

现实世界中的任务和工作天然是多模态的,人类每天都在同时处理文字、图表、截图、网页等不同类型的信息。
如今,基础模型也正从语言理解转向面向真实世界的多模态 Agentic 能力。越来越多的任务,不再只是要求模型在文本中完成推理,还需要它理解图像、视频、网页、文档以及图形用户界面(GUI),并在此基础上正确完成规划与行动。
GLM-5V-Turbo 作为新一代多模态基座模型,在保持纯文本场景下编程、推理、工具调用等能力的前提下,在多模态 Coding、Tool Use、GUI Agent 等方面取得了极具竞争力的性能。模型效果及应用案例详见:刚刚,智谱发布GLM-5V-Turbo:任意图像,皆为代码
日前,智谱(Z.ai)和清华大学团队发布了 GLM-5V-Turbo 技术报告,分享了这一多模态 Coding 基座模型背后的技术细节,以及一些更具普遍意义的 Agent 模型开发经验。我们对技术报告做了一些解读,分享给大家,希望对大家有所帮助。

技术报告链接:https://arxiv.org/pdf/2604.26752
GLM-5V-Turbo 是怎样练成的?
GLM-5V-Turbo 的核心技术改进包括以下 4 个方面:新视觉编码器 CogViT、对大规模基础设施友好的多模态多 token 预测 MMTP、覆盖感知-推理-Agent 的广覆盖联合训练,以及一套面向大规模多模态强化学习(RL)的基础设施。
1.CogViT:参数高效的视觉编码器
我们从零构建了面向多模态感知和下游 Agent 任务的视觉编码器:CogViT。我们采用两阶段预训练:
第一阶段使用基于蒸馏的掩码图像建模,让学生 ViT 在 224×224 输入、35% 掩码率下重建被遮挡区域,并同时对齐两个教师模型的特征(SigLIP2 提供语义表示,DINOv3 提供纹理特征)。训练数据按“质量感知”混合,包括 80% 高质量自然图像、10% 指令跟随数据、10% 科学图像。优化器则使用 Muon,并引入 QK-Norm 在注意力计算前对 Query 和 Key 做归一化,缓解了 logit 爆炸、提升了大规模训练稳定性。
第二阶段切换为对比式图文预训练,把视觉与文本特征对齐到同一嵌入空间。该阶段共有 3 处关键升级:用 NaFlex 方案替换固定 224×224 输入,支持变尺寸、保留原始长宽比;用 sigmoid 形式的 SigLIP loss 把全局批次扩到 64K,并配合双向分布式实现;使用 80 亿规模的中英文双语图文语料,提升跨语言理解能力。
尽管参数规模为 403M,但在通用识别、细粒度理解和空间感知上同时表现良好,ImageNet-1K 零样本分数为 83.5、38 项 CLIP Bench 分数平均为 70.4、14 项通用目标 Bench 分数平均为 45.1,在多数指标上超过 SigLIP2-SO (427M) 和 DFN-H (632M)。
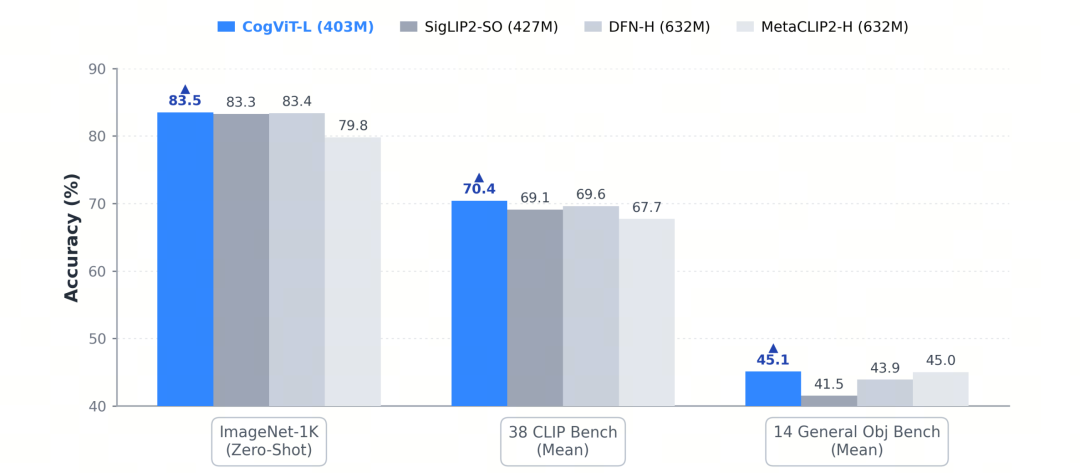
图|CogViT 与其他 SOTA 视觉编码器的性能对比
2.MMTP:让多token预测适配多模态
为在多模态场景中保留训练和推理效率,研究团队扩展了多 Token 预测(MTP),提出了“多模态多 Token 预测”(MMTP)。
在纯文本的 MTP 中,前缀 token 可以通过 ID 直接输入到 MTP head 并经过词嵌入层,但一旦输入中混有视觉 token,就要回答一个核心问题:图像 token 该如何传给 MTP head?
为此,研究团队系统地对比了 3 种方案:(1)直接把 LLM 主干的视觉嵌入传给 MTP head;(2)在 MTP head 输入端把所有视觉 token 掩码掉,退化为纯文本 MTP;(3)保留视觉位置信息,但把所有视觉 token 替换成一个共享可学习的图像特殊 token。
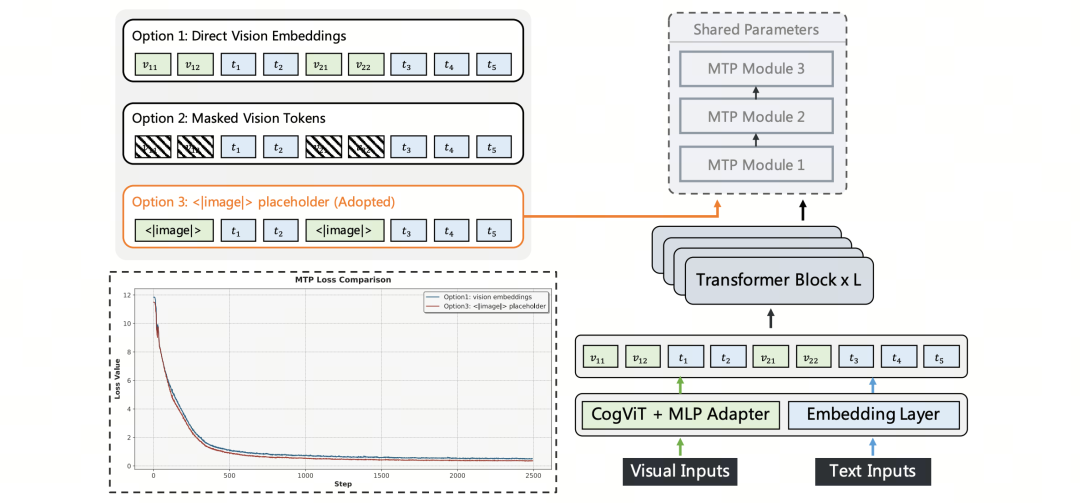
图|MMTP 设计,左下角为方案 1 与方案 3 的训练损失曲线对比,方案 3 实现了更低的损失
GLM-5V-Turbo 则采用了第 3 种方案。相比直接传视觉嵌入,图像占位符方案不需要在流水线并行的多个 stage 之间传递视觉 embedding,显著降低了通信复杂度;在 0.5B 模型上的消融实验显示,该方案训练损失更低、收敛更稳。研究团队的解释是 MTP head 通常较轻,难以有效吸收分布上与文本差异显著的视觉表示,统一形式的占位 token 反而更易优化。同时,相比“完全掩码”方案,这种设计天然兼容序列并行和上下文并行,无需额外处理视觉嵌入的分区与对齐。
3.横跨感知、推理、Agent 的广覆盖训练
在预训练阶段,GLM-5V-Turbo 深度融合了视觉与语言,多模态数据涵盖世界知识、图文交错、OCR、编程、GUI、视频、多模态工具使用、空间感知、grounding、学科问题求解等多个类别,并特别加大了多模态编程数据的比例。
随后,研究团队在 30+ 任务类别下对模型进行了联合 RL 优化。相比于监督微调(SFT),RL 阶段在感知、推理和 Agent 任务上均实现了性能提升。
此外,研究团队还指出了几个值得注意的现象。
首先,相比 SFT 中常见的跨域权衡,多任务 RL 表现出更弱的跨域干扰,多个领域均可以获得稳定的增益;其次,在分布较窄、单任务 RL 容易震荡的领域里,跨域协同训练反而通过更丰富的策略分布让优化更稳定;再者,思维模式存在跨任务迁移:一个领域学到的推理行为有时能在另一个领域带来可衡量的收益。
4.大规模多模态 RL 基础设施
研究团队表示,多任务多模态 RL 对训练系统提出了更严苛的要求,prompt 与回复长度差异大、任务有单步也有多步、每个任务可能挂着不同的规则验证器或模型验证器。
为此,GLM-5V-Turbo 团队从 4 个维度重构了训练栈。
统一任务与奖励抽象:构建 VLM RL Gym 提供统一的环境接口;引入独立奖励系统集中编排多个验证器,规则验证器本地同步执行,模型验证器通过 API 异步调用,输出按可配置策略聚合。每条样本带数据源标签,便于按来源汇报奖励与 pass@k。
全管线解耦与异步:rollout 推理、奖励评估、批(batch)构建、权重传输四阶段最大化重叠。为推理请求注册完成回调函数,单条结束就触发奖励计算,避免被长尾请求拖累;参考模型(reference model)的参数常驻 CPU 内存,在前向传播前异步预取到 GPU、用完即释放。系统还支持基于完成数或时间阈值的提前 abort,被 abort 的 prompt 可缓存复用。
面向多模态的细粒度内存管理:传统重计算策略主要面向纯文本设计,难以应对多模态输入带来的内存压力。研究团队为 ViT 与 projector 模块设计独立的内存管理策略,结合细粒度定向重计算与 CPU offload,避免激活内存随图像数量线性膨胀。
拓扑感知的视觉输入分区:常规实现中,每个 rank 要先持有完整 patch 张量再重新分发,造成不必要的内存与通信开销。研究团队把上下文并行(CP)和张量并行(TP)策略前移到数据加载阶段,与下采样组对齐分组边界,再通过异步 all-to-all 精确传输;将大型 Python 对象从 GPU 通信路径搬到 CPU 路径,实测减少了约 7GB 的 GPU 通信缓存开销。对 rollout 阶段产生的变长序列,还在序列长度和 ViT token 数两个维度上联合做 bin-packing。
多模态 Agent 能力与生态
在模型之上,研究团队继续扩展了 GLM-5V-Turbo 的多模态工具链、Agent 框架集成、官方 Skills 等。
1.多模态工具链:让Agent用图像思考
GLM-5V-Turbo 配备了一套完整的多模态工具,覆盖通用识别(植物、地点、人物)、多模态搜索(文本搜索、以图搜图、相似图搜索、学术搜索)、浏览器工具、图像处理(裁剪、绘制 2D/3D 边界框、绘制点标注、视频对象跟踪)、Web 与 PPT 创建,以及面向深度研究的工具集。

图|根据应用场景和工具集划分的多模态工具与处理功能分类
工具链扩展直接体现在搜索类基准上:MMSearch-Plus 分数为 30.0(实现近 8 倍提升)、BrowseComp-VL 为 51.9、ImageMining 为 30.7,整体在多模态深度搜索类任务上与 Kimi K2.5、Claude Opus 4.6 处于同一水平,部分指标实现超越。
2.与Claude Code、AutoClaw的框架集成
GLM-5V-Turbo 还能作为认知核心嵌入 Claude Code、AutoClaw 等外部 Agent 框架。Claude Code 负责终端环境与本地文件系统的执行逻辑,AutoClaw 提供浏览器与 GUI 自动化的"双手",GLM-5V-Turbo 在其中承担视觉-语言控制器的角色,构成完整的感知-规划-执行闭环。
3.ImageMining:以图像为入口的深度搜索基准
研究团队还推出了 ImageMining,一个专门测试“用图像思考、用图像深度搜索”能力的视觉中心基准。与传统视觉问答(VQA)不同,ImageMining 要求模型通过多步工具调用主动从图像中“挖”出线索,例如先做局部裁剪或放大细节,再以此构造搜索 Query。
ImageMining 共包含 217 道人工整理的测试题,覆盖社交、娱乐、商品、地点、富文本、自然、科学领域,对应通用识别、时空推理、事件推理、富文本推理、视觉搜索推理任务。他们还在数据构建中引入了 Visual Jump 约束(WEB_VISUAL),强制中间推理步骤必须涉及视觉跳转,避免模型走文本捷径或依赖参数知识。
4.多模态深度研究与内容创作
GLM-5V-Turbo 支持从异构信息源出发,完成自主规划、多模态阅读、证据整合、长文合成的完整深度研究工作流,并能生成图文交织报告、深度研究转 PPT、文档风格博客/结构化笔记的输出。
5.官方skills
围绕 OpenClaw、AutoClaw 和 Claude Code 等框架,研究团队还提供了 15 项官方 skills,包括:原生 skills(如 PDF 转网页/PPT、网页复刻、PRD 转应用)、外部工具 skills(如图像描述、视觉 grounding、文档写作)以及基于专用模型 GLM-OCR、GLM-Image 的专项技能,并配有统一的 master skill 入口。
实验结果
GLM-5V-Turbo 与 Kimi K2.5、Claude Opus 4.6 在多模态任务上的对比如下图,可以看到模型在多模态工具使用方面实现全面领先,在多模态编程 Design2Code 这类经典基准上取得了明显领先的成绩。
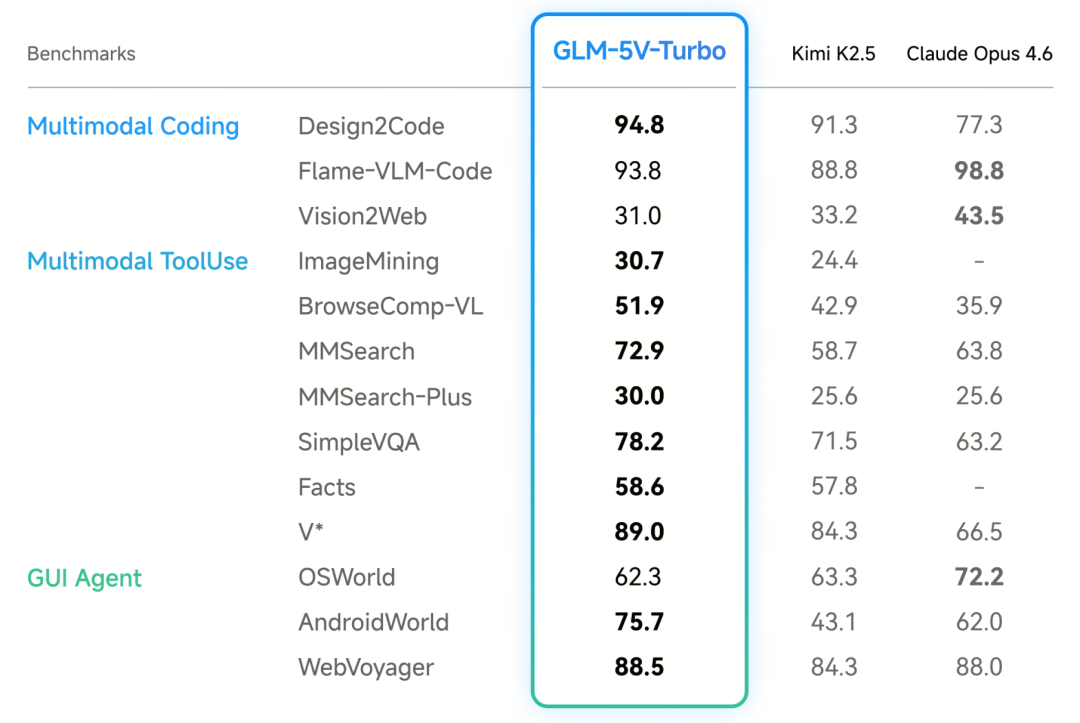
图|GLM-5V-Turbo 在多模态编程、工具调用以及 GUI Agent 基准测试中的评估结果
在文本 Coding 与 claw Agent 方面,GLM-5V-Turbo 实现了与纯文本基座 GLM-5-Turbo 近乎同等的性能。其中,GLM-5V-Turbo 的 CC-Backend 分数从 20.5 提升到 22.8、CC-RepoExploration 分数从 68.9 提升到 72.2;同时,虽与 Claude Opus 4.6 仍有差距,但 GLM-5V-Turbo 在 PinchBench、ClawEval、ZClawBench 上超过了 GLM-5-Turbo 和 Kimi K2.5。
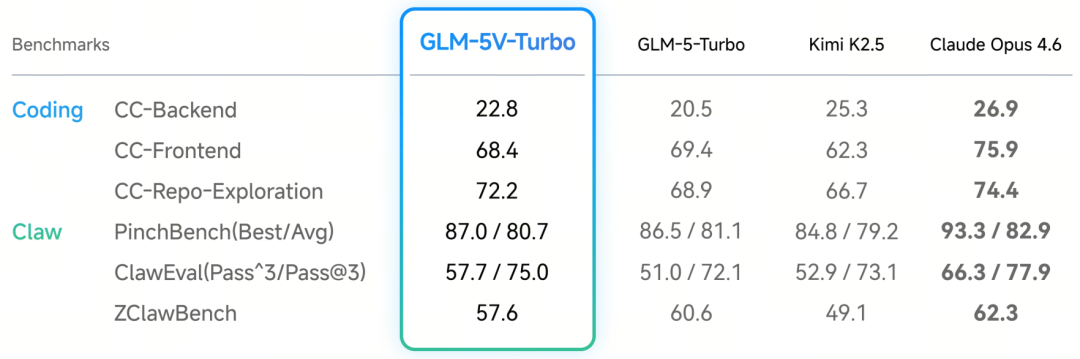
图|GLM-5V-Turbo 在文本 Coding 与 claw Agent 基准测试中的评估结果
来自开发过程的 3 条设计观察
研究团队还分享了 3 条来自 GLM-5V-Turbo 开发的设计观察。
感知仍是更高级多模态能力的基石。即使 SOTA 视觉-语言模型(VLM),其在细粒度感知和空间理解上的错误仍然普遍,并会沿链路传播到下游推理、决策与执行。
在团队的实践中,多模态编程和 grounding 任务被证明是有效的感知“代理任务”,如在预训练中加入学科图像与对应 SVG 代码的配对数据,对下游 STEM 问题求解有正向收益;在 RL 阶段加强 grounding 训练,则能改善 GUI Agent 表现。
在 GUI Agent 的指令微调中,研究团队还引入了针对推理过程错误(如误读界面、错认元素、错误决策)的批评数据,明显减少了几类反复出现的感知失败模式。
Agent 能力更适合用分层优化而非单一端到端训练构建。研究团队发现,Agent 任务普遍存在环境构建昂贵、高质量数据稀缺、可靠验证困难的问题。他们在 GUI Agent 开发中构建了元素感知、GUI grounding、单步动作预测、轨迹级动作预测的多层任务体系,并在 SFT 与 RL 中同时使用,在相同资源约束下,下层任务通常更易构建、标注、验证;当下层能力尚不成熟时,仅在高层任务上训练通常难以稳定收敛。
端到端长程任务的关键不在长度,而在清晰的任务设定、可靠的结果验证和可控的评估流程。现实世界 Agent 场景往往目标欠定、执行边界模糊、结果强依赖中间决策,难以横向比较,更难变成可复用的优化信号。Vision2Web 基准把网页开发任务建立在 PRD、原型图、参考页面、资源资产的多源约束之上,并采用工作流式验证,把执行评估拆成一系列依赖步骤,便于跨系统比较与失败归因。
研究团队还提出了 Vision2Web 基准(https://arxiv.org/abs/2603.26648),把网页开发任务建立在 PRD、原型图、参考页面、资源资产的多源约束之上,并采用工作流式验证,把执行评估拆成一系列 GUI agent 和 visual judge 的依赖步骤,便于跨系统比较与失败归因。
不足与未来方向
当然,这项研究也存在一些局限性和未来挑战。
首先,Agent 策略涌现依然受限。当前 Agent 训练高度依赖人工或强过滤的冷启动轨迹,这有助于初始化,但也压缩了模型能探索的推理与动作模式空间,后续 RL 容易陷在“已有路径上的局部改进”。实验结果表明,在冷启动阶段提升轨迹多样性能部分缓解这一问题,但实现“让模型自己发现更好的策略,乃至涌现出子 Agent 分解、多 Agent 协作等更丰富的组织形式”这一更根本目标仍然遥远。
其次,多模态长程上下文管理仍是瓶颈。与文本相比,图像和视频对上下文预算的消耗大得多,长轨迹中保留全部视觉观测在工程上几乎不可行。当前许多系统的做法是直接丢弃早期视觉观测,但这会丢掉后续推理可能用到的关键信息。文本场景下成熟的“压缩历史”做法(如 Claude Code 的 auto-compact)在多模态下并不直接适用,需要保留的不只是语义内容,还包括布局、空间关系、视频中的时序变化等视觉细节。多模态原生的上下文与记忆机制依然是一个开放问题。
最后,模型将与 harness 共塑系统能力边界。Agent 系统的实际能力边界不再由模型单独决定,而由模型与 harness(任务分解、工具使用、记忆机制、验证回路)共同塑造。这意味着 harness 不再是可独立优化的外层结构,它的价值与最佳形态会随模型能力变化而变化,反过来同一模型在不同 harness 下也可能表现不同。因此,Agent 模型开发不再是单纯的模型改进问题,评估目标本身也需要随之演化。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢