
DRUGONE
多组学技术的发展使研究人员能够从分子层面更深入地理解疾病发生机制,其中代谢组学与蛋白质组学被认为是最具临床转化潜力的两类组学数据。然而,能够同时整合两类组学并系统评估其疾病预测能力的大规模研究仍然较少。该研究基于英国生物银行(UK Biobank)23,776名参与者的数据,整合了159种基于核磁共振(NMR)的代谢物以及2,923种Olink平台检测的血浆蛋白,系统评估其对17种常见疾病发生风险的预测能力。结果显示,与传统临床预测模型相比,加入组学数据后,17种疾病的预测性能均显著提升。总体而言,蛋白质组模型在17种疾病中的16种表现优于代谢组模型,而同时整合代谢组与蛋白质组相比,仅使用蛋白质组并未带来明显额外提升。研究人员进一步识别出多个关键组学特征,包括前列腺癌中的KLK3/PSA等经典标志物,以及皮肤癌中的PRG3等潜在新型分子。此外,研究还通过蛋白质关联分析,将疾病与药物使用、社会经济因素以及生活方式因素联系起来,展示了多组学数据在疾病风险预测、机制解析以及未来药物开发中的巨大潜力。

疾病风险分层是现代精准医学的重要基础。传统疾病风险评估主要依赖年龄、性别、BMI、吸烟状态以及常规实验室检测等临床指标。这些指标虽然具有一定预测能力,但往往难以完整反映疾病背后的复杂分子机制。近年来,高通量组学技术快速发展,使研究人员能够在分子层面系统刻画人体生物过程,从而为疾病预测和个体化医疗提供新的可能。
代谢组学通过测量血液中的小分子代谢物,能够反映机体当前代谢状态。此前已有研究证明,基于NMR平台的代谢组数据可以显著提升多种疾病风险预测能力。另一方面,蛋白质组学则能够更加直接地反映细胞功能状态以及疾病相关信号通路,因此近年来也被广泛用于疾病机制研究与临床风险预测。
英国生物银行的大规模组学数据,为系统研究疾病与组学之间的关系提供了理想资源。然而,目前大多数研究往往只关注单一组学,例如仅分析代谢组或仅分析蛋白质组,对于两类组学联合建模的研究相对有限。研究人员因此提出,希望通过整合代谢组与蛋白质组数据,更全面地评估其在疾病预测中的价值,并探索不同组学层面所反映的疾病生物学机制。
方法
研究纳入了23,776名英国生物银行参与者,所有个体均拥有完整的159种代谢物和2,923种蛋白质数据。研究疾病涵盖17种常见疾病,包括心血管疾病、癌症、呼吸系统疾病、神经退行性疾病、肾脏疾病以及骨折等。研究人员构建了三类基线临床模型:第一类仅包含年龄和性别;第二类为ASCVD相关心血管风险因子;第三类为更全面的PANEL模型,包含人口学、生活方式和实验室指标。
在建模过程中,研究人员首先使用Cox比例风险模型校正临床协变量,并提取Martingale残差作为后续机器学习预测目标。随后,研究人员利用mixOmics框架进行多组学整合建模,分别构建代谢组模型、蛋白质组模型以及联合组学模型。整个分析采用五次重复五折交叉验证,并使用Harrell’s C-index评估模型预测性能。研究还进一步计算各组学特征的重要性评分,并对关键代谢物与蛋白质进行通路富集分析和孟德尔随机化分析。
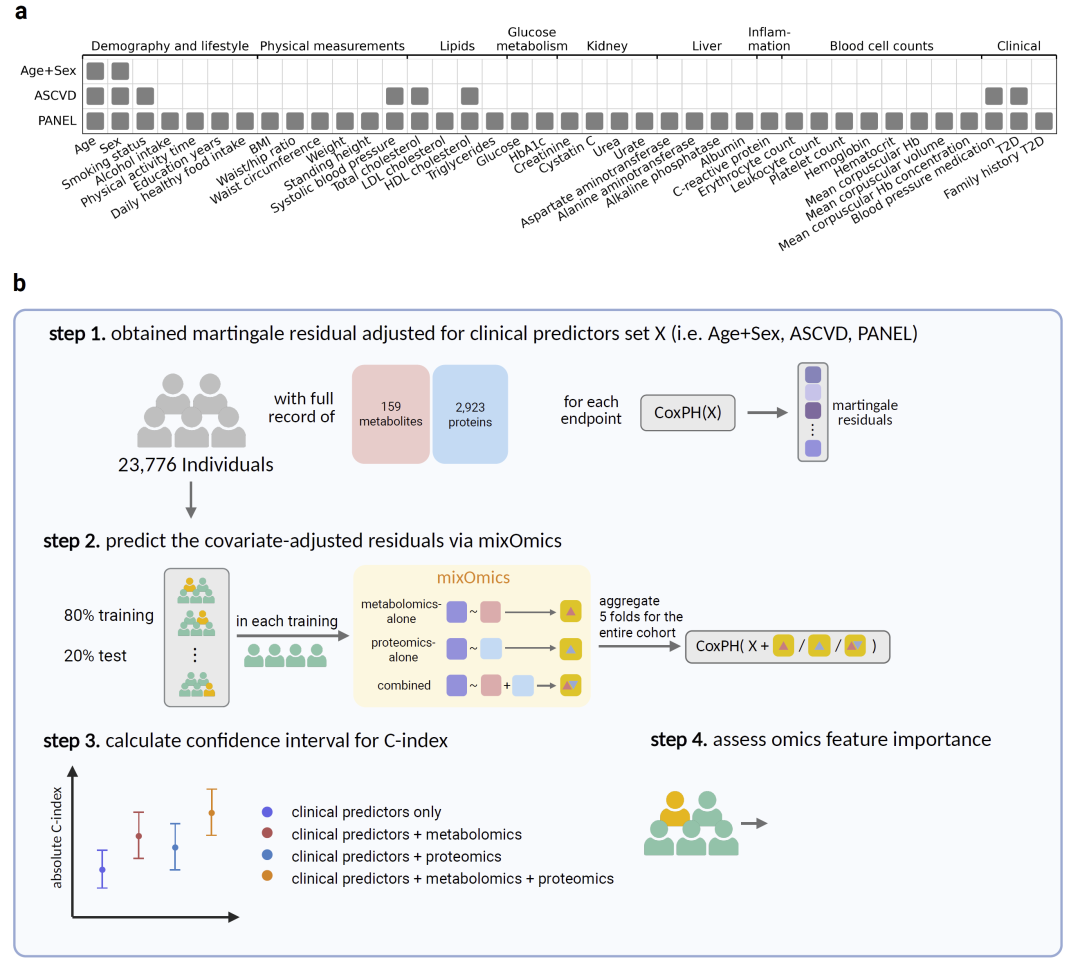
图1:研究总体设计与多组学预测流程图。
结果
多组学数据显著提升17种疾病预测能力
研究发现,无论采用哪一种临床基线模型,只要加入组学数据,17种疾病的预测性能均出现统计学显著提升。与单纯临床模型相比,加入组学后平均C-index分别提升0.063、0.038和0.030。尤其在前列腺癌预测中,仅加入蛋白质组数据就使C-index从0.66提升至0.75,显示出组学数据在疾病风险预测中的巨大增益。
这些结果说明,即使在已经包含大量临床变量的PANEL模型中,多组学数据依然能够提供额外、独立的疾病风险信息。
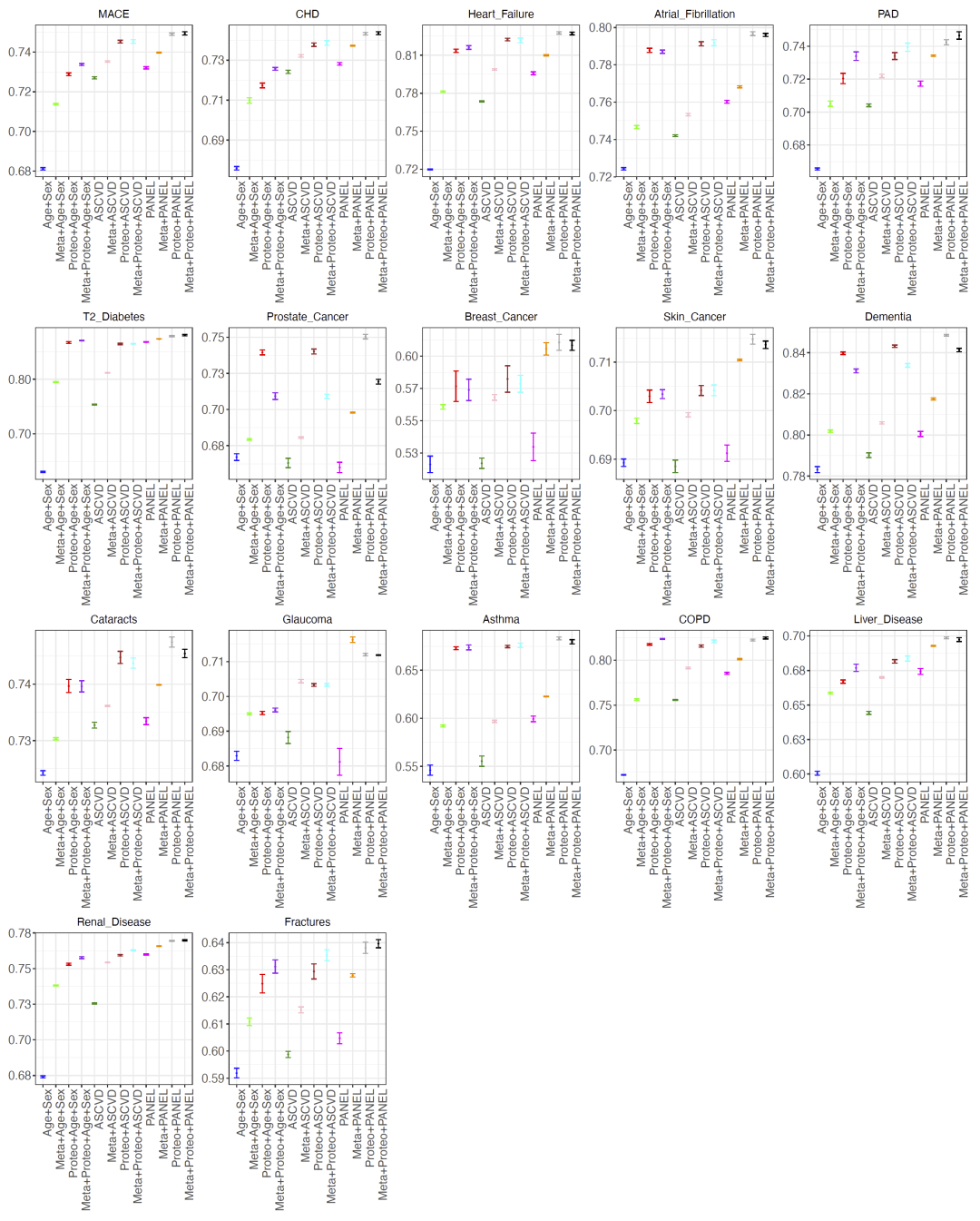
图2:不同组学模型在17种疾病中的预测性能比较。
蛋白质组整体优于代谢组
研究进一步比较了代谢组模型、蛋白质组模型以及联合模型之间的差异。结果显示,在17种疾病中的16种中,蛋白质组模型均显著优于代谢组模型,仅青光眼例外。特别是在哮喘预测中,蛋白质组模型相较代谢组模型展现出最大的优势。
更令人意外的是,同时整合代谢组与蛋白质组,并未显著优于单独使用蛋白质组。这意味着蛋白质组已经捕获了绝大多数疾病相关信息,而额外加入代谢组反而可能增加模型复杂度并带来轻微过拟合。研究人员指出,这一结果部分可能与当前蛋白质组平台检测到的特征数量远多于代谢组有关。
发现大量经典与潜在新型疾病标志物
研究人员系统分析了联合模型中的关键组学特征,并成功验证了大量已知疾病标志物。例如,在前列腺癌中,KLK3/PSA是最显著的预测蛋白;在白内障中,CRYBB2蛋白显著相关;在阿尔茨海默病相关痴呆中,APOE、GFAP和VGF等经典神经退行性疾病蛋白同样位列关键特征。
在心血管疾病中,BNP和NT-proBNP等经典心衰标志物,在房颤、冠心病、心衰和MACE中均表现出显著关联。此外,不同心血管疾病之间还展现出共享但又略有差异的蛋白质特征模式。例如,MACE和冠心病具有高度相似的蛋白特征,而外周动脉疾病则呈现出更加独特的分子模式。
研究还发现了一些潜在新型疾病相关蛋白。例如,在皮肤癌中,PRG3和GGT5被识别为新的重要蛋白。进一步孟德尔随机化分析显示,PRG3可能与皮肤癌存在潜在因果关系,PRG3表达升高与皮肤癌风险下降相关。
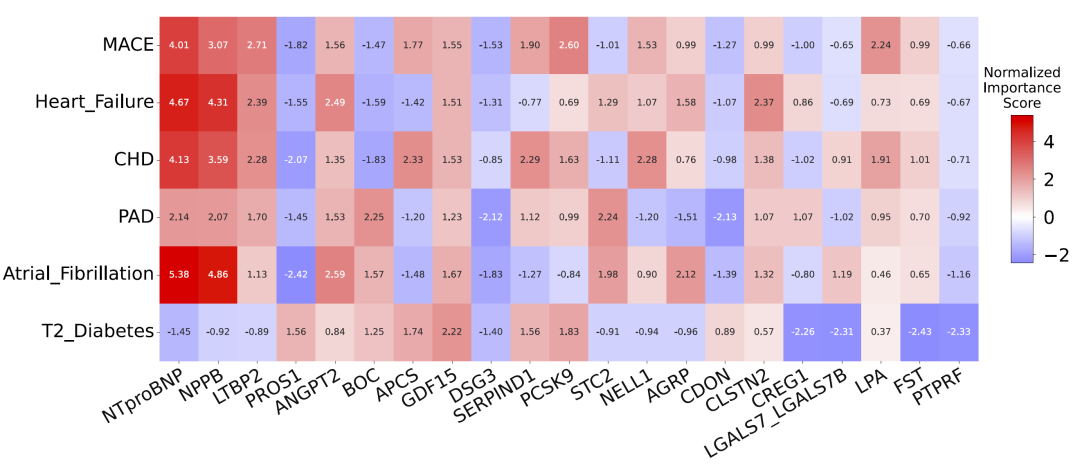
图3:不同疾病中的关键蛋白与代谢物特征图谱。
代谢组与蛋白质组反映不同疾病层面
研究人员进一步对关键组学特征进行了KEGG通路分析。结果发现,代谢组主要反映的是系统性脂质代谢紊乱,因此不同疾病之间共享大量相似代谢通路,例如脂肪酸代谢和HIF-1信号通路。
相比之下,蛋白质组则更能够反映疾病特异性的组织重塑与信号转导。例如,胆固醇代谢在MACE中最显著,细胞黏附与整合素信号在肾病中突出,而细胞因子通路则在COPD中显著富集。
此外,研究还发现一些代谢组与蛋白质组共享的重要通路,例如2型糖尿病中的胰岛素抵抗通路,以及COPD中的AGE-RAGE信号通路。这些共享通路可能代表疾病发生过程中代谢变化与蛋白信号网络协同作用的关键节点。
结果五:蛋白质特征与药物和社会经济因素存在关联
研究人员进一步利用外部蛋白质组数据库,分析关键蛋白与药物使用以及社会经济因素之间的关系。结果发现,多种心血管疾病相关蛋白与Bisoprolol、Warfarin以及Furosemide等经典心血管药物高度相关。COPD与哮喘相关蛋白则与Salbutamol、Fluticasone等呼吸系统药物显著相关。
更重要的是,研究还发现社会经济因素与疾病相关蛋白存在显著联系。例如,COPD相关蛋白与家庭收入水平和Townsend贫困指数高度相关。进一步孟德尔随机化分析显示,家庭收入较低与COPD风险增加存在潜在因果关系。这意味着社会经济因素不仅是流行病学风险因子,也可能通过分子层面影响疾病发生。
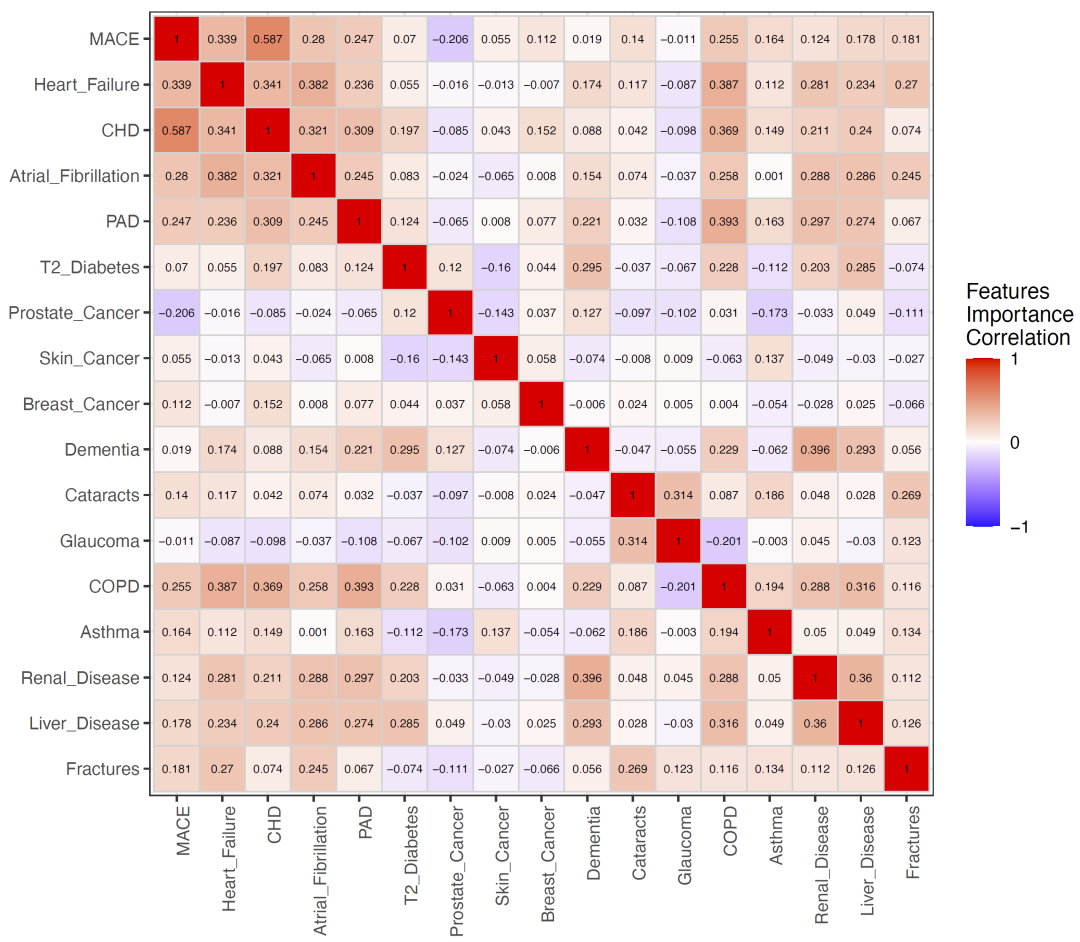
图4:关键蛋白与药物、社会经济和生活方式因素关联网络图。
讨论
该研究是目前规模最大的多组学疾病预测研究之一,系统评估了代谢组和蛋白质组在17种疾病中的预测能力。结果表明,蛋白质组相比代谢组具有更强预测价值,而联合整合多组学并不一定能够进一步提升模型性能。这提示未来多组学整合并非简单“数据越多越好”,而需要更加合理的建模策略与特征选择方法。
研究还揭示了代谢组与蛋白质组所反映的疾病层面存在本质差异。代谢组更多体现全身代谢背景,而蛋白质组则更加接近组织损伤、炎症反应以及细胞信号转导等疾病核心机制。这种差异说明,不同组学可能分别适用于不同临床场景,例如代谢组适合系统性疾病状态监测,而蛋白质组更适合精准疾病风险预测。
此外,研究不仅发现了大量经典疾病标志物,还提出了多个潜在新型蛋白,例如PRG3与皮肤癌的潜在因果关系。这些发现为未来机制研究和药物开发提供了新的方向。研究人员还特别强调,疾病相关蛋白与药物使用、社会经济状态以及生活方式之间存在复杂联系,这进一步说明疾病风险并不仅仅由遗传因素决定,而是受到环境与社会因素的共同影响。
尽管研究规模巨大,但研究人员也指出了一些限制,例如仅使用血浆样本、缺乏纵向组学数据、未纳入更多组学类型以及部分疾病定义依赖医院记录等。未来如果能够结合基因组、表观组以及纵向动态组学数据,或许能够进一步提高疾病预测能力,并更加深入地理解疾病发生发展的分子机制。
整理 | DrugOne团队
参考资料
Du, J., Zhou, M., Wang, H. et al. Multi-omics integration predicts the incidence of 17 diseases in the UK Biobank. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-73017-z

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢