

Stanford CS224W: Machine Learning with Graphs
代码下载:https://t.zsxq.com/Fwwu1
请索引第33个项目
 |  |
背景
公元79年维苏威火山爆发后,数百卷古代文献被掩埋在庞贝和赫库兰尼姆古城中,得以保存至今。由于无法在不破坏内容的前提下展开这些卷轴,人们开发了非侵入式方法来解读其中的内容。这种方法包括对卷轴进行CT扫描,生成由二维CT切片组成的数据集[2]。维苏威挑战赛(https://scrollprize.org/)正致力于利用这些数据解码卷轴,该挑战赛采用机器学习方法来检测CT扫描图像中的墨迹,并实现卷轴的虚拟展开。
动机
考虑到仍需人工验证,目前虚拟展开整卷卷轴的方法和模型将耗资100万至500万美元。由于仍有300多卷卷轴尚未解读,因此需要大幅提升模型迭代时间和精度,尤其要着重于大规模展开[1]。重建剩余的卷轴将揭示古代文学中失落的作品,使历史学家和古典学家受益匪浅。
虚拟展开过程的一部分涉及使用图表示将从CT数据分割出的卷轴图像块拼接在一起。目前的方法使用随机游走或基于优化的方法来解决这个问题,但速度慢且难以操作。我们的目标是将图神经网络(GNN)技术应用于这种基于图的图像块拼接问题,从而实现更高效、更精简且更具通用性的方法。此外,归纳式GNN模型可以更方便地用于快速拼接来自未知卷轴的卷轴图像块图。
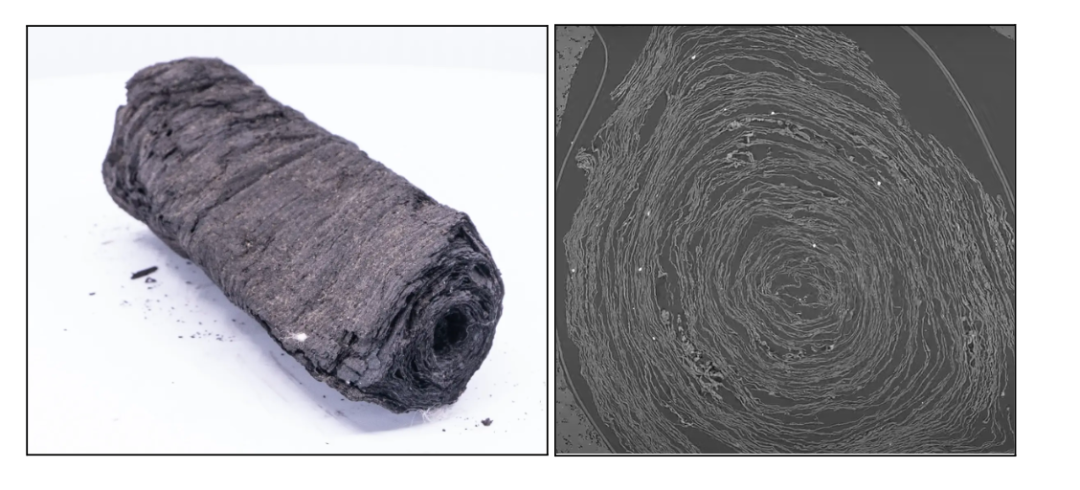
图 1:左侧是那不勒斯国家图书馆的 PHerc. 332(卷轴 #3),我们在本项目中对其进行分析并用于训练/测试。右侧是 PHerc. 332 的 CT 扫描切片 [1]。
数据
EduceLab-Scroll 数据集包含多个卷轴和卷轴碎片的体积 X 射线微型 CT 扫描数据,分辨率为 2.24μm 至 27.17μm。本项目准备工作中使用的数据来自 EduceLab-Scrolls 数据集 [2]。该数据集由维苏威火山项目公开提供(需遵守相关条款):https://scrollprize.org/data。
为了将这些数据转换为用于拼接问题的图表示,必须遵循一个详细的流程(如下所述)。为此,我们还提供了一个预先计算好的图表示,该图表示是其中一个卷轴(卷轴 3)的一部分,并提供了一个将其转换为与 torch_geometric 兼容格式的流程。在我们的流程中,我们将现有的 ScrollGraph 对象转换为 NetworkX 图,然后再将 NetworkX 图转换为 PyG Data 对象。我们确保包含 ScrollGraph 对象中的相关节点特征和标签,并根据训练集和测试集的比例拆分数据集中的节点。
defconvert_scrollgraph_to_networkx(scroll_graph):
graph = nx.DiGraph(name="scroll graph")
nodes = scroll_graph.nodes
nodes_to_add = []
print("length of node items", len(nodes.items()))
for key, val in tqdm(nodes.items()):
# include a subset of the features
centroid = val['centroid']
assigned_k = val['assigned_k']
winding_angle = val['winding_angle']
nodes_to_add.append((key, {'winding_angle': winding_angle, 'centroid': centroid, 'assigned_k': assigned_k}))
graph.add_nodes_from(nodes_to_add)
edges = scroll_graph.edges
# convert the edges into connections between nodes
edge_list = []
for edge in tqdm(scroll_graph.edges):
#ignore the k offset being the key
for number, edge_info in scroll_graph.edges[edge].items():
# only add edges between non-deleted nodes
if (not nodes.get(edge[0])) or (not nodes.get(edge[1])):
continue
# add edge but do not append edge features
edge_list.append((edge[0], edge[1]))
graph.add_edges_from(edge_list)
return graph正如“图问题”部分将要描述的那样,我们有一个初始图和一个已求解的图。初始图包含噪声节点,这些节点在已求解的图中会被移除;已求解的图则包含节点的真实标签。在我们的流程中,我们将来自初始图和已求解图的信息合并成数据对象,用于训练和测试。
预处理
要得到该图表,需要经过从 CT 扫描图像到点云数据的各种步骤,我们将简要描述这些步骤。
首先,我们将所有工作托管在 AWS EC2 实例上,用于存储卷轴数据和模型。我们使用Vesuvius 数据下载仓库(https://github.com/JamesDarby345/VesuviusDataDownload),通过 rclone 获取所有二维 X 射线 CT 扫描数据,这些数据共同构成了卷轴的体积。接下来,我们利用这些数据生成图对象,并遵循ThaumatoAnakalyptor 仓库(https://github.com/ScrollPrize/villa/tree/main/thaumato-anakalyptor)中概述的步骤和脚本。启动 Docker 容器后,我们首先将图像分辨率下采样至 8μm,以简化分割过程。利用下采样后的网格,我们检测高梯度区域以识别表面,并在检测到的纸莎草表面上输出三维点云数据。最后,我们使用 Mask3D 分割模型 [3] 将点云数据块分组。

图 2:PHerc_332(滚动 3)图由ThaumatoAnakalyptor求解器遍历,以确定每个节点的绕数。
在之前的迭代中(Chesler [4]、Schilliger [5, 7, 8]、Mou 和 Ahmed [6]),他们实现了一种拼接算法,该算法将分割的表面块视为节点,边的建立基于相似度得分,该得分取决于块与其他块的重叠程度。过去的方法利用子图上的随机游走来过滤掉噪声节点,并为每个节点分配一个卷绕数(卷绕层)。最近的研究则使用图上的最大后验概率 (MAP) 估计求解器来分配卷绕角度和卷绕数,以最小化与图的物理约束相关的目标函数 [5, 7, 8]。一旦使用分配的卷绕数将块拼接在一起,该流程就会使用泊松表面重建为每个半卷绕创建一个非流形网格。然后使用对称 L1 能量最小化 (SLIM) 对生成的网格进行展平以进行纹理参数化,最后使用 TIFF 表面重建进行渲染 [8]。
图论问题
对于每个分割好的面片,我们都有其质心的三维坐标(质心是其点云表示中所有点的“平衡点”)。根据它相对于卷轴中心(即“脐点”)的位置,我们还可以得到一个介于 -180 度到 180 度之间的角度,该角度表示它相对于中心的角位置。我们将此角度称为初始卷绕角。
每个色块都被视为一个节点,并通过边与被认为与其接近/相似的色块相连,这是由预处理中计算的分数确定的。
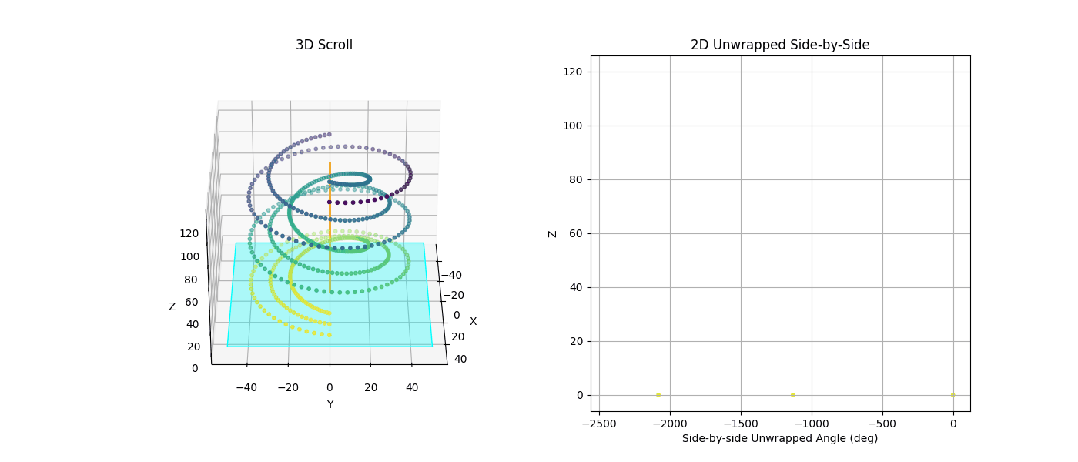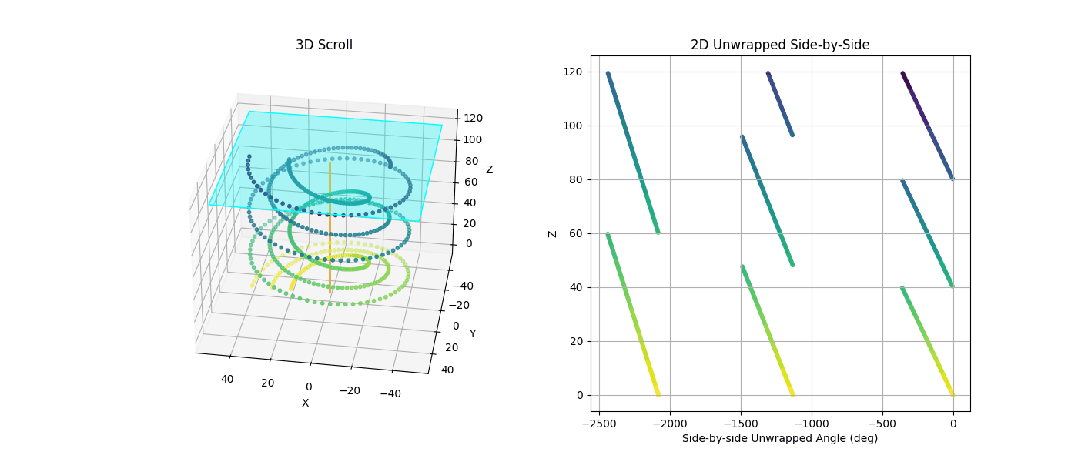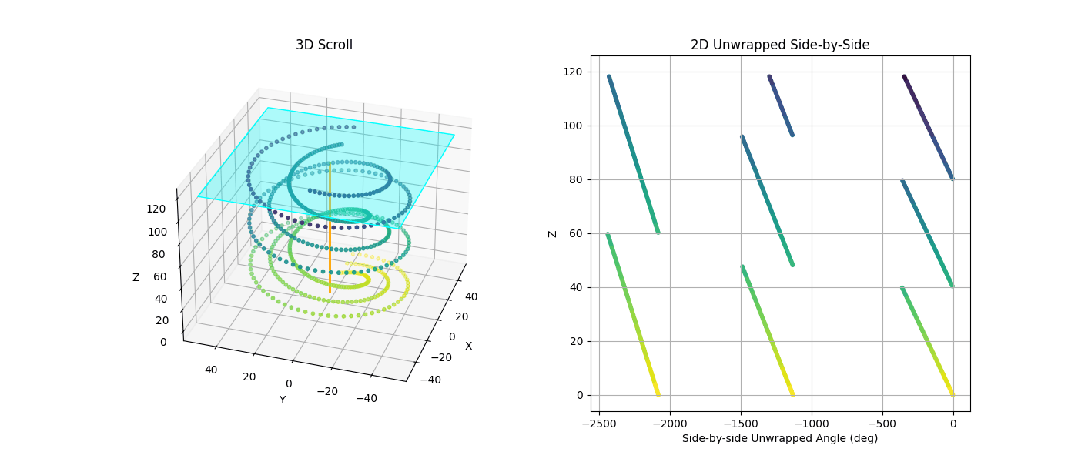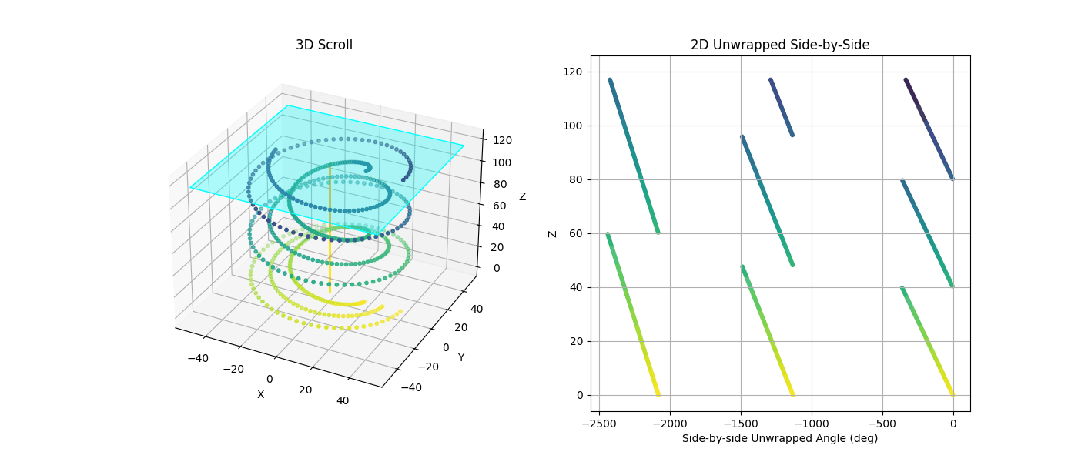
图 3:我们制作的动画,展示了一个由 3 张不同纸张螺旋缠绕而成的合成 3D 卷轴。我们可以看到,我们的目标是获取卷绕次数,以便将这些纸张投影到并排的 2D 视图中。
该图论问题的目标是既要滤除噪声块,又要确定更新后的卷绕角,该卷绕角指示块位于卷轴的哪一层。上述初始卷绕角无法提供关于块位于卷轴哪一层的信息。更新后的角度可以小于-180°,并且大致为a - 360*k,其中k表示块所在的层,a表示初始卷绕角。[5][7][8]
我们将这一层级问题分为两种解决方法:
确定补丁的层数:这是一个节点分类问题,类别数等于卷轴的层数(或 CT 扫描的切片数)。
直接确定更新后的绕线角度:这是一个节点回归问题,目标是预测与真实值“更新后的绕线角度”相似的角度值。
此外,还存在噪声块问题,其中许多块可能是伪影点云数据,与其余块在物理上不一致。现有算法会根据与相邻块的不一致性删除噪声节点。这实际上是一个二元节点分类问题。我们将一个块分类为 0(如果它是真正的块)或 1(如果它是噪声块)。
总的来说,我们使用各种 GNN 预测了 3 项任务:层多类分类、绕角回归和噪声分类。
现有方法
以往的方法使用随机游走来分配卷绕数和角度,而最新的方法则使用了一种基于物理约束优化目标的求解器。它采用基于弹簧的能量模型,经过多次迭代,逐步降低弹簧常数,最终收敛到低能量状态。简而言之,它将卷轴中连接各个区域的每条边都视为一个弹簧,并尝试每个节点的各种卷绕数,以降低系统在稳定状态下的能量。从概念上讲,具有高置信度连接边的节点之间的卷绕数应该相差不大,这意味着求解器会根据这些物理约束找到一个合理的卷绕数分配启发式方法。为了分配卷绕数,他们使用了一个环形求解器,该求解器强制起始种子节点的后续邻居节点的卷绕数单调递增。在此阶段,它还会通过检测最大的连通分量来过滤边并删除噪声节点,从而消除超过某个阈值对系统的干扰。[8, 9]
这种方法的局限性在于其C++实现门槛高、计算时间长,并且基于启发式学习。此外,该实现还不够完善,经常会遇到内存管理问题。我们对其进行了修改,使其能够运行几个周期,从而获得真实的绕线角度、绕线数和噪声节点数据。我们的目标是利用这些数据训练图神经网络(GNN),以创建比当前图求解器更具泛化能力和效率的模型。
将图神经网络应用于此问题
特征增强
该图以质心(x,y,z)坐标和起始卷绕角度(取值范围为[-180, 180])作为唯一的节点属性。我们还拥有每一层的脐点坐标,脐点是穿过卷轴中心的理论直线。为了进行特征工程,我们计算了能够更好地捕捉点云图结构并更准确地表示每个节点相对于脐点的几何形状的节点特征。
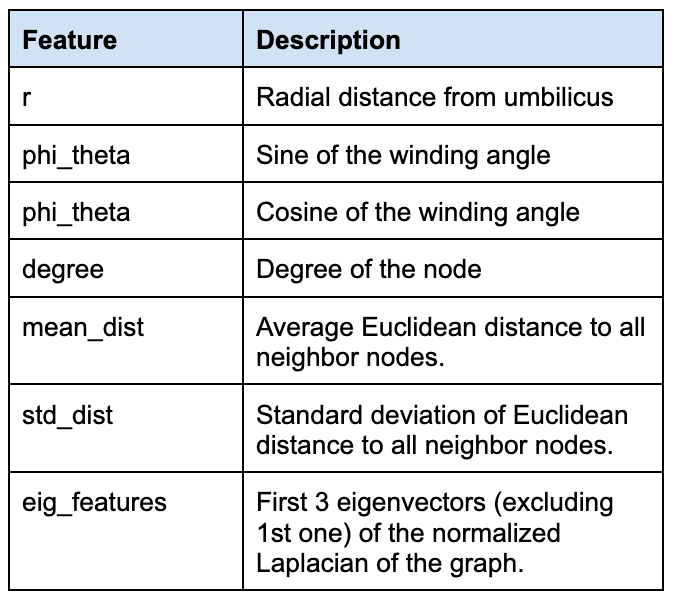
节点特性。
我们还计算了各种边特征,以用结构信息来增强图。
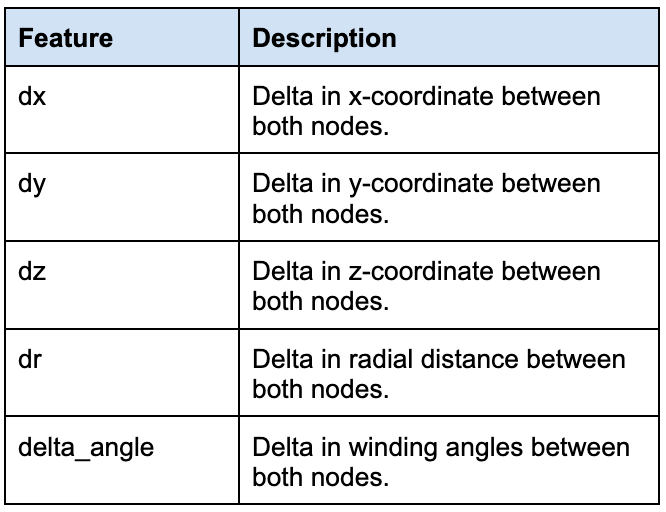
边缘功能。
我们知道,特征值越大,对应的特征向量就越能反映局部结构。在我们的消融实验中,我们比较了仅使用原始节点特征的模型与结合了我们添加的边和节点特征的模型的性能。
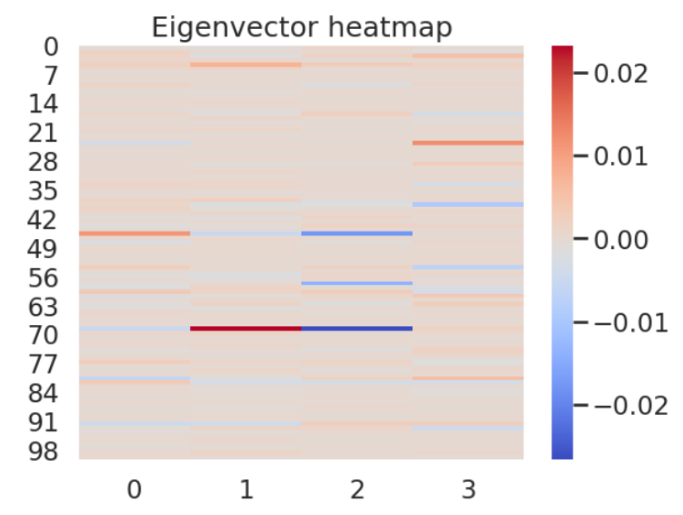
图 4:特征值越高,图的局部结构越丰富。图中展示了归一化拉普拉斯矩阵 D^(-1/2)LD^(-1/2) 的前 4 个特征向量及其在采样图中的元素的热图。我们使用特征向量 1、2 和 3 作为节点特征。
模型
我们使用PyG 内置的 GNN 模型(https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#models)快速比较了不同模型类型在这些任务上的有效性。我们比较了图卷积网络 (GCN) [13]、GraphSAGE [14]、图同构网络 (GIN) [15] 和图注意力网络 (GAT) [16] 模型。
由于 GIN、GAT 和 GraphSage 都是归纳模型,因此能够很好地泛化到未见过的图,我们希望它们能为未来处理未见过的滚动图的应用提供良好的解决方案。因为每种模型架构使用的消息传递、聚合和更新方法略有不同,我们旨在通过实验来确定哪种模型最适合每项任务。
除了这些内置模型之外,我们还实现了 DCGNN(Wang 等人,2019)[10],这是一种专门用于学习点云数据的 GNN。由于我们的图源自点云数据,我们认为该模型可能优于其他更通用的 GNN 模型。DGCNN 的主要创新点在于 EdgeConv 层。该论文对连接点对的边应用了类似卷积的操作。他们还允许图是动态的,其中节点的 k 个最近邻节点在每一层都会发生变化。这种操作具有置换不变性和部分平移不变性,“在保持全局形状信息的同时平衡了局部信息”[10]。形式上,他们定义了一个具有共享 MLP 权重的非对称边函数:
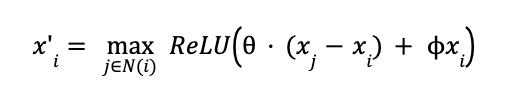
这在数学上等价于学习连接上的线性层,如 PyG 文档 [9] 所示:
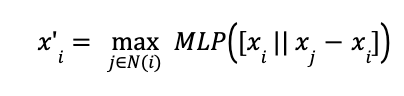
我们可以看到我们使用 PyG 支持的 PyG EdgeConv 层实现的 DGCNN 代码。我们采用了 5 层,使用 ReLU 激活函数和 dropout 正则化,并使用交叉熵损失函数进行多分类任务(预测每个节点所在的层)。
classDGCNN(nn.Module):
def__init__(self, in_channels, hidden_channels, out_channels, num_layers=5):
"""
DGCNN with EdgeConv layers
Args:
in_channels (int)
hidden_channels (int)
out_channels (int)
num_layers (int)
"""
super().__init__()
self.convs = nn.ModuleList()
for i inrange(num_layers):
in_c = in_channels if i == 0else hidden_channels
self.convs.append(
EdgeConv(
nn=nn.Sequential(
nn.Linear(2 * in_c, hidden_channels),
nn.ReLU(),
nn.Linear(hidden_channels, hidden_channels)
)
)
)
self.mlp = nn.Sequential(
nn.Linear(hidden_channels, hidden_channels),
nn.ReLU(),
nn.Linear(hidden_channels, out_channels)
)
defforward(self, x, edge_index, batch=None, return_embed=False):
embeddings = []
for conv in self.convs:
x = conv(x, edge_index)
embeddings.append(x)
if batch isnotNone:
x = global_max_pool(x, batch)
out = self.mlp(x)
if return_embed:
return out, embeddings
else:
return out平滑损失项
预测缠绕角的回归任务对于我们的模型来说非常困难,并且容易出现异常预测,因为在我们的数据集中,缠绕角最大可达约 2500 度(因为每个螺旋都是 360 度,而我们研究的卷轴有 7 层)。受求解器单调性约束的启发,我们尝试在模型中添加一个潜在的损失项来捕捉这一物理约束。我们称之为平滑性损失,因为它会惩罚模型给出与其相邻区域缠绕角差异过大的情况,从而确保在卷轴中跟随相邻区域时,缠绕角能够平滑变化。我们将其定义为:
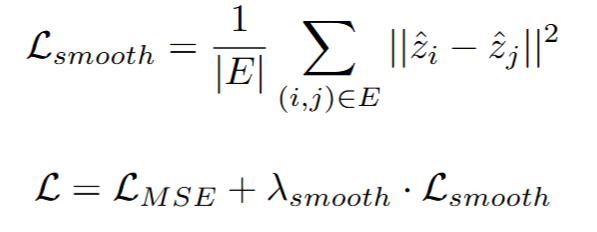
平滑损失的公式以及如何将其与 MSE 损失结合起来。
我们可以看到,我们对节点对预测缠绕角之差的平方进行惩罚,并将其加权到均方误差损失中,权重项为某个值,我们根据经验将其设置为 0.30。以下是我们在 Python 中实现该算法的方法:
defsmoothness_loss(pred, edge_index):
i, j = edge_index
diff = pred[i] - pred[j]
return (diff**2).mean()
...
if use_smoothness_loss:
loss += lambda_smooth * smoothness_loss(out, data.edge_index)跳跃知识 LSTM
我们比较了启用和禁用内置PyG Jumping Knowledge 模式(使用 LSTM)的 GraphSAGE 的性能。Jumping Knowledge 允许中间表示为最终节点嵌入提供信息。启用 LSTM 的版本使用注意力机制来确定哪些邻域范围与最终表示最相关。我们排除了这种修改,因为 Jumping Knowledge 此前已被证明可以提高各种 GNN 架构的性能。[17]
性能
图层分类
这些多类层分类任务的结果没有使用边/节点特征,并且每种模型类型都具有相同的层数和超参数。
GraphSAGE准确率:0.84
GAT准确率:0.71
GIN准确率:0.82
GCN准确率:0.83
DGCNN准确率:0.81
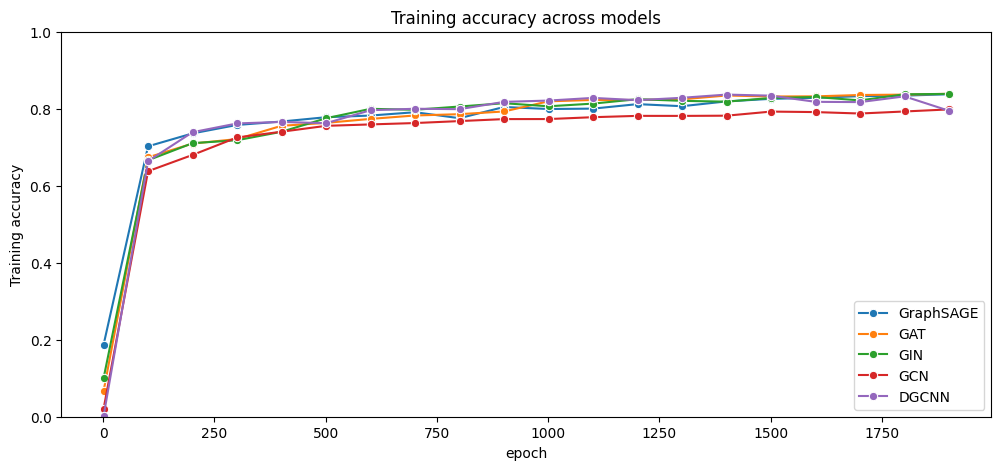
图 5:我们可以看到多类层分类任务的训练准确率随时间的变化。可以看出,GraphSAGE 的表现最佳。
绕线数回归
这些结果是在考虑平滑度损失但未包含边/节点特征的情况下得到的。我们可以看到,GraphSAGE 和 DGCNN 在回归任务中表现最佳。
GraphSAGE 平均绝对误差:135.62
GAT 平均绝对误差:192.19
GIN 平均绝对误差:408.33
GCN 平均绝对误差:257.20
DGCNN 平均绝对误差:93.58
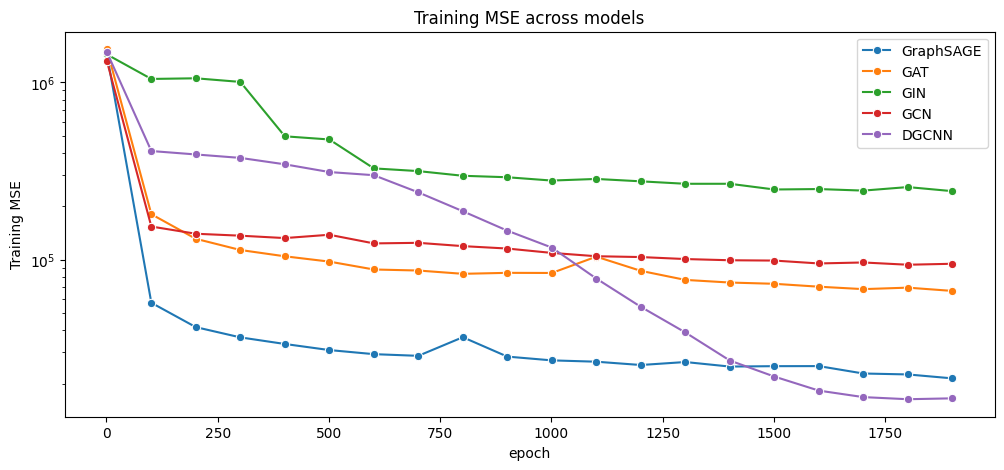
图 6:各模型训练损失随时间变化的对比。我们可以看到,DGCNN 和 GraphSAGE 在绕线角回归任务上表现最佳。
噪声斑块分类
对于噪声块的二元分类,我们发现 GIN 在此任务上的表现优于所有其他模型。
GraphSAGE准确率:0.69
GAT准确率:0.66
GIN准确度:0.75
GCN准确率:0.51
DGCNN准确率:0.64
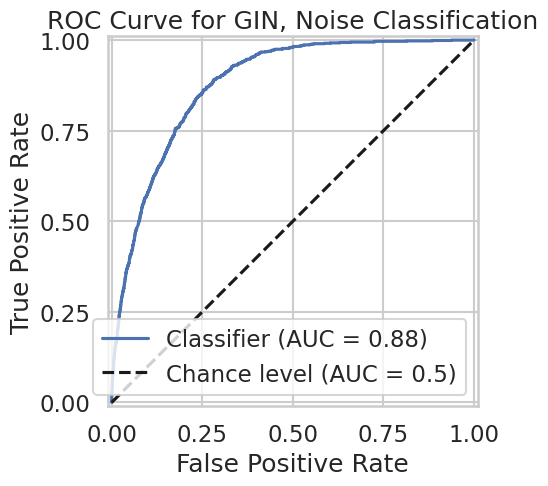
图 7:我们的二元分类 GIN 模型的 ROC AUC 图,用于确定哪些节点是噪声,应该删除还是不应该删除。
回归任务的消融分析
我们希望了解模型开发的不同组成部分如何影响回归任务。我们纳入了节点特征(包括特征向量特征)、边特征、平滑损失项以及多种模型类型。为了进行消融分析,我们创建了一个消融配置,可以轻松地启用或禁用每个组件,并可以按如下方式调用它们:
@dataclass
classAblationConfig:
use_node_features: bool = True
use_edge_features: bool = True
use_smoothness_loss: bool = False
lambda_smooth: float = 0.3
model_name: str = "DGCNN"
example_ablation_settings = [
AblationConfig(model_name="GraphSAGE",
use_node_features=False,
use_edge_features=False,
use_smoothness_loss=False),
AblationConfig(model_name="DGCNN",
use_node_features=True,
use_edge_features=False,
use_smoothness_loss=False)
]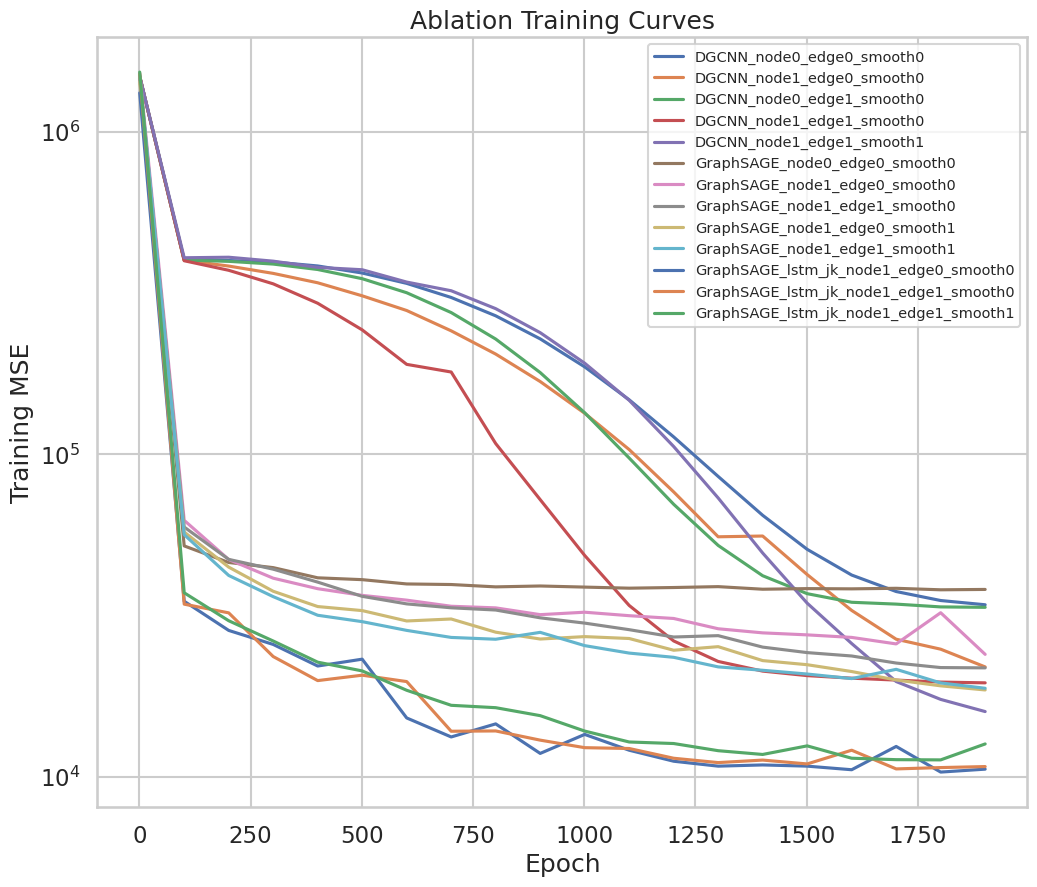
图 8:消融分析中各种模型的训练损失。我们可以看到,采用 LSTM 跳跃知识的 GraphSAGE 模型表现最佳,而是否使用边缘特征或平滑损失对模型的影响并不显著。
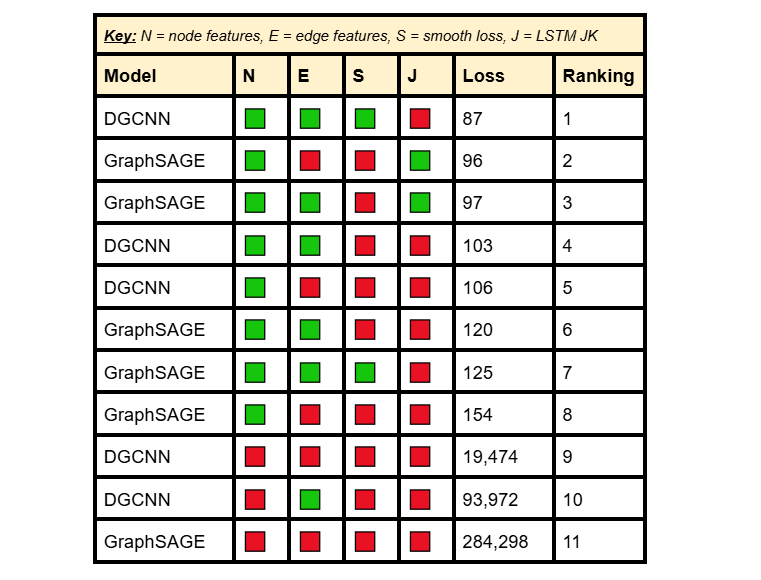
我们可以看到,节点特征对于模型在回归任务上的良好表现至关重要,这不难理解,因为特征向量特征和其他几何计算为模型提供了关键的结构信息,从而能够更好地预测角度。我们还发现,平滑损失和LSTM跳跃知识显著提高了模型性能。
延迟
我们可以看到,DGCNN模型的训练和推理速度比基于物理的求解器快近10倍。为了便于比较,两个模型都启用了GPU加速。
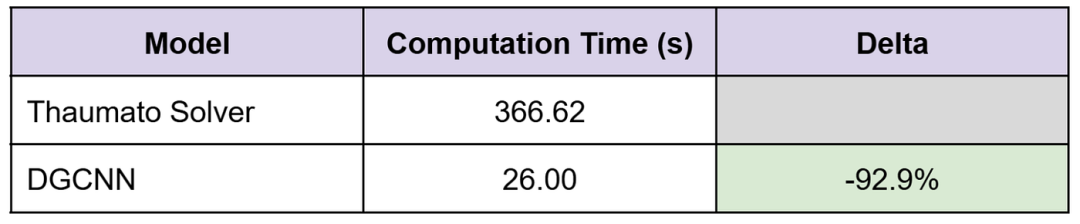
下表比较了运行 Thaumato 图求解器处理 Scroll 3 数据与在 Scroll 3 点云数据上训练 DGCNN 模型所需的计算时间。我们可以看到,当两种运行都启用 GPU 时,延迟降低了约 10 倍。
嵌入式可视化
我们采用 TSNE [12] 来表示和分析 DGCNN 模型中单个 EdgeConv 层之后的高维节点嵌入子样本。类别标签代表每一层。我们可以从下面的可视化图中看到 EdgeConv 层能够以对当前任务(分类或回归)有意义的方式表示节点。
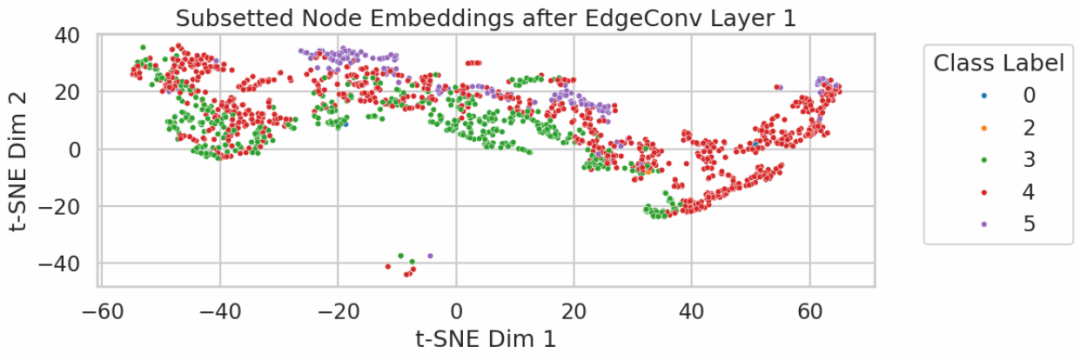
图 9:DGCNN 模型中 EdgeConv 层之后节点嵌入的 TSNE 可视化图。我们可以看到采样点主要来自第 3、4 和 5 层,并且不同节点之间存在有趣的区分/模式。
要点总结
对于古代卷轴重建中的拼接问题,图神经网络为基于求解器的方法提供了一种很有前景的替代方案。
在确定一张纸位于哪一层时,所有 GNN 的表现都类似,并且通常都能分配正确的层。
在回归绕线角方面,模型遇到了更多困难,而我们的模型改进显著提升了其性能。就模型类型而言,GraphSAGE 和我们实现的 DGCNN 模型表现最佳。消融分析表明,节点特征对于模型做出合理的预测至关重要。在此基础上,我们的平滑损失函数增加了进一步的物理约束以提高预测质量,而 LSTM 跳跃知识框架则进一步提升了模型性能。
我们的模型不仅在这些任务上取得了优异的性能,而且速度比求解器快得多(快约 10 倍),使其成为极具扩展潜力的候选方案。目前,我们已经展开了个位数的卷轴,还有 300 多卷卷轴尚未读取。利用图神经网络 (GNN) 将专家和现有求解器所掌握的高质量洞察推广到更多新的卷轴上,将使这项壮举更容易实现。
对于检测噪声片,我们的模型也获得了 0.88 的 AUC,这表明 GNN 能够利用点云关系来过滤掉噪声节点,以用于其他下游任务。
我们选择使用监督学习方法,通过计算密集型物理求解器生成的真实值结果进行训练。展望未来,我们也假设无监督或自监督方法可能对卷绕数和噪声分类任务有益。例如,对抗正则化图自编码器(ARGVA)等架构利用基于图的变分自编码器生成节点嵌入,可用于k均值聚类[11]。这种自监督学习技术可以利用图的结构特性,根据卷绕角或噪声程度对节点进行聚类。由于我们能够获得的所有关于卷绕数和真实值的数据都是通过计算得到的,因此利用固有结构特性的自监督方法可能是训练这些预测模型的更直接的方式。
总之,利用拼接技术重建卷轴是一项极具挑战性且引人入胜的任务,而图神经网络(GNN)则是一种很有前景的方法。精确的归纳式GNN模型可以加快未见卷轴的重建速度,并提高自动化的可行性。我们希望未来的研究能够在此基础上继续发展,帮助重建剩余的300多卷卷轴,揭开失落的历史。
参考文献
[1] Vesuvius Challenge. https://scrollprize.org
[2] Parsons, S., Parker, C. S., Chapman, C., Hayashida, M., & Seales, W. B. (2023). EduceLab-Scrolls: Verifiable Recovery of Text from Herculaneum Papyri using X-ray CT. ArXiv [Cs.CV]. https://doi.org/10.48550/arXiv.2304.02084
[3] Schult, J., Engelmann, F., Hermans, A., Litany, O., Tang, S., & Leibe, B. (2022). Mask3d: Mask transformer for 3d semantic instance segmentation. arXiv preprint arXiv:2210.03105.
[4] A. L. A. T. Ryan Chesler, Ted Kyi. Solution for kaggle vesuvius ink detection challenge, 2023. URL https://github.com/ainatersol/Vesuvius-InkDetection.
[5] J. Schilliger. Thaumato anakalyptor, 2024. URL https://github.com/schillij95/ThaumatoAnakalyptor.
[6] F. S. Mou and T. Ahmed. Ink detection from carbonized herculaneum papyri using deep learning. In 2023 26th International Conference on Computer and Information Technology (ICCIT), pages 1–6. IEEE, 2023.
[7] J. Schilliger. Sheet Stitching Problem Definition, 2024. https://github.com/schillij95/ThaumatoAnakalyptor/blob/main/documentation/Sheet_Stitching_Problem_Definition.pdf
[8] J. Schilliger. Thaumato Anakalyptor Technical Report and Roadmap, 2024. https://github.com/schillij95/ThaumatoAnakalyptor/blob/main/documentation/ThaumatoAnakalyptor___Technical_Report_and_Roadmap.pdf
[9] PyG Team. (2024). EdgeConv layer. PyTorch Geometric Documentation. https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.nn.conv.EdgeConv.html
[10] Wang, Yue, et al. “Dynamic graph cnn for learning on point clouds.” ACM Transactions on Graphics (tog) 38.5 (2019): 1–12.
[11] Pan, Shirui, et al. “Adversarially regularized graph autoencoder for graph embedding.” arXiv preprint arXiv:1802.04407 (2018).
[12] Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of machine learning research, 9(Nov), 2579–2605.
[13] Kipf, T. N. “Semi-supervised classification with graph convolutional networks.” arXiv preprint arXiv:1609.02907 (2016).
[14] Hamilton, Will, Zhitao Ying, and Jure Leskovec. “Inductive representation learning on large graphs.” Advances in neural information processing systems 30 (2017).
[15] Veličković, Petar, et al. “Graph attention networks.” arXiv preprint arXiv:1710.10903 (2017).
[16] Xu, Keyulu, et al. “How powerful are graph neural networks?.” arXiv preprint arXiv:1810.00826 (2018).
[17] Xu, Keyulu, et al. “Representation learning on graphs with jumping knowledge networks.” International conference on machine learning. pmlr, 2018.



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢