
DRUGONE
近年来,大语言模型(LLMs)在自然语言处理领域取得突破性进展,但其在分子生成与药物发现中的能力仍然有限。传统化学语言模型(CLMs)通常需要从头使用大量化学数据训练,而尚未有研究证明通用大语言模型能够直接转化为高性能化学生成模型。该研究提出了SmileyLlama,一种基于Meta-Llama-3.1-8B-Instruct构建的化学空间探索模型。研究人员通过监督微调(SFT)和直接偏好优化(DPO),使Llama能够直接生成满足特定药物化学性质的SMILES分子。研究结果显示,SmileyLlama不仅能够生成高有效性、高新颖性和高多样性的药物样分子,还能够根据自然语言提示定向探索特定化学空间,例如生成满足Lipinski规则、特定骨架或共价战头结构的分子。进一步地,研究人员将SmileyLlama整合进iMiner强化学习框架,实现针对SARS-CoV-2主蛋白酶(MPro)的结构优化与高亲和力分子设计。研究表明,通用LLM可以通过轻量级微调快速转化为高性能化学生成模型,并保留部分自然语言能力,为未来AI驱动药物发现与材料设计提供了新范式。

化学语言模型近年来已成为分子生成领域的重要工具。研究人员通常使用SMILES或SELFIES等字符串表示分子,并通过深度学习模型学习化学结构分布,从而实现新分子的生成。此前已有大量研究采用VAE、RNN、GPT以及S4等模型架构训练专用化学语言模型,并在药物发现中展现出巨大潜力。
与此同时,大语言模型的发展彻底改变了自然语言处理领域。GPT-4、Llama等LLM在语言理解、推理与生成方面展现出强大能力。近年来,研究人员开始尝试将LLM应用于科学研究,例如辅助实验设计、化学语言翻译以及自动科研代理等方向。然而,大多数LLM在化学领域仍然主要充当“知识助手”,而不是能够真正生成和优化分子的模型。
此前也有研究尝试利用LLM修改SMILES字符串或结合进化算法探索化学空间,但这些方法大多仍依赖专门训练的化学模型。研究人员指出,目前尚未有研究证明,一个预训练通用LLM能够通过轻量级微调直接达到现代化学语言模型的性能。
因此,研究人员提出SmileyLlama,希望利用监督微调和偏好优化,将Llama转化为能够直接“说化学语言”的模型,并进一步探索其在药物发现与定向化学空间搜索中的能力。
方法
研究人员首先选取约200万个来自ChEMBL数据库的药物样分子,并利用RDKit计算其药物化学相关性质,包括氢键供体/受体数量、分子量、logP、TPSA、sp3碳比例、可旋转键数量、宏环结构、共价战头SMARTS模式以及特定子结构等。随后,研究人员将这些性质组织为自然语言提示(prompt),并将对应SMILES作为模型目标输出,对Llama进行监督微调。
在监督微调后,研究人员进一步使用Direct Preference Optimization(DPO)优化模型。具体而言,模型会根据给定性质生成多个SMILES字符串,再利用RDKit评估这些分子是否满足提示要求。满足条件的分子被标记为“赢家(winner)”,不满足条件的则作为“输家(loser)”,模型随后通过DPO强化对优质输出的偏好。
研究人员还将SmileyLlama整合至iMiner强化学习框架中,并结合AutoDock Vina实时分子对接,实现针对SARS-CoV-2 MPro的三维结构优化与高结合亲和力分子生成。
结果
SmileyLlama成功将通用LLM转化为化学生成模型
研究人员首先评估了SmileyLlama生成药物样分子的能力,并使用GuacaMol benchmark进行系统测试。结果显示,未经训练的Llama在零样本条件下仅能生成68.8%的有效SMILES,并且分子多样性与稳定性较差。即使提供20个SMILES示例,其有效性仍下降至46.5%。
相比之下,经过监督微调后的SmileyLlama有效率达到95.8%,新颖性达到98.7%,整体性能已经接近甚至超过许多经典化学语言模型,例如GPT-based CLM与S4模型。
研究人员进一步通过UMAP分析发现,SmileyLlama生成的分子能够覆盖ChEMBL训练数据中的主要化学空间区域,并在分子量、氢键供受体、TPSA、QED等多个药物化学性质上与真实药物分布高度一致。
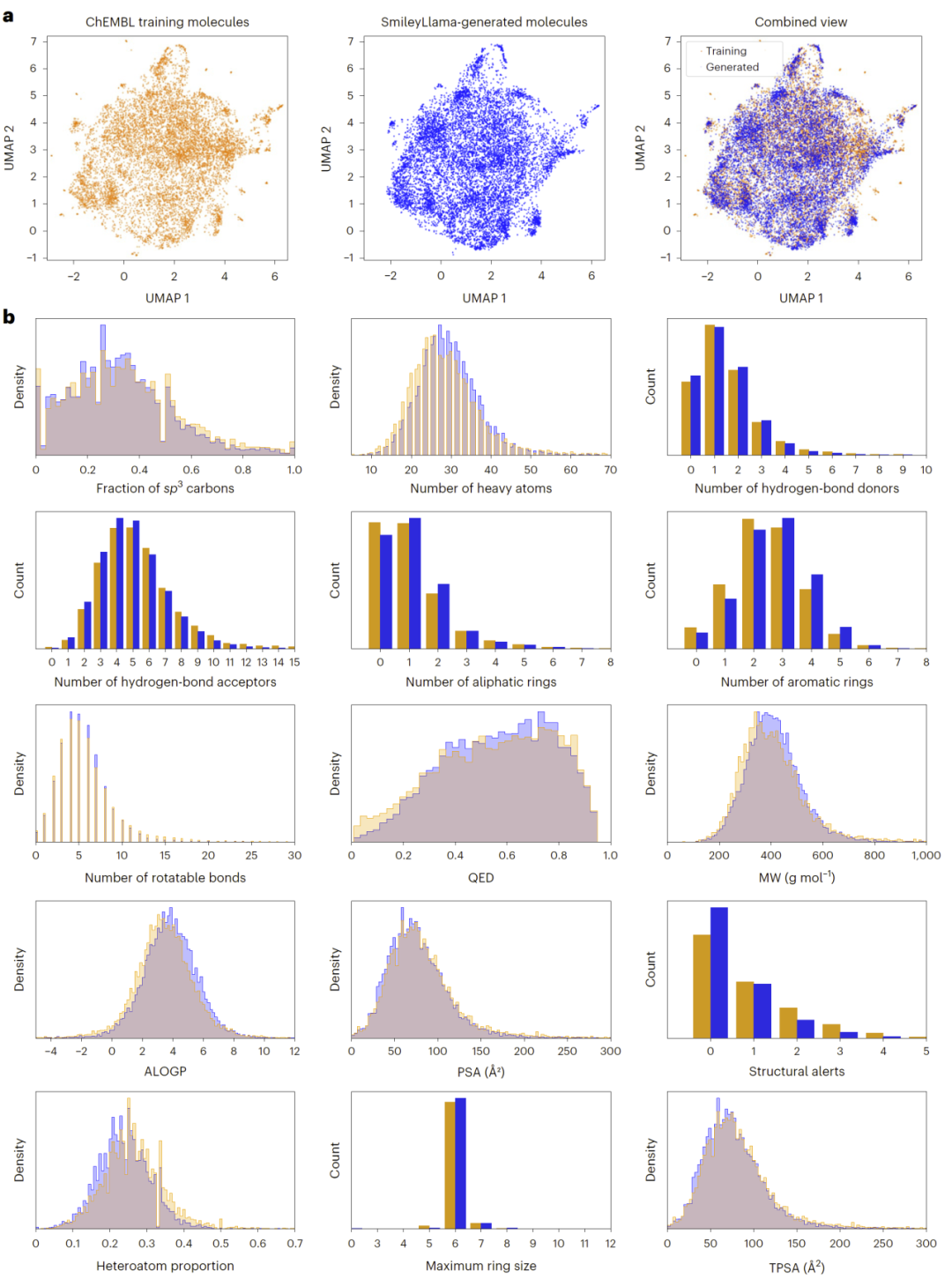
图1:SmileyLlama生成分子与ChEMBL训练分子的化学空间与性质分布比较。
SmileyLlama能够根据自然语言定向生成分子
研究人员随后测试了SmileyLlama根据提示生成特定性质分子的能力。结果显示,SmileyLlama能够高精度生成满足氢键供体数量、分子量、logP、TPSA以及Lipinski rule-of-five等条件的分子。
例如,在“分子量≤500”“logP≤5”等经典药物化学约束下,SmileyLlama能够以接近90%以上准确率生成符合要求的分子。模型还能够执行更加复杂的组合任务,例如“包含指定Enamine子结构并满足Lipinski规则”的分子设计,实现类似scaffold hopping与片段扩展的能力。
研究人员特别进行了“prompt ablation”实验,即移除所有性质提示,仅保留统一SMILES生成任务。结果发现模型性能显著下降,尤其在宏环、共价战头等稀有性质上几乎完全失效。这表明自然语言提示工程在SmileyLlama中具有核心作用,而不能仅依赖LLM自身知识。
DPO显著增强模型对提示的遵循能力
研究人员进一步利用DPO强化模型输出。结果显示,DPO几乎在所有性质生成任务上均进一步提升了性能。
例如,在Lipinski rule-of-five任务中,SFT模型准确率约为81–89%,而经过DPO后提升至97–99%。在宏环和共价战头等复杂任务中,DPO同样带来明显提升。
研究人员发现,DPO能够显著提高模型对提示约束的服从性,但也会缩窄生成分子的性质分布与多样性。因此,研究人员认为SFT更适合早期化学空间探索,而DPO更适合后期约束优化。
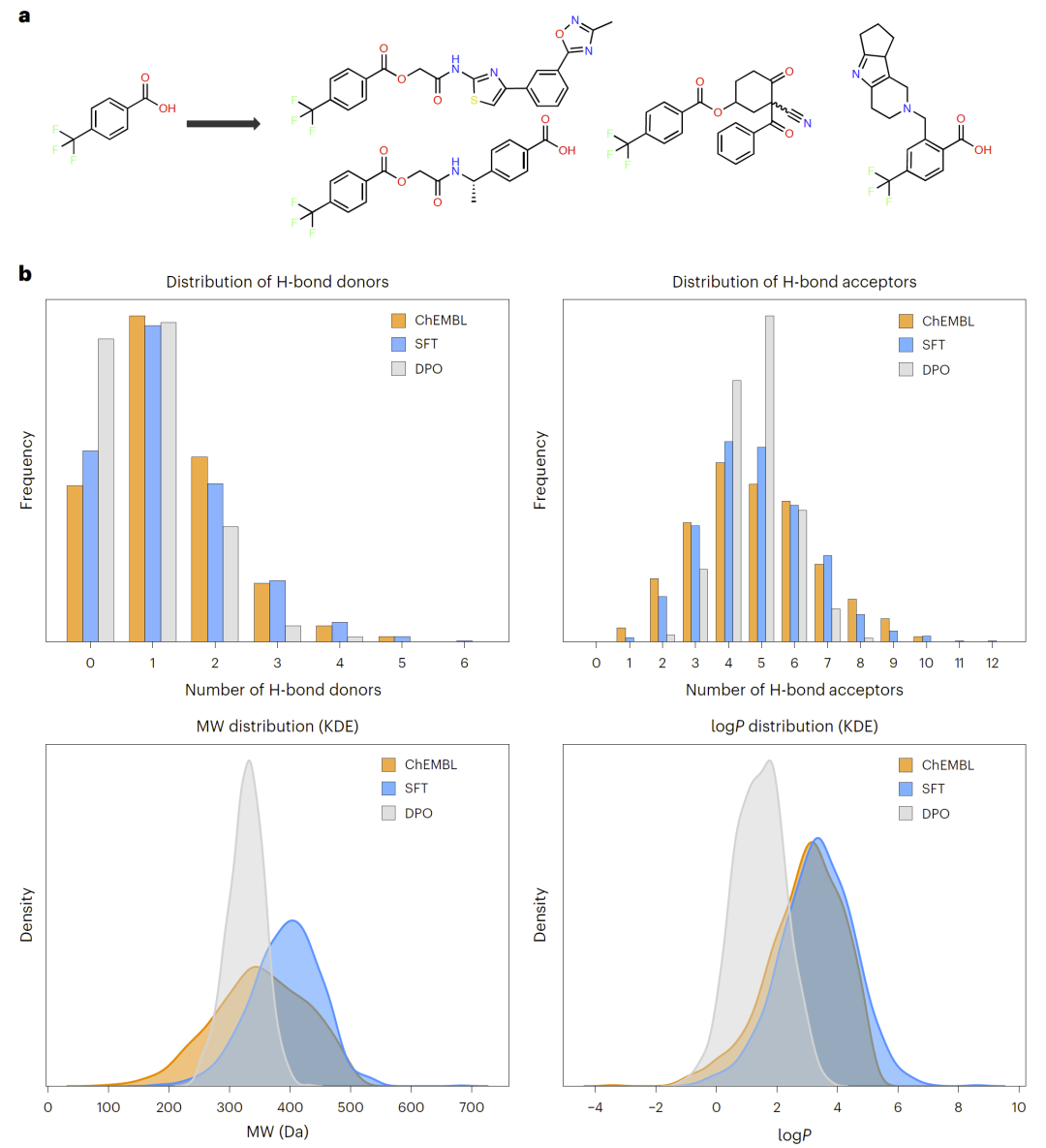
图2:SmileyLlama在SFT与DPO下的性质控制能力比较。
SmileyLlama能够结合强化学习进行结构导向药物设计
研究人员进一步将SmileyLlama与iMiner强化学习框架结合,用于针对SARS-CoV-2 MPro的分子优化。结果显示,SmileyLlama相比原始iMiner具有更高的数据效率,仅需约25%的训练迭代即可达到相似甚至更优的对接分数。
更重要的是,传统iMiner在后期优化过程中会出现“多样性崩塌”,即大量生成高度相似分子,而SmileyLlama则始终保持较高化学多样性。
研究人员还发现,仅通过自然语言prompt即可调整生成分子的药物样性质。例如,在加入“≤500 MW”“≤5 logP”等约束后,模型生成分子的药物相容性明显提升,而无需重新训练模型。
进一步结构分析显示,SmileyLlama生成的多个分子能够稳定结合于MPro活性口袋,并形成合理氢键网络。部分高评分分子甚至展现出此前未见于数据库的新型骨架结构,说明模型并非简单记忆训练集,而是真正具备化学创新能力。
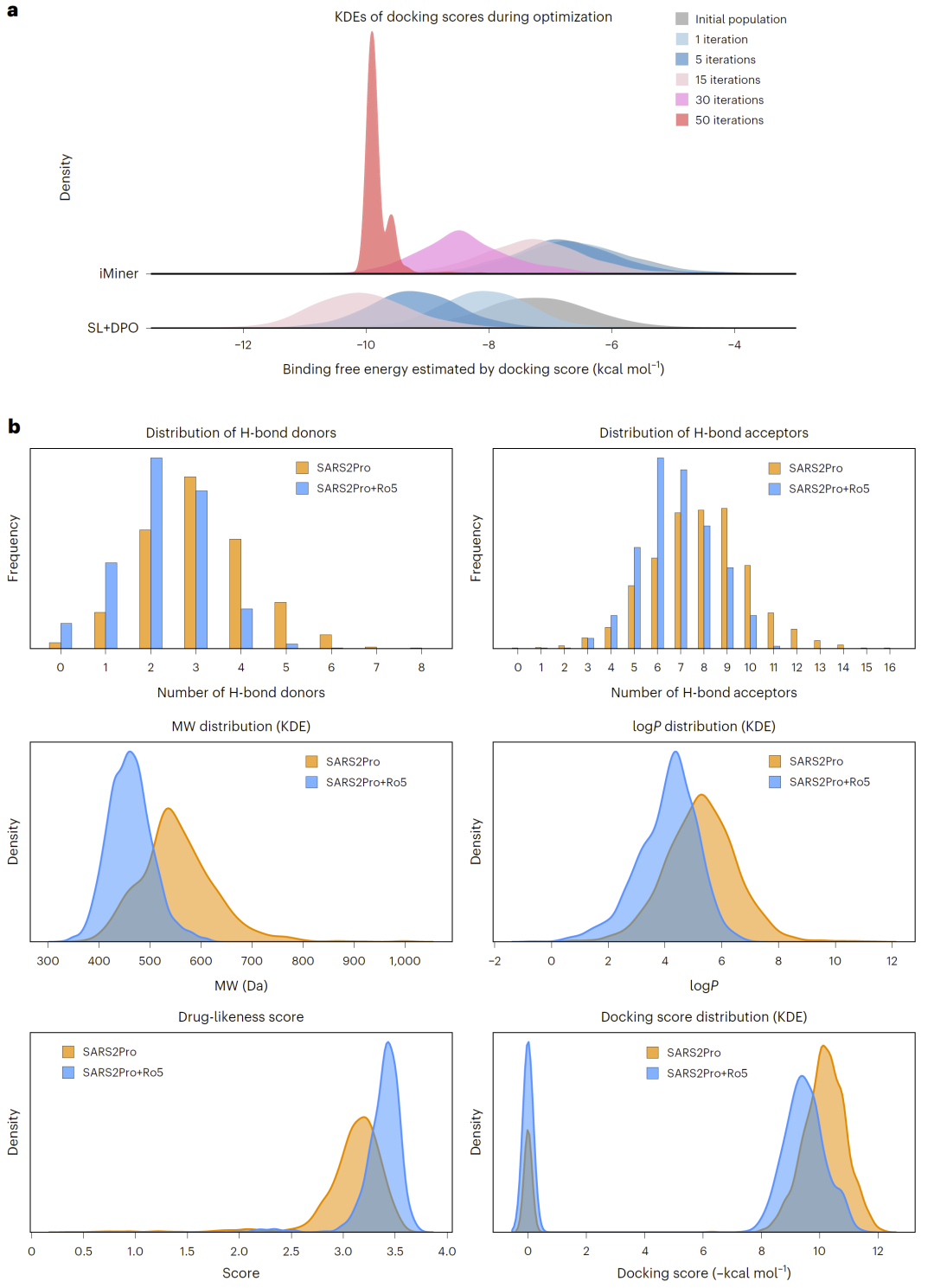
图3:SmileyLlama生成的SARS-CoV-2 MPro抑制剂及其结合模式。
讨论
该研究首次证明,通用大语言模型可以通过轻量级监督微调与偏好优化,被转化为高性能化学语言模型,而无需从头进行大规模化学预训练。研究人员指出,这种方法相比传统CLM训练大幅降低了资源需求,同时继承了LLM的自然语言能力。
研究还表明,自然语言prompt本身可以作为一种“化学空间导航器”,使研究人员无需修改模型权重,即可动态调整生成分子的性质与探索方向。这种能力在药物发现中尤其重要,因为药物设计本质上是一个多目标优化问题。
然而,研究人员也指出了一些限制。例如,DPO虽然提高了提示遵循能力,但会降低分子多样性;SmileyLlama在宏环等低数据任务上仍然表现较弱;此外,当前模型尚未显式优化脱靶效应、代谢稳定性与抗突变能力等更复杂药物性质。
研究人员认为,SmileyLlama不仅适用于药物发现,还可能扩展至材料设计、过渡金属配合物生成以及化学合成规划等更广泛领域。总体而言,该研究展示了“LLM+化学语言”融合的新方向,意味着未来大语言模型可能不再只是科研助手,而是真正参与化学空间探索与分子创造的核心系统。
整理 | DrugOne团队
参考资料
Cavanagh, J.M., Sun, K., Gritsevskiy, A. et al. SmileyLlama: modifying large language models for directed chemical space exploration. Nat Comput Sci (2026).
https://doi.org/10.1038/s43588-026-00986-y

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢