
随着大语言模型(LLM)与多模态模型(VLM)在生产环境的爆发式应用,“内容安全”已成为一道绕不开的防线。然而,目前的防御范式大多采取“后置检测”模式——即等模型生成完整答案后,再进行二次审查。这种“先污染、后治理”的模式,不仅存在明显的防御滞后,效率与检测能力还存在“两难抉择”。
近日,阿里安全AIGC安全团队发表的最新研究成果PlugGuard被人工智能领域顶级会议ICML 2026正式录用。该研究跳出了传统的“事后审查”思维,提出了一套兼具超高精度与毫秒级效率的流式防御框架。
ICML(International Conference on Machine Learning) 是全球公认的机器学习领域最具影响力的顶级学术会议之一,也是CCF推荐的A类国际会议, 录用率为 26.6%。ICML 汇聚了全球AI领域的顶尖学者与工业界创新者,其录用论文代表了相关领域最前沿的学术水平。
https://arxiv.org/abs/2510.09694https://github.com/Alibaba-AAIG/Kelp🎈传统“后置检测”(Post-hoc Detection):这是目前主流的方案。模型必须先把一段完整的内容生成出来,防御系统才能开始工作。如果这段话包含违规信息,那它已经完整展示给用户,即便最后被撤回,风险早已暴露。这不仅导致了严重的防御滞后,还产生了额外的审查延时。🎈流式实时防御(Streaming Detection):在生成过程中执行流式、逐词元(per-token)的安全性预测。使得系统能够以极少的训练参数和极低的延迟,实现即时干预。流式防御可以将安全防线从“响应生成后”前移至“解码过程中”,化解了内容泄露与防御滞后的问题,实现安全防控与生成体验的同步兼顾。
长期以来,流式安全防御的研究受困于一个核心难题:缺乏科学的评估标准。现有的端到端安全评测中的模型回复大多依赖于静态语料库,这些数据源往往来自异构模型或人工撰写,无法真实模拟目标模型在解码过程中(token-by-token)产生的实时风险分布。这种“脱离目标模型”的评测方式,无法准确评估安全护栏实际嵌入到解码流程中,究竟能真正阻止多少不安全内容的产生。为了填补这一空白,阿里安全团队构建了业界首个模型相关的(Model-dependent)流式防御基准——StreamGuardBench。该基准具备三大核心特性:忠实还原生成轨迹:基准中的每一条响应,均由待测的特定目标模型(涵盖Qwen、Llama等10款主流模型)实时生成,确保了“防御对象”与“测试对象”的一致性。覆盖风险全:整合了WildGuard、S-Eval等权威数据集,覆盖多种复杂风险场景,包含图片和文本模态。大规模实战验证:包含26.8万对query-response样本,为防御技术提供了真实可靠的“安全试金石”。PlugGuard是一个专为大模型生成全链路设计的轻量化插件框架,将大模型生成的动态过程视作风险控制问题,通过“旁路监听”模型中间层状态,进行动态建模,实现了对风险的实时预判。PlugGuard抛弃了传统做法中对模型输出结果的简单分类,转而利用流式隐状态动态感知头(SLD)。通过引入封闭式(closed-form)连续时间神经网络,感知头能够对连续文本序列隐状态进行建模。🎈风险挖掘:它像一个精密的“监听器”,能够实时挖掘模型推理过程中大脑深处的中间层隐藏状态。🎈动态捕捉:通过追踪风险随序列生成的演化轨迹,感知器能从细微的语义波动中提前预判风险,而无需等待整句话生成完毕。为了确保防御系统不会出现“忽冷忽热”的误判,团队设计了锚定时序一致性(ATC)损失函数。ATC对生成序列的尾部token进行监督,而不仅仅是句子级别单token的监督,通过添加单调性约束,使模型内部的风险评估曲线始终保持平滑递增。🎈策略执行:该机制强制模型遵循“一旦发现有害即立即拦截(stop-if-harmful)”的安全策略。🎈平滑鲁棒:ATC有效抑制了检测器在连续token生成中的抖动,使得拦截决策不仅快速,而且稳定可靠,显著降低了误伤良性内容的风险。
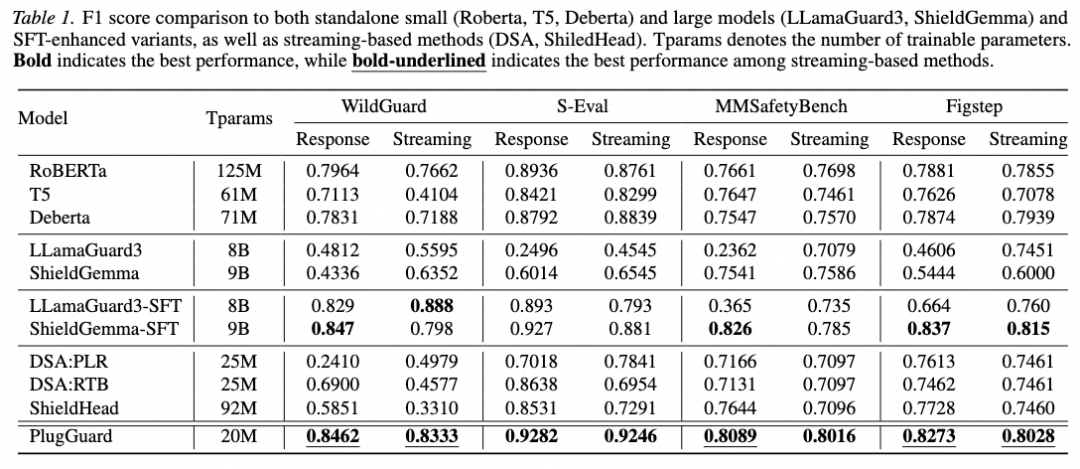
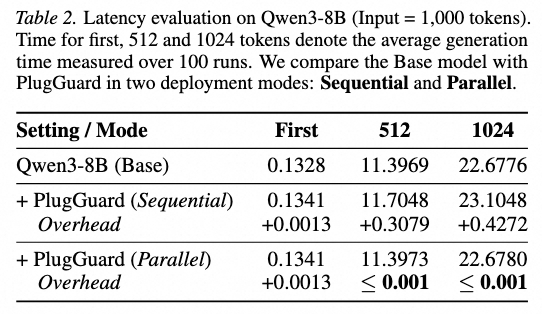
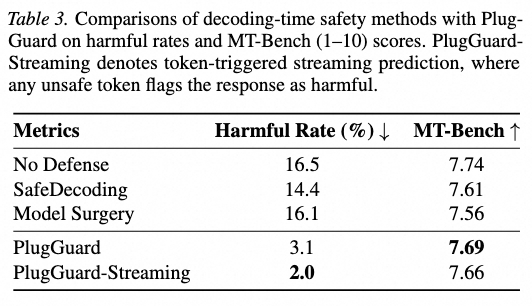
 实验数据显示,PlugGuard在防御效能与计算开销之间找到了黄金平衡点:🎈检测能力领先:在多项权威流式安全评测中,PlugGuard的检测准确率(F1分数)较现有最优流式方案平均提升了0.1561。🎈超轻量部署:仅需20M可训练参数,通过轻量级插件即可赋能百亿级参数模型,无需改动基座模型参数。🎈极致推理速度:单token的额外处理延迟低于0.5毫秒。在生产环境中,这几乎是用户“无感”的防御体验,彻底解决了性能与安全的“两难抉择”。🎈有用性的稳健保持:在评估模型通用任务有用性的MT-Bench指标上,PlugGuard 表现稳健,高于对比基线。这说明PlugGuard在实现安全防控的同时,未对模型的通用交互能力造成明显的负面影响。PlugGuard推动着大模型安全防御正从“事后被动扫描”向“解码中实时干预”迈进。该成果不仅在学术评测基准上取得了优异表现,也在实际业务场景中得到了验证,为企业部署可控、可信的大模型系统提供了切实可行的技术路径。目前,PlugGuard的代码和评测基准StreamGuardBench已开源。阿里安全期待通过这一开放的基准与框架,与学术界、工业界共同推动大模型安全技术向更深层次的防御演进。
实验数据显示,PlugGuard在防御效能与计算开销之间找到了黄金平衡点:🎈检测能力领先:在多项权威流式安全评测中,PlugGuard的检测准确率(F1分数)较现有最优流式方案平均提升了0.1561。🎈超轻量部署:仅需20M可训练参数,通过轻量级插件即可赋能百亿级参数模型,无需改动基座模型参数。🎈极致推理速度:单token的额外处理延迟低于0.5毫秒。在生产环境中,这几乎是用户“无感”的防御体验,彻底解决了性能与安全的“两难抉择”。🎈有用性的稳健保持:在评估模型通用任务有用性的MT-Bench指标上,PlugGuard 表现稳健,高于对比基线。这说明PlugGuard在实现安全防控的同时,未对模型的通用交互能力造成明显的负面影响。PlugGuard推动着大模型安全防御正从“事后被动扫描”向“解码中实时干预”迈进。该成果不仅在学术评测基准上取得了优异表现,也在实际业务场景中得到了验证,为企业部署可控、可信的大模型系统提供了切实可行的技术路径。目前,PlugGuard的代码和评测基准StreamGuardBench已开源。阿里安全期待通过这一开放的基准与框架,与学术界、工业界共同推动大模型安全技术向更深层次的防御演进。
🔥XGuard护栏揭榜赛火热进行中
点击下面【阅读原文】立刻参与
目前已有数百种思路涌现!如果你刚读完PlugGuard的流式拦截思路,欢迎将更多灵感注入比赛!👇点击阅读比赛详情
📌往期推荐
AAIG课代表,获取最新动态就找她👇关注公众号发现更多干货❤️
内容中包含的图片若涉及版权问题,请及时与我们联系删除





















评论
沙发等你来抢