
Dynamic-dLLM团队 投稿
量子位 | 公众号 QbitAI
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。
但与此同时,它也面临着严重的计算瓶颈——
为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

不同于主流的dLLM加速方案(如dLLM-Cache、Fast-dLLM等),它们主要依赖静态缓存或固定阈值的并行解码策略,该框架则巧妙结合了动态缓存预算分配(DCU)与自适应并行解码(APD),能够实现良好的性能保持以及显著的加速比。
在多个代表性扩散大语言模型和主流权威基准上,Dynamic-dLLM均达成了SOTA。

尤其是在LLaDA-8B-Instruct模型的GSM8k任务上,Dynamic-dLLM实现了4.48倍的吞吐量加速(从8.32 TPS提升至37.29 TPS),在几乎无损精度的前提下,实现了跨任务平均3倍以上的加速。
以下是更多详细内容。
研究背景
现有dLLMs加速框架尝试复用前一步骤的中间特征(如Query、Key、Value),假设相邻步骤的特征相似度很高。然而,这种静态加速策略面临两大困境:
1、层级缓存更新需求差异巨大:
在实际解码中,浅层特征变化平缓,深层特征变化剧烈,需要更新缓存的Token比例随层数增加而单调上升。统一的缓存更新策略造成了极大的算力浪费。
2、固定阈值并行解码阻碍了效率:
并行解码会在Token置信度超过设定阈值时将其固定(Unmask)。
但处于早期步骤时,最高置信度的Token往往不是最终输出,固定阈值会导致“过早承诺”带来错误累积;而对于那些分布极其集中的Token,又因为绝对置信度没达到阈值而白白浪费计算步骤。
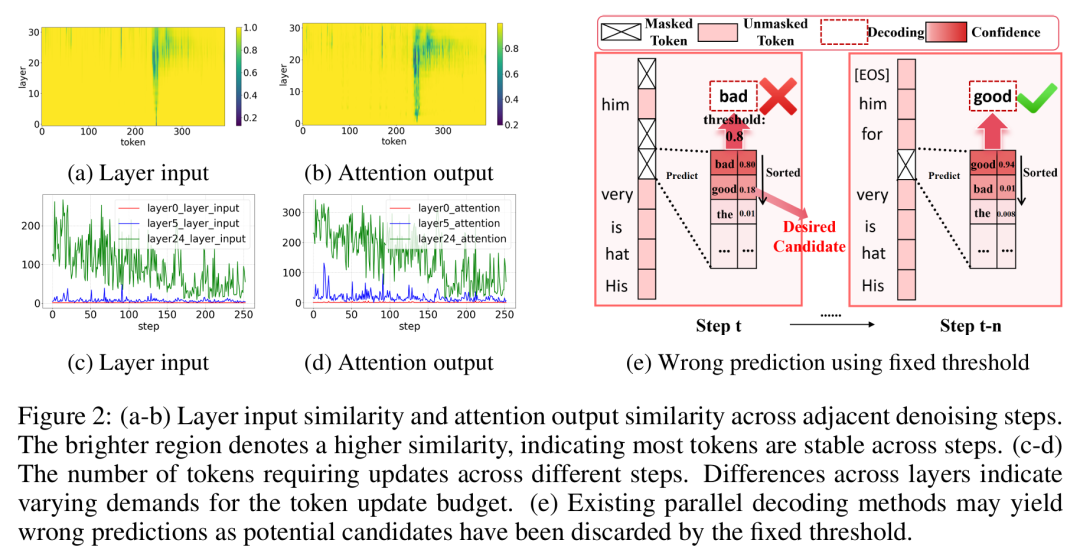
如上图所示,不同层和步骤的Token特征相似度及更新需求差异显著。其中图(e)展现了使用固定阈值导致潜在正确候选被错误丢弃的现象。
这证明了动态对齐模型内在层级与步骤级动态特性的必要性。
结合DCU和APD,实现动态极致加速
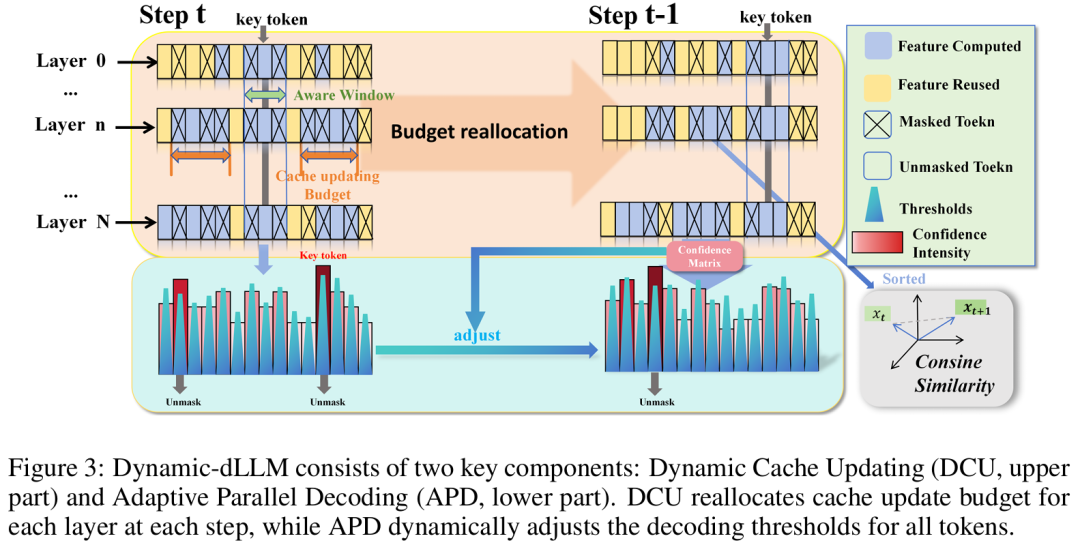
DCU:动态缓存更新
针对Token特征在层级间的异质动态特性,DCU实现了自适应的缓存预算分配:
1、层级自适应预算分配:
无需重新计算高开销的Value向量,DCU直接利用归一化后的Token输入计算相邻步骤间的余弦距离,以此作为表征变化的度量。
通过汇总Token级别的变化,DCU动态计算各层的活跃度,并将总更新预算按比例倾斜给变化最剧烈的层。
2、强制更新窗口(破除陷入泥潭问题):
如果一个Token被分配到较低优先级未更新,其特征将保持静止,导致后续层测算时其变化度为0,从而引发Token跨层“卡死(Stuck in the mud)”。
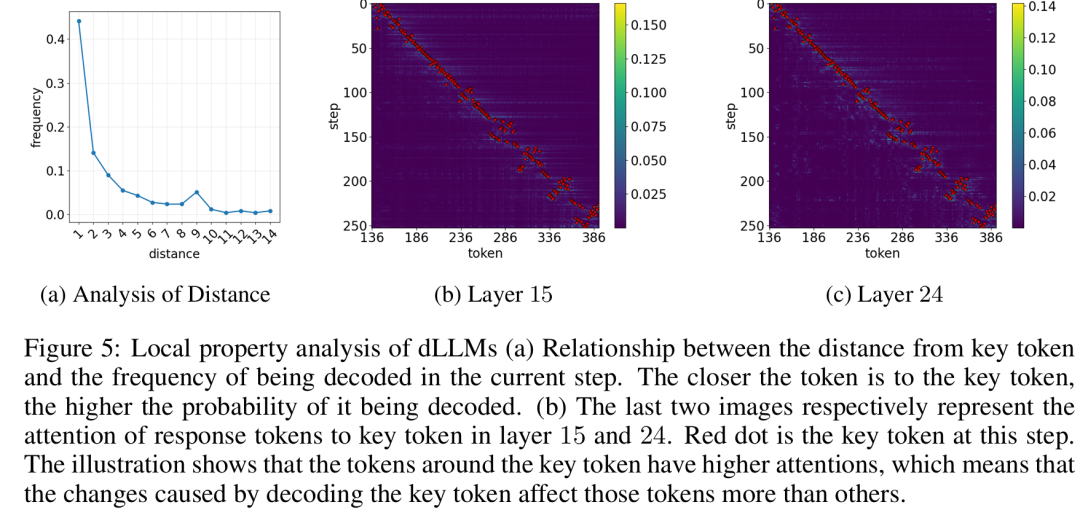
为此,基于局部性原理,DCU引入了固定大小的强制更新窗口(Mandatory Update Window),确保关键Token及其周围的局部区域强制进行缓存更新,从而保障关键上下文响应局部变化。
APD:自适应并行解码
针对Token置信度随解码步波动的特点,APD引入了动态阈值校准机制,为每个Token定制独立的解掩码阈值:
1、基于置信度集中的阈值自适应:
通过计算Token预测分布最高概率与次高概率的差距(集中度),对于分布高度集中(极有可能不再改变)的Token降低其阈值使其尽早固定;对分布分散的Token提高阈值防止错判。
2、融合时序不稳定性:
结合相邻步骤间概率分布的余弦距离,量化该Token历史预测的动荡程度。如果预测极其不稳定,则施加更严格的阈值惩罚,防止过早解码。


实验结果
Dynamic-dLLM在3个主流扩散大语言模型以及5个具有挑战性的数据集上进行了全面评估。
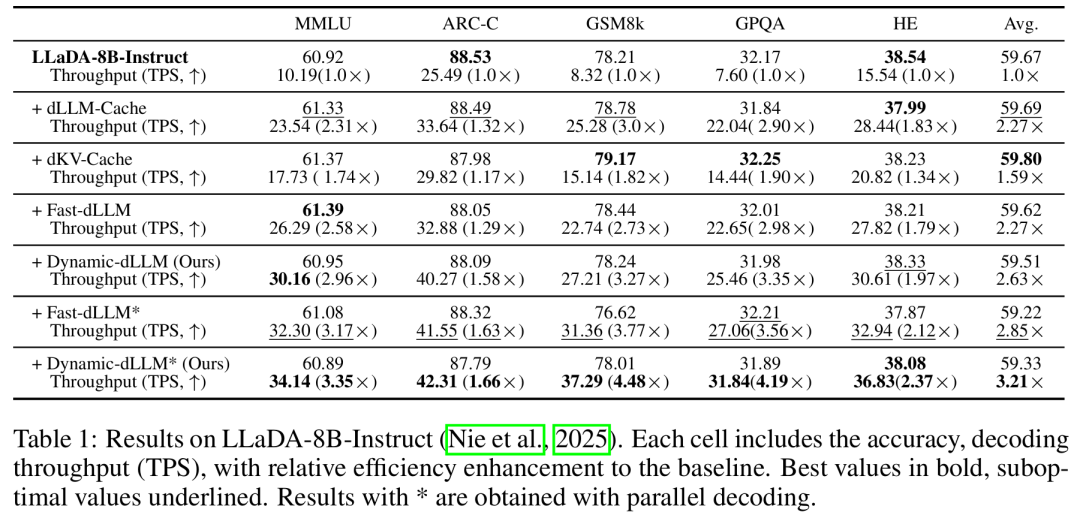
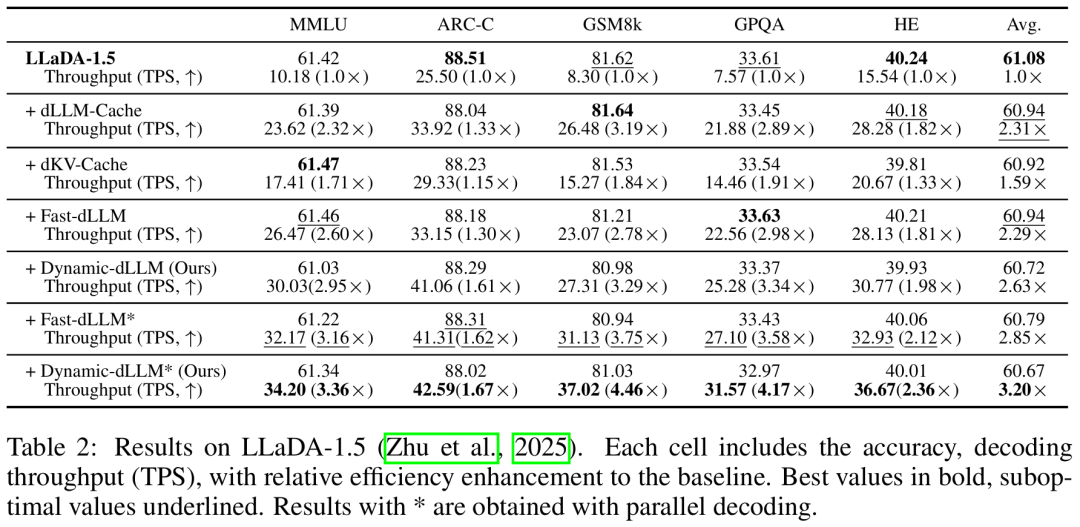
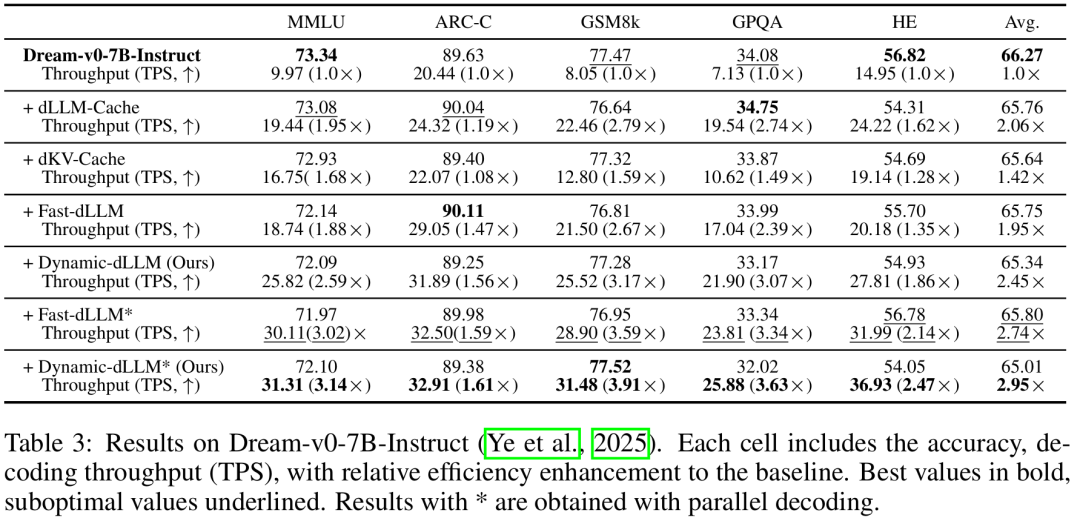
可以看出:
加速与性能保持
如表 1、2、3 所示,无论 LLaDA-8B-Instruct还是Dream-v0-7B-Instruct,Dynamic-dLLM(及搭配并行解码的Dynamic-dLLM版本)*均领先dLLM-Cache、dKV-Cache和Fast-dLLM方案。
在保持甚至微升准确率的情况下,平均TPS提升均达到2.5x~3.2x。
跨模型泛化性
在LLaDA-1.5上,GSM8k任务的加速比达到了4.46x(37.02 TPS vs 8.30 TPS),Dream模型的加速比同样达到3.91x,证明了该方法对于架构差异的泛化能力。
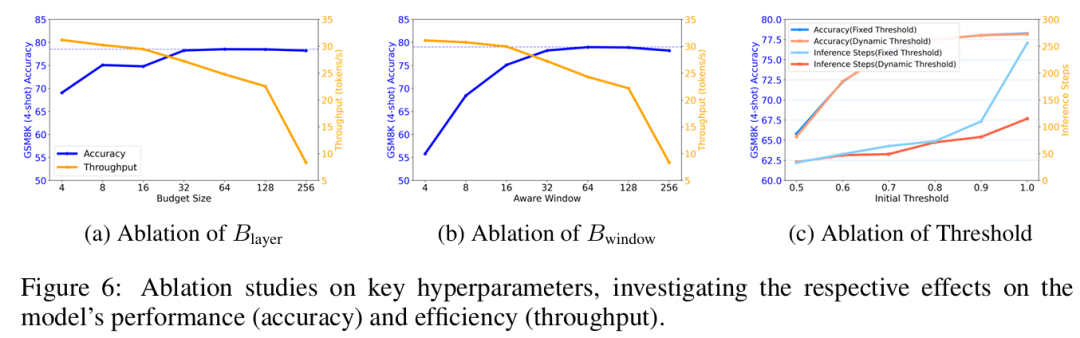
另外,消融实验也展示了关键超参数对精度与吞吐量的权衡影响,同时证明了动态阈值相比于固定阈值能在不掉点的情况下进一步减少约30%的推理步骤。
总的来讲,研究者敏锐地发现了非自回归生成的dLLM在推理时,特征更新与置信度随“层”和“步”存在剧烈的动态变化,而现有加速框架对此视而不见,导致了性能损耗与冗余计算。
而本论文的贡献可归纳为:
1、揭示现有规则加速的局限性:发现了dLLMs层级与解码步间的动态变化规律会削弱静态缓存框架的有效性。
2、提出无训练加速框架 Dynamic-dLLM:巧妙结合动态缓存更新(DCU)和自适应并行解码(APD),解决层级算力分配与动态置信度误判问题。
3、即插即用的卓越性能:在主流开源扩散模型与多维基准测试上实现了一致的SOTA性能,在保持模型精度的同时,达成平均超过3倍的推理加速,为dLLMs的低延迟实际部署扫清了障碍。
论文链接:https://openreview.net/forum?id=SdnkB5pGbq
代码链接:https://github.com/TianyiWu233/DYNAMIC-DLLM
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢