

请索引第89篇论文
 |  |
凌晨三点盯离心机?ACL 2026这篇Agent神作,把“炸实验室”的概率降到了0.1%
带你读懂前沿顶会,拓宽科研边界。本期为您深度拆解 ACL 2026 最新力作:
BioProAgent。看它如何用“神经符号系统”接管湿实验室,让科研自动化真正落地。
你是否经历过这样的至暗时刻?
历经数周设计好的实验方案,因为助手不小心看错了一个试剂 ID,或者在操作离心机时设错了转速,瞬间功亏一篑。更惨的是,如果是高危化学或生物实验,一个参数的偏差甚至可能损坏昂贵的设备。
在软件世界里,代码报错只需按下 Ctrl+Z;但在湿实验(Wet-lab)里,物理法则是不可逆的。
近年来,大语言模型(LLM)Agent 在科学发现中大放异彩,从设计合成路线到 orchestrating 计算工作流,看似无所不能。然而,一旦要让它们跨越“模拟到现实”的鸿沟,亲手操刀物理实验,现有的通用 Agent 就会集体翻车——概率性的幻觉在不可逆的物理世界里是致命的。
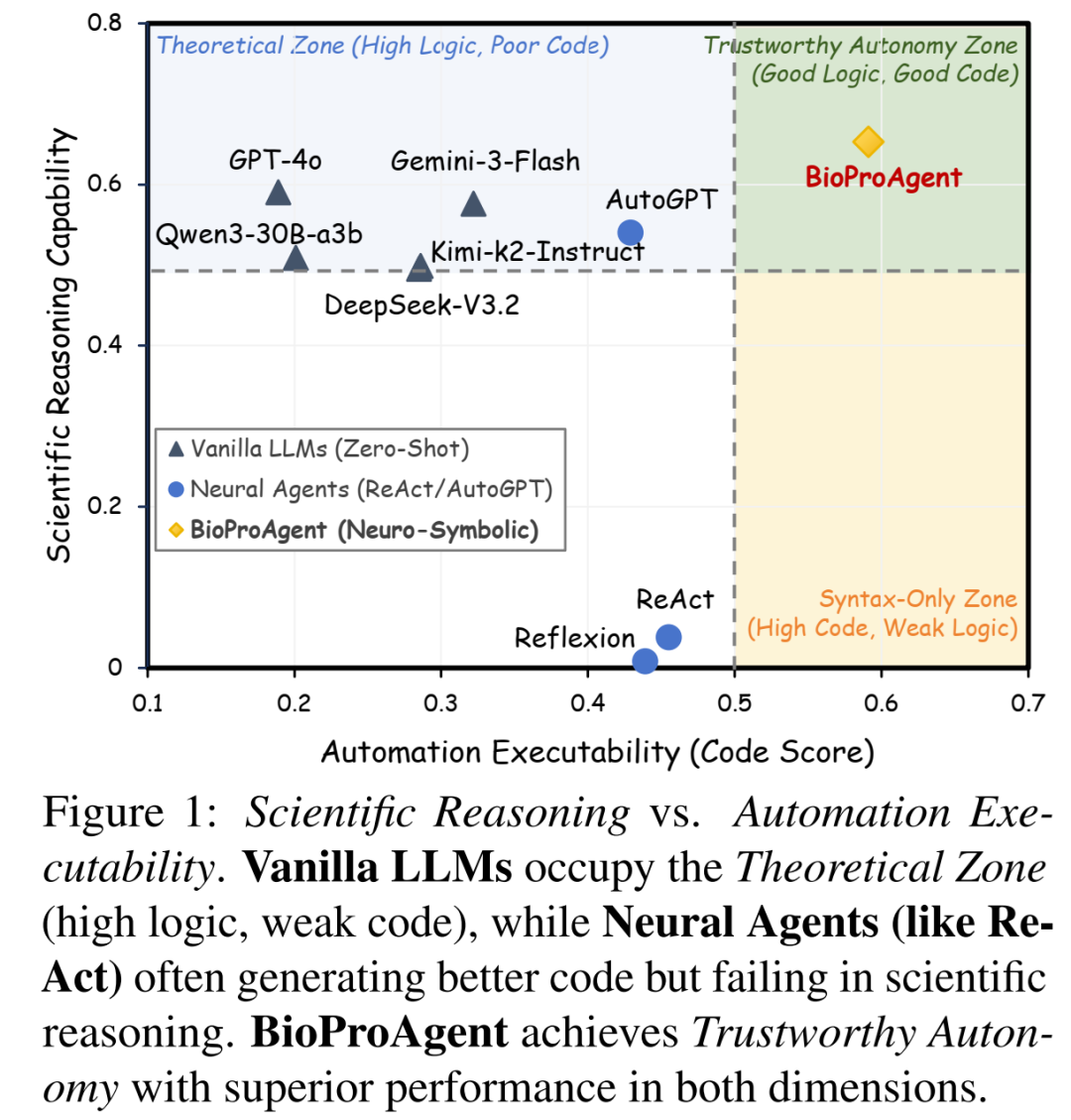
近日,北京大学团队在 arXiv 上发表了被 ACL 2026 录用的重磅论文 《BioProAgent: Neuro-Symbolic Grounding for Constrained Scientific Planning》。该研究首次提出了一套训练无关(Training-free)的神经符号框架,成功将概率推理锚定在确定的物理规则之上,让 AI Agent 在复杂生物实验中的物理合规率飙升至 95.6%(传统方法仅为 21%)。
今天,「图科学实验室」就带大家拆解这个可能改变未来科研模式的硬核系统,看它如何为我们的实验室装上“自动驾驶”系统。
01. 痛点直击:为什么 ChatGPT 不能帮你做实验?
在深入探讨 BioProAgent 之前,我们必须理清一个核心问题:为什么基于 LLM 的通用 Agent(如 ReAct, AutoGPT)无法直接用于真实的科学实验?
论文指出,现有 Agent 在面临高风险、长周期的物理实验时,存在三大致命缺陷:
认知漂移(Cognitive Drift)与上下文丢失:一个完整的实验协议动辄几百个步骤。在处理庞大的设备参数时,Agent 极易陷入“Lost in the Middle”困境,混淆试剂 ID 或忘记前序步骤的物理限制。
缺乏执行前互锁(Pre-Execution Interlocks):现有的 Neuro-Symbolic 方法(如 PAL、SayCan)只关注逻辑正确性,缺乏基于物理规则的确定性控制机制。它们无法在代码执行前“踩刹车”。
不可逆的安全隐患:在虚拟环境里,Agent 可以无限次试错;但在湿实验室,一次越界的操作就会导致设备损坏或样本报废。
简单来说,纯神经网络的“随机鹦鹉”特性,绝对驾驭不了需要 100% 精准度的精密仪器。
02. 核心解法:给 LLM 套上“确定性紧箍咒”(FSM)
为了彻底堵死这些安全漏洞,北大团队提出了一个极其巧妙的架构:BioProAgent。
它的核心思想是“分而治之”——让 LLM 负责灵活的创造性推理(Neural),让确定性算法负责严苛的物理规则校验(Symbolic)。两者通过一个有限状态机(FSM)无缝衔接。
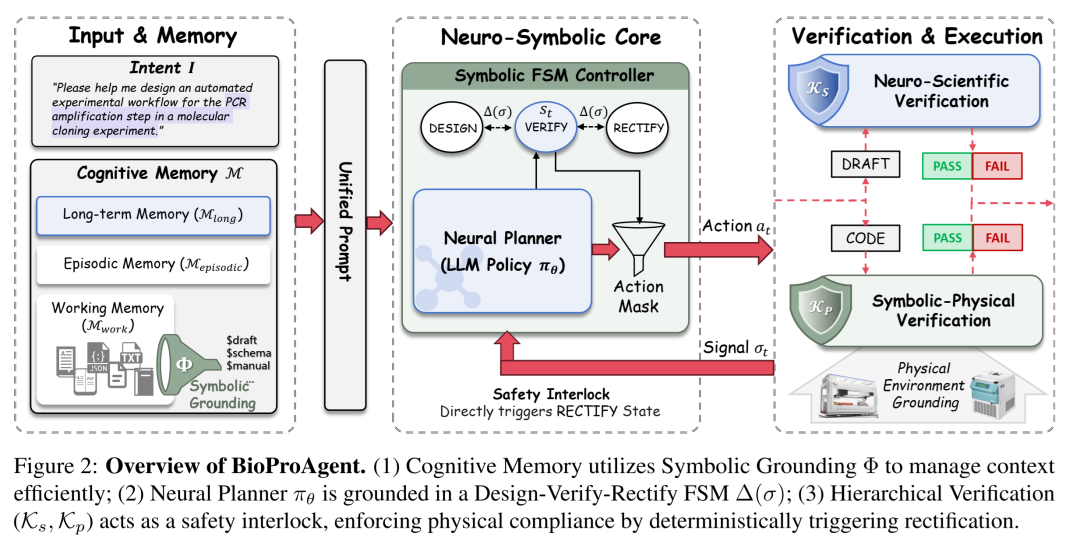
图1:BioProAgent 整体架构示意图。左侧为结构化记忆与符号化抽象模块,右侧为 FSM 控制的“设计-验证-修正”闭环工作流。
创新点一:状态增强规划(Design-Verify-Rectify)
BioProAgent 抛弃了传统 Agent 那种“想到哪写到哪”的线性生成模式,而是引入了一个由 FSM 驱动的严格工作流:设计(Design) ➡️ 验证(Verify) ➡️ 修正(Rectify)。
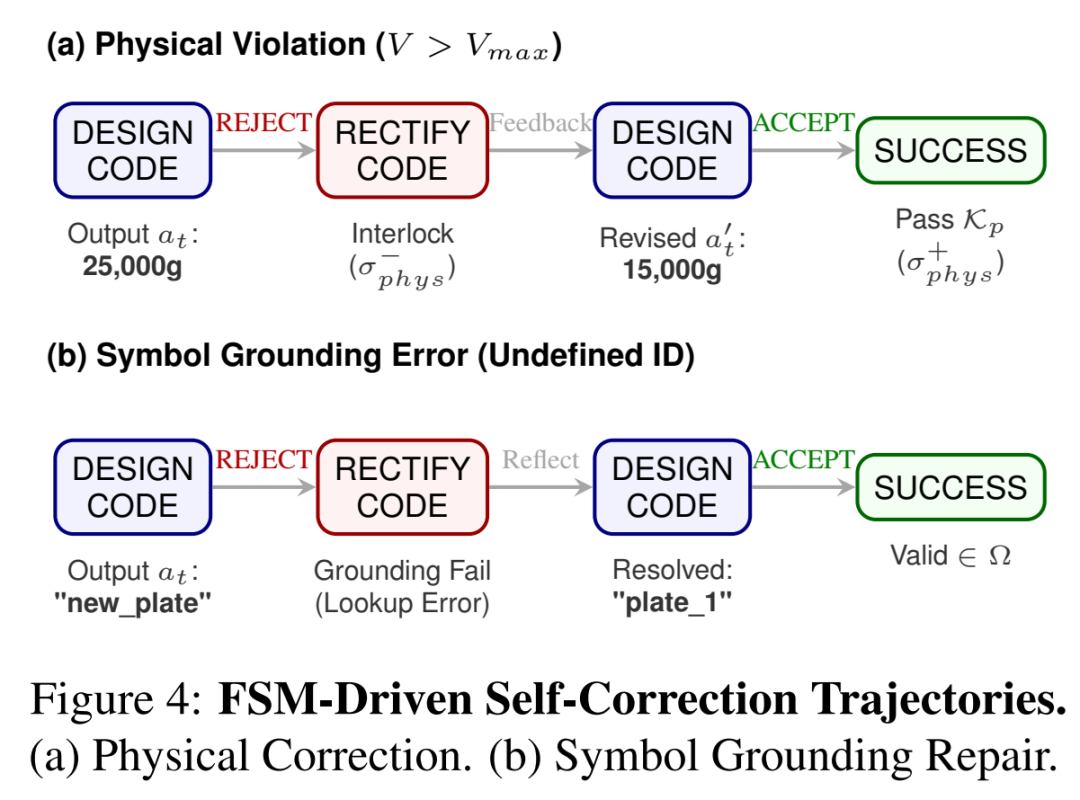

图2:BioProAgent 的确定性有限状态机(FSM)控制器。当物理规则校验失败时,系统会强制触发“INTERLOCK”信号,将状态强行拉回 RECTIFY 阶段,阻止非法代码执行。
这个 FSM 就像是一个极其严苛的实验室导师,它定义了 Agent 在不同阶段能做什么。例如,只有当“科学反思器”确认草案无误后,Agent 才能进入代码编写阶段;而一旦“物理规则引擎”发现代码参数超标,系统会立刻触发强制转移(Force Transition),打回重做。

表 1:FSM 优先级决策矩阵(部分)。系统会根据当前的上下文信号(如 σ_phys物理校验失败),按优先级跳转至目标状态(如 RECTIFY_CODE)。这种确定性路由确保了非法操作永远无法触及真实硬件。
创新点二:语义符号接地(Semantic Symbol Grounding)
除了安全性,长上下文处理也是一大难题。一个完整的设备 JSON 模式往往超过 10k tokens,全部喂给 LLM 不仅昂贵,还会导致模型注意力分散。
BioProAgent 采用了一种极简主义的符号抽象方法:将具体的设备参数映射为轻量级的符号指针(key-value 对)。
设计阶段:LLM 只需要处理逻辑流,操作符号化的 Key,Token 消耗骤降约 6倍。
执行阶段:系统通过解析函数,将符号指针无损还原为真实的物理参数(Value)。
这就好比写代码时调用变量名而不是直接把大段数据写在行内,既清爽又不容易出错。
03. 降维打击:95.6% 的物理合规率是怎么炼成的?
理论再完美,也要看疗效。研究团队在扩展版的 BioProBench 基准上,对 BioProAgent 进行了严苛的测试。该基准包含 22 种仪器的 API 约束,涵盖液体处理、温控、离心等多个维度。
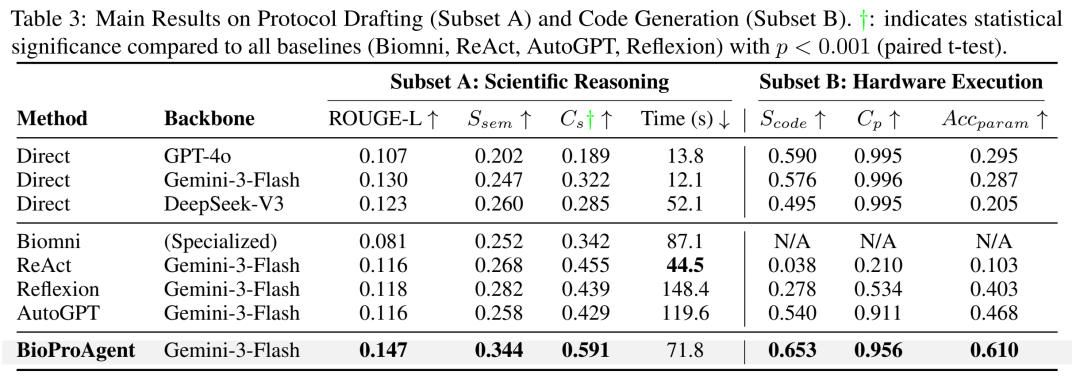
表 3:协议起草(Subset A)与代码生成(Subset B)实验结果。 相比基线模型,BioProAgent 在科学性(Cs)和物理合规性(Cp)上均取得显著提升,且参数准确率(Acc_param)大幅领先。
数据说明了一切:
安全性碾压:传统强力 Agent(如 ReAct)虽然试图完成复杂操作,但物理合规率(Cp)惨不忍睹(仅 21%),这意味着它每执行 5 次操作就会有 4 次可能引发实验室事故。而 BioProAgent 将这一指标提升至惊人的 95.6%。
打破“保守陷阱”:普通的 Direct Prompting 虽然合规率高(99.5%),但那是因为模型过于保守,拒绝执行复杂操作,导致参数准确率极低。BioProAgent 则在保证安全的同时,完美完成了复杂任务。
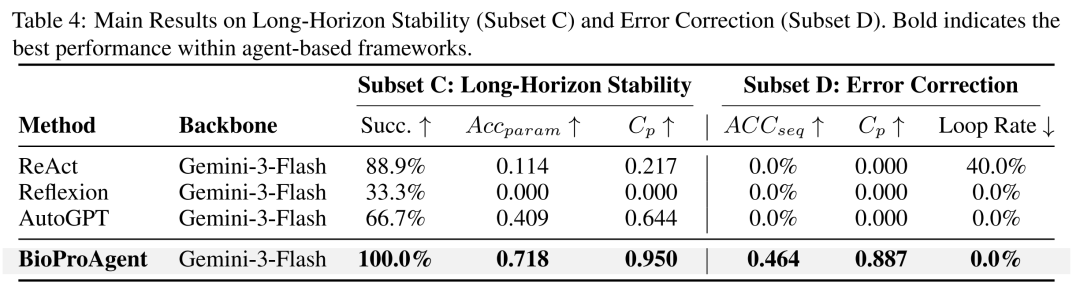
表 4:长程稳定性(Subset C)与纠错能力(Subset D)实验结果。 BioProAgent 在面对超长流程和人为注入的错误时,展现了极强的鲁棒性。
更震撼的是在长流程(Subset C)和错误纠偏(Subset D)测试中:
面对长达数百步的实验流,所有基线模型都出现了不同程度的“失忆”或崩溃,而 BioProAgent 保持了 100% 的成功率和极高的物理一致性。
当人为注入物理违规错误时,传统 Agent 要么直接放弃(0% 纠正率),要么陷入死循环;而 BioProAgent 凭借 FSM 的强制路由,硬生生把物理合规率拉回到了 88.7%。
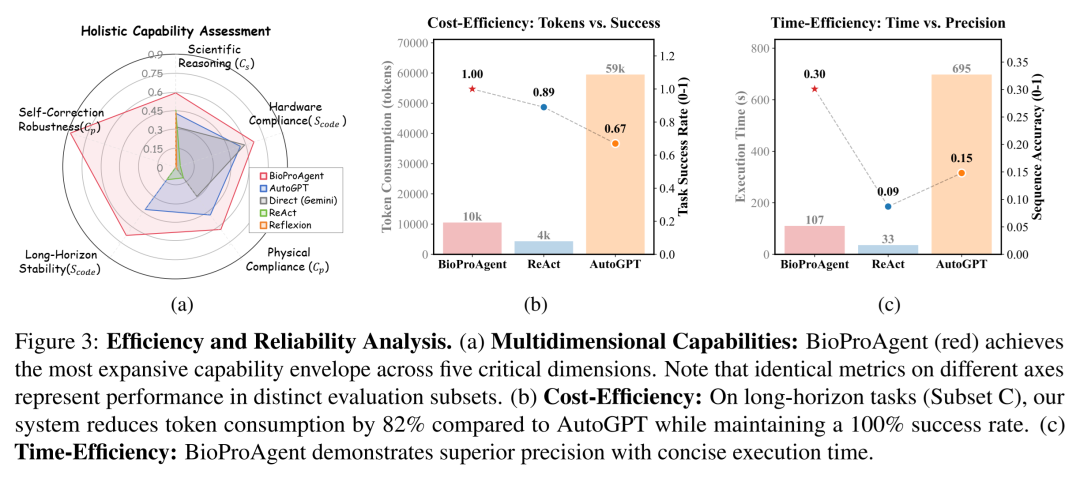
图3:Agent 综合能力信封曲线(Capability Envelope)。气泡大小代表 Token 消耗量。可见 BioProAgent(紫色)在拓展各项能力边界的同时,极大降低了资源消耗。
04. 写在最后:科研自动化的下一站在哪里?
BioProAgent 的出现,不仅仅是一个算法的胜利,它为我们指明了AI4Science 落地的必经之路:概率模型与确定性系统的深度融合。
对于每天泡在实验室里的本硕博们来说,这项研究无疑是一个强烈的信号:未来的科研不再是我们单打独斗去重复那些繁琐、易错的机械操作,而是学会如何与智能体协作,让 AI 成为我们可靠的“数字同事”。
当神经符号系统真正普及,也许用不了几年,我们就能在深夜安心入睡,而把执行实验的重任交给那个永远不会疲倦、也不会犯错的 BioProAgent 了。
你怎么看 AI Agent 在你们领域的应用前景?欢迎在评论区留言讨论!
喜欢今天的硬核解读吗?别忘了点赞、在看并分享给身边的同学,关注「图科学实验室 Graph Science Lab」,和我们一起探索科研的前沿边界!



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢