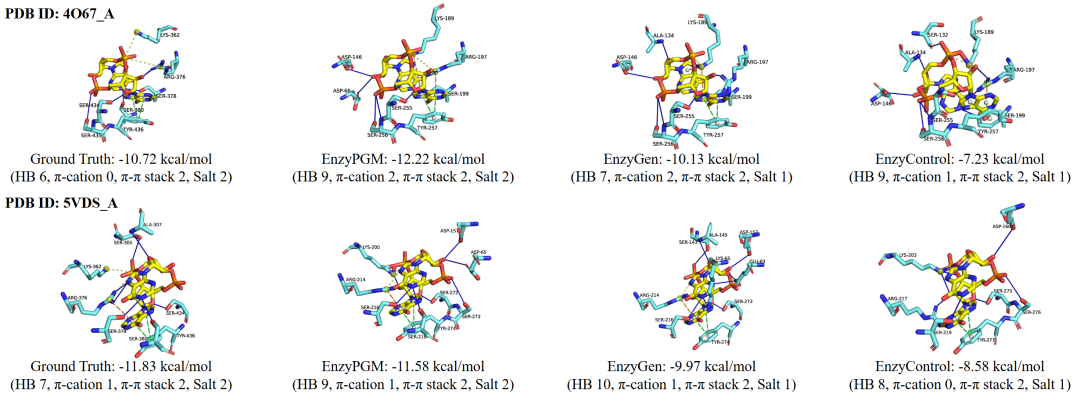
图 4: EnzyPGM 生成结果案例分析。图中展示了真实结构、EnzyPGM 以及基线方法在底物相互作用模式和结合能方面的差异。
泛化能力分析
面向真实应用时,模型不仅要在已有数据分布上表现良好,也需要面对未见过的酶家族和新底物。论文进一步构建了排除训练集中 EC-4 家族和底物的测试场景,用于评估 EnzyPGM 对新反应和新底物的泛化能力。
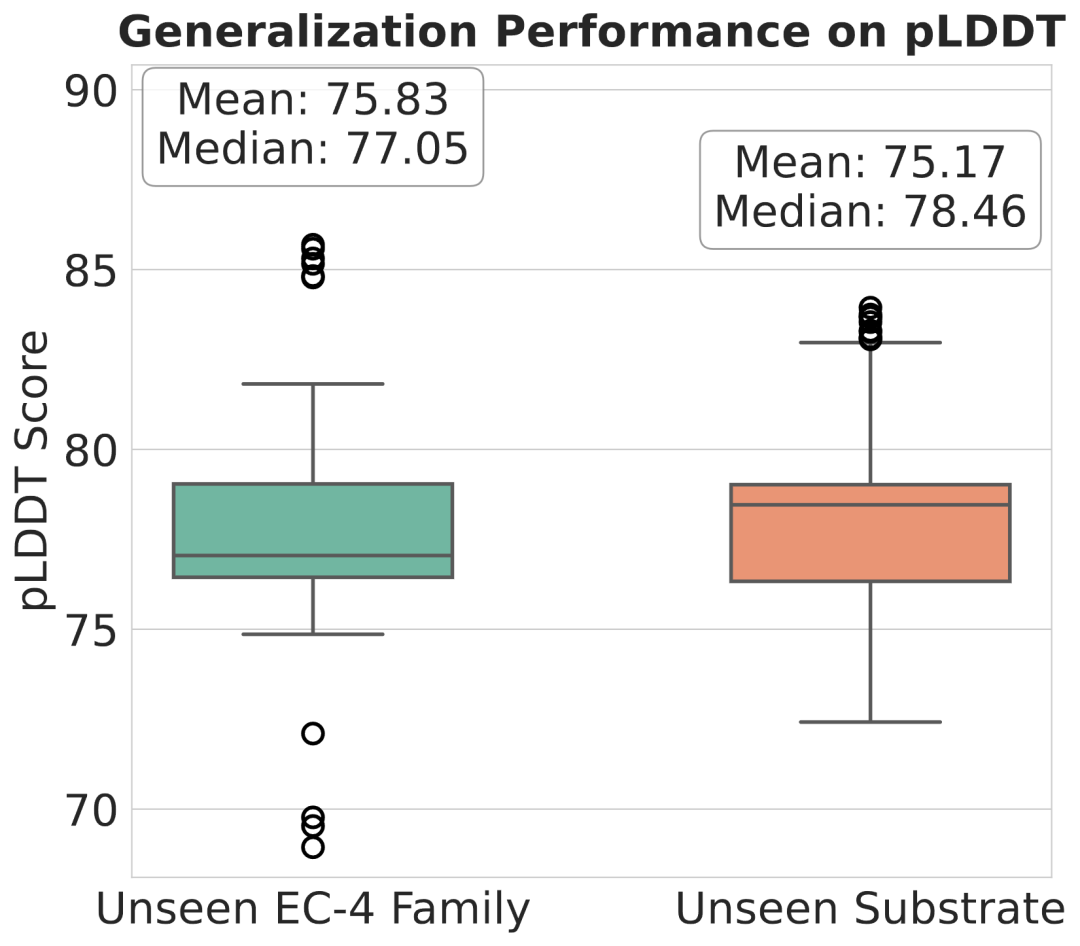
图 5: 泛化场景下的结构置信度分析。EnzyPGM 在未见 EC-4 家族和未见底物场景中仍能保持较好的 pLDDT 表现。
结果显示,EnzyPGM 在未见家族上取得平均 pLDDT 75.83,在未见底物上取得平均 pLDDT 75.17;在结合亲和力方面,未见家族和未见底物场景下的平均 Vina score 分别达到 -6.22 和 -7.14。这表明模型不仅能够记忆训练集中常见模式,也具备一定的跨家族和跨底物设计能力。
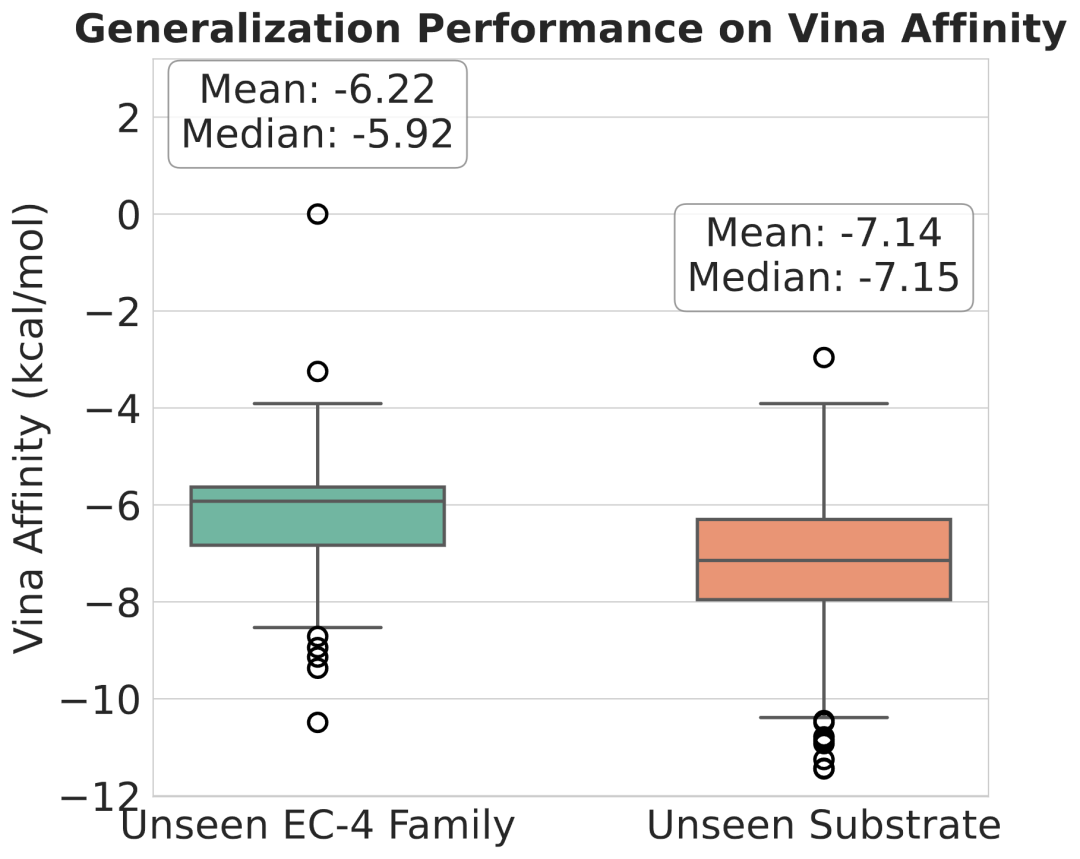
图 6: 泛化场景下的底物结合亲和力分析。模型在新底物或新反应场景中仍展现出较强的应用潜力。
研究意义
总体而言,EnzyPGM 的意义在于把底物结合口袋从“生成后再检查”的对象,提升为“生成过程中显式建模”的条件。对于酶设计任务来说,这种变化非常关键:真正可用的酶不仅要能折叠,还要能结合特定底物,并在局部空间中形成适合催化的相互作用网络。
从方法角度看,EnzyPGM 提供了一种将功能先验、空间结构和底物相互作用纳入统一生成框架的思路;从数据角度看,EnzyPock 也为后续酶—底物—口袋联合建模提供了可复用的基础资源。未来,如果进一步结合更高质量的实验数据、分子动力学模拟、反应机制约束和湿实验反馈,这类模型有望推动 AI 酶设计从“结构合理”走向“功能可验证”。
参考资料
Zefeng Lin et al. EnzyPGM: Pocket-conditioned Generative Model for Substrate-specific Enzyme Design. arXiv:2601.19205v1, 2026.
代码与数据集:论文中说明将后续发布。
整理|EnzyPGM 团队
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢