

准确且可解释的作物病害(crop disease)诊断对于农业决策(agricultural decision-making)至关重要,然而现有方法通常依赖于成本高昂的监督式微调,且在领域转换时表现不佳。我们提出了一种无需训练的少样本框架——Caption-Prompt-Judge (CPJ),该框架通过结构化、可解释的图像描述增强了 Agri-Pest VQA。CPJ 采用大型视觉语言模型(vision-language models)生成多角度图像描述,并通过 LLM 作为评判模块进行迭代优化,进而为双重答案 VQA 流程提供信息,用于识别和管理响应。在 CDDMBench 测试中,CPJ 显著提升了性能:使用 GPT-5-mini 生成的图像描述,GPT-5-Nano 在病害分类方面比无图像描述基线模型提高了 22.7 个百分点,在 QA 得分方面提高了 19.5 分。该框架提供透明的、基于证据的推理,无需微调即可实现稳健且可解释的农业诊断。

论文:CPJ: Explainable Agricultural Pest Diagnosis Via Caption–Prompt–Judge with LLM-Judged Refinement
单位:山东理工、澳门中西创新学院
发布日期:2026年4月
请索引第90篇论文
 |  |
告别枯燥微调!CPJ框架如何用“免训练”三步走,实现农业病害诊断SOTA?
在深度学习领域摸爬滚打的各位同学,有没有被“微调(Fine-tuning)”折磨得疲惫不堪?标注数据昂贵、算力资源吃紧、跨域泛化能力差……这几乎是每个做多模态/视觉问答(VQA)研究的学生都会遇到的“老大难”问题。
特别是在农业AI(Agricultural Pest Diagnosis)这种极具落地价值的场景中,环境复杂、作物品种繁多,传统的大视觉语言模型(LVLMs)往往只能给出一个冷冰冰的分类标签,不仅缺乏可解释性,一旦遇到陌生的地理环境或季节变化(域偏移),准确率更是断崖式下跌。
有没有一种可能,不用耗费显卡去微调,就能让轻量级模型实现性能的“无痛涨点”?
今天为大家深度解读一篇刚被 ICASSP 2026 录用的硬核好文——《CPJ: EXPLAINABLE AGRICULTURAL PEST DIAGNOSIS VIA CAPTION–PROMPT–JUDGE WITH LLM-JUDGED REFINEMENT》。来自山东理工大学和澳门中西创新学院的研究团队,提出了一个极其优雅的 Caption-Prompt-Judge (CPJ) 框架,完全摒弃了监督微调(SFT),仅靠巧妙的提示词工程和AI自我评判,就实现了农业病虫害诊断的鲁棒性与可解释性双飞跃!
01 核心洞察:把“暗箱操作”变为“因果推演”
现有的农业VQA模型往往直接根据输入图像 和问题 来生成答案 。这种做法忽略了人类专家诊断时的核心逻辑:先观察症状,再下诊断结论。
CPJ框架的精髓在于引入了“可解释的图像描述(Explanational Caption)”作为中间推理层。它不试图去改变模型内部的权重,而是通过结构化的外部提示,引导模型像人类一样“自言自语”:
看(Caption):提取图像的客观特征(如病斑颜色、叶片形态)。
想(Prompt):结合任务要求,生成初步的诊断和管理建议。
判(Judge):引入更强大的大模型作为“裁判”,对初稿进行打分和纠偏。
这种 Generate-Judge-Select 的流水线设计,不仅打通了视觉特征到因果解释的鸿沟,还巧妙地避免了模型产生幻觉(Hallucination)。
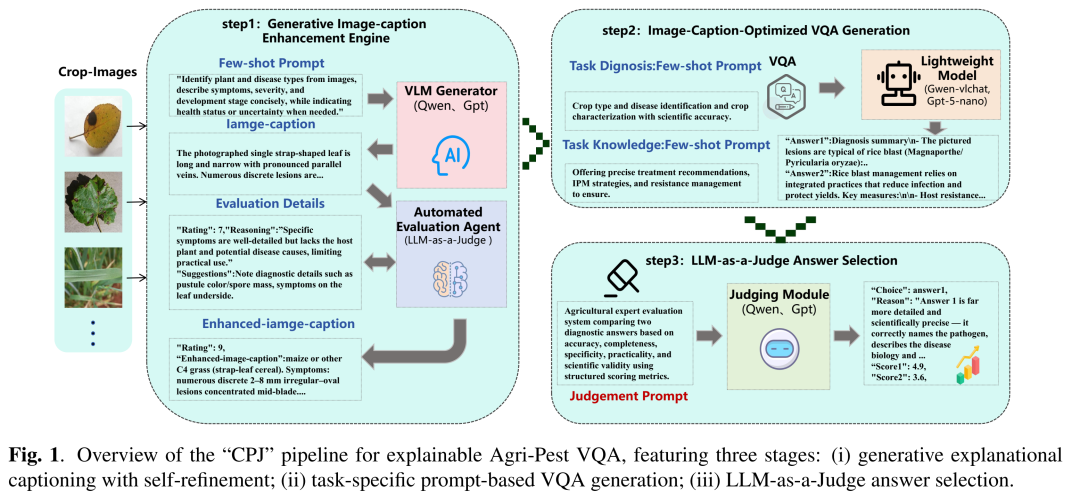
02 技术拆解:CPJ框架的“三板斧”
整个CPJ框架(对应论文图1)是一个精妙的闭环系统,我们逐一拆解它的三个核心阶段:
1. Caption:多视角描述与自迭代优化 (LLM-as-a-Judge Refinement)
为了让模型“看懂”图片,研究团队首先利用一个较强的LVLM(如GPT-5-mini)生成多角度的初始图像描述 :
这里的关键技巧是:提示词中明确排除了作物或病害的名称,强迫模型专注于客观的形态学和症理学特征。
随后,大语言模型(LLM)化身为严苛的“评委”,基于准确性、完整性和中立性对描述进行打分 。如果分数低于阈值 ,LLM会给出修改意见 ,退回LVLM重新生成,直到产出语义密度极高且无偏见的优化描述 :
2. Prompt:双通道VQA解答 (Explanational Caption-Optimized VQA)
有了高质量的客观描述 作为上下文,接下来就是针对具体问题生成答案。
研究团队设计了一个任务相关的提示词模板 ,将输入定义为 。为了提升鲁棒性,模型被要求针对每个问题生成两个互补的答案。
对于病害识别任务:一个侧重病虫害特征(症状、严重程度),另一个侧著作物本体特征(种类、品种)。
对于知识问答任务:一个侧重防治措施( actionable recommendations),另一个侧重病理机制解释(disease explanation)。
3. Judge:大模型裁决最优解 (LLM-as-a-Judge Answer Selection)
两个答案难免有优劣之分。在最后阶段,一个更强大的LLM(如GPT-4级别)“裁判”再次登场。它会根据一套预设的标准 (如事实正确性、相关性、清晰度、可操作性)对这两个答案进行打分:
最终,系统选出得分最高的答案 作为输出,并附带一份详细的评估报告。这不仅保证了最终结果的可靠性,也让整个决策过程变得完全透明、可溯源。
03 实验精析:免训练如何打败强监督?
理论再优美,也要看实验数据。研究团队在农业多模态权威数据集 CDDMBench 上进行了严苛测试。
下表展示了在两种不同 backbone(Qwen-VL-Chat 和 GPT-5-Nano)上,引入 CPJ 各模块后的性能对比。我们可以清晰地看到几个关键结论:
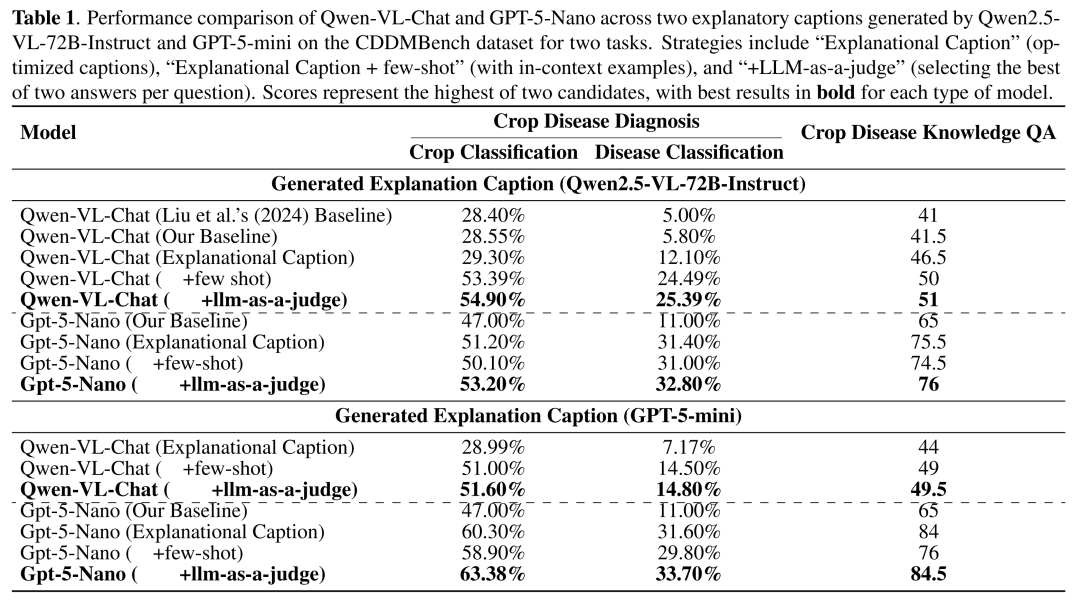
Captions 是核心驱动力:仅仅是加入了第一步生成的“可解释描述”,就让病害分类和QA分数产生了爆炸式的提升(Disease Cls飙升20个点!)。这证明了在复杂推理任务中,给模型提供结构化的“中间思考过程”远比直接丢给它一张原始图片有效得多。
Judge 负责锦上添花:最后的裁判机制虽然提升幅度不如加描述那么大,但它起到了稳定器的作用,成功把峰值拉到了最高(63.38% 和 84.5),并且过滤掉了模型可能产生的低级错误。
此外,论文的消融实验(对应论文图2)还揭示了一个非常有趣的发现:
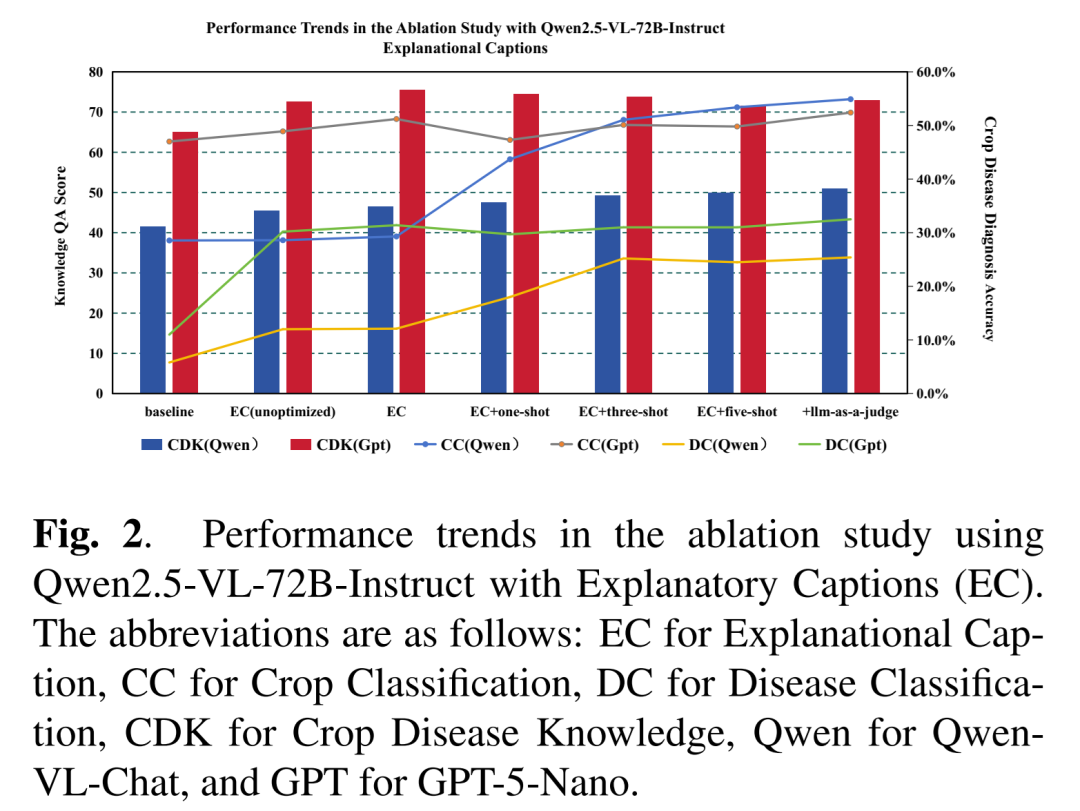
对于小模型(如 Qwen-VL-Chat),Few-shot 带来的增益极大,说明小模型非常依赖上下文示例来激活潜能;而对于本身就很强的大模型(如 GPT-5-Nano),它对 Caption 的质量极其敏感,高质量的描述能让它迅速趋近最优解。
05 给图科学实验室同学们的科研启示
读完这篇 ICASSP 2026 的论文,作为本硕博学生的我们,除了感叹 idea 的巧妙,更应该从中提炼出对自身科研范式的启发:
“微调不是唯一的出路”:在数据稀缺或算力受限的情况下,如何通过 Prompt Engineering 和 外部知识库的引入来构建 Agentic Workflow(智能体工作流),是极具生命力的研究方向。CPJ 就是一个完美的 Training-free (零训练) 范式。
“可解释性(XAI)是落地的敲门砖”:纯靠数据驱动的黑盒模型越来越难以满足医疗、农业等关键领域的要求。将“观察-推理-判断”人为拆解并显式化,不仅能提升性能,更是赋予AI系统“人类逻辑”的关键。
“强者愈强,合理利用API”:不必执着于从头搭建一切。用大模型(GPT-4/5)去辅助、评判小模型(Qwen-VL),形成级联系统(Cascade System),是目前学术界和工业界都非常推崇的高性价比打法。
最后留一个互动话题给大家:
除了农业病虫害诊断,你认为这种“Caption-Prompt-Judge”的三步走框架,还能无缝迁移到哪个研究领域?是医学影像报告生成?还是遥感图像解译?



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢