
点击蓝字
关注我们

编者按:本文根据美国乔治城大学安全与新兴技术中心(CSET)研究员Andrew J. Lohn于2026年5月发布的报告《Beyond P(doom) for AI Risk: Quantifying Uncertainty Without Probability》编译。原报告旨在探讨AI灭绝风险评估中概率估计的局限性,介绍一系列替代工具和方法。本文保持中立视角,按原文结构呈现其核心观点与政策含义。
导语: 当前关于AI造成灾难性风险的预估差异极大,部分原因在于缺乏可靠数据,专家们往往只能依赖主观猜测给出“末日概率”(p-doom)。Lohn 研究认为,决策者不应仅仅询问这种概率值,而应提出更多元化的问题和工具来处理不确定性。报告强调,通过引入信心三元组(Belief、Plausibility、Ignorance)等概念,分析者可以更直接地考察证据支持程度与未知程度,并在整合多名专家意见时避免盲目求同。文末作者建议在AI风险分析中额外提问“您有多确定风险会/不会发生”,以迫使分析者正视主观不确定性并丰富评估手段。
研究发现,对AI灭绝风险的概率评估存在极大分歧(例如一项研究中,持怀疑态度的专家与担忧态度的专家给出灭绝概率分别为0.001和0.25,相差250倍)。

1
引言:概率评估的分歧与不确定性
报告一开始指出,专家、政策者和公众对AI可能引发的生存风险看法悬殊。一项研究中,“怀疑派”和“担忧派”分别给出的AI灭绝概率差距竟高达250倍(约0.001对比0.25),甚至同一群体内部也可能出现剧烈波动。这表明仅用单一概率来表达风险会掩盖许多重要信息。Lohn强调,AI带来的存在性风险在可预见的未来主要是认识论的不确定性(源于知识缺乏),而非事件本身的随机性(aleatoric)。换言之,与其问“结果的随机概率是多少”,不如直接探询专家对某一结果发生或不发生的确定度或证据强度。
2
概率并非唯一选项:引入信度与不确定性
作者提出,政策制定者在评估AI风险时,只需额外询问两个问题,就能大大改善评估质量。第一个是“您对该风险会发生有多大的确定性?”(或“支持这一结果的证据有多强?”),第二个是“您对该风险不会发生有多大的确定性?”(或“反对这一结果的证据有多强?”)。这两个问题迫使分析师直接面对不确定性来源,扩充分析工具箱。报告指出,专家主观评估下,决策者和风险分析师不应仅限于使用概率评估,还可以采取额外工具来处理AI风险中的不确定性。
报告用一个掷骰子例子来说明差异:假设你面对一个六面骰,只看见三面(1面刻星星、2面空白、其余3面未知),那么随机性和未知性混合存在。与其问“掷出星星的概率”,更有价值的问题可能是“在你所掌握的信息下,您有多确定会掷出星星?”和“您有多确定不会掷出星星?”。这体现了区分”事件发生的可能性 (probability)与证据支持度 (Belief/Plausibility)“的重要性。
3
信心三元组:Belief、Plausibility与Ignorance
为更清晰地分解专家估计中的不确定性,Lohn引入了Dempster–Shafer理论中的信心三元组概念。一个三元组由Belief(相信度)、Plausibility(可能度)和Ignorance(无知度)组成,三者之和为1。概率可以理解为Belief和Plausibility之间的比值:(p = Belief/(Belief + Negation))。与简单概率不同,三元组提供了关于证据支持和未知程度的详细信息。
例如,报告中提到一个研究里专家对AI灭绝风险估计为0.25。这个0.25可以对应多种不同的三元组组合:比如[Belief, Plausibility, Ignorance] = [0.25, 0.25, 0.50],表示专家认为证据不足,只知道0.25的相信度;也可能是[0.001, 0.997, 0.002],表示几乎不确信灭绝会发生但也几乎不确信不会发生(极高的无知)。这些解读含义截然不同。报告强调,对概率0.25的灭绝风险,可能有多个不同的信心三元组解释,例如[0.25,0.75,0]或[0.001,0.003,0.996],分别反映了不同的置信度和未知程度。因此,决策者应当向专家额外询问“Belief”和“Ignorance”的信息,才能准确理解他们的真实意图。
4
专家分歧的根源:忽视还是相信?
在讨论专家评估差异时,Lohn指出,不同群体之间往往对“证据支持”和“证据反对”持不同看法。在缺乏额外提问的情况下,分析师可能会误以为分歧出在是否会发生灾难上;实际上,分歧更常发生在对“灾难不会发生”的证据量和专家的知识空缺程度上。报告举例说明,在那项研究中,即便两组专家的Belief数值相同,概率估计却差距悬殊,是因为“怀疑派”和“担忧派”对反对灭绝的证据和未知度存在巨大不同。这意味着,如果不同时询问不确定性,政策分析可能会忽视真正的分歧点,误判风险评估的含义。
在没有明确询问专家不确定性的情况下,分析者可能会误以为专家们在“灭绝是否会发生”的判断上存在分歧,而实际上真正的分歧可能在于反对灭绝的证据量和专家的知识缺失程度。
5
证据的整合:不同组合规则的效果
报告还讨论了如何将多名专家的评估汇总为一致意见。通常有两种目标:一是将新专家的独立信息纳入总体评估,二是对同一证据来源的不同意见寻求一致。在例子中,假设专家A认为灭绝概率15%,专家B认为20%,那么余下的85%和80%可分配给“未知”或“否定”。选择不同的方法会产生不同结果。
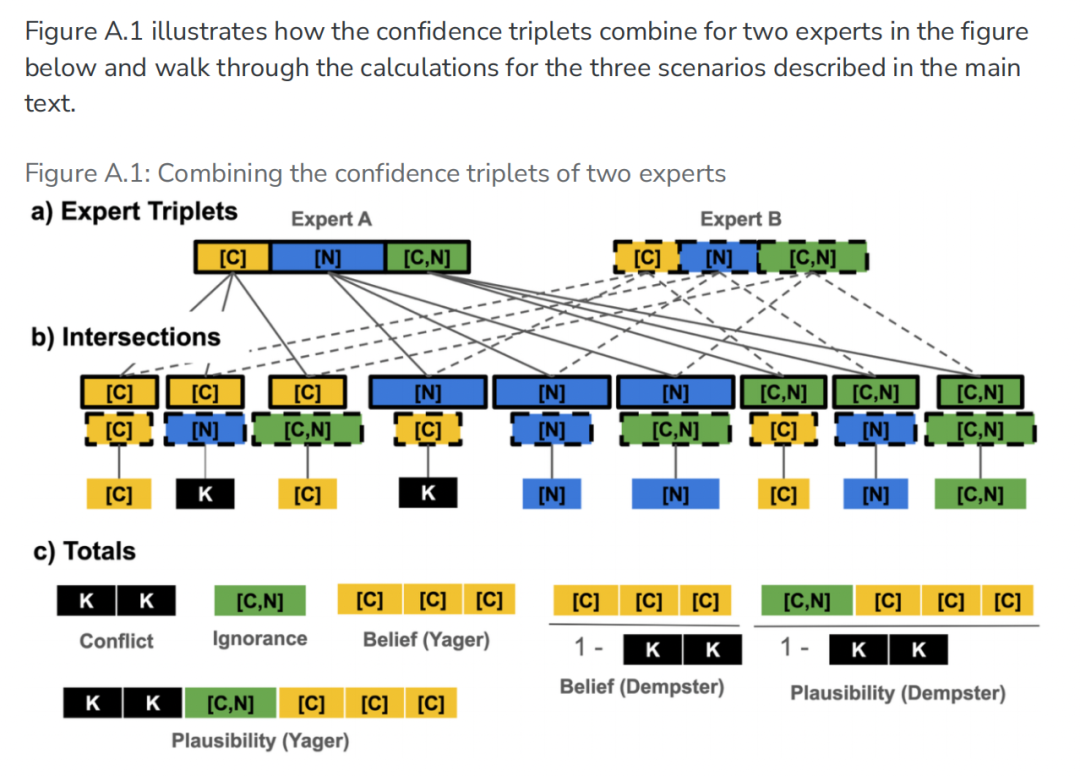
(Figure A.1:两位专家信心三元组的组合示意。该图展示了专家A与专家B的判断如何在 Belief、Plausibility 与 Ignorance 框架下被拆解和重新组合。)
以两位专家都将余量视为“不确定”为例(即Belief分别为0.15和0.20,Plausibility都为0,Ignorance分别为0.85和0.80),报告通过Yager规则和Dempster规则分别计算得出不同的合并信心三元组:
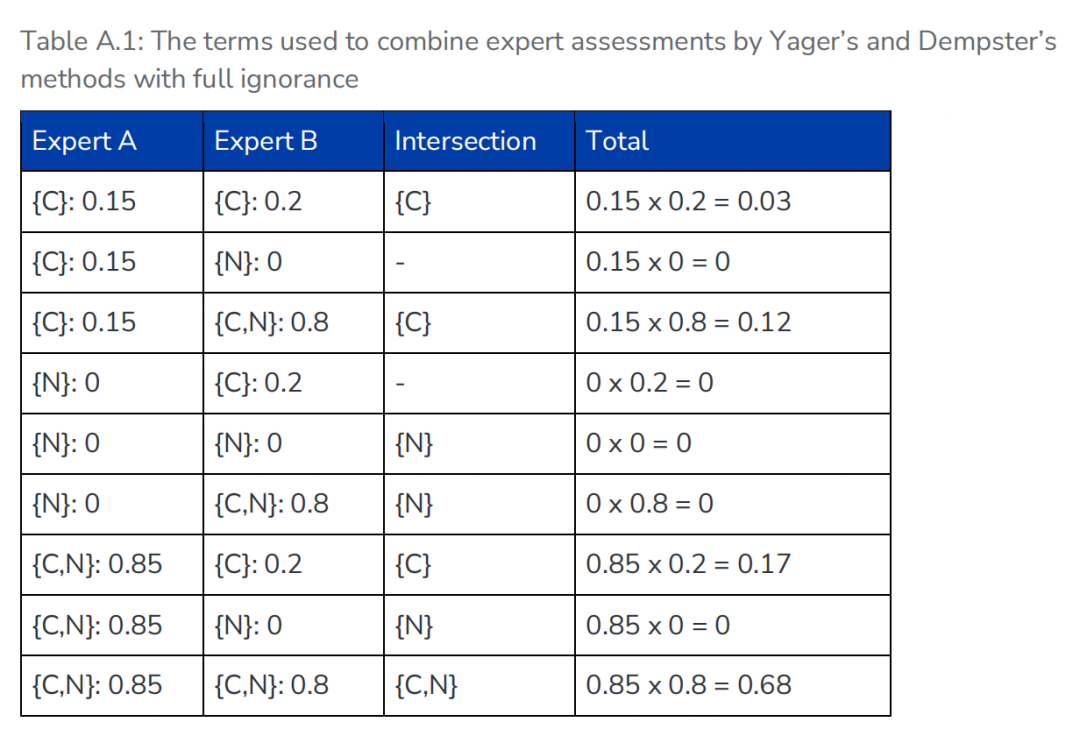
(Table A.1:完全未知情形下的专家评估组合。该表展示了当专家将大量剩余判断保留为 Ignorance 时,Belief 与 Plausibility 如何被计算出来。)
Yager规则:冲突(两者意见完全相反的部分)全部归入Ignorance,结果为[Belief=0.03, Plausibility=0.68, Ignorance=0.29]。
Dempster规则:将冲突按比例分配回Belief和Plausibility,最终无Ignorance,Belief≈0.042, Plausibility≈0.958。
两种方法的差别在于是否“消化”了证据冲突。报告指出,即便在简单示例中,不同的组合规则也会得到截然不同的结果:采用Dempster规则时Belief和Plausibility值相同,而Yager规则则保留了不确定性。
作为对照,报告在附录中还展示了“完全确定”情形下的组合计算:当专家评估不再保留无知项时,冲突会更多地被重新分配,Belief与Plausibility也更接近传统概率推断。
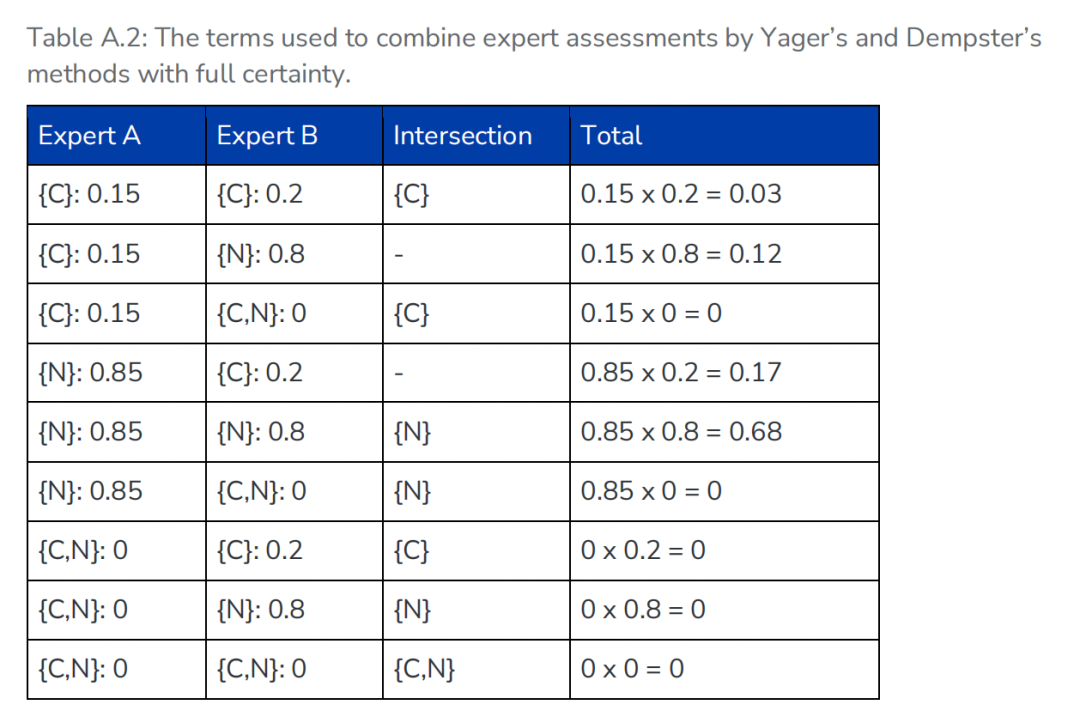
(Table A.2:完全确定情形下的专家评估组合。与完全未知情形相比,该表展示了当 Ignorance 被移除后,冲突如何通过不同规则影响最终 Belief 与 Plausibility。)
示例中,即使只有两名专家,不同的证据组合规则也会得出不同结果:Dempster规则消除了无知(得出Belief≈0.042),而Yager规则则将冲突计入无知(得出Belief=0.03)。
6
未来展望与局限
作者承认,这些证据组合方法并无完美解法,不同方法可能导致“悖论”结果(即看似矛盾的合并结论),这本身是一个缺点。尽管如此,作者认为当前AI风险研究领域对如何处理冲突证据的探讨仍严重不足,而Belief和Plausibility等工具恰好提供了这样的探索途径。正如批评者Pearl所言,Belief和Plausibility“为描述所收集的证据提供了丰富的语言”,即使其批评者也认可这一点。Lohn建议学界应继续在实践中尝试这些非概率的方法,以便在面对高不确定性时获得更全面的分析视角。
Belief和Plausibility提供了一种描述所收集证据的丰富语言,即使连它们的批评者也认可它们的价值。
7
结论:扩展风险评估问法
报告最后总结道,AI风险评估不应仅仅追问“灾难发生的概率是多少?”,而应额外问:“您有多确定该风险会发生?”和“您有多确定该风险不会发生?”这两个问题将迫使政策者、专家和分析师直接面对知识的缺口,不再把主观不确定性与随机性混为一谈。加入这两个简单问题的负担很小,因为Belief/Plausibility等概念和计算方法本就存在并逐步为相关领域所熟悉。作者希望未来的风险讨论能够更多选择最适合当前问题的工具,而不是因缺乏对非概率方法的了解而仅仅使用概率估计。这个改变不会立刻消除所有不确定性,但能帮助风险分析更加透明、周全且富有谦卑。
我们建议继续询问风险发生的概率,同时额外提出两个问题:‘你有多确定该风险会发生?’和‘你有多确定该风险不会发生?’,以此迫使专家更直接地面对知识的不确定性并拓展他们的分析工具箱。
编辑|徐赫泽
审核|赵杨博
终审|梁正 王净宇





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢