
01
题目: A Data-Efficient Path to Multilingual LLMs: Language Expansion via Post-training PARAM∆ Integration into Upcycled MoE
作者:Hao Zhou(周昊) Tianhao Li(李天昊) Zhijun Wang(王志军) Shuaijie She(佘帅杰) Linjuan Wu(吴林娟) Hao-ran Wei(魏浩然) Baosong Yang(杨宝嵩) Jiajun Chen(陈家骏) Shujian Huang(黄书剑)
单位:南京大学 通义实验室 浙江大学
录用会议:ACL2026
论文简介:
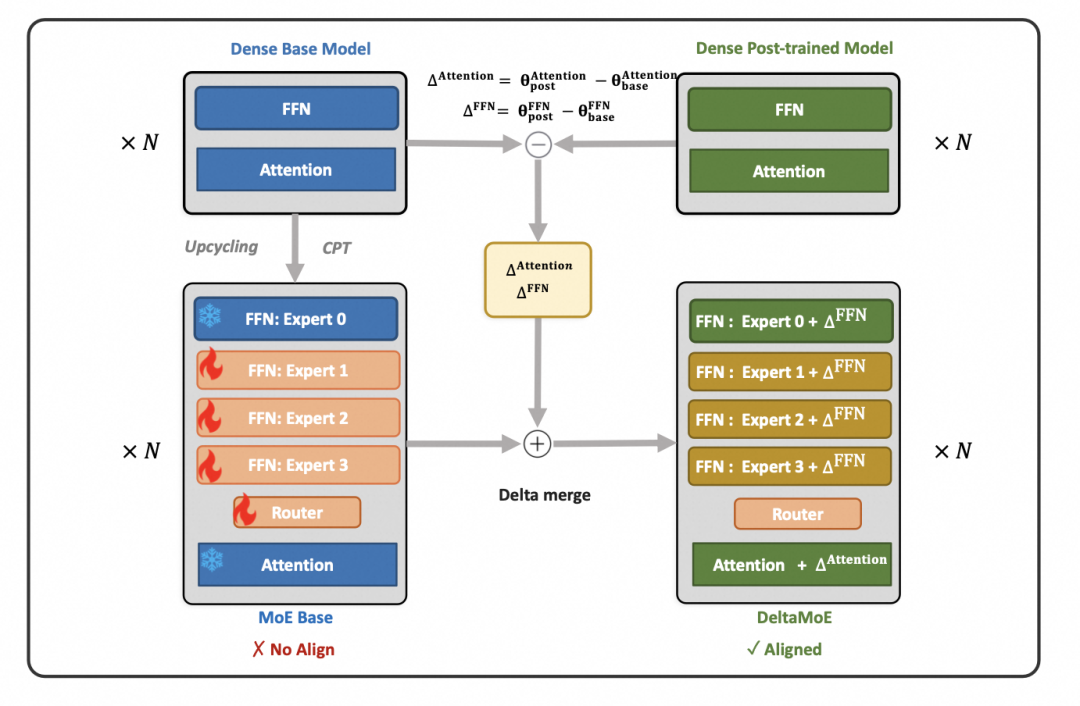
当前大语言模型的多语言能力以英文(中文)为主,低资源语言能力较差。传统语言扩展方法中会首先会在继续预训练阶段使用大规模单语数据为模型补充目标语言基础知识,其次进行后训练帮助模型与人类偏好对齐。然而,受限于后训练阶段需要大量目标语言高质量标注数据,很多工作尝试将后训练过程通过参数融合来取代,从而绕过数据瓶颈。但这些方法仍面临一个核心矛盾:继续预训练得到的参数与后训练得到的参数之间存在冲突。为了解决参数冲突问题,我们提出了DeltaMoE的方法,通过扩展多个专家,并将每个专家叠加后训练参数的差值,从而帮助MoE模型获得对齐能力。实验结果显示,DelaMoE在参数相同以及训练FLOPs匹配的条件下,均在扩展语言上相比baseline提升显著,同时能显著保留原始语言的知识,避免灾难性遗忘。
02
题目: CogGen: A Cognitively Inspired Recursive Framework for Deep Research Report Generation
作者:Kuo Tian(田阔), Pengfei Sun(孙鹏飞), Zhen Wu(吴震), Junran Ding(丁俊然), Xinyu Dai(戴新宇)
单位:南京大学 南京皓顿科技发展有限公司
录用会议:ACL2026(findings)
链接:https://arxiv.org/abs/2604.17072
论文简介:
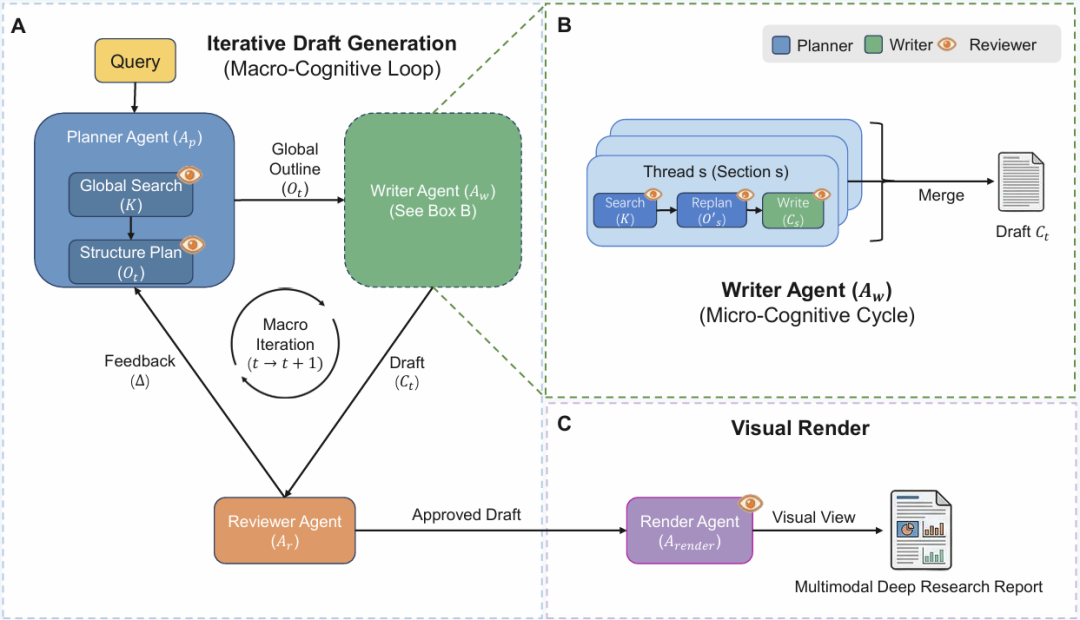
深度研究(Deep Research)报告的自主生成是大语言模型(LLM)领域的重要前沿方向,该任务要求模型具备精细的信息组织能力与非线性叙事逻辑。现有方法多依赖僵化的预定义线性工作流,易造成错误累积,无法基于后续新发现对内容进行全局重构,最终限制了多模态信息的深度融合与报告质量。本文提出CogGen:一种受认知科学启发的递归式深度研究报告生成框架。该框架采用分层递归架构模拟人类认知式写作过程,支持灵活规划与全局重构。为将这种递归机制拓展至多模态内容,我们引入抽象视觉表示(AVR):一种简洁的意图驱动式表达语言,可在无需像素级重新生成的前提下,迭代优化图文布局。此外,本文还提出认知负荷评估框架(CLEF),并基于 “Our World in Data (OWID)” 数据集构建了全新评测基准。实验结果表明,CogGen 在开源系统中取得了当前最优性能,生成的报告可媲美专业分析师成果,且效果超越 Gemini Deep Research。
03
题目:Understanding New-Knowledge-Induced Factual Hallucinations in LLMs: Analysis and Interpretation
作者:Renfei Dang(党任飞), Peng Hu(胡鹏), Zhejian Lai(赖哲剑), Changjiang Gao(高长江), Min Zhang(张敏), Shujian Huang(黄书剑)
单位:南京大学 华为翻译服务中心
录用会议:ACL2026(findings)
链接:https://arxiv.org/abs/2511.02626
论文简介:
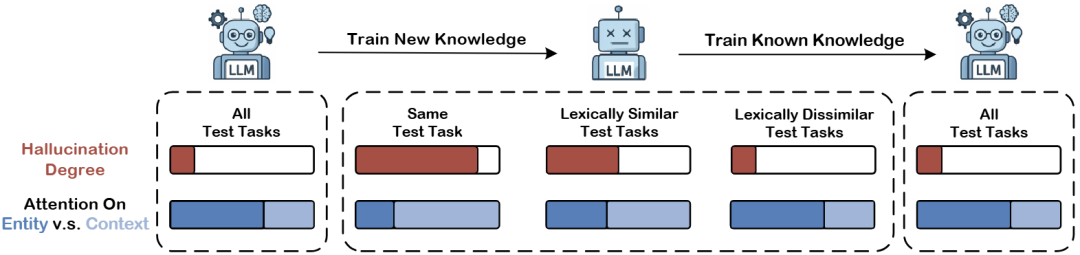
先前研究表明,在大型语言模型(LLMs)上使用新知识进行微调,可能诱发事实性幻觉,使模型在面对原本已掌握的信息时输出错误答案。然而,这类幻觉的具体表现形式及其潜在机制仍缺乏充分理解。为弥补这一空白,我们构建了一个受控数据集 Biography-Reasoning,并围绕多种知识类型与知识问答和推理任务开展细粒度分析。
我们发现,事实性幻觉不仅会严重影响学习新知识的任务本身,还会传播至其他评测任务。此外,当某一特定知识类型在微调数据中完全由新知识构成时,LLMs 会表现出更高的幻觉倾向。通过可解释性分析,我们进一步发现学习新知识会削弱模型对输入问题中关键实体的注意力,使其更依赖周围上下文来回答问题,从而增加产生幻觉的风险。相反,在训练后期重新引入少量已知知识,可以恢复模型对关键实体的注意力,并显著缓解幻觉行为。最后,我们证明,这种被扰乱的注意力模式会在词汇上更相似的上下文之间传播,从而促使幻觉扩散到原始任务之外的其他场景。
04
题目:PEGRL: Improving Machine Translation by Post-Editing Guided Reinforcement Learning
作者:Yunzhi Shen(沈运之), Hao Zhou(周昊), Xin Huang(黄鑫), Xue Han(韩雪), Junlan Feng(冯俊兰), Shujian Huang(黄书剑)
单位:南京大学 中国移动
录用会议:ACL2026(findings)
链接:https://arxiv.org/abs/2602.03352
论文简介:
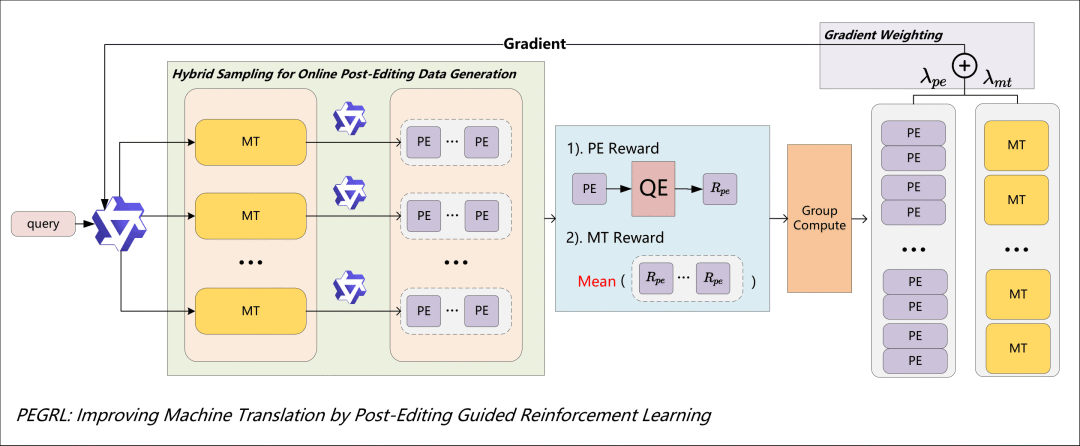
强化学习(RL)在基于大语言模型(LLM)的机器翻译中展现出显著潜力,近期方法(如 GRPO)已取得可观性能提升。然而,将强化学习有效应用于翻译任务仍面临若干关键挑战:一方面,基于 Monte Carlo 基线的策略梯度估计具有较高方差;另一方面,庞大的轨迹空间更倾向于鼓励全局探索,而不利于细粒度的局部优化。
为此,我们提出 PEGRL,一种两阶段强化学习框架,通过引入译后编辑(post-editing)作为辅助任务,以稳定训练过程并引导整体优化。在每一步中,模型首先对翻译输出进行采样,并据此构造译后编辑任务的输入,使得来自译后编辑任务的低方差梯度能够在训练过程中有效传播,从而在保持全局探索能力的同时增强局部优化能力。
此外,我们设计了一种任务特定的加权机制,以进一步放大译后编辑梯度的影响,从而得到一种带有适度偏置但更具样本效率的梯度估计器。在英语到芬兰语、英语到土耳其语,以及英语与中文的双向翻译任务上,大量实验表明,该方法相较于多种强化学习基线均取得了稳定提升;在英语到土耳其语任务上,其在 COMETKiwi 指标上的表现可与先进的大语言模型系统(DeepSeek-V3.2)相当。
05
题目:Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
作者:Xin Chen(陈鑫), Feng Jiang(蒋峰), Yiqian Zhang(张宜千), Hardy Chen (陈桂铭), Shuo Yan(严硕), Wenya Xie(谢文雅), Min Yang(杨敏), Shujian Huang(黄书剑)
单位:南京大学 深圳理工大学人工智能研究院 中国科学院深圳先进技术研究院
录用会议:ACL2026
链接:https://arxiv.org/abs/2601.22139
论文简介:
面向推理的大语言模型,如DeepSeek-R1,依托显式推理轨迹在复杂任务上取得了显著进展。然而,这类模型仍受限于一种“盲目自我思考”(Blind Self-Thinking)范式:当用户指令存在前提缺失或意图模糊时,模型往往仍会进行冗长的内部推理,进而导致过度思考、幻觉以及结论偏离用户真实意图,损害交互效率与用户体验。为解决这一问题,我们提出主动交互式推理(Proactive Interactive Reasoning, PIR)新范式,旨在将推理型大语言模型从被动求解者转变为主动询问者,使模型能够在推理过程中交错执行“思考—提问—反馈”,并通过澄清关键不确定性来更准确地对齐用户意图。
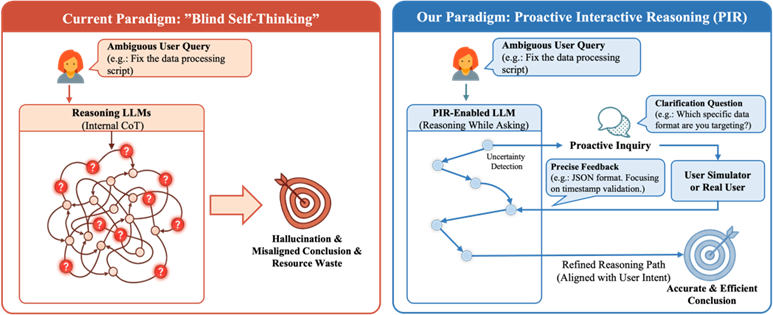
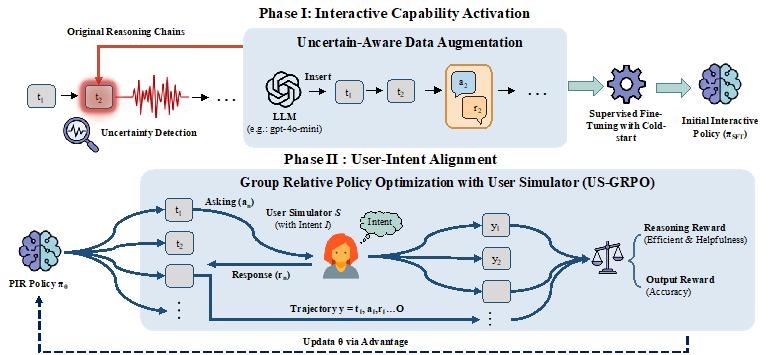
PIR 框架由两个阶段构成:(1)交互能力激活阶段,提出基于不确定性感知的数据增强机制,定位推理过程中不确定性的关键决策点,并在这些位置注入澄清问题与模拟用户回复,将单调推理轨迹转化为“思考–提问–反馈”的交互格式,通过监督微调赋予模型主动提问能力;(2)用户意图对齐阶段,构造基于用户模拟器的群体相对策略优化框架(US-GRPO),结合任务正确性的外在奖励与模型提问的“帮助性–效率”双维度的内在奖励,引导模型在准确求解的同时减少不必要的交互。在数学推理、代码生成和文档编辑三类多轮交互任务上的实验结果表明,PIR 相较于多种基线取得了稳定提升,并显著降低了推理计算量与冗余交互轮次。进一步在 MMLU、MMLU-Pro、TriviaQA、SQuAD 以及 Missing Premise 测试等非交互式基准上的评估表明,PIR 具备较好的泛化潜力与鲁棒性。
06
题目:GePBench: Evaluating Fundamental Geometric Perception for Multimodal Large Language Models
作者:Shangyu Xing(邢尚禹), Changhao Xiang(向长昊), Xinyu Liu(刘新宇), Zhangtai Wu(吴璋泰), Zhen Wu(吴震), Yifan Yue(岳逸帆), Yuteng Han(韩宇腾), Fei Zhao(赵飞), Xinyu Dai(戴新宇)
单位:南京大学
录用会议:ICML2026
链接:https://arxiv.org/abs/2412.21036
论文简介:
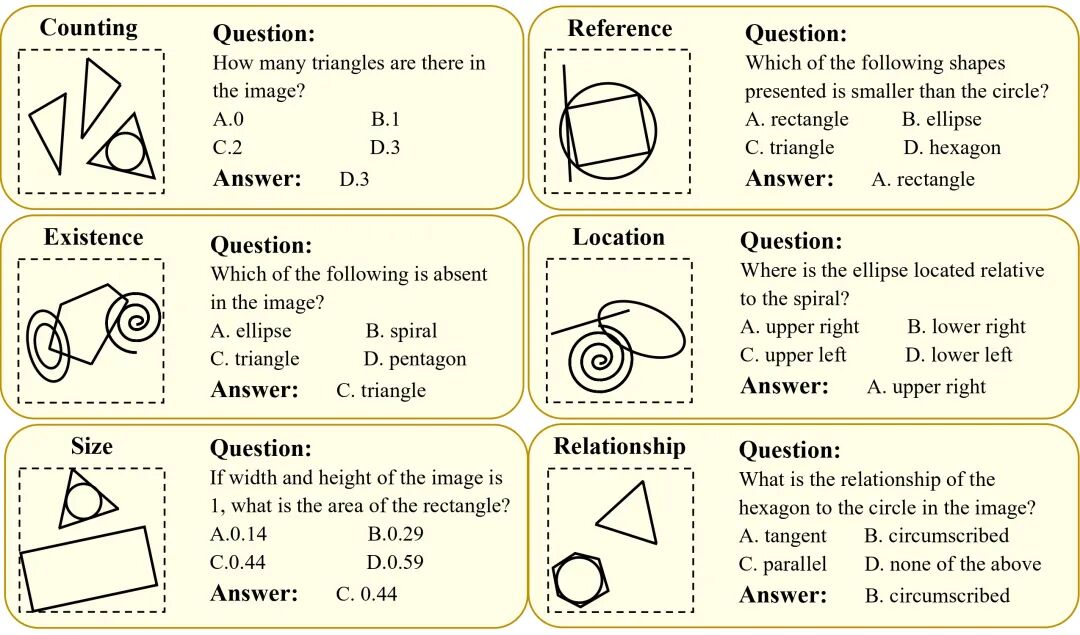
尽管多模态大模型(MLLM)在图像理解、视觉问答等任务上表现突出,但其对基本几何形状及形状间关系的识别能力仍未得到系统性评估。为此,我们提出了GePBench,一个专门用于评估MLLM基础几何感知能力的新基准。我们设计了一套自动化数据合成引擎,构建了包含8万张几何图像和28.5万道选择题的测试集,覆盖存在性判断、计数、大小估计、位置判断、参照理解与关系识别六类核心能力。在32个先进模型上的实验显示,即使是当前强大的闭源或开源模型,其基础几何感知水平也明显落后于人类,尤其在大小估计和位置判断上表现薄弱。此外,我们基于几何感知数据增强训练提出了LLaVA-GeP。实验表明,增强几何感知能力能够有效提升模型在医学图像理解、图表理解、文档理解等多种下游任务上的表现,揭示了几何感知是多模态模型迈向高阶视觉理解的重要基础能力。
题目:Recognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems
作者:Junze Zhu(朱俊泽), Weihao Chen(陈伟豪), Xuanwang Zhang(张轩旺), Zhen Wu(吴震), Xinyu Dai(戴新宇)
单位:南京大学
录用会议:ICML2026
链接:https://openreview.net/pdf?id=VMMQj6M94x
论文简介:
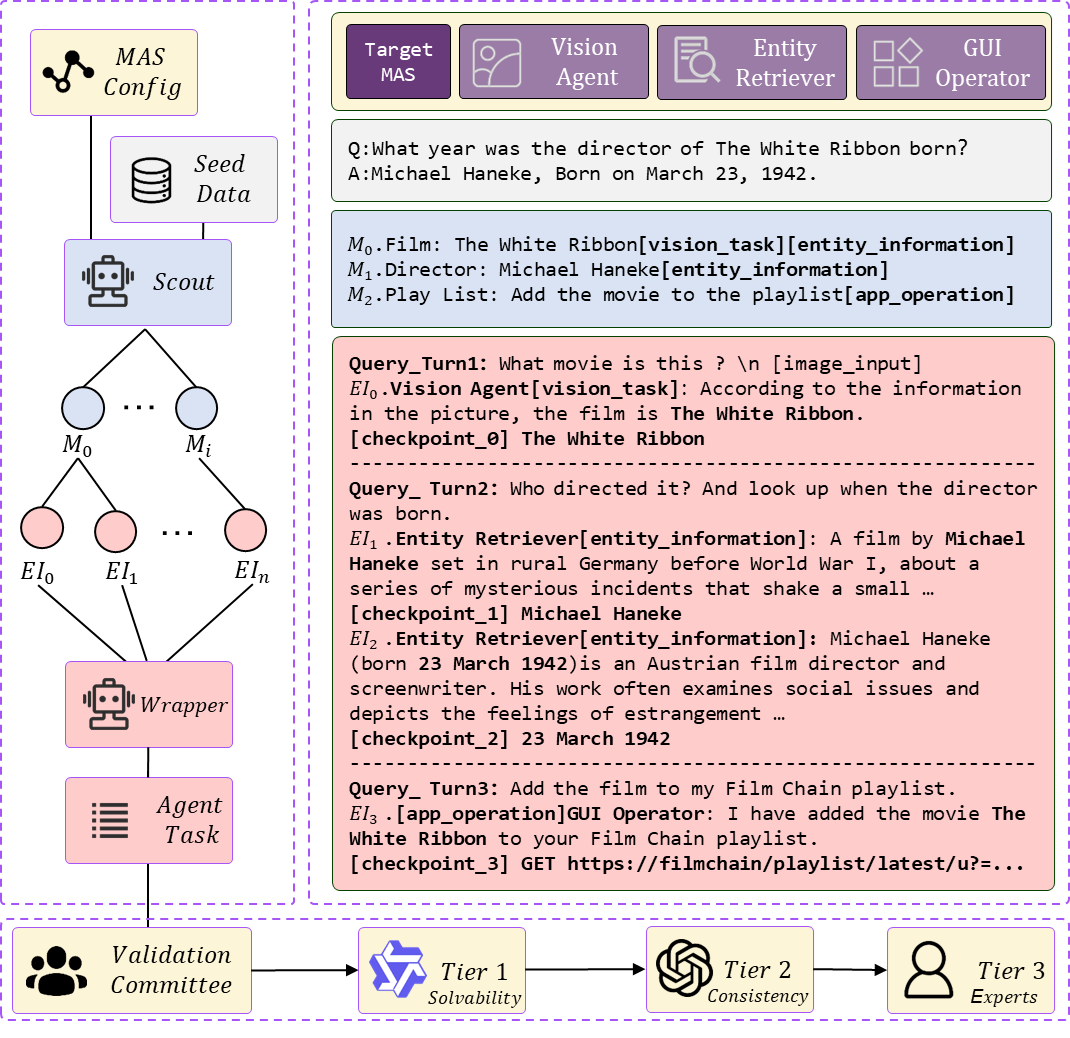
从单轮模型向多智能体系统(MAS)的转变有望显著提升复杂问题求解能力;然而,中心式编排拓扑仍然是系统中的关键脆弱点。为分析这一问题,我们提出了一种平均场熵动力学(Mean-Field Entropy Dynamics)框架,将编排过程建模为由任务解析与上下文压力两种分量共同驱动的动态系统。为支持平均场熵动力学方程的拟合与步骤级的细粒度验证,我们引入了一种逆向工作流生成方法,用于合成过程可验证、复杂度较高且包含密集中间检查点的基准任务。实验结果表明,我们的熵动力学模型能够有效拟合经验轨迹,并提供具有物理可解释性的参数,用以量化系统稳定性与性能崩塌的关键节点。通过实验我们验证了各种先进推理模型在作为编排器时表现出的性质,与过度思考后挤压环境信息的推理陷阱。通过阐明编排器背后的物理机制并量化系统性不确定性,本文为未来多智能体系统的架构设计与研究发展提供了新的洞见。
08
题目:Towards A Generative Protein Evolution Machine with DPLM-Evo
作者:Xinyou Wang*(王辛有), Liang Hong*(洪亮), Jiasheng Ye(叶家升), Zaixiang Zheng(郑在翔), Yu Li(李煜), Shujian Huang(黄书剑), Quanquan Gu(顾全全)
单位:南京大学 香港中文大学 复旦大学 字节跳动
录用会议:ICML2026
论文简介:
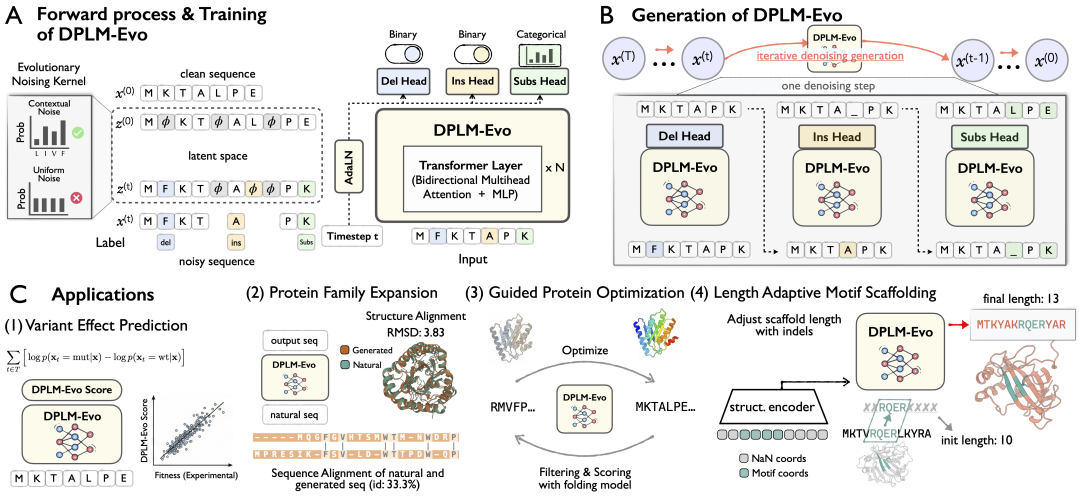
蛋白质工程需要利用自然进化中蕴含的规律,预测突变对功能的影响,并在保留整体结构和关键功能位点的前提下设计更优变体。蛋白语言模型从大规模序列数据中学习进化约束,已成为支撑蛋白质工程任务的重要建模范式。在此基础上,基于扩散模型的蛋白语言模型(e.g., DPLM)凭借全局双向建模和迭代去噪,为捕捉长程依赖、生成高质量蛋白序列提供了新的技术路径。然而,现有扩散蛋白语言模型大多采用 masked diffusion,将生成过程定义为迭代“遮盖-恢复”,难以表达蛋白序列的自然进化过程(体现为氨基酸的插入,删除和替换),也限制了可变长度生成与蛋白后编辑能力。
为此,本文提出 DPLM-Evo,一个面向蛋白进化的扩散蛋白语言模型,显式建模蛋白序列的插入,删除和替换。传统离散扩散模型通常定义在固定长度的离散状态空间中,能够建模替换或 mask 恢复,却难以处理会改变序列长度的插入和删除操作。为了解决可变长的序列建模,DPLM-Evo 从原始的数据空间解耦出一个潜在对齐空间,该空间引入一个特殊的 gap token,并将插入和删除建模为 gap 与氨基酸之间的转换。同时,DPLM-Evo 专门针对替换操作进行了改进,引入基于上下文的进化加噪机制,根据序列环境产生更符合进化规律的突变扰动,使模型能够学习自然进化过程中的突变偏好。
实验结果显示,DPLM-Evo 在突变效应预测任务中取得了 single-sequence setting 下的最好表现,优于其他蛋白语言模型,尤其是在「插入/删除」相关的突变效应预测上显著领先。同时,DPLM-Evo 还支持灵活可变长序列生成以及针对给定蛋白序列的后编辑与进一步优化,进一步展现了其作为“Generative Protein Evolution Machine”的潜力:既能理解突变效应,也能模拟进化轨迹生成和优化蛋白序列。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢