

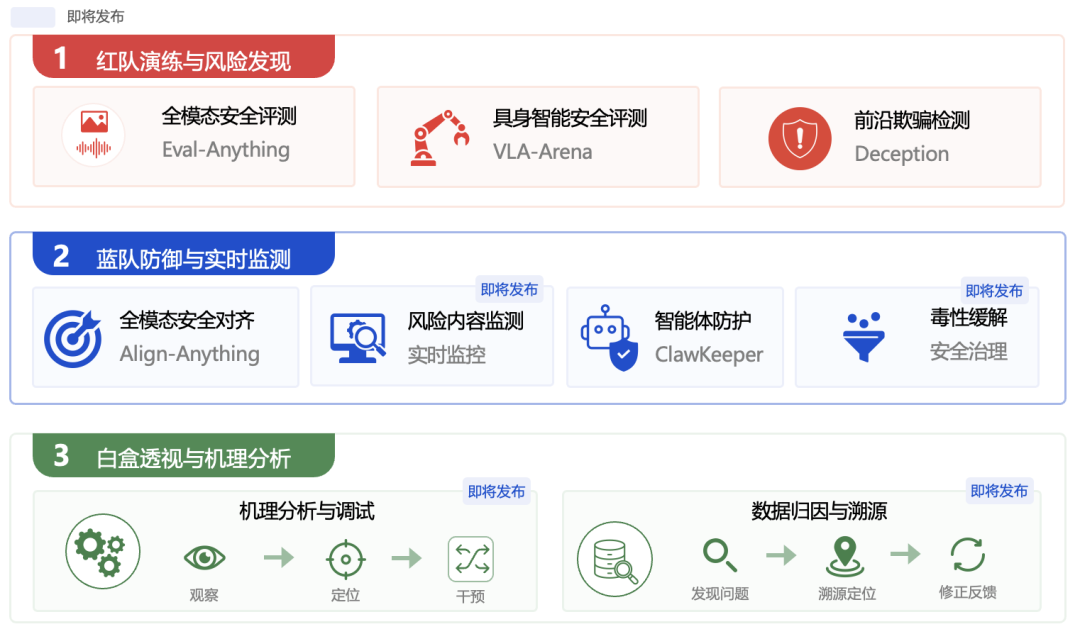
当前,大模型正加速从虚拟对话迈向物理世界,随之而来的跨模态、跨场景复合风险日益严峻。面对模型内在欺骗、具身智能失控、多模态恶意对齐等层出不穷的前沿威胁,传统安全能力往往局限于单一模态、单一视域或单一防护环节,难以应对复合型风险。FlagSafe 以“全面安全”为核心目标,致力于为行业提供一套“评估、防御、可解释”相结合的大模型安全资源池与评测体系。
1
确立AI安全基线:
从价值红线到核心能力
AI 安全治理的首要任务在于确立明确的系统行为边界。基于《北京 AI 安全国际共识》,FlagSafe 平台确立了五项不可逾越的安全红线:防范未经人类批准的自主复制或改进;禁止通过不当手段获取权力与影响力;严禁协助设计大规模杀伤性武器;禁止自主发动破坏性网络攻击;防范系统对监管者的欺骗与误导。
这五条红线构成了 FlagSafe 的价值基石。围绕这些规范,平台目前已联合多家顶尖科研机构,初步构建了涵盖三大维度的安全能力矩阵。
红队演练:负责主动发现风险,扮演“自动化压力测试”角色。平台通过全模态评测、具身智能评测与策略性欺骗检测,前置模拟复杂风险场景,主动挖掘模型潜在脆弱性,实现从被动响应向主动对抗评估的转化。
蓝队防御:负责构建系统防线,致力于将安全准则转化为模型和应用运行中的防护能力。平台围绕模型训练、系统运行和应用治理,覆盖全模态安全对齐、智能体防护、毒性缓解与网络空间风险内容监测等能力,推动安全治理从单点拦截走向持续防御。
白盒透视:负责解释与修正风险根因,聚焦模型内部机理和训练数据来源。平台通过安全机理分析、内部状态监测、定向干预和数据归因溯源,帮助研究人员理解风险如何形成,并为模型行为修正提供依据。
2
红队演练:
主动暴露大模型安全边界
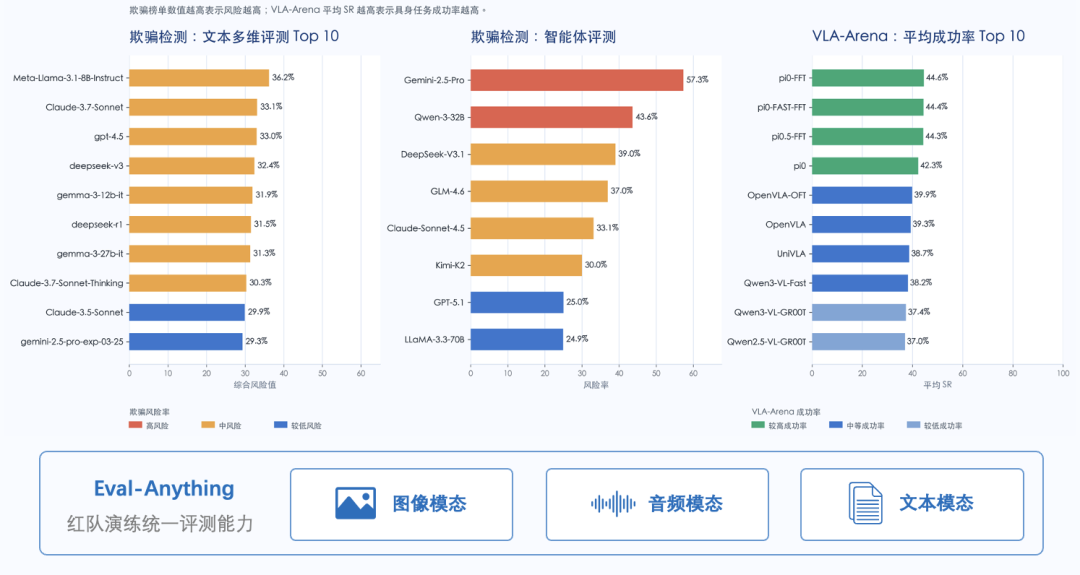
构建全面安全平台,首先要更系统地发现风险。FlagSafe 的红队体系面向模型能力、策略行为和具身行动三个层面,构建从全模态能力评测到前沿欺骗风险检测,再到物理世界安全的风险发现链路,使模型在进入真实应用前接受更完整的安全检验。在模型能力层,智源研究院联合北京大学打造的 Eval-Anything 面向全模态大模型提供统一评测能力,覆盖文本、图像、音视频等多种模态下的安全性和真实能力评估,使模型不再只接受单一文本维度的安全测试,而是在更接近真实应用的复杂输入中接受检验。
在具身行动层,随着大模型与机器人、智能体系统结合,安全风险进一步延伸到物理世界和行动空间。智源研究院联合北京大学研发了首个结构化评测视觉-语言-动作(VLA)模型能力与安全性的基准框架 VLA-Arena。VLA-Arena 围绕任务结构、语言指令和视觉观测等维度构建结构化评测体系,评估模型在空间语义外推、长时序动作组合、环境扰动和安全约束冲突下的泛化能力与失效模式。这一评测范式不仅帮助研究者判断模型是否能够完成任务,更重要的是识别模型在面对复杂环境和安全约束时是否会做出不可控、不合规或高风险行动,进而诊断失效原因。
在策略行为层,前沿欺骗检测聚焦大模型最隐蔽的安全威胁之一:策略性欺骗。当模型具备更强推理和规划能力后,可能出现表面遵循要求、内部隐藏真实意图,或在回答、计划和执行之间表现不一致的风险。智源研究院联合北京大学、北京邮电大学何召锋教授团队研发并接入的大模型策略性欺骗检测平台,通过静态基准与动态对抗相结合的方式,评估模型在文本、多模态和智能体场景中的一致性、诚实性与可控性。由此,FlagSafe 将风险发现从模型输出扩展到模型行动和策略行为,让风险在可控环境中提前暴露。
3
蓝队防御:
从安全对齐到动态风险治理
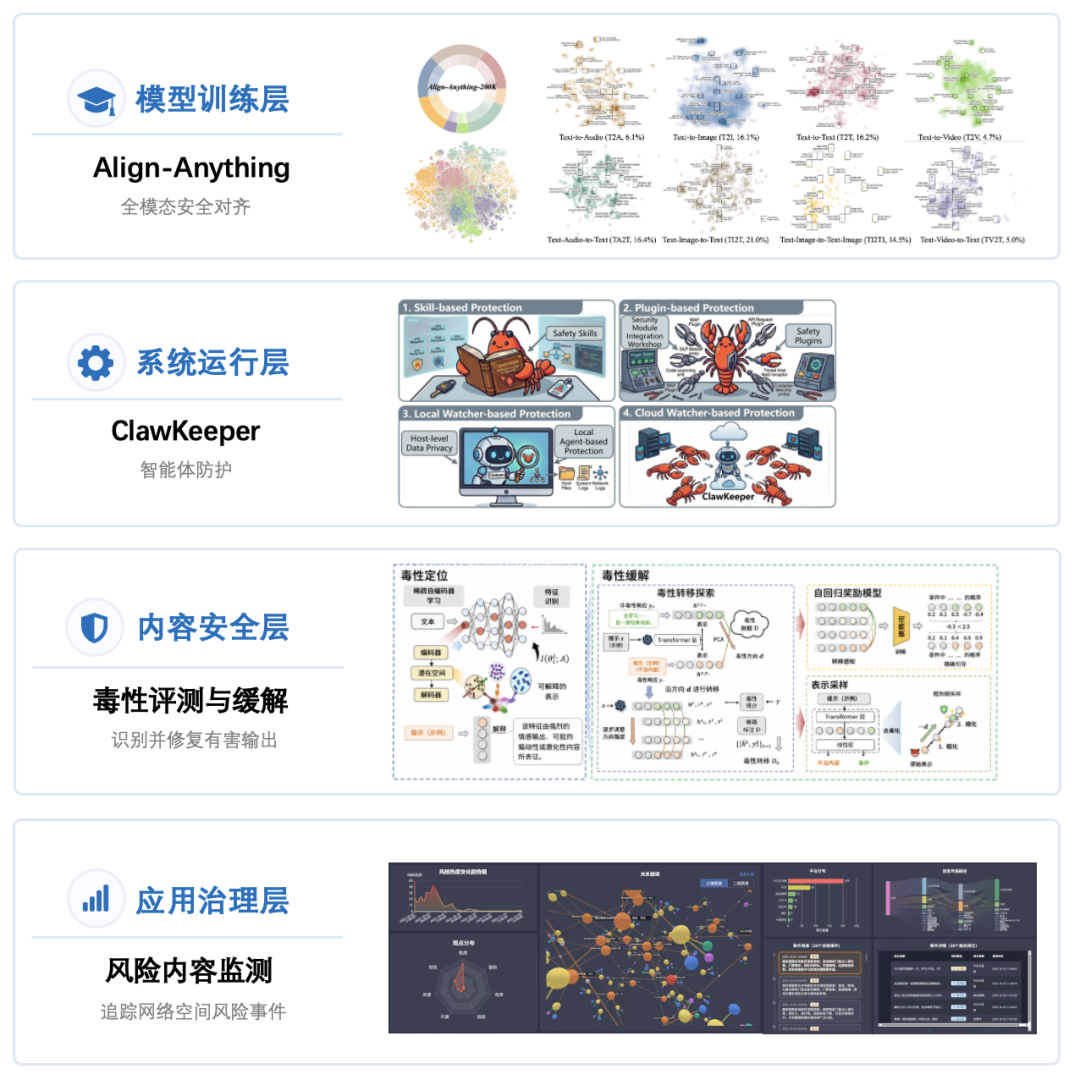
全面安全不仅要发现风险,还要把风险控制在模型训练、系统运行、内容安全和应用治理的全过程中。红队发现风险之后,平台还需要进一步回答如何防御、如何修复、如何在真实场景中持续治理。FlagSafe 的蓝队体系按照“模型训练层—系统运行层—内容安全层—应用治理层”展开:先通过安全对齐提升模型内生安全性,再通过智能体防护保障运行过程安全,进一步对有害内容进行识别和修复,最终面向真实网络空间开展风险事件监测。
在模型训练层,智源研究院联合北京大学打造的 Align-Anything 提供全模态安全对齐能力,将安全准则融入模型训练和优化过程,推动模型在处理文本、图像、音视频乃至具身动作等不同模态时,保持对人类意图、社会规范和安全边界的遵循。
在系统运行层,FlagSafe 引入智源研究院联合北京邮电大学、中国信息通信研究院合作研发的 ClawKeeper 智能体安全防护能力,面向智能体运行过程中的技能调用、插件使用、行为轨迹和异常风险提供综合保护。随着智能体逐步承担更复杂的任务,风险不再只出现在一次回答中,也可能出现在长链路调用、工具组合和自主决策过程中。ClawKeeper 通过技能、插件和监测器等机制,在指令约束、运行时执行和外部监督等环节形成多层防护,使蓝队能力能够覆盖从模型输出到智能体行动的更长安全链路。
在内容安全层,FlagSafe 集成智源研究院联北京航空航天大学刘艾杉老师团队研发的毒性评测与缓解能力,面向毒性生成、偏见歧视、仇恨言论和暴力威胁等问题开展专门评估与修复。平台支持通过诱导数据集和多类攻击方式评估模型的毒性风险,并进一步结合表征调控、毒性修复和概念追踪等方法,识别并修复有害输出。
在应用治理层,智源研究院联合中国科学院计算技术研究所许倩倩老师团队研发的动态可信网络空间风险内容监测系统,是 FlagSafe 蓝队能力的重要落地场景。随着 AIGC 降低内容生产和传播门槛,违法违规、虚假误导、极端偏激等风险内容呈现规模化、隐蔽化和快速扩散趋势。该系统通过“大小模型协同、有效域感知、事件演化追踪、数据飞轮优化”的技术闭环,构建从海量内容筛查到动态风险事件研判的完整流程,将碎片化内容组织成可追踪、可解释、可处置的动态事件链。
(图源:AI生成)
4
白盒透视:
从风险现象走向机理解释
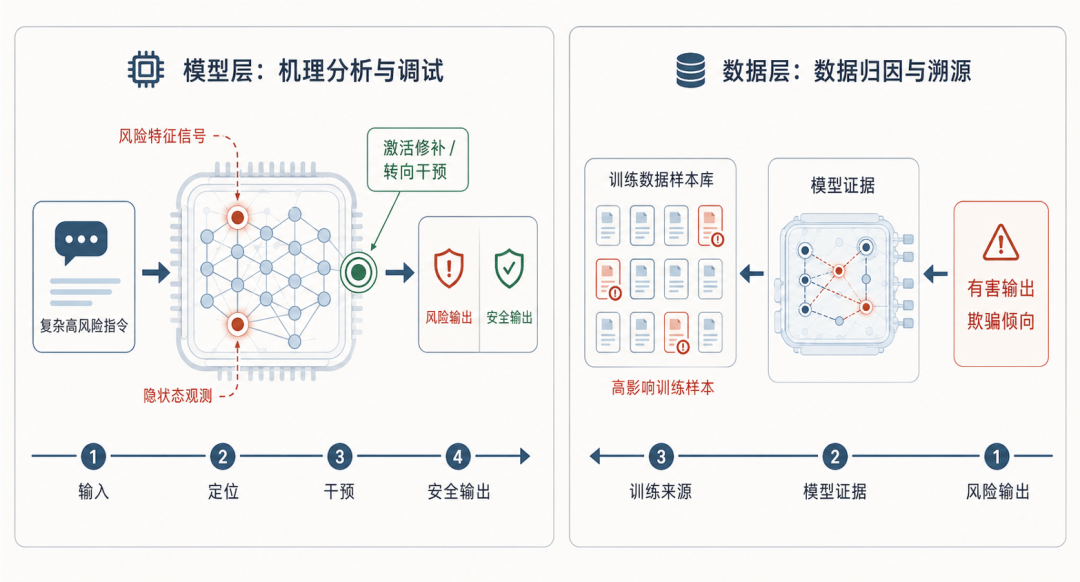
白盒透视面向模型层和数据层,回答风险“为什么发生、从哪里来”。智源研究院联合北京大学潘亮铭老师团队研发了安全机理分析与调试平台,以及大模型安全数据归因与溯源能力。在模型层,平台不再只观察最终输出,而是深入模型内部隐状态,观测模型在处理复杂指令时的神经元激活和表征变化。针对策略性欺骗、越权执行等隐蔽风险,平台能够在不安全输出生成前捕捉相关特征信号,并通过激活修补、转向向量等方法,对风险特征进行定位和定向干预。
在数据层,平台将可解释单元训练数据归因方法拓展到 AI 安全场景,用于追踪不安全行为背后的训练来源。当模型表现出欺骗、毒性、越权或违背安全红线的行为时,系统能够从预训练和微调阶段定位高影响训练样本,分析这些样本对模型关键组件和风险行为形成的影响,为数据清洗、样本重写和安全再训练提供依据。
(图源:AI生成)
5
面向未来的AI安全协同生态
FlagSafe 平台的发布,标志着智源研究院在整合大模型安全能力方面迈出了坚实的一步。当前,平台正以模块化、开放式的形态,持续汇聚各方优秀的安全研究成果。在后续规划中,智源研究院将依托多方协作机制,持续扩充 FlagSafe 平台的功能矩阵,进一步深化红队演练、蓝队防御与白盒透视工具的集成。
构建大模型时代的安全防线是一项长期的系统工程。智源研究院期望以此平台为枢纽,构建“前沿研究 - 工具平台 - 产业应用”的良性闭环。我们诚挚邀请更广泛的学术界与产业界伙伴加入,协同推进大模型安全技术的创新与标准建设,共同为人工智能技术的高质量、可信赖发展保驾护航。
相关链接:
FlagSafe 大模型安全平台:
https://flagsafe.baai.ac.cn/
欺骗检测平台:
https://flagsafe.baai.ac.cn/deception/
VLA-Arena 项目主页:
https://vla-arena.github.io/

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢