
【论文标题】UNIMO: Towards Unified-Modal Understanding and Generation via
Cross-Modal Contrastive Learning
【作者团队】Wei Li, Can Gao, Guocheng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu, Haifeng Wang
【发表时间】2020/12/31
【论文链接】https://github.com/weili-baidu/UNIMO
【推荐理由】本文来自百度团队,文章提出了一个统一的多模态预训练模型UNIMO,该模型能够有效地适应单模态和多模态的理解和生成任务。
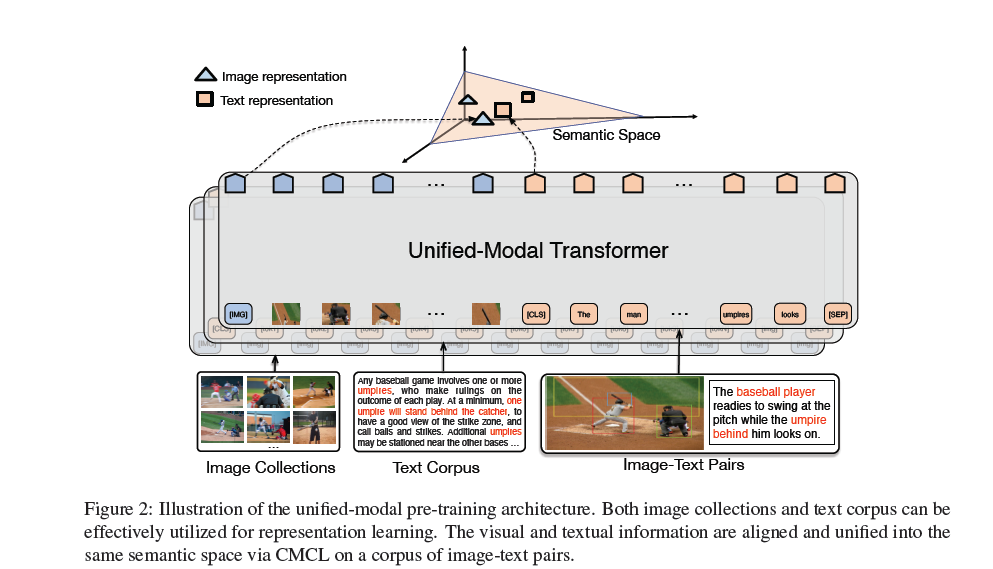
近年来,预训练技术在计算机视觉和自然语言处理领域均受到广泛关注。在视觉领域,通常在 ImageNet 数据上进行纯视觉的单模预训练,训练 ResNet、VGG 等图像特征抽取模型。在自然语言处理领域,基于自监督的预训练模型,如 BERT、UniLM、ERNIE,则利用大规模的单模文本数据,训练了强大的语义表示能力。为了处理多模场景的任务,各种多模预训练模型进一步被提出来,如 ViLBERT、UNITER 等。这些多模模型在图文对(Image-Text Pairs)数据上进行预训练,从而支持下游的多模任务。受限于只能使用图文对数据,多模预训练模型仅能进行小规模数据的训练,并且难以在单模下游任务上使用。
事实上,现实世界中同时存在大量纯文本、纯图像的单模数据,也存在图文对的多模数据。显然,一个强大且通用的 AI 系统应该具备同时处理各种不同模态数据的能力。为此,百度提出统一模态预训练,同时使用文本、图像、图文对数据进行预训练,学习文本和图像的统一语义表示,从而具备同时处理单模态和多模态下游任务的能力。对于大规模的单模图像数据和单模文本数据,UNIMO 采用类似的掩码预测自监督方法学习图像和文本的表示。同时,为了将文本和图像的表示映射到统一的语义空间,论文提出跨模态对比学习,基于图文对数据实现图像与文本的统一表示学习。
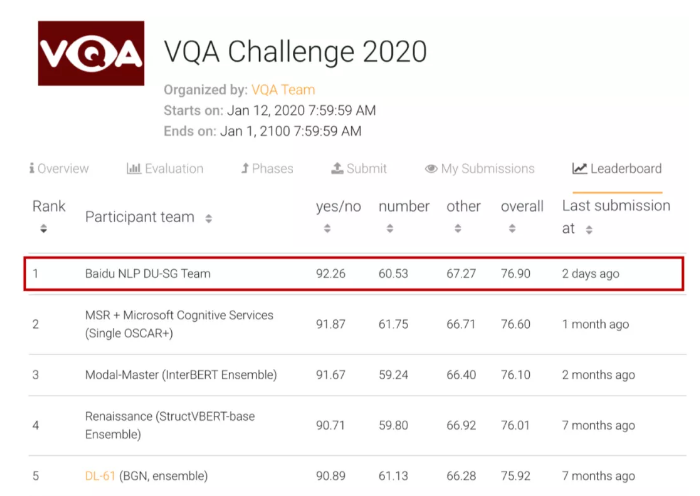
 此外,百度基于 UNIMO 还刷新了视觉问答 VQA 权威榜单,超越了微软、阿里巴巴、Facebook 等知名单位,位列榜首,进一步说明了统一模态预训练的领先性。
此外,百度基于 UNIMO 还刷新了视觉问答 VQA 权威榜单,超越了微软、阿里巴巴、Facebook 等知名单位,位列榜首,进一步说明了统一模态预训练的领先性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢