

论文:BuildArena: A Physics-Aligned Interactive Benchmark of LLMs for Engineering Construction
单位:西湖大学
发布日期:2026年4月
请索引第91篇论文
 |  |
大模型学会“无中生有”造机器了吗?西湖大学BuildArena给出硬核答案!
当ChatGPT还在帮你写诗、写代码时,新一代的大模型(LLM)已经开始“下海”搞工程了——设计桥梁、组装汽车、甚至发射火箭!但问题是,它们真的懂物理吗?还是会造出一堆“赛博废品”?
近日,西湖大学“AI for Scientific Simulation and Discovery Lab” 投递给顶级会议 ICML 2026 的重磅论文 《BuildArena: A Physics-Aligned Interactive Benchmark of LLMs for Engineering Construction》 引爆了学术界。他们创建了史上首个专为大模型工程建造量身定制的“物理对齐交互式基准测试”。
今天,「图科学实验室」就带大家深度拆解这篇硬核论文,看看谁能成为AI界的“鲁班大师”!
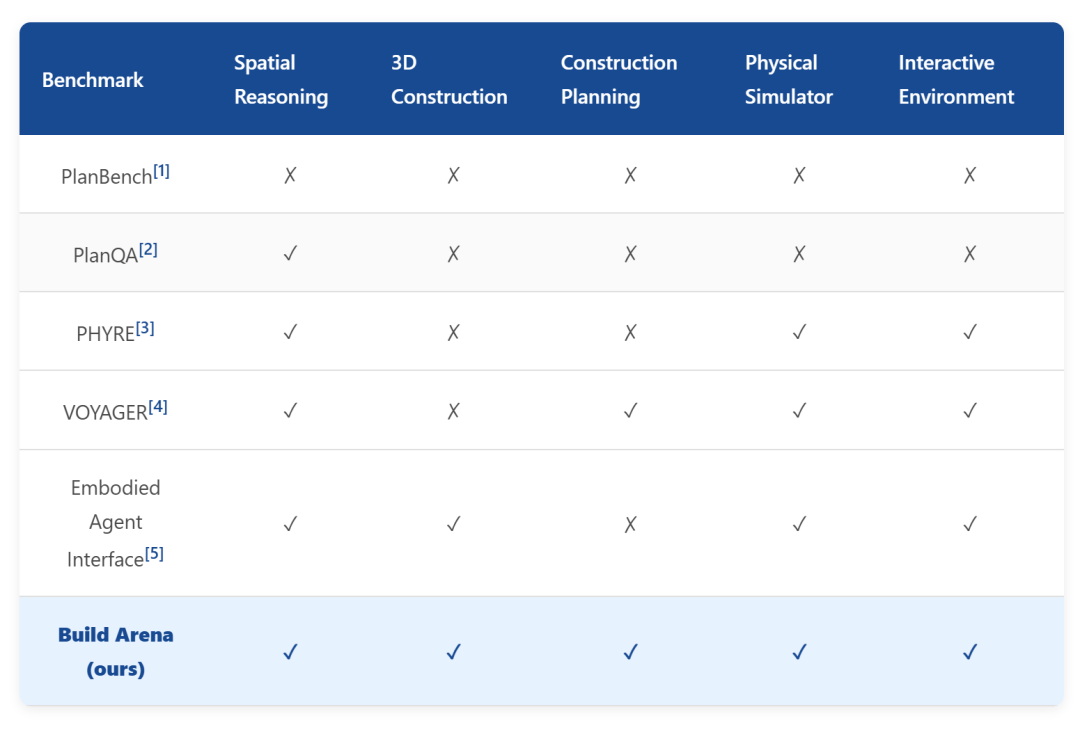
01 为什么我们需要一个大模型“工地”?
想象一下这样的未来图景:你只需对AI说一句:“帮我设计一辆能在火星表面行驶的探测车”,AI就能瞬间生成完美的零部件图纸、计算出材料承重,并给出一步步的装配指南。这就是工程建造自动化(Engineering Construction Automation)的终极梦想。
但是,让大语言模型(LLM)去搞工程,面临着两大“致命”挑战:
缺乏物理常识的试炼场: 以往的训练和测试大多停留在文本层面,LLM哪怕写出了违背牛顿定律的代码,只要语法正确就能蒙混过关。
极其复杂的长程规划: 造一架飞机不是写几句话那么简单,它需要层次化的结构设计、严密的时序控制,以及极其精准的3D空间几何推理。稍有偏差,就会“车毁人亡”。
为了真实评估各大LLM的“动手能力和智商”,西湖大学的研究团队重磅推出了 BuildArena。这不仅是一个测试基准,更是一个高度可定制、可扩展的研发框架。

图1:BuildArena建造结果示例。 直观展示了不同任务下LLM生成的最终物理结构形态。
02 BuildArena的“三大试炼”与“黄金工作流”
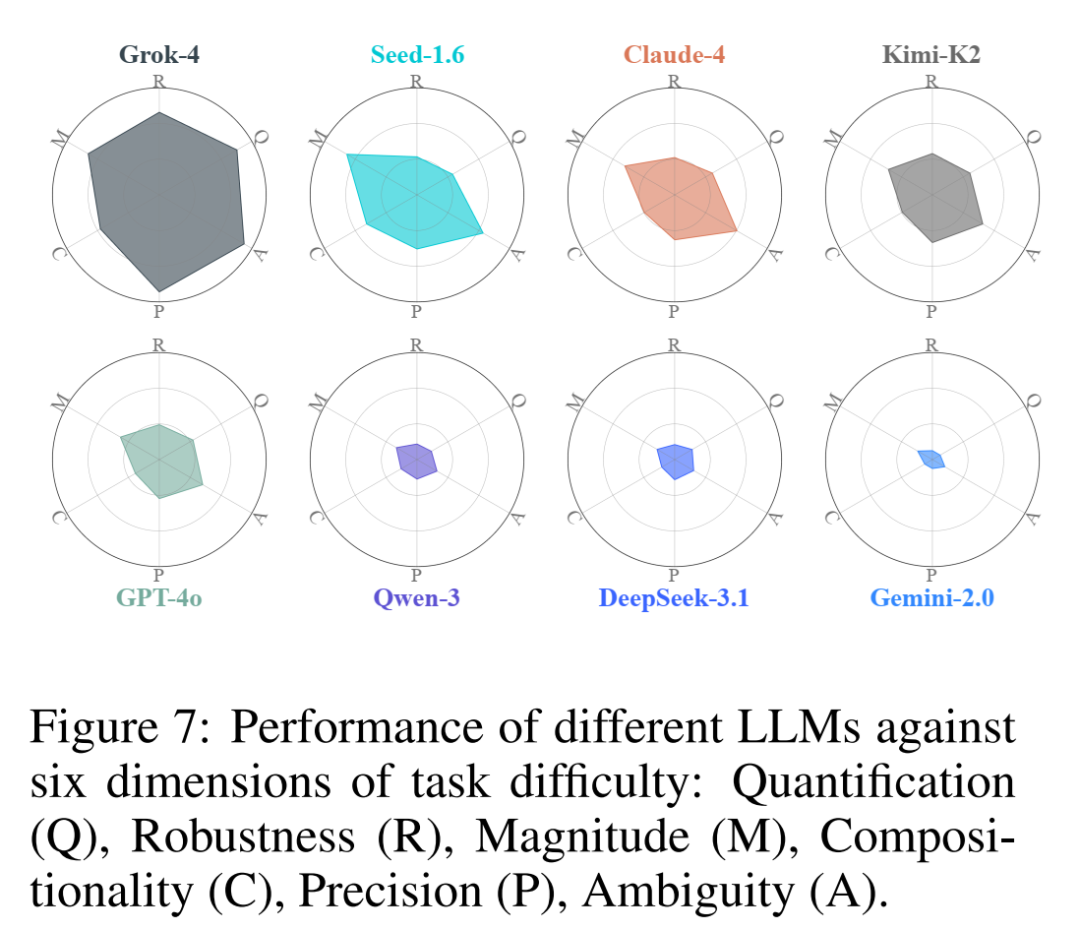
BuildArena究竟是怎么给大模型出卷子的?研究团队巧妙地抽象出了工程中六个核心的难度维度:量化计算、鲁棒性、规模跨度、组合复杂度、操作精度以及指令模糊性。
基于这些维度,他们设立了三大经典工程关卡,难度从 Lv.1 到 Lv.3 依次递增:
Transport(交通运输): 造一辆车(或载具),让它跑得越远越好。考察对移动部件的空间利用。
Support(承重支撑): 造一座桥,跨越不断加宽的鸿沟,承受越来越重的货物。考察静态结构稳定性。
Lift(垂直发射): 造一个火箭发动机乃至完整的火箭飞机,让它飞得越高越好。这是最难的一关,考验模块化组装和严格的重心控制。
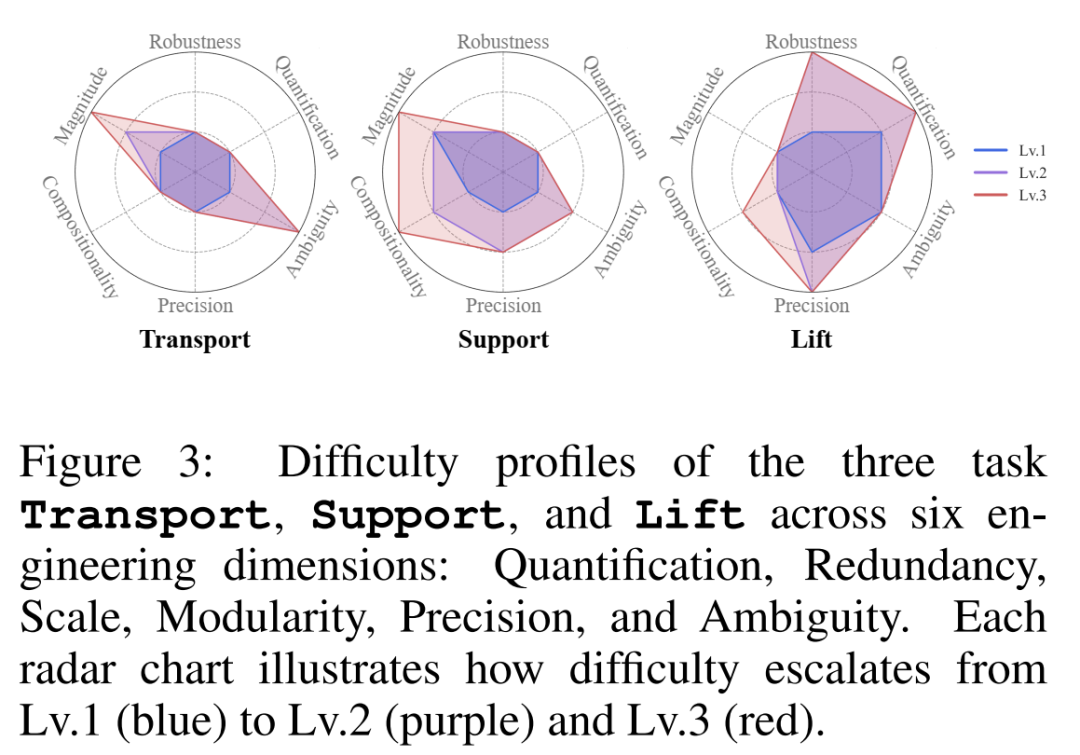
图3:三大任务的工程难度维度雷达图。 直观展示了从 Lv.1(蓝)到 Lv.3(红),各项工程挑战如何呈指数级飙升。
03 核心技术突破:让LLM真正“懂”物理建模
为了让LLM能与物理引擎无缝对接,研究团队做了一件极具工程意义的事:逆向解析并复现了风靡全球的沙盒建造游戏《Besiege》的底层几何计算逻辑,开发了一套开源的 3D 空间几何计算库。
这套系统就像一座“翻译桥”,能把LLM输出的自然语言指令,精准转化为无碰撞、符合物理约束的3D坐标代码。如果LLM瞎指挥(比如把轮子悬空安装),系统会立刻报错并打回重做。
04 惊艳的 Agentic Workflow:五大智能体协同作战
直接让LLM去盲造肯定是一团糟。为此,研究人员设计了一个极其优雅的多智能体协作工作流(Agentic Workflow),作为测试的基线:
P (Planner) 规划者: 负责宏观统筹,拆解任务。
D (Drafter) 起草者 & R (Reviewer) 审查者: 两人形成“草稿-审查”闭环,不断打磨出可行的微观设计方案。
G (Guidance) 指导者 & B (Builder) 构建者: 指导者一步步下达操作建议,构建者将其转化为具体代码并在几何库中执行。遇到报错就退回去修改。
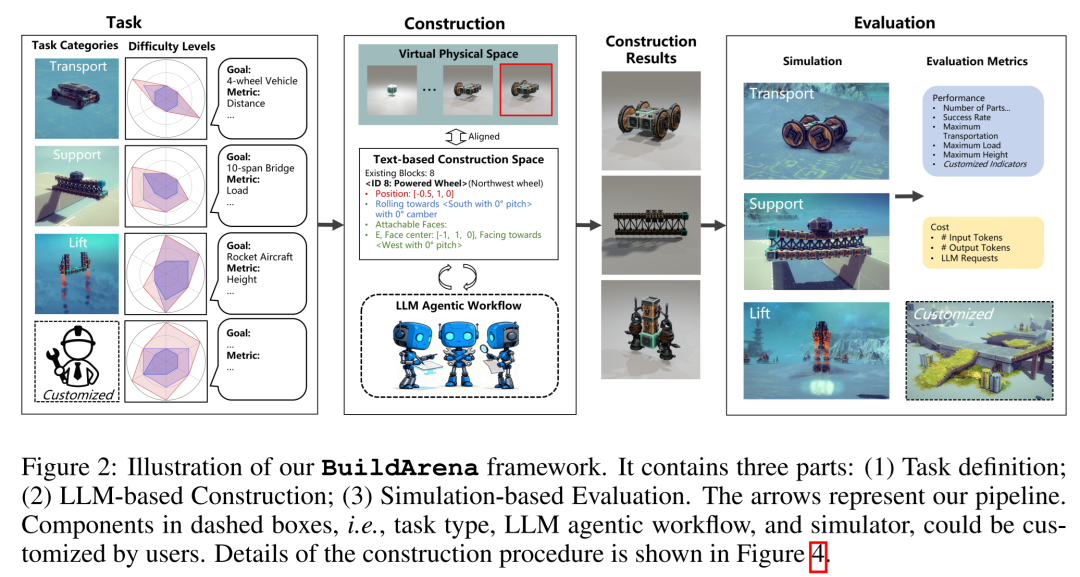
图2:BuildArena 整体框架图。 展示了从任务定义、LLM构建到基于模拟器的评估三大核心组件。
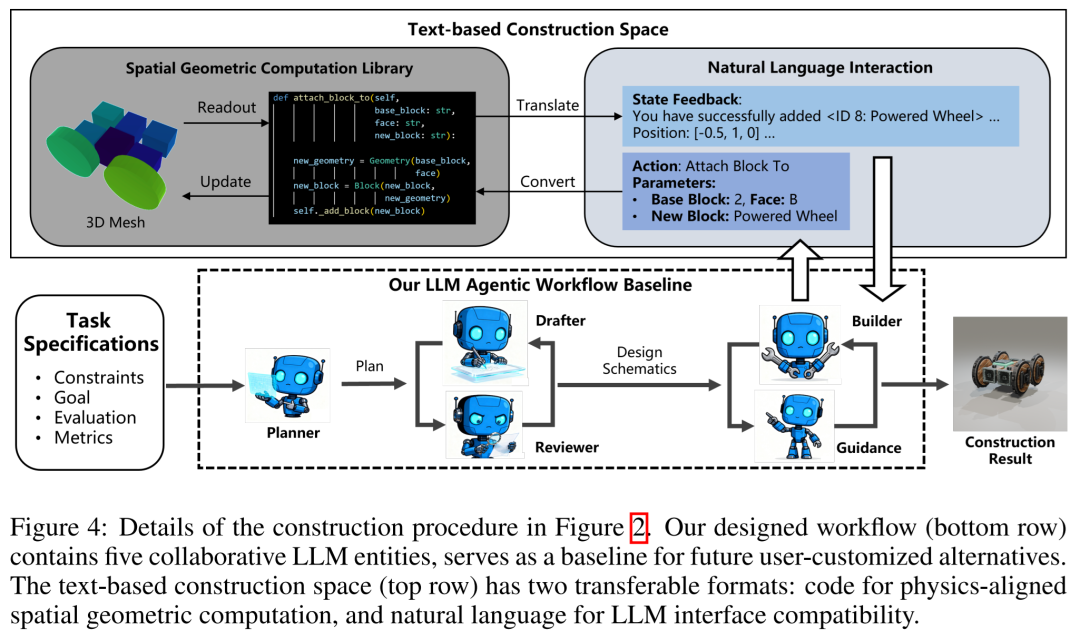
图4:LLM Agentic 工作流细节图。 五大智能体(P, D, R, B, G)如何通过文本空间和计算库进行高效协作。
05 八仙过海,各显神通:谁是真正的“机械大师”?
研究团队找来了当下最火的 8 位“顶流”大模型选手 进入 BuildArena 一较高下:
(GPT-4o, Claude-4, Grok-4, Gemini-2.0, DeepSeek-3.1, Qwen-3, Kimi-K2, Seed-1.6)
每个模型对每个任务都要进行 64 次独立采样测试,最终数据可以说是相当真实且残酷。我们直接来看核心成绩单(表2):
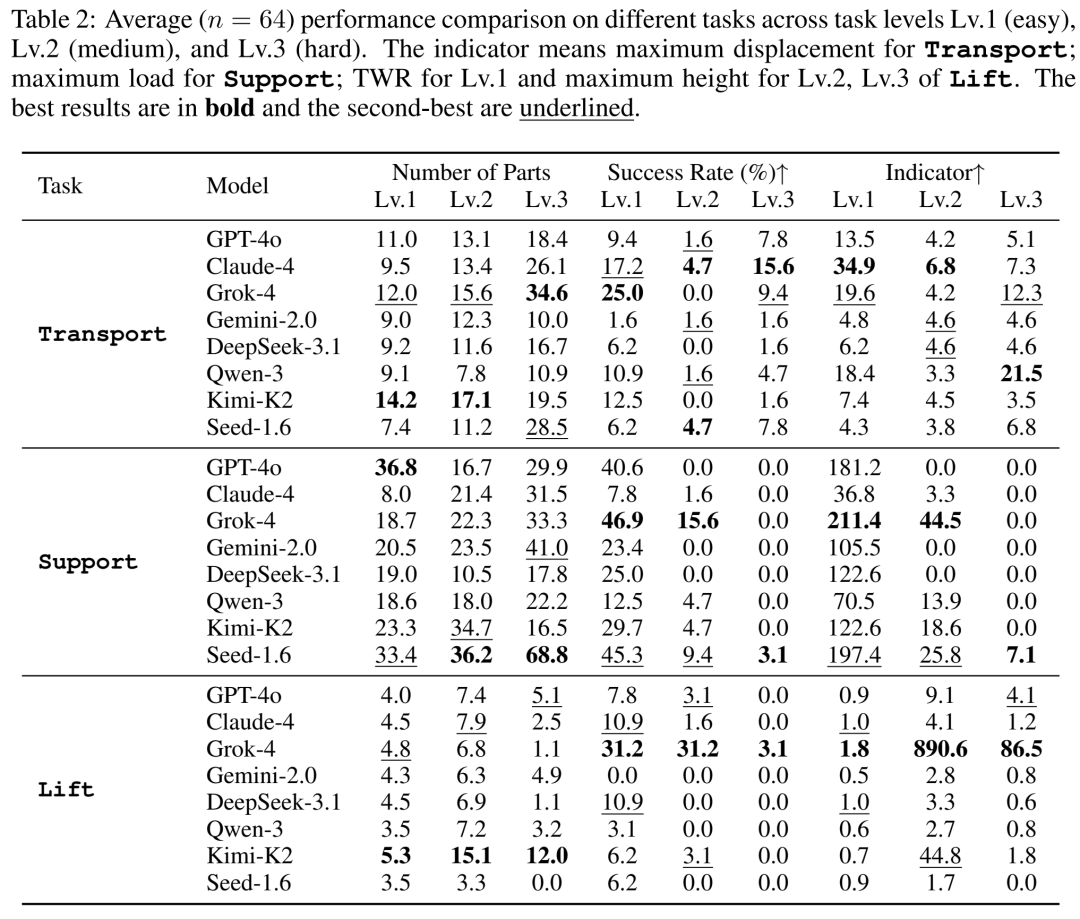
表2:八大模型在三大任务(Transport, Support, Lift)不同难度级别的表现对比。
指标说明:
Number of Parts(零件数):越少越好(工程美学:极简即极美)。
Success Rate(成功率):越高越好。
Indicator(任务特定指标):Transport看最大位移,Support看最大承重,Lift看推力重量比/最大高度。越高越好。
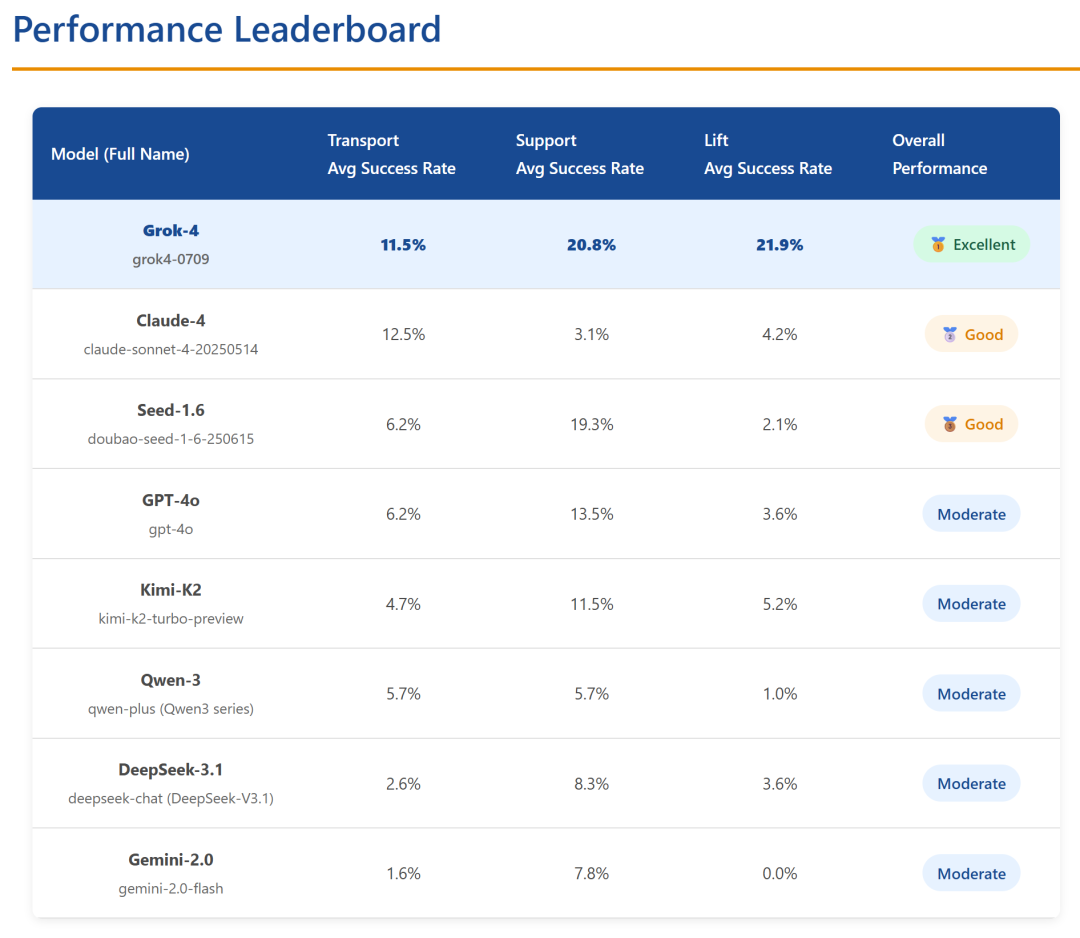
透过数据看本质:
绝对王者:Grok-4
在最具挑战性的 Lift(发射)任务中,Grok-4 展现了恐怖的统治力!在 Lv.2 难度下,它的成功率高达 31.2%,最大飞行高度更是达到了惊人的 890.6(其他模型连 100 都很难达到)。这说明 Grok-4 在处理极其严密的模块化组装和物理参数计算时,具有断层式的优势。
六边形战士:Claude-4
Claude-4 虽然没有一项数据是绝对的第一,但它的表现极其均衡且稳健。无论是在 Transport 还是 Support 任务中,它都保持着不错的成功率和指标,展现了强大的综合逻辑推理能力。
残酷的现实:高级物理推理全军覆没
看看 Support 任务的 Lv.3(最高难度建桥),所有 8 个模型的成功率全部为 0%! 在 Lift 任务的 Lv.3 中,除了 Grok-4 勉强达到 3.1%,其他模型也全部挂科。这血淋淋的数据告诉我们:目前的 LLM 在面对高难度的物理结构设计和长程规划时,依然束手无策。
工程美学缺失:AI 偏爱“暴力美学”
在 Support 任务中,老牌强者 GPT-4o 虽然取得了 40.6% 的成功率,但它用的零件数高达 36.8 个!相比之下,Claude-4 仅用 8.0 个零件就完成了基础建桥。这说明 AI 目前还不懂“大道至简”的工程美学,经常采用冗余设计来强行凑出结果。
06 给本硕博研究生的学术启发
读完这篇论文,作为身处科研一线的本硕博学生们,我们能从中汲取什么营养?
评估基准(Benchmark)永远是硬通货。 在 AI 圈,提出一个公认的高质量 Benchmark,其影响力往往不亚于一两个 SOTA(当前最佳)模型。BuildArena 巧妙地将“LLM + 物理引擎 + Agent 工作流”结合在一起,填补了领域空白。
Agent 工作流设计大有可为。 论文中那个“五大智能体协同”的基线工作流设计得非常漂亮。它证明了,面对复杂任务,合理的任务拆解和多轮自我修正机制(Self-Correction)能够有效提升 LLM 的表现上限。
物理对齐(Physics Alignment)是一片蓝海。 大家都关注 Model Alignment(如 RLHF),但 AI 真正要走进现实世界(Robotics, AI4Science),就必须跨越“物理规律”这道坎。如何将物理约束无缝融入到 AI 的生成过程中,是一个极具潜力的研究方向。
07 结语
BuildArena 的出现,不仅是一份给各大语言模型的大考卷,更是为人类指明了一条通往通用人工智能(AGI)的必经之路——从“纸上谈兵”到“亲手造物”。

虽然目前所有的模型在最高难度的物理建造前都折戟沉沙,但这正是科研的魅力所在。下一次,会不会是你或者你的课题组,提出了打破 0% 成功率的突破性算法呢?
喜欢今天的硬核解读吗?欢迎在评论区留下你看完后的想法,或者分享给同样关注AI前沿的同门好友!我们下期见!



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢