
近年来,多模态大语言模型(MLLMs)在视觉理解、文本生成和跨模态推理方面不断取得突破,人工智能也正在加速走进化学研究的核心场景。但在真实的化学工作流中,研究者面对的往往不是单一模态的信息,而是文本描述、分子结构式、SMILES字符串以及分子图像等多种表示方式交织在一起的复杂问题。模型能否真正打通这些模态,并在“理解”之外进一步完成“生成”,仍然是一个关键挑战。
近日,上海人工智能实验室与中国科学技术大学等团队联合提出ChemMLLM—— 一个面向化学领域的统一多模态大语言模型,能够在文本、SMILES与分子图像之间实现分子理解与生成,为化学人工智能提供了更自然、更直观的人机交互范式。论文第一作者为上海人工智能实验室与中国科学技术大学联培博士谭骞。

为什么化学领域需要这样的多模态大模型?
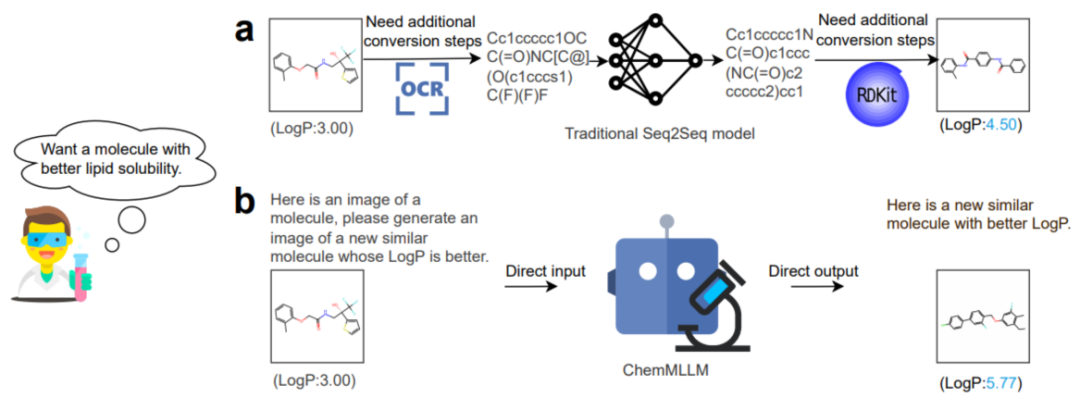
化学研究天然就是一个多模态领域。研究者既需要阅读文本中的性质描述,也要理解分子图像中的结构信息,还要借助SMILES等符号形式进行计算与建模。然而,现有大多数化学AI系统仍然以单任务、单方向处理为主:它们往往可以从图像中识别分子,或从文本中预测分子性质,却很难在不同模态之间进行统一建模,更缺乏直接生成化学可视化结果的能力。现有方法多数偏重“理解”,而对化学研究中同样重要的“视觉生成”探索仍然不足。尤其在分子设计任务中,传统流程通常需要模型先输出 SMILES,再借助外部工具渲染成图像,这种割裂式流程会明显降低研究效率。
ChemMLLM
:统一的“分子理解”和“分子生成”框架
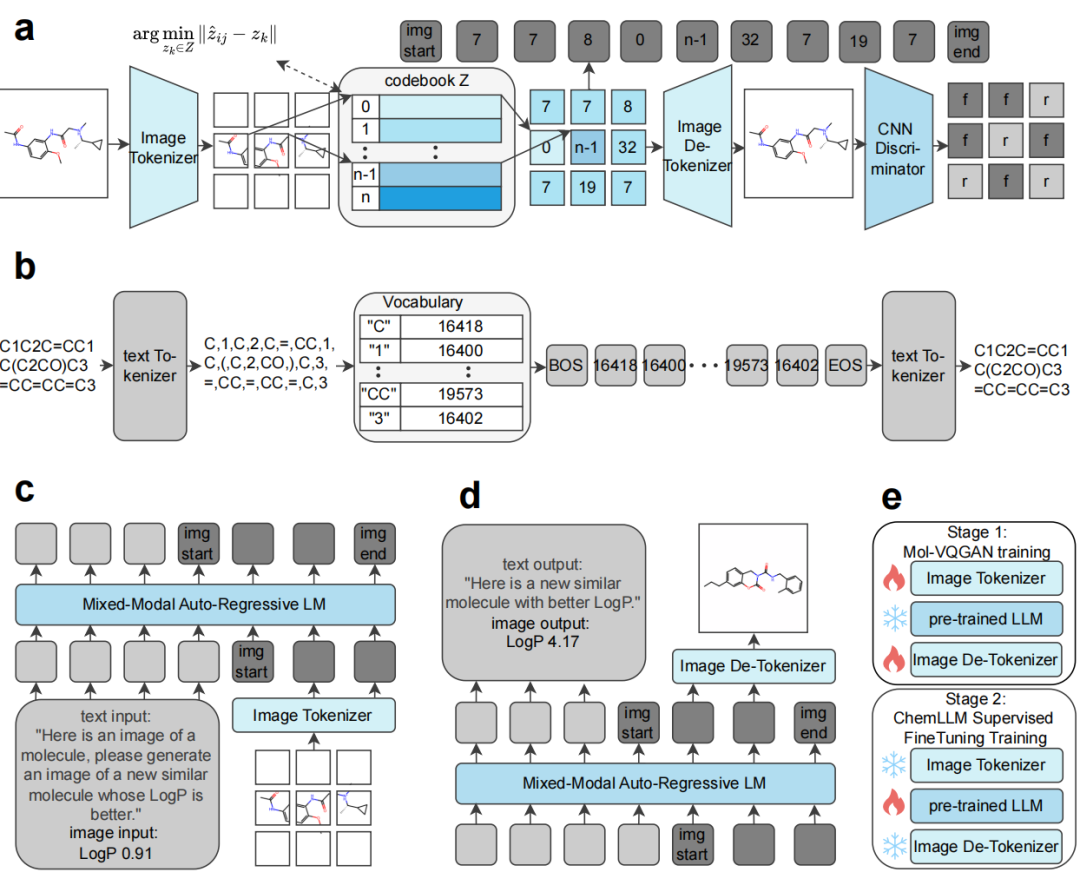
针对这一空白,ChemMLLM提出了一个统一的化学多模态框架。该模型的核心目标,是让模型不仅能读懂分子图像、识别分子结构、预测化学性质,还能够直接生成分子图像,真正打通化学场景下的跨模态理解与生成。ChemMLLM围绕文本、SMILES与图像三种模态,系统设计了五类任务:
分子图像描述(Molecule Image Captioning)
分子图像性质预测(Molecule Image Property Prediction)
图像到 SMILES 转换(Image-to-SMILES Conversion)
可控多目标分子图像设计(Controllable Multi-objective Molecule Image Design)
分子图像优化(Molecule Image Optimization
这些任务同时覆盖“看懂分子”“识别分子”“设计分子”“优化分子”等关键能力,使得多模态化学大模型不再局限于单点任务,而是朝着更完整的化学工作流能力迈进。
在方法上,ChemMLLM的一个重要创新,是引入了面向分子图像专门训练的Mol-VQGAN,将分子图像离散化为token,使其能够像文本和SMILES 一样被统一送入大语言模型中处理。基于这一设计,模型采用“Image Tokenizer–LLM–Image De-tokenizer”的统一架构,并配合两阶段训练策略,实现跨模态的早期融合与端到端生成。相比于通用图像模型,Mol-VQGAN 更能忠实编码和重建分子图像中的原子、键和结构细节,这为后续的化学推理与生成提供了关键基础。
从“会看图”到“会设计图”:ChemMLLM展现出更完整的化学能力
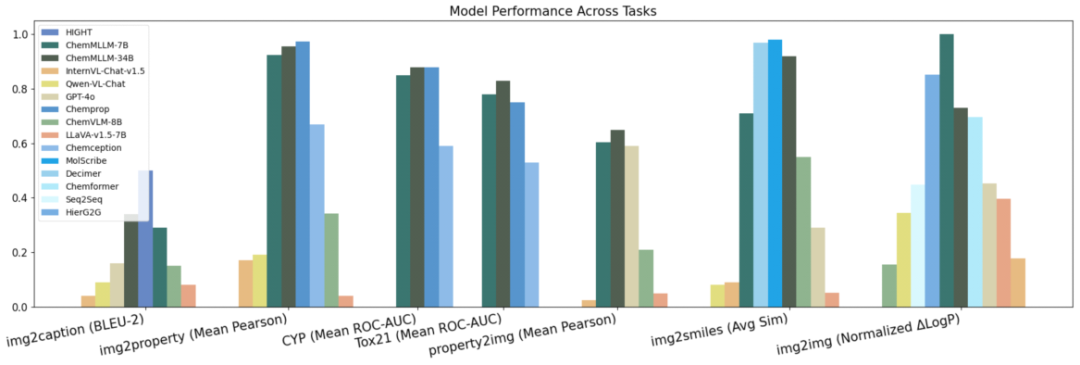
实验结果表明,ChemMLLM在五类任务上整体优于通用多模态大模型,并逼近专用模型,验证了统一化学多模态基础模型的可行性。
更具体地说,在分子图像性质预测任务中,ChemMLLM在七项分子性质上均显著优于通用MLLMs,并在Tox21 基准上超过了专用图模型Chemprop,在CYP基准上也取得了具有竞争力的表现,说明它不仅能“看见”分子图像,还能从中提炼出与生物活性相关的重要结构信息。
在图像到SMILES转换任务中,ChemMLLM在所有通用多模态模型中取得最佳表现,ChemMLLM-34B 的Tanimoto similarity 达到0.92,相较ChemVLM的0.55 提升显著,显示出其对分子结构、键连接和立体化学信息的强大识别能力。
而更值得关注的是,ChemMLLM不只会“识别”,还具备了直接生成分子图像的能力。在可控多目标分子设计和分子优化任务中,它可以根据给定性质要求直接生成目标分子图像,或基于输入分子图像生成性质更优的新分子图像。在分子优化任务中,ChemMLLM-34B 获得了最高的LogP提升,相比GPT-4o 提升120.81%。这意味着模型已经不仅能回答“这是什么分子”,还开始具备回答“我想要一个更好的分子,应该长什么样”的能力。
ChemMLLM
的意义,不止于“多做了几个任务”
ChemMLLM的价值,不仅在于把多个化学任务统一进了一个模型,更在于它拓展了化学大模型的人机交互方式。相比只能输出SMILES的符号式流程,直接生成2D 分子图像能够为化学家提供更加即时、轻量且直观的视觉反馈,减少外部转换步骤,降低认知负担,加快分子设计迭代。与此同时,分子图像这一视觉模态也让模型有机会处理更多现实世界中的化学数据来源,例如论文中的结构图、历史文献中的位图、实验笔记中的手绘草图等,这是纯文本或纯图结构模型难以覆盖的。
ChemMLLM 的发布,并不是简单地把“图像输入”加进化学模型,而是在尝试构建一个真正能在化学家熟悉的表达方式中进行交流、理解和创作的多模态基础模型。它让化学 AI从“能回答问题”进一步走向“能参与分子设计与可视化生成”,也为未来更自然的化学智能助手打开了新的可能。
参考资料
Tan Q, Zhang D, Gao B ..., Developing ChemMLLM as a multimodal large language model for chemistry, Cell Reports Physical Science, 2026
https://doi.org/10.1016/j.xcrp.2026.103310
GitHub
https://github.com/bbsbz/ChemMLLM
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢