
MetaCompress团队 投稿 凹非寺
量子位 | 公众号 QbitAI
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
第一轮关注人物,第二轮追问背景,第三轮讨论构图,但现有压缩方法在多轮场景下集体翻车。
为应对这一挑战,浙江大学宋明黎教授团队与阿里巴巴集团安全部联合提出了MetaCompress——
一套面向多轮视觉问答的学习式Token压缩框架,被CVPR 2026录用。

研究背景
视觉Token带来的算力爆炸
当前主流LVLM如LLaVA-NeXT,通过多尺度视觉输入实现了极强的细粒度视觉理解能力,但也伴随视觉Token数量的指数级增长。
而Transformer中多头注意力的计算复杂度与序列长度呈平方关系,海量视觉Token直接导致:
Token生成延迟显著升高,实时交互体验极差 显存占用与计算量居高不下,难以在端侧、资源受限设备上部署 多轮对话中,KV缓存的复用成本随Token数量线性增长,对话轮次越多,效率越低
单轮→多轮:现有方法的核心失效场景
现有Token压缩技术虽已取得不少进展,但都只针对单轮视觉问答场景设计。
在单轮问答中,模型只需回答一次性问题,因此可以“贪婪地”只保留与当前问题相关的Token,丢弃其余信息。
但在真实的人机交互场景中,团队与模型的对话大多是多轮视觉问答模式。
在这种对话里,模型无法预判用户的后续提问,问题可能指向图片中的任意区域:
第一轮对话,用户或许只关注画面前景的人物;
到了第二轮,就会追问背景里的建筑细节;
第三轮甚至会问到整张图片的色调与构图风格。
正是这种开放式的对话特性,让现有的两类主流Token压缩方法直接陷入了困境:
Prompt依赖型方法(如FastV): 仅根据首轮文本Prompt筛选Token,天然偏向初始问题,极易丢弃后续轮次需要的关键视觉信息,直接导致多轮对话里模型性能断崖式下跌 Prompt无关型方法(如PruMerge): 仅基于视觉Token之间的相似性信息做压缩,理论上可适配多轮视觉问答场景,但完全依赖人工先验设计的启发式准则(如注意力分数),缺乏理论指导
注意力分数,真的是Token压缩的最优指引吗?
基于Prompt无关型方法可以适配多轮场景,团队重新审视Prompt无关型方法的Token压缩准则。
现有绝大多数Prompt无关型方法都把“对CLS token或者文本Prompt Token的注意力分数”作为视觉Token保留的核心依据——
注意力分数越高,视觉Token越重要。
但这个被广泛沿用的启发式设计,真的符合多轮视觉问答的需求吗?
研究成果
关键洞察:启发式注意力指引,本质是次优的
团队首先进行底层的理论范式统一:
所有Token操作,无论是剪枝(Token Pruning)还是合并(Token Merging),都可以被公式化为一个可学习的压缩映射优化问题。
简单来说,视觉Token缩减的核心目标,就是找到一个最优的压缩矩阵P,将原始n个视觉Token压缩为m个(m≪n),使得压缩前后,LVLMs对文本Prompt输入的响应分布差异最小。
基于这个统一的公式化定义,团队为每张图片单独学习了最优压缩矩阵,再分析“最优策略保留的Token”与“启发式注意力分数”之间的关联。
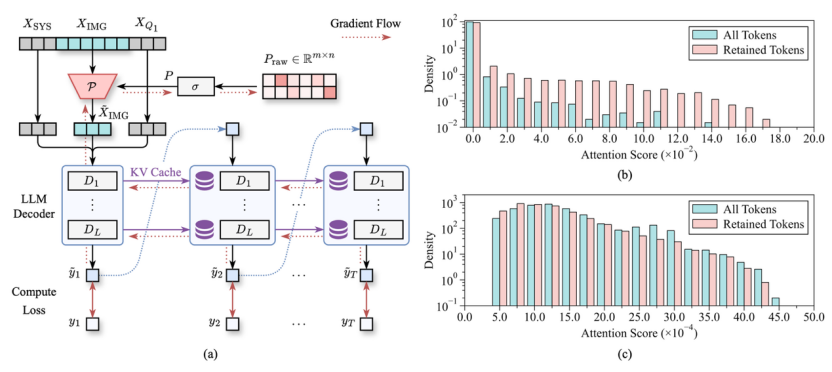
上图中(a)为最优压缩矩阵训练的整体Pipeline;(b)为最优压缩保留的Token与所有Token对CLS Token的注意力分布;(c)为最优压缩保留的Token与所有Token对文本Prompt Token的注意力分布
实验结果显示,绝大多数被最优压缩策略保留的Token,与注意力分数没有明显相关性。
即便有少量高注意力Token被保留,占比也仅为1.71%。
这个核心发现,说明了依赖人工先验的启发式注意力分数准则,在多轮对话场景下并非最优Token保留策略。
团队最终确定,必须跳出人工设计的桎梏,用数据驱动的方式,学习通用的最优Token压缩映射。
MetaCompress:面向多轮视觉问答的学习式Token压缩框架
基于上述洞察,团队提出了MetaCompress。
核心设计目标非常明确:仅根据输入图像本身,生成最优的压缩映射,在大幅缩减Token数量的同时,完整保留应对未知多轮提问的通用视觉信息。
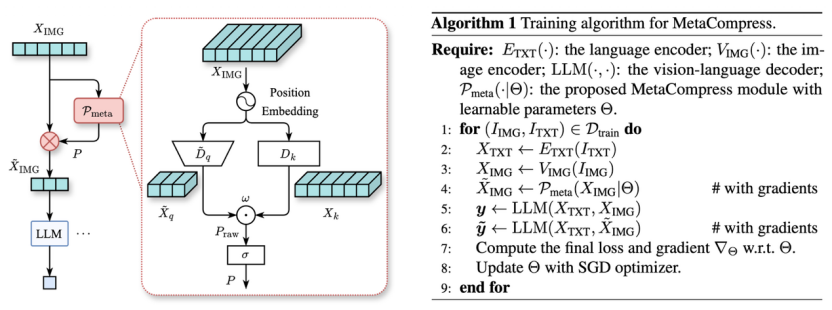 △(左)MetaCompress整体架构图;
△(左)MetaCompress整体架构图;
(右)MetaCompress整体训练Pipeline
当前主流的LVLMs普遍采用多尺度视觉塔来提升细粒度理解能力,输入图片的分辨率会动态变化,对应的视觉Token数量也不固定,这给压缩策略的生成带来了核心挑战:
固定的人工压缩规则,根本无法适配灵活多变的输入。
为此,团队设计了一个轻量级元生成器来解决这一痛点——无论输入图片的分辨率是多少、对应多少个视觉Token,它都能自适应生成匹配当前输入的最优压缩映射,可兼容LLaVA-NeXT等主流多尺度LVLMs架构。
元生成器的核心逻辑分为三点:
多尺度适配:通过自适应下采样实现灵活匹配不同视觉Token数量,兼容主流LVLMs多尺度架构,同时强化Token的空间位置信息,避免压缩时过度破坏图像的空间结构 自适应生成压缩策略:通过轻量化的特征投影,自主学习视觉Token的重要程度,全程靠数据驱动找到最优压缩方案,不用人工预设的规则来判断Token的取舍 轻量化架构:整体仅由少量线性投影层构成,额外计算开销几乎可忽略,在压缩Token降本提速的同时,完全不影响模型原本的推理速度
实验验证
团队在多个多轮视觉问答基准上,覆盖了多款主流LVLM架构的不同规模模型,完成了全面的实验验证。
结果显示:
精度表现:即使在70%和90% Token的高压缩率下,MetaCompress效果远优于现有主流Token压缩方法 推理效率:Token生成延迟、端到端推理耗时、显存占用等核心指标与等距下采样方法持平,几乎不会产生额外的推理开销 泛化能力:在未参与训练的评测基准、跨数据集及视频问答任务中,无需额外微调,效果仍优于对比方法,展现出良好的跨场景迁移性
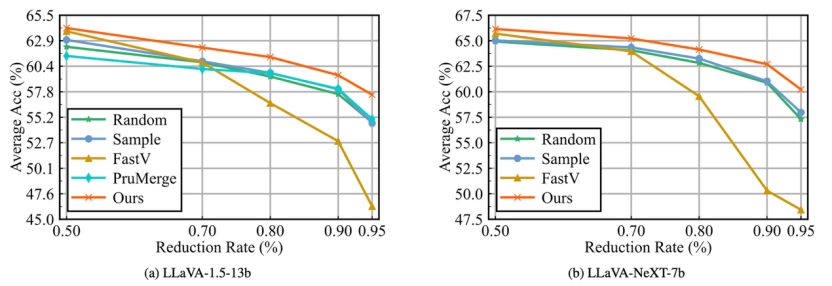 △Token压缩方法在不同压缩率下MT-GQA数据集的平均精度对比曲线图
△Token压缩方法在不同压缩率下MT-GQA数据集的平均精度对比曲线图
这项工作针对多轮视觉问答场景下LVLMs的视觉Token压缩问题,提供了一套数据驱动的解决方案。
MetaCompress面向多轮视觉问答的学习式Token压缩框架,无需依赖人工先验和启发式准则,可实现端到端的压缩映射学习。
同时仅需少量训练数据与算力开销,即可在Token压缩率与模型精度之间实现良好的平衡。
作者简介
本文第一作者为浙江大学计算机科学与技术学院博士生王毅,研究方向为多模态大模型及其加速。
其导师为浙江大学宋明黎教授,导师组成员包括宋杰副教授、张皓飞研究员。
主要合作者为来自阿里巴巴集团安全部的汪维、金炫。
论文链接:https://arxiv.org/abs/2603.21701
代码仓库:https://github.com/MArSha1147/MetaCompress
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢