

长期以来,构建能够在非结构化物理环境中感知、推理和行动的机器人,一直是具身智能(Embodied AI)研究的目标。
尽管视觉-语言-动作(VLA)模型展现出了作为通用具身策略学习范式的潜力,但依然只是“被动学习”,无法预测环境在干预下的未来状态。
在这一背景下,世界动作模型(World Action Models),即“一种统一环境动态建模(世界建模)与动作生成的具身基座模型”,正成为学界、业界的热门研究方向之一。
日前,复旦大学团队及其合作者在一篇最新综述文章中系统梳理了世界动作模型的定义、架构、训练数据、基准、开放挑战和未来机遇。

论文链接:https://arxiv.org/abs/2605.12090
研究团队表示,世界动作模型具备更强的物理理解力、在未知环境中更优的泛化能力,并能够利用大规模缺乏动作标注的人类视频数据,有效扩展具身策略学习的数据基础。
该综述对世界动作模型领域提供了首次系统且批判性的分析,为理解设计空间提供了一个概念框架,并为进入这一快速演进领域的科研人员提供了一份实用指南。
架构
研究团队指出,不同于 VLA 世界模型(WM),世界动作模型需同时具备以下特点:一是能预测世界,二是能让动作对齐预测。世界动作模型既要预测环境的物理演化,也要让生成的动作与预测出的未来状态相匹配。
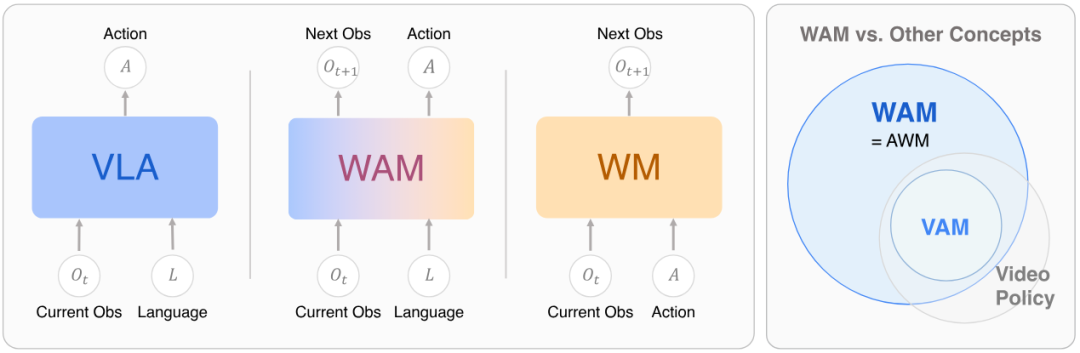
图|VLA、WM 和 WAM 的概念定义与比较。
在架构上,研究团队将现有 WAM 分为两类:级联式 WAM 和联合式 WAM。
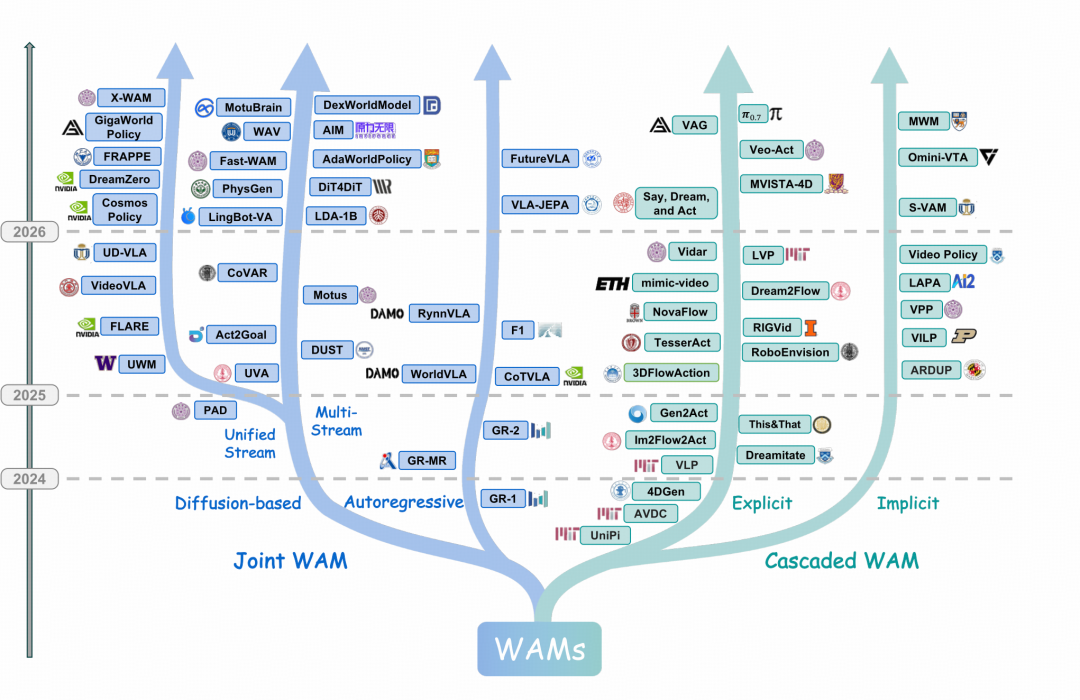
图|代表性世界动作模型的时间演变与分类。
第一类是级联式 WAM。它先由世界模型生成未来状态或视觉计划,再由动作模型从中解码机器人动作。中间规划载体既可以是未来 RGB 帧、光流、深度图等显式视觉结果,也可以是压缩后的潜在表示。显式视觉计划更直观,但还需要通过逆动力学模型、动作模型或几何提取等方式转化为可执行动作;潜在表示则不直接生成完整像素级画面,而是在更紧凑的特征空间承载规划信息,计算开销更低,但可解释性相对较弱。
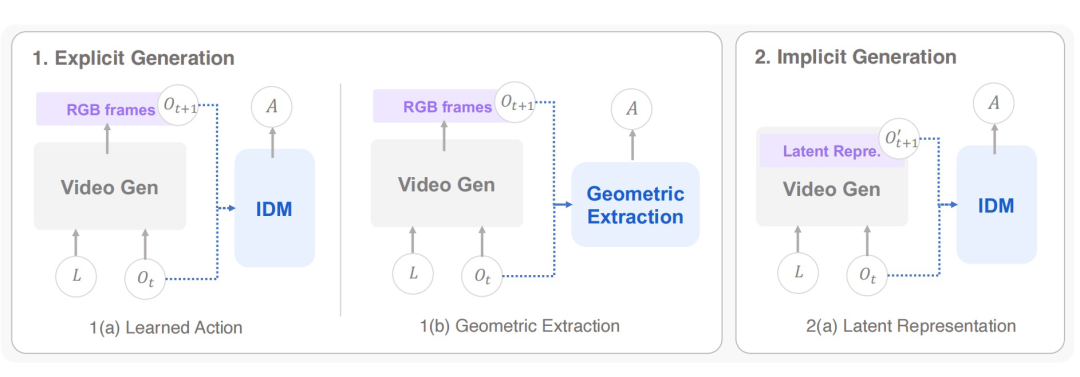
图|级联式 WAM 结构的示意性比较。
第二类是联合式 WAM。它在单一系统中同时预测未来状态和动作,将世界建模和动作生成作为联合监督目标。按生成方式,分为自回归生成和扩散式生成:自回归生成会把未来状态和动作排成序列并逐步预测,扩散式生成则通过扩散或流匹配过程,同时生成未来状态和动作。在基于扩散的联合式 WAM 中,一类是统一流结构,即将世界状态和动作整合进同一个 DiT 骨干网络;另一类是多流结构,让视频生成分支和动作生成分支通过交叉注意力、隐藏状态条件化或共享表示进行耦合。
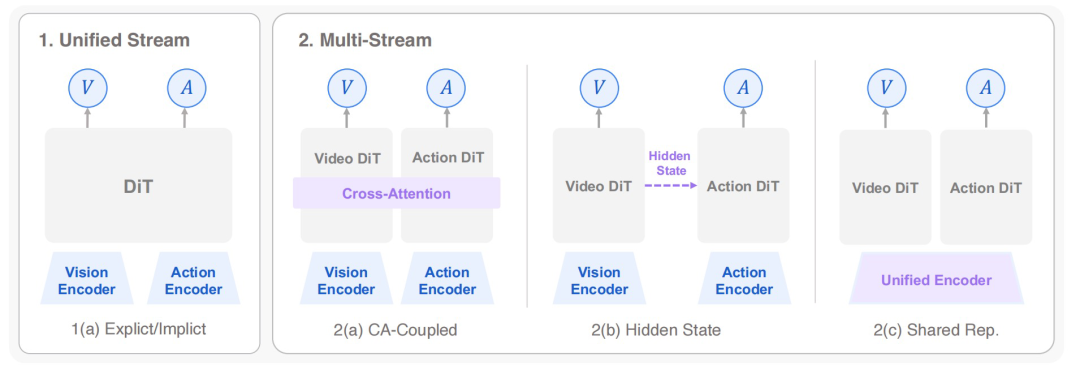
图|基于扩散的联合式 WAM 主要架构模式分类。
训练数据
在训练数据方面,WAM 需要同时学习状态转移、动作条件和直觉物理。传统 VLA 依赖带动作标注的机器人轨迹,规模容易受限;纯世界模型可以利用大规模无动作视频,但缺少对物理控制的 grounding。
因此,WAM 的数据建设不只是扩大机器人数据规模,还需要混合带动作标注的示范数据和大规模无动作观察数据,文中总结了四类主要数据来源。
1.机器人中心遥操作数据。这类数据记录感知观测、本体状态和可执行动作,能提供严格对齐的观测-动作-后续状态轨迹,适合学习精确的动作条件物理动态,但采集成本高,场景也相对有限。
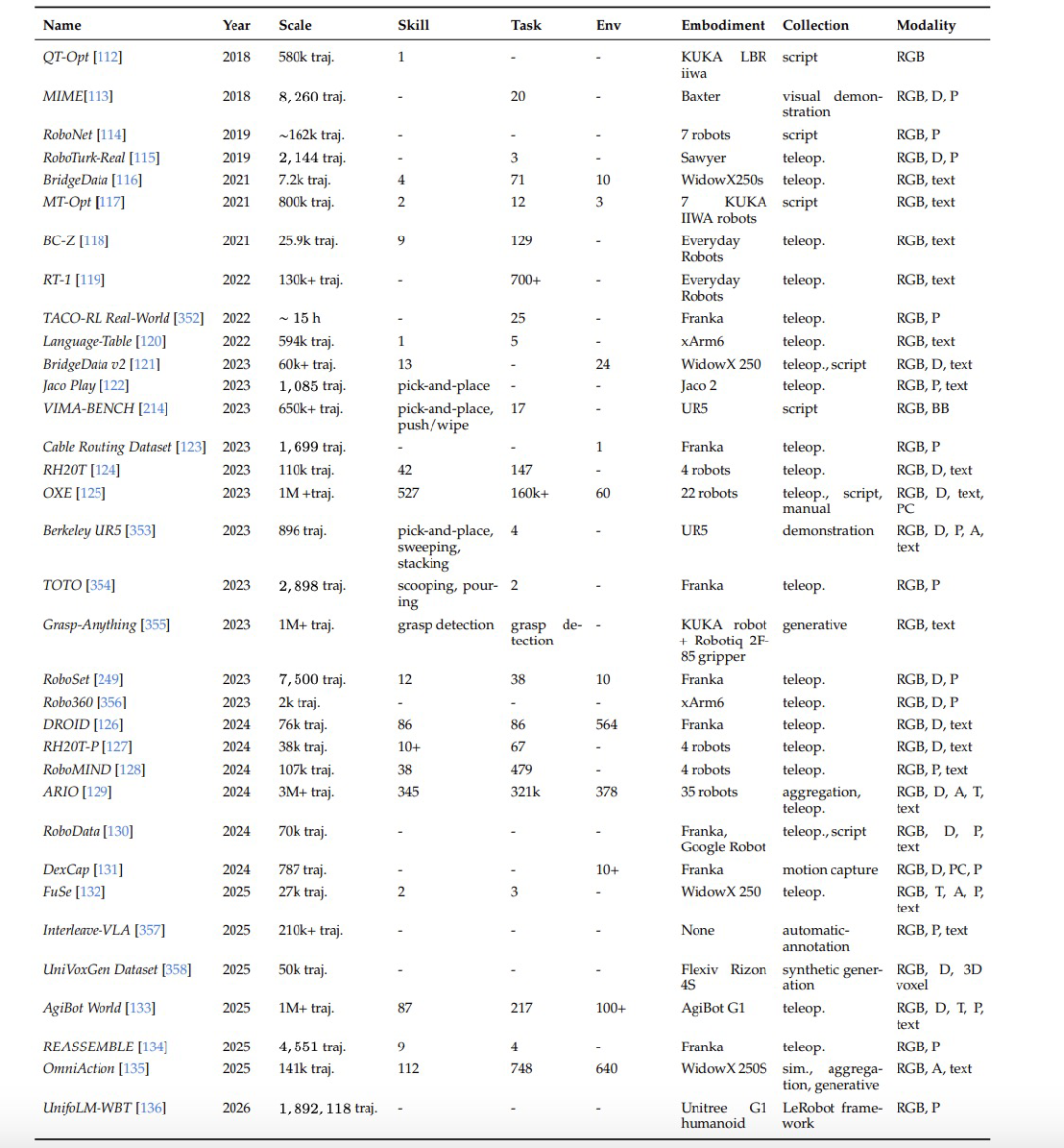
图|以机器人为中心的操作数据集
2.便携式人类示范数据。例如 UMI 使用手持夹爪和可穿戴相机,让非专家在真实日常环境中采集操作轨迹,再通过视觉跟踪和重定向转为机器人可执行动作。
3.仿真数据。仿真可以提供可扩展、可控、确定性的训练数据,也能提供完美深度、精确 6D 物体姿态、碰撞边界和无遮挡多视角状态。
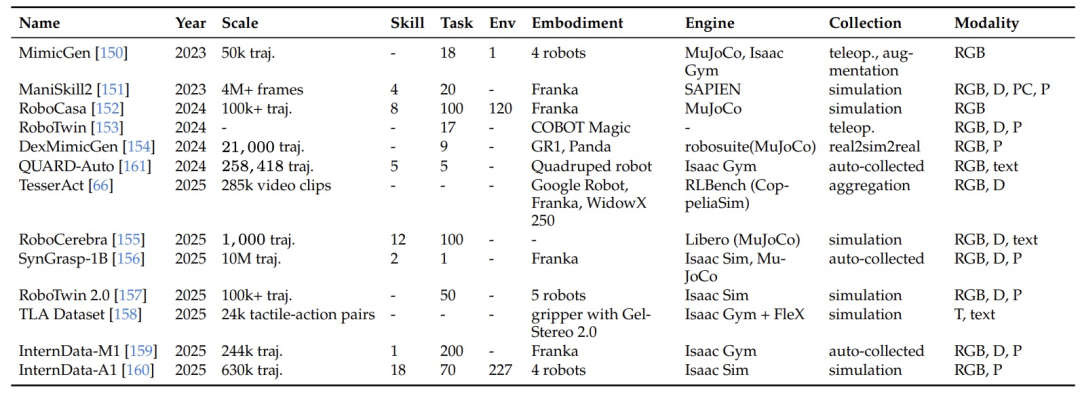
图|仿真数据集概览。
4.人类和第一视角数据。这类数据可以帮助模型学习真实世界中的被动物理动态。通过 3D 姿态、手部轨迹和物体姿态标注,它们也可以连接人类视频和机器人动作。
基准
在评估方面,WAM 不能只评估生成结果的视觉质量,还要考察未来状态预测、动作生成,以及二者之间的因果一致性。目前,相关评估大多仍被拆成两部分:世界建模能力评估和动作策略能力评估。具体来看,世界建模能力主要分为三类:
1.视觉保真度,包括 PSNR、SSIM、LPIPS、DreamSim、DINO 相似度和 FVD,用于衡量像素重建、结构相似性、感知相似性、语义一致性和分布级视频质量。
2.物理常识,关注生成世界是否保持物体连续性,接触、碰撞、状态变化和轨迹是否符合物理规律。相关基准包括 VideoPhy、PhyGenBench、VBench-2.0、WorldModelBench、Physics-IQ、WorldScore 和 EWMBench。
3.动作合理性,生成出来的视频,能不能反推出机器人真正可以执行的动作。研究团队提到两个相关基准:WorldSimBench 评估生成视频是否保留了足够的控制信息,能否转化为动态具身环境中的正确控制信号。Wow, wo, val! 则进一步把生成视频交给逆动力学模型,让模型从视频中推断动作序列,再把这些动作放到真实机器人上执行。结果显示,许多视觉上可信的模型,在真实执行成功率上接近零。
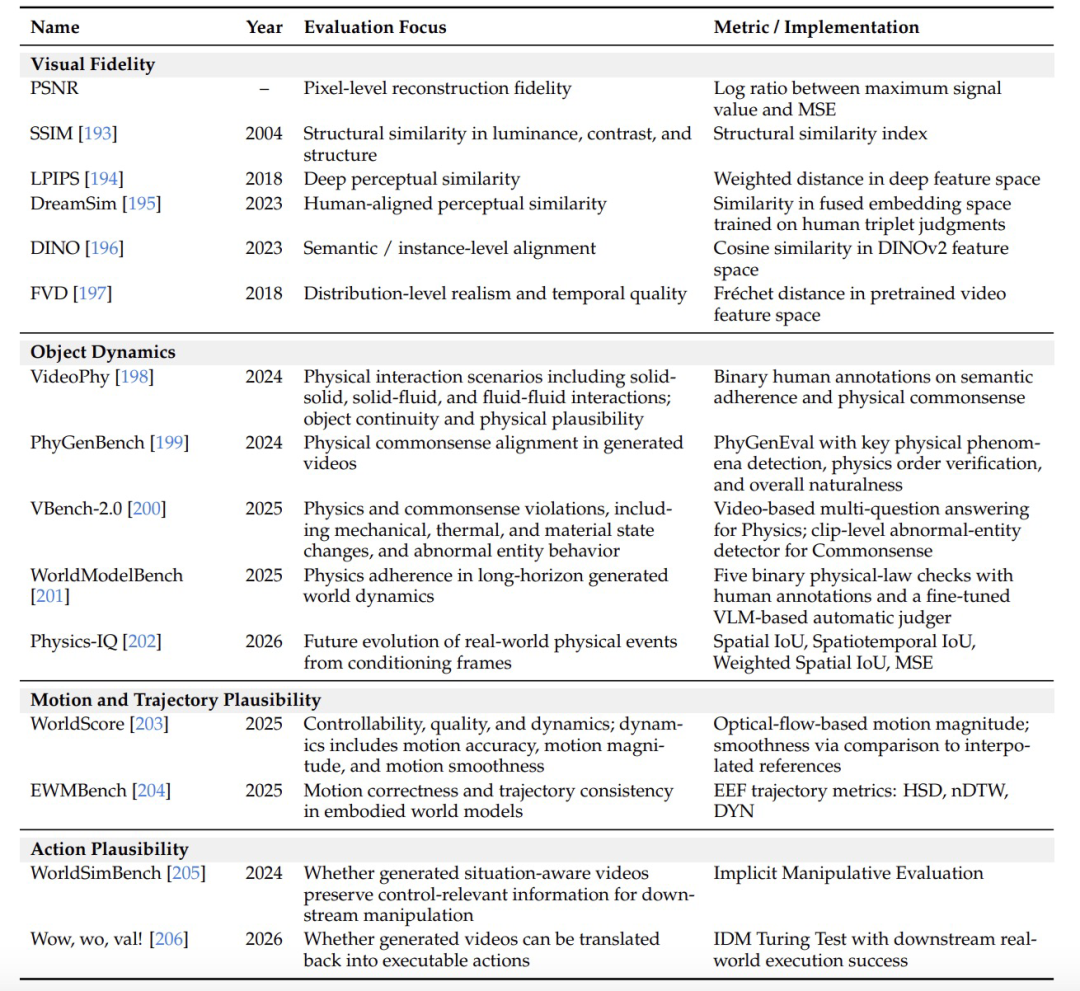
图|世界建模评估指标与基准概览。
除世界建模能力外,研究团队还梳理了动作策略能力的评估方式。他们整理了 2019 到 2026 年的 40 多个主流机器人操作基准,覆盖通用操作、双臂和人形、移动操作、接触和形变操作、真实机器人评估等场景。不过,这些基准仍主要衡量任务成功率,缺少对“预测未来”和“执行动作”之间因果一致性的评估。
不足与未来方向
研究团队也总结了 WAM 当前面对的主要挑战,具体如下:
1.架构耦合
研究团队表示,现有方法包括级联式流水线、联合扩散骨干网络、离散 token 化方案,以及隐式表征对齐等,但目前还缺少在相同规模、数据条件和评估协议下的受控对比。因此,显式预测视觉未来是否必要、不同耦合机制对下游控制的影响是什么,目前仍没有明确结论。潜在预测式 WAM是未来探索的方向,即不再依赖推理阶段的显式未来帧生成,而是在联合学习的潜在空间中建模动作条件下的状态转移,以实现更高效、更抽象的世界-动作耦合。
2.多模态物理状态表征
现有 WAM 大多预测 RGB 未来状态,但接触操作所需的触觉分布、接触力、声学特征和材料柔顺性,往往无法从像素中直接获得。研究团队认为,只依赖视觉预测会在关键物理交互处留下系统性盲点。将 WAMs 扩展为能够联合预测并推理触觉、力觉和本体感知等未来状态,发展支撑这种多模态世界建模所需的架构与数据集,是尚未被充分探索的前沿方向。
3.数据利用与混合设计
研究团队认为,人类第一视角视频和非机器人数据已经显示出价值,但不同数据源各自贡献多少仍不清楚。收益主要来自语义信息还是动态信息、训练过程如何从大规模互联网视频过渡到带精确动作标注的机器人示范,也还没有清晰答案。未来值得探索的是面向 WAM 的原则化数据混合与具身感知过滤机制,从多样化数据源中选择性提炼普适物理规律,同时抑制与目标机器人运动学不兼容的行为。
4.长时程规划与时间抽象
WAM 目前多在短程操作任务和单次交互场景中评估,但通用具身智能需要在更长任务跨度上持续推理。随着预测步数增加,模型会面临世界状态预测漂移、动作误差累积,以及长程轨迹生成带来的计算和架构压力。研究团队写道,未来长时程推理可沿模块化层级结构、内生层级式 WAM,以及扩展时间上下文三个方向发展。
5.推理延迟与计算效率
世界预测会增加计算开销,使 WAM 难以达到高频控制所需的响应速度。研究团队提到,DreamZero 通过算法加速和 CUDA 优化将推理频率推进到 7Hz,但仍低于非生成式 VLA 策略约 50Hz 的标准。模型应根据任务需求和误差容忍度,在需要高精度的地方投入更多计算,在其他地方使用更粗略的近似,兼顾物理预见能力、实时控制需求和计算效率。
6.评估方法
当前评估通常将世界建模和动作生成分开,世界建模看预测质量,动作生成看任务成功率。未来评估方向应转向联合评估世界预测与动作生成之间的因果一致性,设计反事实一致性、预见条件成功率等耦合指标,检验模型想象的未来是否真正影响并约束其物理执行,并建立共享基准框架。
7.安全性与可靠物理部署
研究团队认为,如果模型预测了错误的未来状态,并据此生成动作,就可能执行难以及时中断或纠正的动作,带来真实风险。未来, WAM 的预测能力也可以变成安全检查机制,让机器人在行动前先预演、评估风险,再决定要不要执行。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢