

投稿作者:圣母大学、耶鲁大学团队
近年来,大语言模型(LLM)在数学推理任务上取得了显著进展。从小学算术题到竞赛级推理题,模型已经能在不少纯文本数学任务中给出令人惊讶的答案。
然而,现实中的数学问题,往往并不只存在于文字里。
一道几何题可能包含复杂的辅助线与角度关系;一张统计图可能隐藏着坐标轴、图例、刻度和趋势;一道应用题也可能要求模型从图片中数物体、比较数量、理解空间关系。对于这些问题,模型不仅要“会算”,还要先“看懂”。
这正是多模态数学推理(Multimodal Mathematical Reasoning,MMR)面临的核心挑战:模型需要同时处理文本、图像、图表、表格、几何图形等多种信息,并在此基础上完成可靠的数学推理。
来自圣母大学、耶鲁大学、哥伦比亚大学、纽约大学和宾夕法尼亚州立大学的研究团队系统梳理了这一快速发展的方向,并提出了一套面向多模态数学推理的统一分析框架:Perception–Alignment–Reasoning(PAR)。
值得一提的是,该论文已被 ACL 2026 Main Conference 接收。

论文链接:https://arxiv.org/abs/2603.08291
资源整理:https://github.com/formula12/Awesome-Multimodal-Mathematical-Reasoning-Perception-Alignment-Reasoning
多模态数学推理不是“看图+做题”这么简单
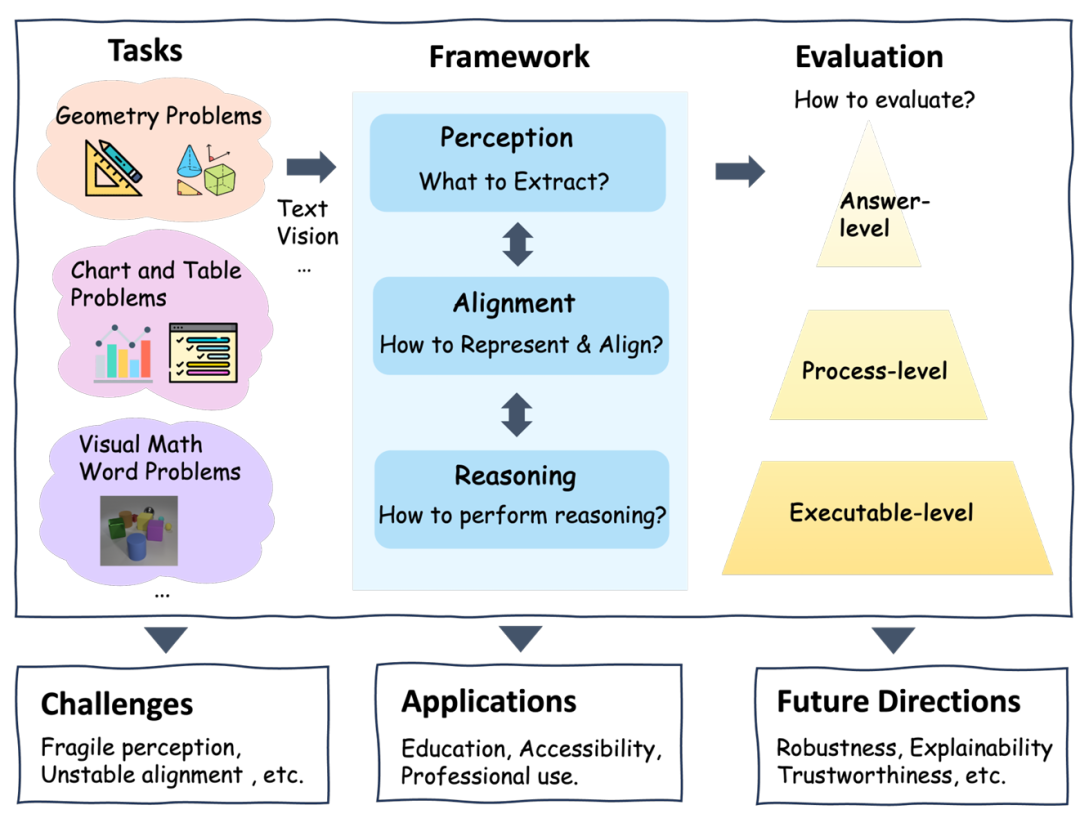
很多视觉数学题看似只是把图片交给大模型,再让它一步步推理。但实际上,错误往往在推理开始之前就已经发生了。
例如,在几何题中,模型可能没有正确识别点、线、角、平行关系;在图表题中,模型可能读错坐标轴、图例或单位;在表格题中,模型可能把错误的行列与问题中的实体绑定起来。即使后面的推理链写得很完整,前面的视觉证据一旦出错,最终答案也很可能只是“看起来合理”。
因此,研究团队指出,多模态数学推理不能只看最终答案,而应该拆解成一个完整的过程:
- 第一,模型从多模态输入中提取了什么?
- 第二,模型如何把视觉信息与文本、符号或程序对齐?
- 第三,模型如何完成多步数学推理?
- 第四,我们如何评估这个推理过程是否真的正确?
围绕这四个问题,研究团队提出了 PAR 框架。
多模态数学推理的难点,不只是“算错了”,更可能是“看错了”、“对齐错了”或“推理过程不可验证”。
PAR:从感知、对齐到推理的统一框架

PAR 将多模态数学推理拆解为三个相互依赖的阶段。
1.Perception:模型到底看到了什么?
感知阶段关注的是:模型能否从图像、图表、表格或几何图中提取出真正有计算意义的证据。
在几何问题中,这意味着识别点、线、角、圆、相交、平行、垂直等结构;在图表和表格问题中,这意味着识别坐标轴、图例、刻度、单元格、行列关系和单位;在视觉数学应用题中,则涉及物体数量、属性、空间关系和跨图像对应关系。
论文强调,数学感知不是普通视觉识别。它要求模型提取的是可以被后续推理使用的结构化证据,而不仅仅是“图片里有什么”。
2.Alignment:视觉证据如何变成可推理的表示?
感知之后,模型还需要完成对齐:把看到的视觉事实绑定到文本、符号、程序或可执行中间表示上。
例如,几何题中的图形可以被转化为几何描述语言、约束集合或证明草图;表格和图表问题可以被转化为 SQL、程序操作序列或数值计算步骤;视觉应用题中的对象与数量关系,也需要和题目中的自然语言描述正确对应。
这一阶段是多模态数学推理中非常容易出错、但又常被忽略的部分。模型即使识别出了图中的元素,也可能把“这个角”、“2021 年的柱子”、“表格第三行的数值”绑定到错误位置。
3.Reasoning:如何进行稳定、可验证的推理?
当感知和对齐完成后,模型才真正进入推理阶段。
研究团队总结了当前主要的推理范式,包括 Chain-of-Thought、Tree/Graph of Thoughts、强化学习、工具增强推理、程序执行、符号求解器,以及过程反馈和验证机制等。
其中,一个重要趋势是:未来的多模态数学推理系统不能只依赖自然语言链式推理,而需要更多引入可执行程序、符号工具、验证器和过程级反馈,让模型的中间步骤可以被检查,而不是只输出一段“看起来很像推理”的文本。
APE:只看最终答案已经不够了
除了 PAR,研究团队还提出了一个互补的评测视角:Answer–Process–Executable(APE)。
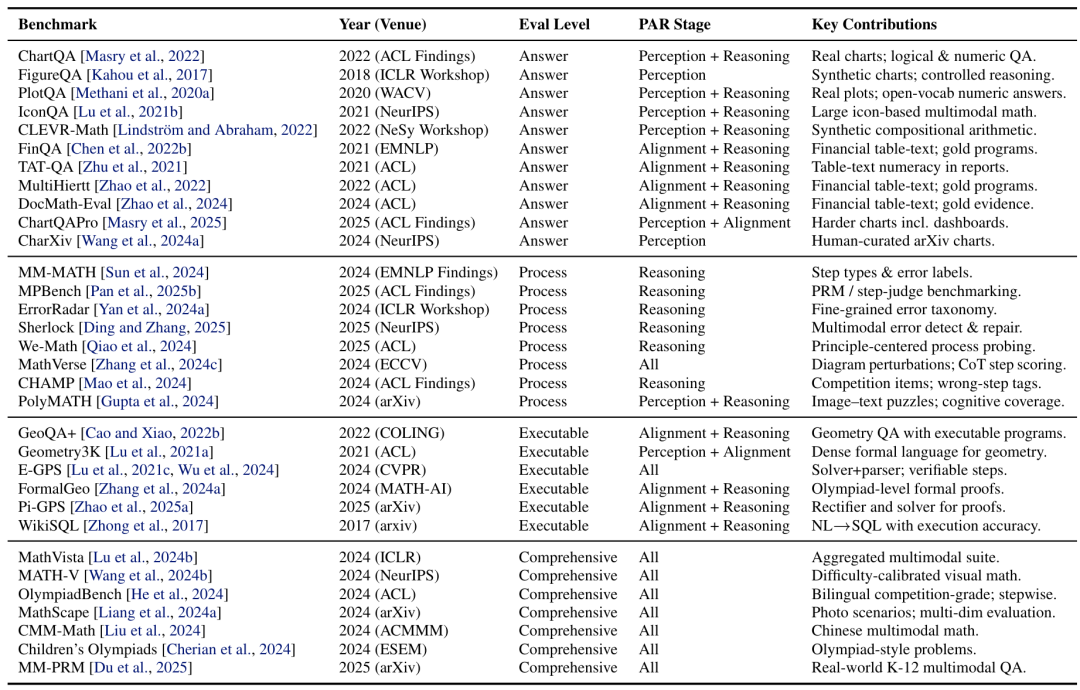
传统评测大多停留在 Answer-level,也就是只检查最终答案是否正确。这种方式简单、可扩展,但很难判断模型到底是正确推理得出答案,还是靠语言先验、数据偏差或偶然猜对。
Process-level 评测进一步检查中间步骤是否合理。例如,模型有没有正确引用图中的视觉证据?推理链中是否存在幻觉步骤?是否出现了“答案对了,但过程错了”的情况?
Executable-level 则更进一步,要求模型生成可以被执行或验证的程序、证明、约束或 SQL。这样一来,系统可以通过求解器、程序执行或证明检查器判断推理是否真的成立。
从 Answer 到 Process,再到 Executable,评测标准正在从“答对了吗”走向“你是怎么答对的,以及这个过程能否被验证”。
三类核心任务:几何、图表表格、视觉数学应用题
研究团队将当前多模态数学推理任务主要梳理为三大类。
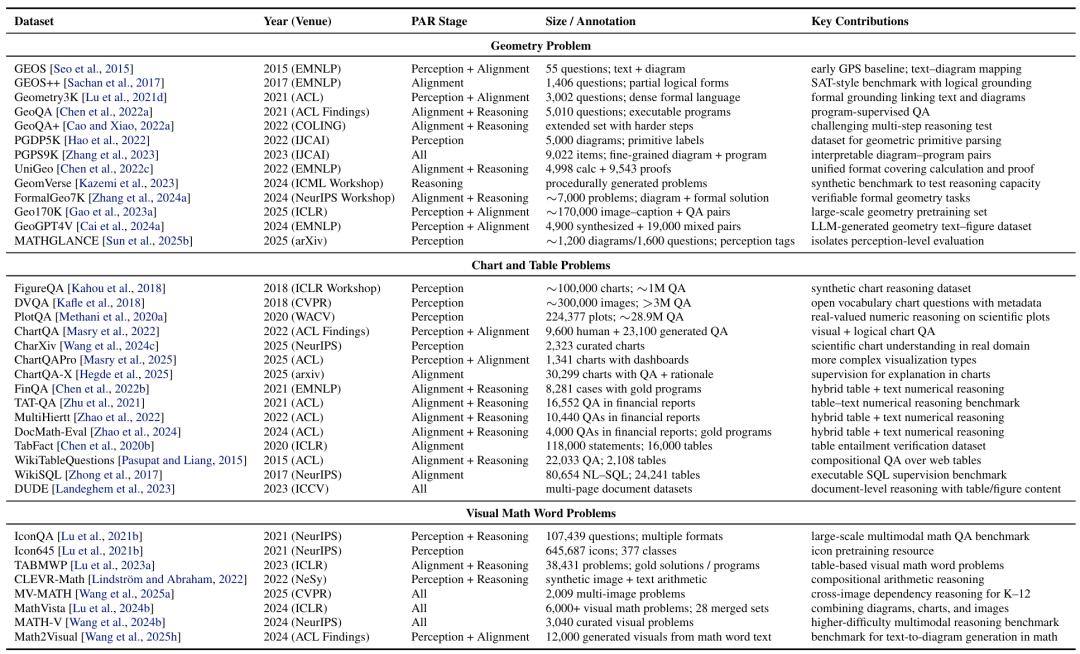
第一类是几何问题。几何推理要求模型同时理解文字描述和图形结构,并完成数值求解或形式证明,代表性方向包括从早期的 GEOS,到 Geometry3K、GeoQA、E-GPS、Pi-GPS、FormalGeo、AlphaGeometry 等系统和数据集。
第二类是图表与表格问题。这类任务要求模型理解图表布局、坐标轴、图例、表格行列和数值关系,再完成逻辑或数值推理,代表性基准包括 ChartQA、PlotQA、FinQA、TAT-QA、MultiHiertt、DocMath-Eval、CharXiv 和 ChartQAPro 等。
第三类是视觉数学应用题。此类任务更贴近教育和日常场景,模型需要从图像中识别对象、数量和空间关系,并结合自然语言完成计算,代表性数据集包括 IconQA、CLEVR-Math、TABMWP、MathVista、MATH-V、MV-MATH 等。
当前模型还有哪些问题?
尽管多模态大模型进展很快,但研究团队也指出,多模态数学推理仍存在几个关键瓶颈。
- 感知不够精确。当前模型仍可能误读几何元素、图表布局和表格结构,在低清晰度、复杂布局或风格变化下尤其明显。
- 对齐不够稳定。不同任务中使用的符号语言、单位约定和中间表示高度碎片化,导致模型很难在不同领域之间迁移。
- 长链推理容易偏离视觉证据。模型在生成多步推理时,可能逐渐忘记图像信息,转而依赖语言先验,产生看似流畅但并不忠实于视觉内容的推理链。
- 评测仍不够充分。只看最终答案会掩盖大量过程错误,而过程级和可执行级评测虽然更可靠,却需要更高质量的数据标注、验证器和形式化接口。
未来:让模型不仅会答题,还能被检查、被教学、被部署
研究团队认为,多模态数学推理的未来方向并不只是刷高 benchmark 分数,而是构建真正可靠、可解释、可验证的数学智能系统。
在教育场景中,这类系统可以用于智能辅导、自动批改、定理解释和过程反馈,帮助学生理解每一步为什么成立,而不是只给出答案。
在无障碍场景中,多模态数学系统可以把视觉数学内容转化为语音、盲文或其他可访问形式,帮助视障用户理解图形、公式和图表。
在专业场景中,结合 AR/VR、工程设计、可视化分析和符号求解器,多模态数学推理系统有望成为交互式、可验证的专业工具。
下一阶段的目标,是让多模态模型不仅能“看图做题”,还要能说明它看到了什么、如何对齐证据、怎样推理,以及这个过程能否被验证。
结语
多模态数学推理处在视觉理解、符号推理和大模型能力交汇的位置。它要求模型既能感知图像中的结构,又能把视觉证据转化为可推理的表示,并在此基础上完成稳定、可检查的数学推理。
这篇综述的价值在于,它没有只罗列数据集和模型,而是用 PAR 和 APE 两套框架重新组织了整个领域:前者回答模型如何完成推理,后者回答我们如何评估推理是否可靠。
从这个角度看,多模态数学推理的发展,也许正从“追求最终答案正确”转向“追求全过程可信”。这对于教育、科研、工程和可解释 AI 系统,都具有重要意义。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢