

基于流(Flow)的视觉-语言-动作(VLA)策略在动作生成方面具有强大的表达能力,但存在一个根本性的低效问题:需要多步推理才能从无信息的高斯噪声中恢复动作结构,导致在实时约束下效率与质量之间难以平衡。我们通过重新思考生成动作建模中起点的角色来解决这一问题。我们没有缩短采样轨迹,而是提出了 CF-VLA,这是一种由粗到细的两阶段公式,将动作生成重构为一个粗略初始化步骤,该步骤构建一个动作感知的起点,随后是一个单步局部细化步骤,用于纠正残差误差。具体来说,粗略阶段学习一个关于终点速度的条件后验,将高斯噪声转换为结构化的初始化,而精细阶段从这个初始化进行固定时间的细化。为了稳定训练,我们引入了一种逐步策略,首先学习一个受控的粗略预测器,然后进行联合优化。 在 CALVIN 和 LIBERO 上的实验表明,我们的方法在低 NFE(函数评估次数)条件下建立了高效的性能边界:它始终优于现有的 NFE=2 方法,在多个指标上与 NFE=10 基线持平或超越,将动作采样延迟降低了 75.4%,并实现了 83.0%的平均真实机器人成功率,比 MIP 高 19.5 分,比 高 4.0 分。这些结果表明,结构化的由粗到精生成方法既保证了高性能,又实现了高效的推理。

论文:CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
单位:南科大、西交、芯联集成、中科大
发布日期:2026年4月
请索引第93篇论文
 |  |
CF-VLA:打破VLA策略效率瓶颈,粗到细动作生成新范式
在机器人操控领域,视觉-语言-动作(Vision-Language-Action, VLA)策略通过结合视觉感知与语言指令,让机器人能够执行复杂的操作任务。然而,基于流匹配(Flow Matching)的VLA策略虽然表达能力强,却存在一个根本性的效率瓶颈:推理时需要从无结构的高斯噪声出发,经过多步迭代才能恢复出有意义的动作结构,这导致在实时约束下效率与质量难以兼得。
今天要解读的这篇论文《CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies》提出了一种全新的粗到细两阶段动作生成框架,将动作生成重新构建为粗初始化与细 refinement 两个明确阶段,在仅需两步推理(NFE=2)的严格预算下,不仅显著降低了计算延迟,更在多项指标上匹配甚至超越了需要10步推理的强基线方法。
01 核心思想:重构起点,而非缩短轨迹
传统流匹配方法(如π₀.₅)的动作生成过程可以类比为“从一团混沌中逐步雕刻出形状”。论文指出,其低效根源在于:早期迭代主要用于将高斯噪声向动作流形进行全局对齐,后期迭代才专注于局部细节修正。当推理步数(NFE)被压缩时,这两个阶段被迫在同一个缩短的轨迹中竞争,导致生成质量下降。
CF-VLA的突破在于转变思路:不再试图缩短采样轨迹,而是直接重构起始点。它将生成过程解耦为两个功能明确的阶段:
粗初始化阶段:学习一个关于端点速度的条件后验分布,将高斯噪声转化为一个偏向动作流形的结构化初始化点(AP-guided initialization)。
细 refinement阶段:从该初始化点出发,仅通过单步局部修正来恢复最终动作。
如图1所示,这种设计用“AP引导初始化 + 局部修正”的两步流水线,替代了传统的“从无结构噪声开始的迭代 refinement”。
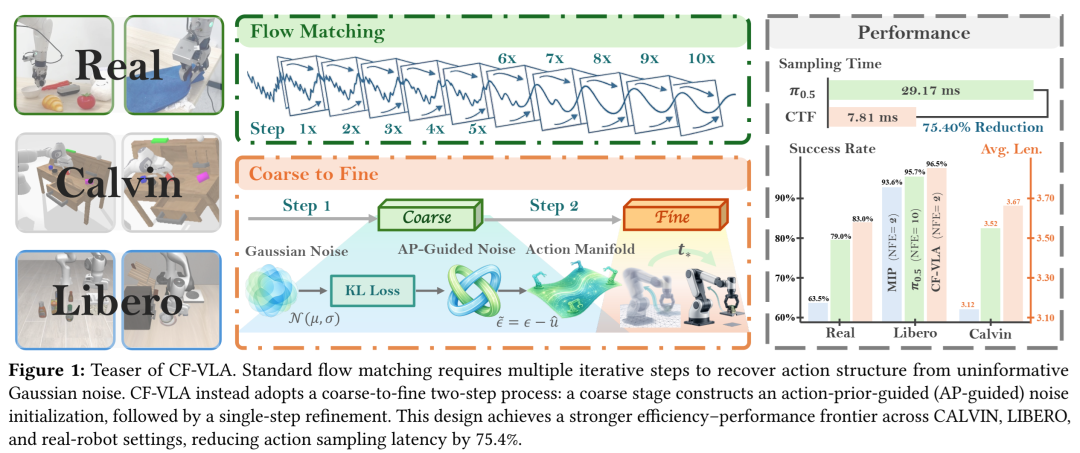
图1:CF-VLA方法概览。该图对比了标准流匹配(FM)与CF-VLA的生成过程。FM需要多步迭代从噪声(左)逐步形成为动作(右),而CF-VLA首先通过粗阶段将噪声转化为一个靠近目标动作流形的初始化点,然后通过细阶段一步修正到位。
02 方法详解:如何实现粗到细生成
1. 端点先验建模(粗阶段)
粗阶段的目标不是预测最终动作,而是塑造初始化点的分布几何。对于每个训练对 (o, a),模型学习一个条件后验分布 qθ(u|o, ε₁),旨在匹配以真实端点速度 u_{t₁} = ε₁ - a 为中心的目标分布。
通过优化KL散度目标 ℒ_coarse,模型学会输出一个随机、任务条件化的初始化分布,其概率质量集中在合理动作附近,而非坍缩为一个确定性估计。最终,AP引导的初始化点定义为 ε̃ = ε₁ - û,其中 û 从后验分布中采样。与纯高斯噪声相比,ε̃ 的均值已向动作流形偏移,为后续 refinement 提供了信息量更大的起点。
2. 局部流形恢复(细阶段)
一旦获得了良好塑造的初始化分布,模型面临的问题发生了根本变化。细阶段不再需要发现全局动作结构,而是在目标流形附近的局部邻域内操作。
因此,refinement 被重新表述为一个局部恢复问题。给定初始化点 ε̃,模型在固定时间 t_f 应用单步更新,通过最小化均方误差损失 ℒ_fine 来学习如何从 ε̃ 恢复出最终动作 a。
3. 分步训练策略:先稳定,后联合
粗到细的框架引入了一种不对称依赖:细阶段的有效性依赖于粗初始化的质量。直接联合优化可能不稳定。
为此,论文提出了一个两阶段训练策略(如算法1所示):
阶段一(稳定化):首先在受控监督下训练端点表示,同时让 refinement 分支接触一个通过噪声与真实动作插值构建的稳定代理分布。此阶段尚未实现完整的粗到细机制,但确保了两个分支都在条件良好的输入上运行。
阶段二(联合优化):当粗输出变得足够结构化后,切换到完整目标。此时 refinement 分支接收由学习到的粗后验生成的输入,联合优化学习分布塑造与局部恢复如何相互增强。
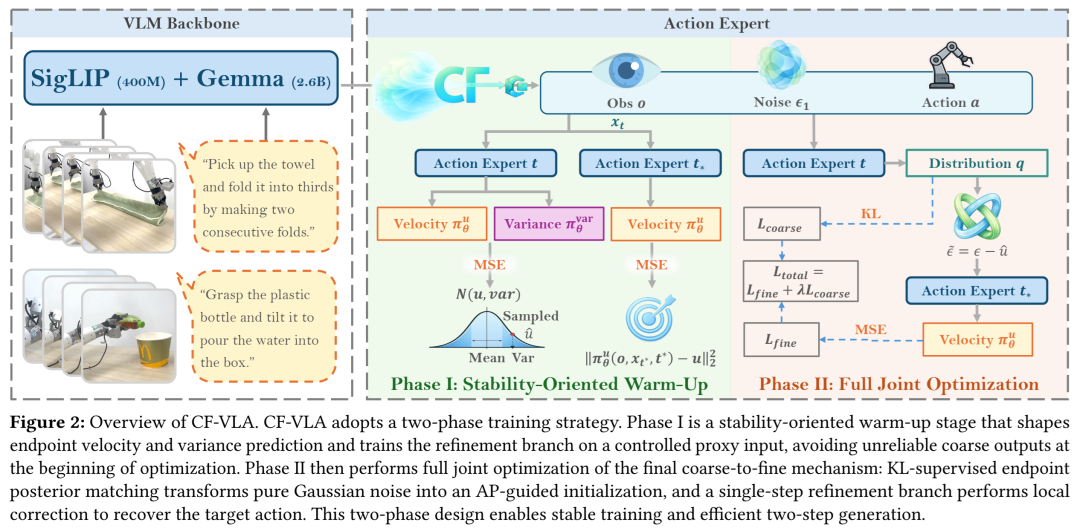
图2:CF-VLA训练与推理流程。该图展示了CF-VLA的两阶段训练流程(Phase I & II)以及简洁的两步推理路径。推理时,高斯噪声先通过后验采样转化为AP引导的初始化,再经过一次 refinement 更新即产生最终动作。
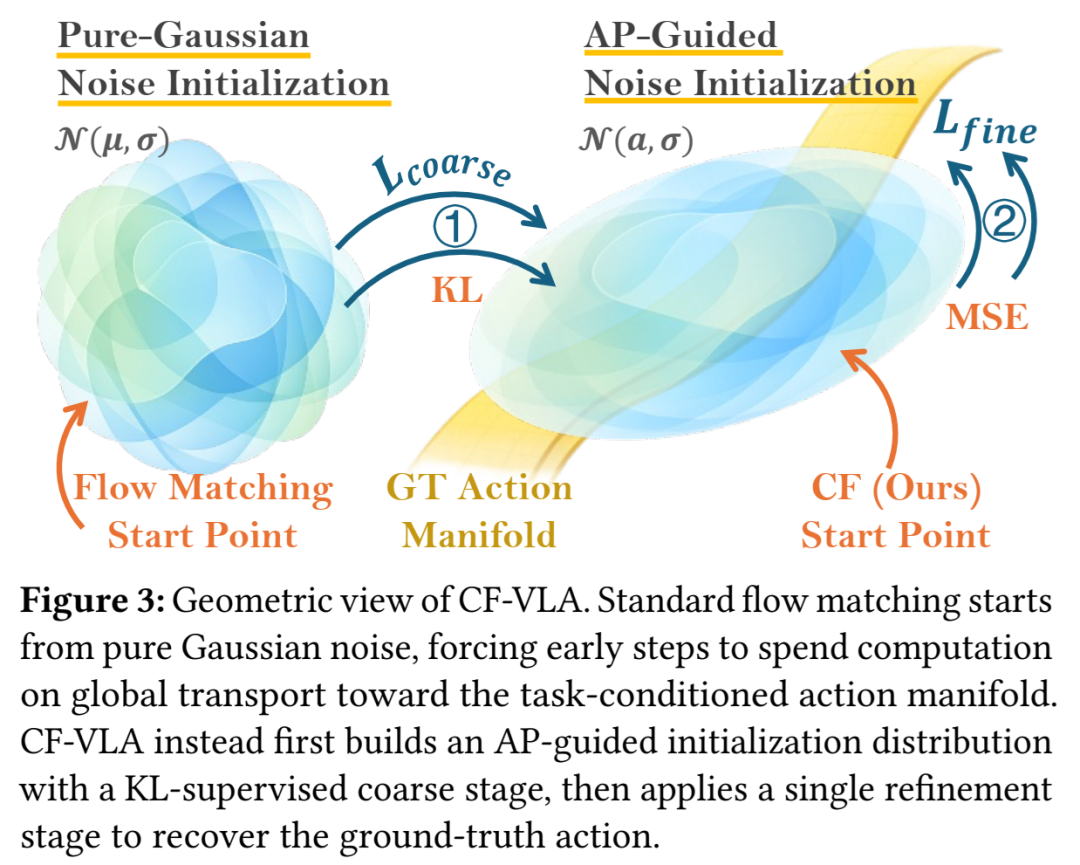
图3:标准FM与CF-VLA的轨迹对比。该图通过可视化对比了标准流匹配与CF-VLA在动作生成轨迹上的差异。CF-VLA的初始化点(橙色)更靠近目标动作流形,因此其 refinement 轨迹(红色)更短、更直接,而标准FM需要更长的轨迹从噪声(蓝色)开始探索。
03 实验结果:效率与性能的双重突破
论文在LIBERO和CALVIN两个具身AI基准上进行了全面评估,并从仿真任务成功率、推理效率和真实机器人泛化能力三个维度验证了CF-VLA的有效性。
1. 仿真性能:低NFE下的新标杆
在LIBERO基准上,CF-VLA在仅使用2步推理(NFE=2) 的情况下,取得了平均96.5% 的成功率。如表1所示,它不仅显著超越了其他NFE=2的方法(如MIP和π₅),其性能甚至与许多需要8步或10步推理的先进方法(如π₀.₅、Flower VLA、MemoryVLA等)持平或更优,在“空间”、“物体”、“目标”三个任务类型上均表现优异。
表1:LIBERO仿真任务性能对比,CF-VLA在NFE=2的设定下达到了与更高NFE方法相媲美的性能。
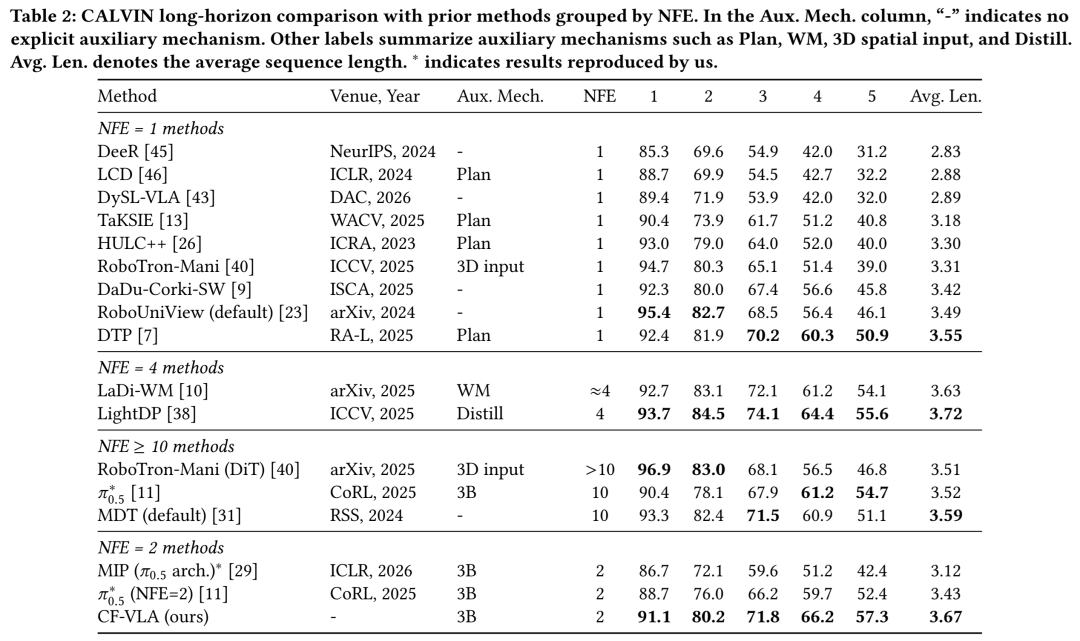
在CALVIN基准的D→D长时任务协议下,CF-VLA同样展现出了强大的竞争力。
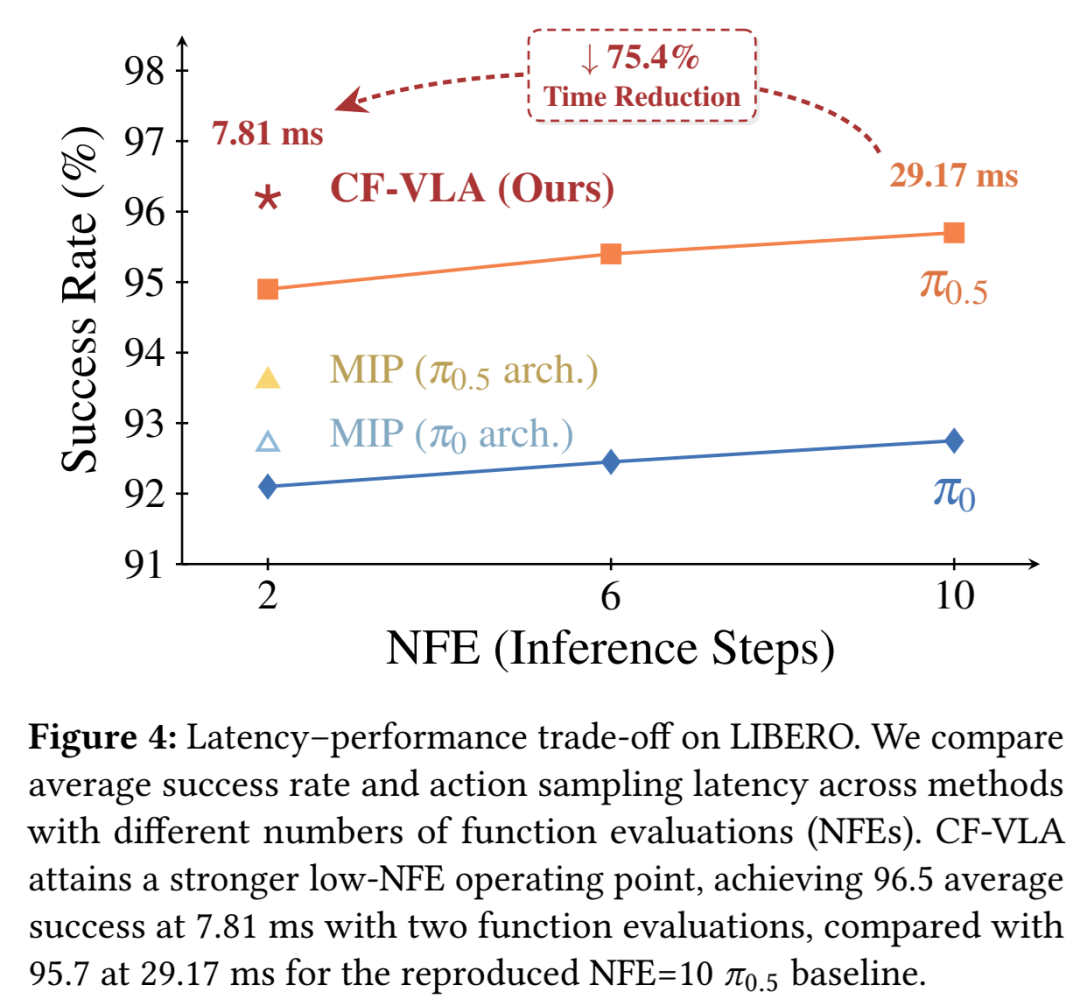
2. 推理效率:延迟大幅降低
效率提升是CF-VLA的核心优势之一。实验表明,与需要10步推理的π₀.₅基线相比,CF-VLA将动作采样延迟降低了75.4%。这对于需要高频闭环控制的实时机器人应用至关重要。
3. 真实机器人验证:泛化能力卓越
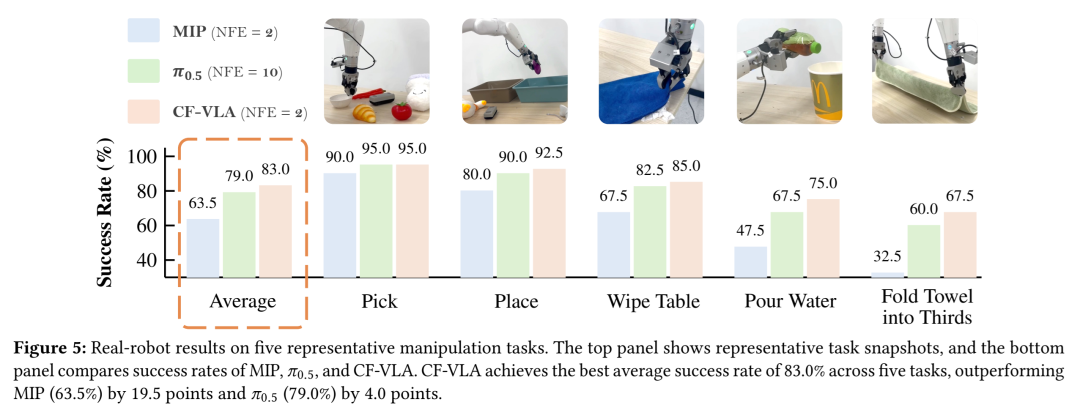
在真实机器人操控实验中,CF-VLA取得了平均83.0%的成功率,显著优于MIP(高出19.5个百分点)和π₀.₅基线(高出4.0个百分点)。特别是在接触密集型和双手操作任务上,CF-VLA表现出了额外的优势,证明了其生成动作的精确性和鲁棒性。
04 总结与展望
CF-VLA通过将动作生成明确分解为全局对齐和局部修正两个阶段,巧妙地解决了流匹配VLA策略在低推理预算下的效率瓶颈。其核心贡献在于:
一个即插即用的粗到细两阶段VLA框架,可无缝应用于任意基于流的VLA策略。
一种方差感知的端点分布公式,能将高斯噪声转化为更接近有效动作流形的初始化点。
一种分步训练策略,稳定了跨阶段耦合,实现了高效的低步数生成。
这项工作表明,对于基于流的策略,效率瓶颈在于起始点的结构,而非采样轨迹的长度。CF-VLA为在资源受限的边缘设备上部署高性能VLA策略开辟了新的可能性,是迈向高效、实用具身智能的重要一步。
延伸思考:CF-VLA的“粗-细”思想是否可以迁移到其他生成式模型(如图像、视频生成)中以提升推理效率?其分步训练策略对于训练其他具有复杂依赖关系的多阶段模型是否有借鉴意义?欢迎在评论区留下你的看法。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢