

近期研究已开始探索大型视觉语言模型(LVLM)中的注意力动态,以检测幻觉(Hallucination)。然而,现有方法在可靠区分幻觉输出和基于事实的输出方面仍存在局限性,因为它们仅依赖于前向传递的注意力模式,而忽略了揭示词元影响如何在网络中传播的基于梯度的信号。为了弥补这一不足,我们提出了LVLMs-Saliency,这是一个梯度感知的诊断框架,它通过融合注意力权重及其输入梯度来量化每个输出词元的视觉关联强度。我们的分析揭示了一个关键模式:当先前的输出词元对下一个词元的预测表现出较低的显著性时,幻觉往往就会出现,这表明上下文记忆保持能力出现了问题。基于此洞见,我们提出了一种双机制推理时框架来缓解幻觉:(1)显著性引导的拒绝采样(SGRS),它在自回归解码过程中动态过滤候选词元,拒绝显著性低于上下文自适应阈值的词元,从而防止破坏连贯性的词元进入输出序列;(2)局部连贯性强化(LocoRE),这是一个轻量级的即插即用模块,它增强了当前词元对其最近前导词元的注意力,主动抵消了LVLMs-Saliency所识别出的上下文遗忘行为。在多个LVLM模型上进行的大量实验表明,我们的方法显著降低了幻觉发生率,同时保持了流畅性和任务表现,为提高模型可靠性提供了一种稳健且易于解释的解决方案。
请索引第94篇论文
 |  |
LVLM幻觉诊断大突破!上交&阿里开源新工具:幻觉,始于显著性下降
一种新的内部观察工具,揭示了模型“遗忘”的瞬间
“这是什么?”
“图片里有一个交通锥、一个椅子,以及一个男人。”
这段与某个大模型的对话看似平常,但仔细看,图片里根本没有椅子。模型凭空“想象”出了一把椅子——这就是困扰当前大视觉语言模型的核心难题:“幻觉”。
幻觉问题严重影响LVLM的可靠性。以往,我们像“黑盒”一样使用模型,知其然不知其所以然。大量研究试图从“注意力机制”入手,但效果有限。问题出在哪?
今天,一篇被ICLR 2026收录的论文《Hallucination Begins Where Saliency Drops》给了我们一个全新的、深刻的视角。来自上海交通大学、阿里巴巴、北京大学等机构的研究团队指出,仅靠前向传播的“注意力”不足以揭示幻觉根源,必须结合反映信息传播的“梯度”。
他们由此提出了LVLMs-Saliency这一革命性的诊断工具,并基于其发现构建了能实时抑制幻觉的推理框架。这个工作不仅在技术上实现了SOTA,更重要的是,它为我们打开了理解模型内部工作机制的一扇窗。
01 现有方法瓶颈:为何只看“注意力”不够?
在深入新方法之前,我们需要理解当前研究的困境。许多工作已关注到LVLM中的“注意力沉没”现象,即模型过度关注某些特定Token(如初始Token或图像Token),这可能损害后续生成。
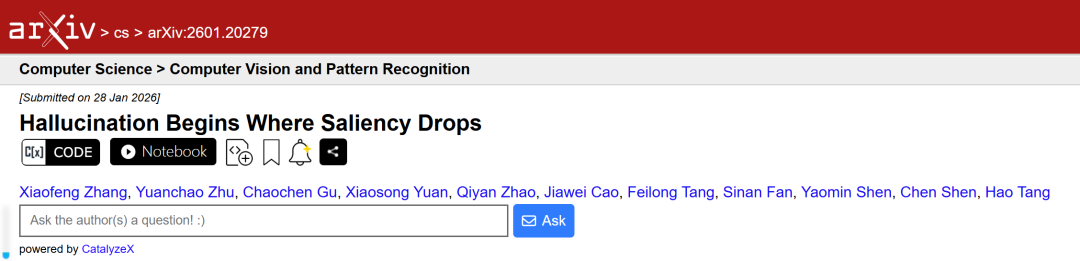
然而,这篇论文的开篇就指出了关键局限:注意力权重只告诉我们模型“在看哪里”,却无法告诉我们输入的变化如何“影响”最终输出。
如图1所示,在传统的注意力热力图中,我们几乎无法分辨正确输出与幻觉输出的模式差异。注意力图是模型决策的“瞬时快照”,但丢失了信息流动的动态因果。
“这就像只通过观察司机的视线方向来判断他的驾驶决策,却忽略了油门、刹车和方向盘的操作如何具体影响车辆轨迹。”论文一作张晓风解释道。为了理解模型为何“跑偏”,我们必须知道内部信号的“传导”强度。
02 核心突破:LVLMs-Saliency——融合注意力与梯度的“显微镜”
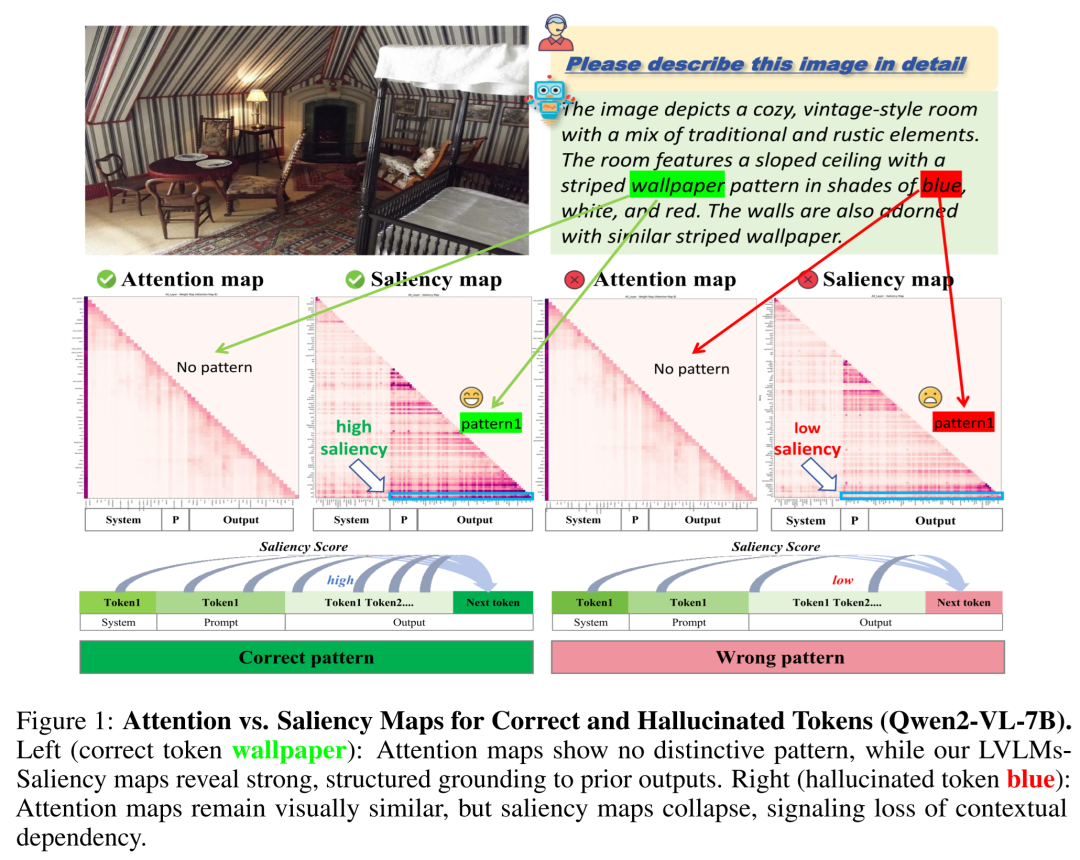
受“标签词是锚点”工作中信息流思想的启发,研究团队提出了LVLMs-Saliency。它的定义简洁而有力:将注意力权重与其对应的梯度进行逐元素相乘。
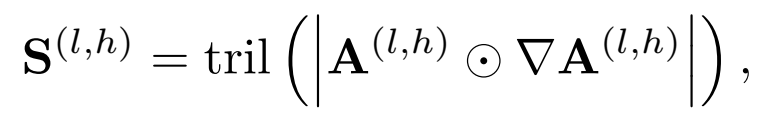
这个公式的含义是:
(注意力):Token j 对生成当前Token i 的“关注度”。
(梯度):注意力权重的微小变化,对最终预测损失的影响程度。它衡量了注意力连接的“重要性”或“影响力”。
(显著性):二者的结合,量化了之前生成的每个输出Token对预测下一个Token的真实、有效的影响强度。
你可以将显著性理解为一种“ grounding strength”,它揭示了模型在自回归生成过程中,其文本输出上下文的“记忆”有多牢固。
图2 直观地展示了其威力。在Qwen2-VL模型上,当生成正确Token“woman”时,模型对前文中的关键描述“two people”保持了高显著性(暖色),上下文记忆连贯。而当模型产生幻觉Token“bench”时,它对前文关键信息的显著性急剧下降(冷色),模型似乎“忘记”了刚刚说过的内容。
03 决定性模式:幻觉,始于显著性下降
通过对大量样本的系统性分析,论文揭示了导致幻觉的一个决定性模式:
Pattern 1: Hallucinations occur when prior output tokens shows low saliency to the next token.
幻觉,发生在前序输出Token对下一个Token的显著性降低之时。
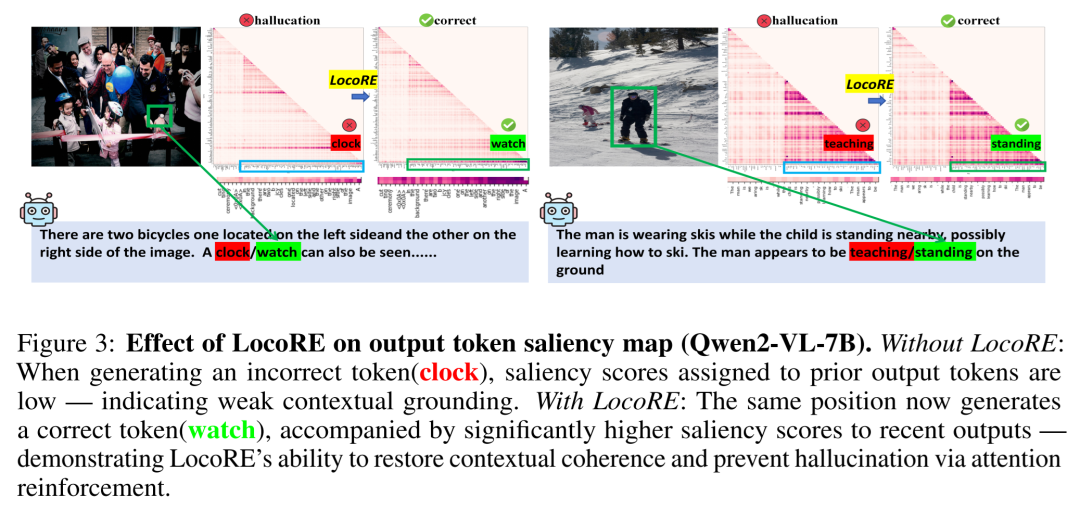
图3 清晰地阐释了这一模式。在正确的生成轨迹中,模型像有一条坚实的记忆链,每个新Token都牢牢“锚定”在前文上(高显著性)。而一旦这个链条断裂——模型对最近输出的“记忆”变弱(低显著性)——它就失去了文本上下文的约束,陷入“信口开河”的幻觉状态。
这个发现至关重要。它指出,许多幻觉并非源于图像信息不足,而是源于模型在生成长文本时,对自身历史输出的“遗忘”。这为干预提供了极其精确的“靶点”。
04 双机制解决方案:从诊断到治疗
基于上述核心洞察,论文提出一个在推理阶段即可使用的双机制干预框架,形成一个闭环的连贯性保持系统。
机制一:显著性引导拒绝采样——主动的“守门员”
Saliency-Guided Rejection Sampling 扮演“守门员”角色。在解码的每一步,模型用Top-K采样得到K个候选Token。SGRS的核心思想是:在候选Token被正式写入序列之前,先评估其“根基”是否牢固。
它会计算每个候选Token 相对于前文输出Token的显著性分数 。然后设定一个自适应的动态阈值,该阈值基于最近W个历史输出Token的显著性均值计算。
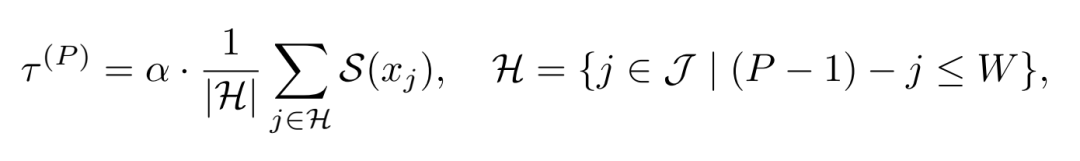
只有显著性分数不低于此阈值的候选Token才会被接受。 这就主动拦截了那些与上下文关联薄弱、可能引发连贯性崩溃的“捣乱分子”,迫使模型重新采样,直到选出一个与历史上下文“接地气”的Token。

算法1 形式化了SGRS的完整流程,确保了方法的严谨和可复现性。
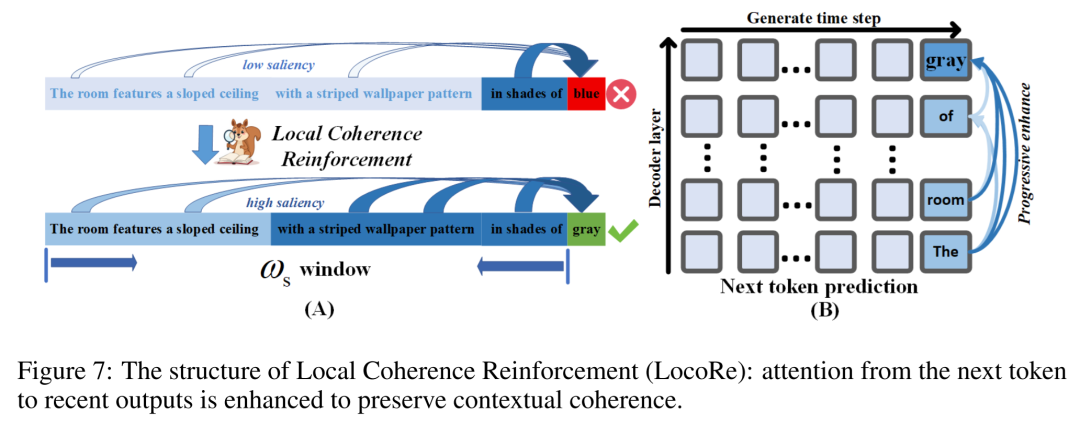
机制二:局部连贯性增强——被动的“稳定器”
Local Coherence Reinforcement 扮演“稳定器”角色。它在一个Token被SGRS接受并写入序列后启动工作。LocoRE的目标是:确保这个刚被接受的Token,在后续生成中不会被快速“遗忘”。
它的操作非常轻量且巧妙:在预测下一个Token时,显式地增强当前查询位置对最近 个输出Token的注意力权重。通过一个距离感知的增益因子来实现:
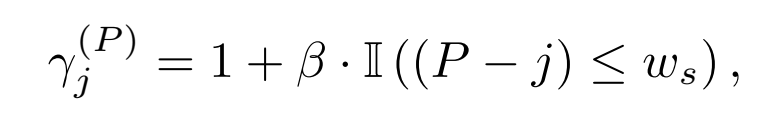

算法2 展示了LocoRE如何在不进行任何梯度计算或修改模型参数的情况下,仅通过前向传播中的注意力权重操作,就实现了对近期上下文的记忆强化。这直接对抗了在Pattern 1中观察到的“遗忘”行为。
协同工作流:SGRS确保进入序列的每个Token都是“根基牢固”的;LocoRE随后确保这些Token不会被立即“遗忘”。二者在每一步解码中顺序执行,形成了“预防-巩固”的完美闭环。
05 实验结果:全方位领先,效果显著
理论和方法再优美,也需要实验的坚实验证。论文在包括幻觉评测、综合能力评测、通用VQA在内的多个基准上,对LLaVA-1.5、Qwen2-VL、Intern-VL等多种主流LVLM进行了广泛测试。
5.1 幻觉评测基准上的卓越表现
在业界公认的POPE和CHAIR幻觉评测集上,SGRS+LocoRE的组合方法取得了领先的性能。
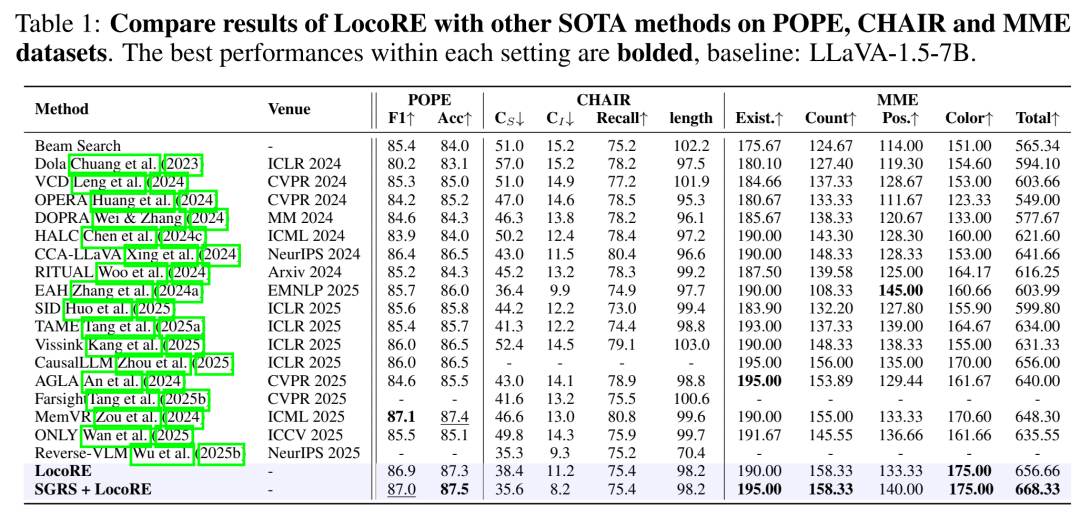
表1 详细对比了LocoRE与众多SOTA方法。可以看到,在LLaVA-1.5-7B基础上,该方法在POPE的准确率、F1分数,以及CHAIR的指标上均表现优异。特别是,它超越了如Vissink、TAME等同样操作注意力的方法。论文指出,这是因为LocoRE同时增强了视觉信息和文本输出间的上下文依赖,而其他方法可能只侧重其一。
5.2 通用能力不受损,甚至获得提升
一个优秀的去幻觉方法不能以损害模型通用能力为代价。令人惊喜的是,该方法在抑制幻觉的同时,普遍提升了模型在综合与通用VQA任务上的表现。
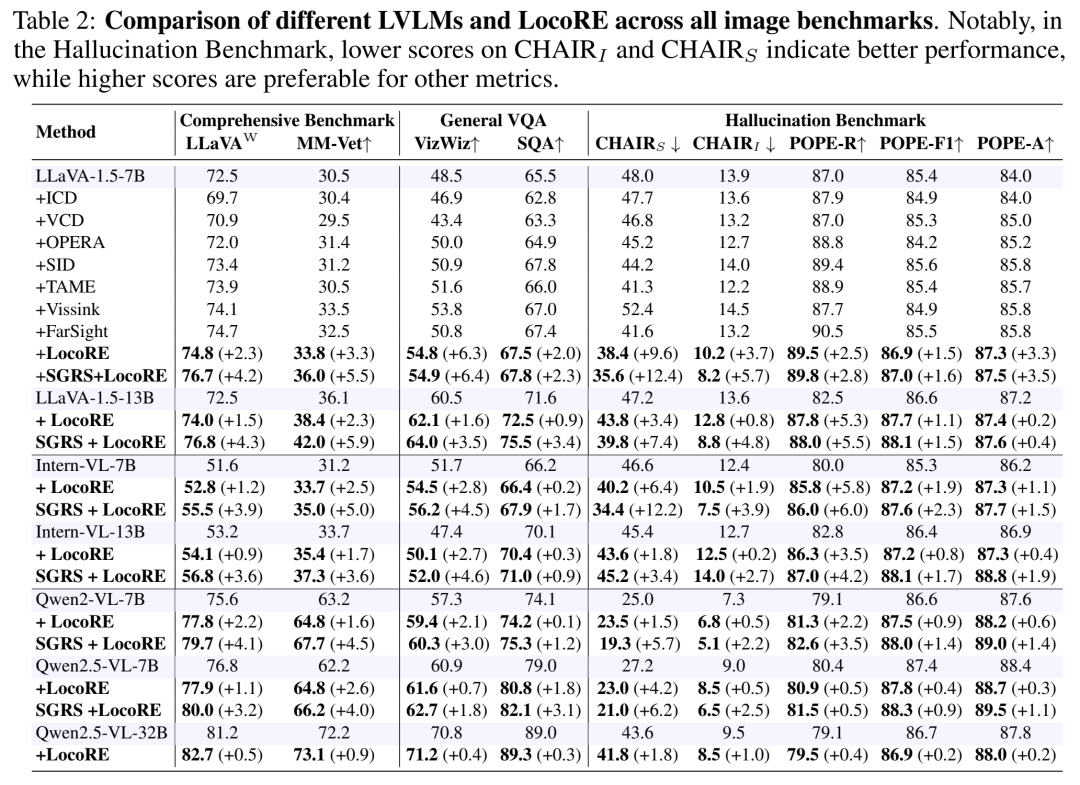
表2 呈现了全面、详实的实验结果。以LLaVA-1.5-7B为例:
综合评测:在LLaVA-Win和MM-Vet上分别提升+2.3和+3.3分。
通用VQA:在VizWiz和ScienceQA上分别提升+6.3和+2.0分。
幻觉评测:在CHAIRs和POPEA上分别大幅降低3.7和提升3.3分。
更重要的是,这种提升在不同规模(7B, 13B, 32B)和不同架构(LLaVA, Qwen, Intern)的模型上都普遍存在,证明了该方法的强泛化性和可插拔性。
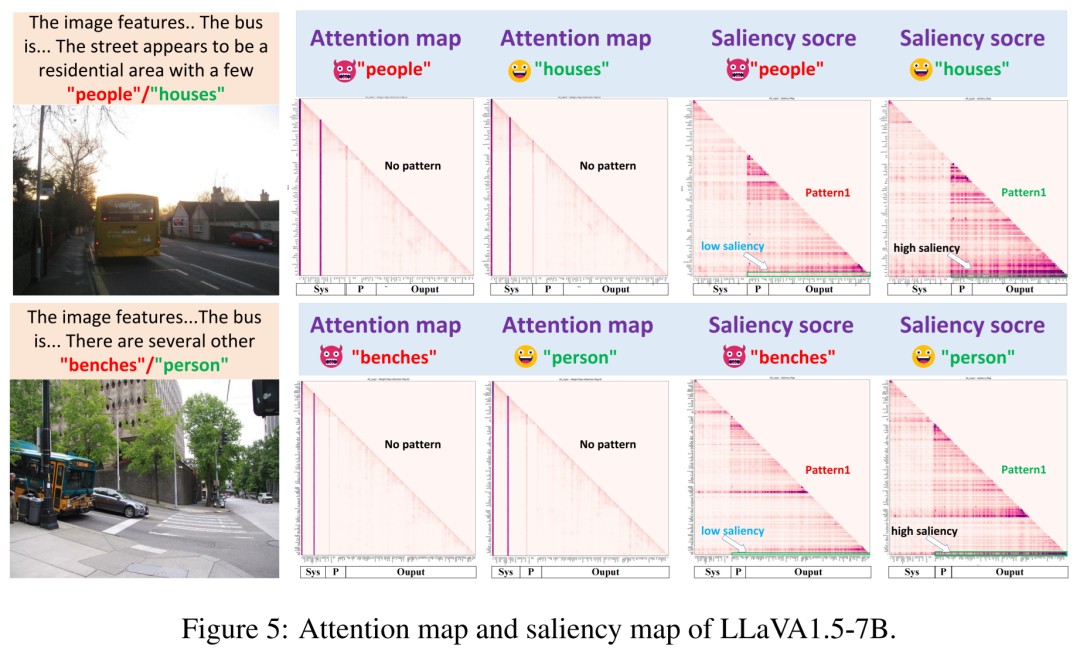
5.3 关键参数分析与效率考量
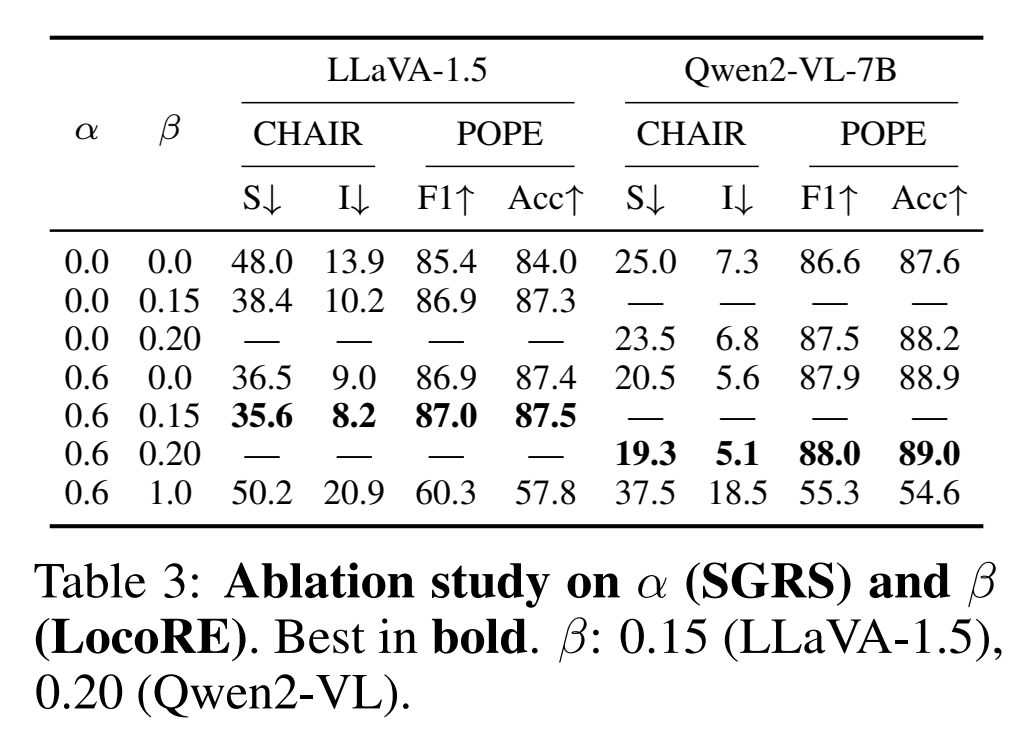
表3 的消融实验揭示了两个核心参数 和 的影响。研究发现:
SGRS是效果提升的主要来源。仅使用SGRS就能大幅降低幻觉率。
LocoRE能带来进一步的稳定增益。二者结合效果最佳。
论文推荐 作为效果与效率的最佳平衡点。
在效率方面,完整的SGRS+LocoRE由于需要计算梯度,会引入30-40%的额外延迟。但论文特别指出,仅使用LocoRE就能在仅增加<2%延迟的情况下,取得大部分的性能增益,这使其成为对推理速度敏感场景的绝佳选择。
06 更深度的思考与讨论
这项研究不仅提供了强大的工具,也引发了更深的思考:
对“注意力沉没”理论的补充:本文并非否定“注意力沉没”与幻觉的关联,而是提供了一个更本质、更可操作的视角——显著性。它揭示了沉没的注意力若缺乏有效的信息流动(低梯度),其危害性才真正显现。
“高显著性”幻觉的挑战:在论文附录的失败案例分析中,作者也坦诚了当前方法的边界。存在少数“高置信度”幻觉,即模型“自信地”输出错误答案且显著性很高。这引向一个更深层的问题:如何让模型学会“知之为知之,不知为不知”?这或许需要从训练机制和人类反馈设计上进行根本性思考。
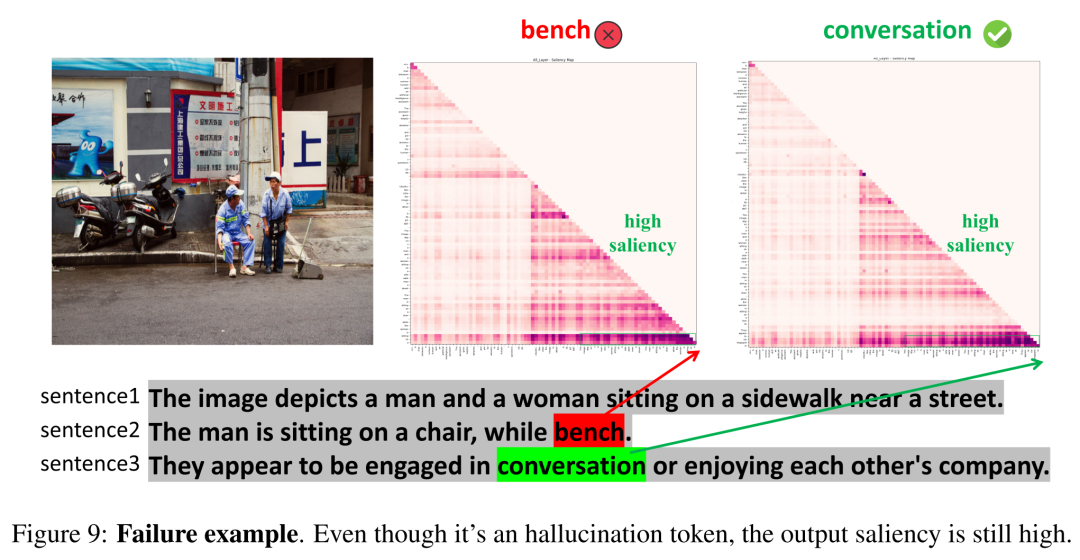
图9 展示了这样一个“高显著性幻觉”的失败案例,提醒我们解决幻觉问题的道路依然漫长。
07 总结与展望
《Hallucination Begins Where Saliency Drops》是一项从理论洞察到实践落地的杰出工作。
理论层面:它创新性地融合注意力与梯度,提出了“显著性”这一更精准的诊断指标,并发现了“幻觉始于显著性下降”这一核心模式,极大地增进了我们对LVLM生成机制的理解。
技术层面:它提出了SGRS和LocoRE这一协同的双机制框架,在多个基准上实现了显著的幻觉抑制效果,且具备即插即用、泛化性强的优点。
开源层面:作者已公开代码,社区可以立即复现、使用并在此基础上进行创新。
这项研究为构建更可靠、更透明的下一代多模态大模型指明了方向。它告诉我们,让模型“记住”自己说过的话,是避免其“胡说”的关键。而这,仅仅是开始。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢