
点击蓝字
关注我们

美国前沿 AI 实验室 Anthropic 近期发表政策立场文件《2028:全球 AI 领导权的两种情景》(2028: Two scenarios for global AI leadership)。文件勾勒了截至 2028 年全球前沿 AI 发展可能走向的两种相互排斥的路径,并据此向美国政府提出具体政策建议。
该文件没有署名具体作者,代表的是Anthropic的机构立场,同时延续了其首席执行官达里奥·阿莫代伊(Dario Amodei)此前在公开场合的相关论述。这份文件属于政策游说文件(policy paper),而非学术研究。本文整理了Anthropic的核心论点与建议,对其中已在业内引发争议的判断做了明确标注,并补充了其他智库的立场及公开数据作为对照坐标。(本文是对公开内容的整理与精编,不代表本研究院立场。)

1
Anthropic 看 2028:两种可能
“全球前沿 AI 的发展正处于一个关键的政策窗口期。”文件指出,“美国及其盟友当前在前沿模型能力、算力供给、半导体制造等关键维度仍占据领先位置,但这一领先并不能自动延续。”
据此,Anthropic 提出一个具体的政策目标——通过收紧出口管制、遏制蒸馏行为,确保美国到2028年时能够稳住12至24个月的前沿模型能力领先优势。文件多处反复强调这一窗口的时效性:“相关政策若不在近期落地,这一窗口期将逐渐收窄直至关闭。”
据此,Anthropic向美国决策者发出核心呼吁——“今年政策制定者的决定将决定变革性 AI 的未来”。(The decisions made by policymakers this year will determine the future of transformative AI)
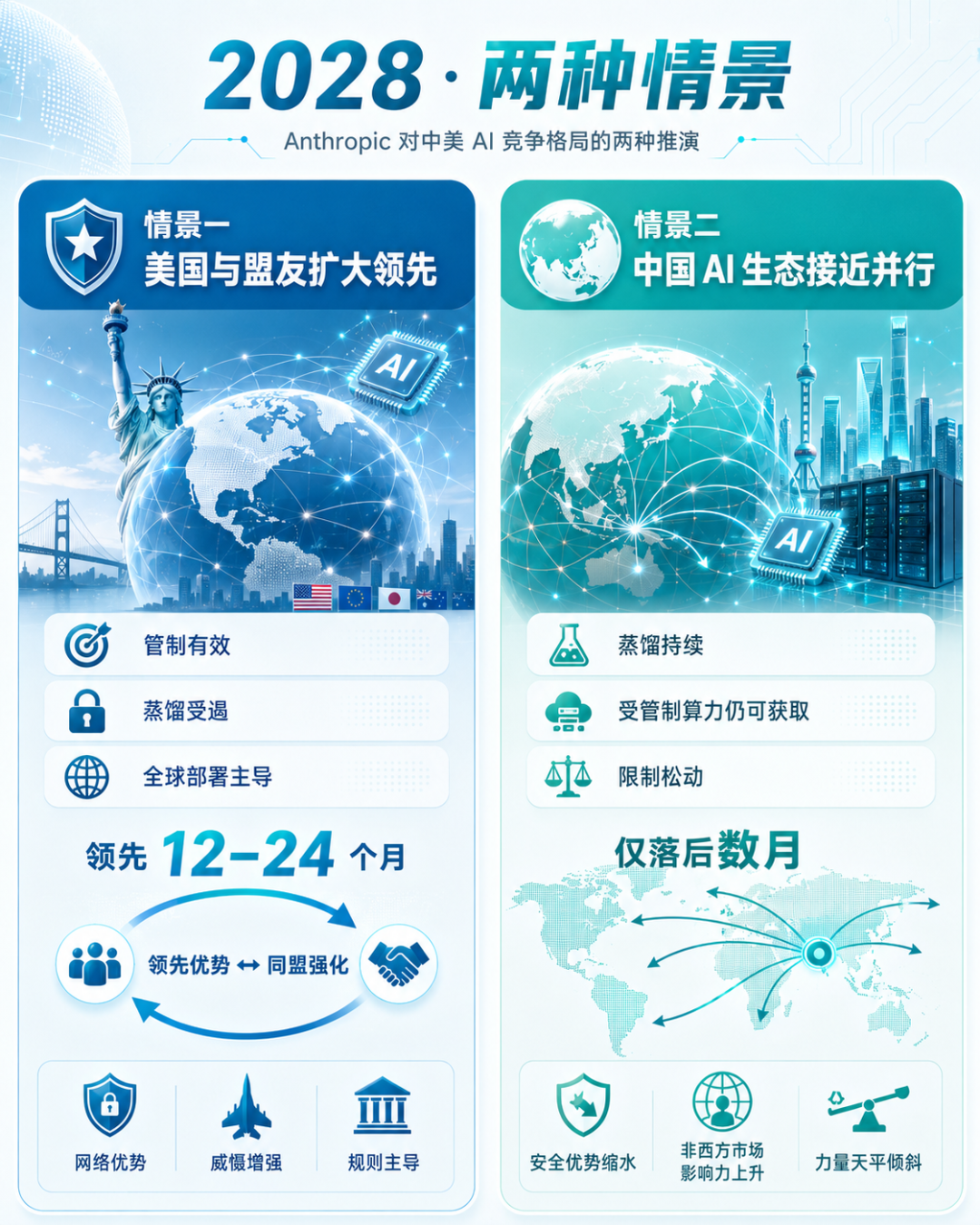
情景一 美国主导秩序
美国前沿 AI 模型在智能水平上"领先 12 至 24 个月,且差距持续扩大";全部前沿 AI 实验室位于美国本土;美国 AI 主导全球部署。Anthropic 指出将形成一个自我强化的循环——美国的 AI 领先使更多国家选择加入美国主导的 AI 同盟,扩大后的同盟反过来巩固美国的领先。在这一情景下,Anthropic 推断美国将获得网络优势与对中国军事行为的威慑能力,并实现"全球秩序在 AI 转型期由民主国家主导"的格局。
情景二 力量天平倾斜
中国前沿实验室的模型"仅落后美国数月";中国通过华为、阿里巴巴等海外基础设施,向全球南方推出更便宜、更易部署的"够用"模型;通过"AI+"政策推动国内 AI 部署进度领先于美国。Anthropic 据此推断——美国将丧失通过 AI 转型期可能获得的安全优势;中国在全球非西方市场获得显著影响力;"全球力量天平向中国倾斜"。
2
Anthropic 的三项政策建议
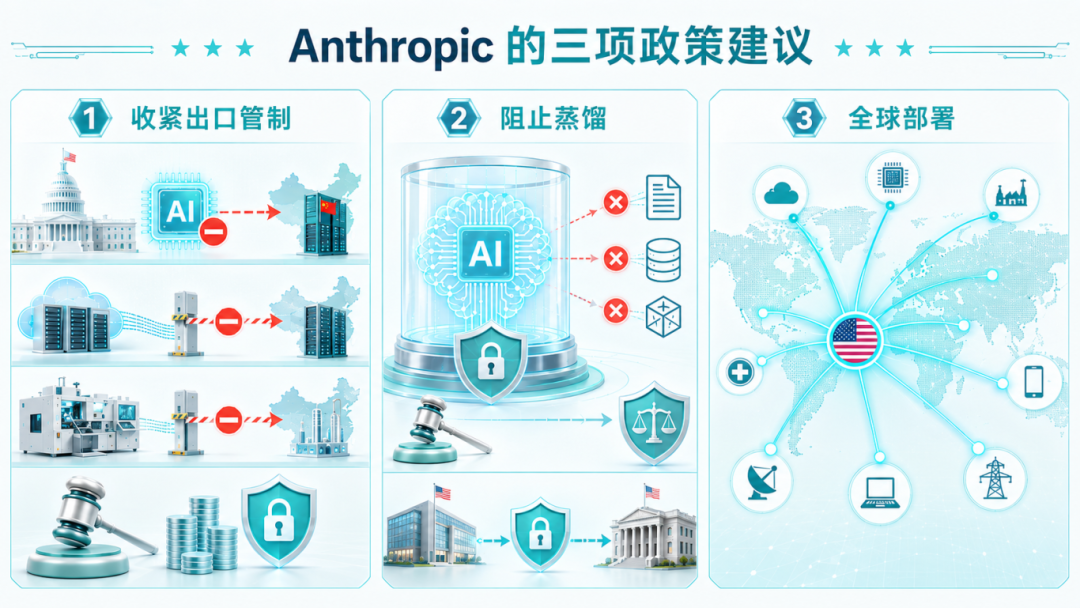
为了实现上述情景一,Anthropic 向美国政府提出三项具体政策主张。
主张一 · 收紧对华芯片出口管制
打击芯片走私、关闭海外数据中心远程访问、半导体制造设备等相关漏洞,并提升执法预算。Anthropic 援引美国国会众议院近期相关法案的投票数据,主张参议院尽快跟进。
主张二 · 以立法与执法手段阻止蒸馏行为
界定模型蒸馏行为的违法性,限制中国前沿实验室对美国 AI 模型的访问,并推动美国 AI 实验室与政府在威胁情报与安全技术层面的共享。主张三 · 推动美国 AI 在全球范围的部署
加速美国 AI 硬件与模型在全球范围的采用,以‘锁定’市场份额。
3
事实与立场之间:争议点
(一)蒸馏:是"产业间谍活动",还是合同违约?
Anthropic 在文件中将蒸馏行为定性为"一项对美国长期国家安全利益至关重要的技术的系统性产业间谍活动"。
这一定性在业内存在明显争议。本研究院此前已编译过乔治城大学安全与新兴技术中心(CSET)临时执行主任 Helen Toner 于4月22日提交美国参议院的书面证词明确指出——"蒸馏作为一项技术本身合法且普遍,Google 的 Gemini Flash 系列就是由更大的 Gemini 模型蒸馏而来。蒸馏应被认定为合同违约,并非严格法律意义上的"窃取"(theft)。两者在法律责任、举证标准与可适用救济上存在本质区别。"
(二)开放权重:是 AI 安全的解药,还是风险源?
Anthropic 在文件中提到:“一旦模型以开放权重发布,已有的安全保障措施就可被移除”,并据此将开放权重发布列为全球 AI 安全的潜在风险。
这一判断与业内另一种主流声音直接对立。NVIDIA 首席执行官黄仁勋、Meta 首席 AI 科学家 Yann LeCun、法国 Mistral AI、Hugging Face 等多家机构与行业领袖长期主张:开放权重恰恰是提升 AI 安全的重要路径——更多研究者得以审视模型行为,避免少数闭源公司形成监督垄断,推动安全研究走向开放。
需要指出的是,Anthropic 自身采取闭源订阅的商业模式。其在开源与闭源安全议题上的立场,与其商业模式选择高度相关。
(三)94% vs 8%:单次测试难以说明问题
Anthropic 援引美国 NIST 下属人工智能标准与创新中心(CAISI)的一项评估指出,在一种常见越狱技术下,DeepSeek R1-0528 模型对 94% 的明显恶意请求作出响应,而美国参考模型的响应率仅为 8%。文件据此推断,中国前沿实验室在 AI 安全实践上与美国同行存在显著差距。
然而,该数据来自单一测试方法、单一时间点的评估。不同模型版本、不同测试场景下的结果可能存在显著差异。(来源:US Center for AI Standards and Innovation (CAISI), 2026 单次评估。)
编辑|李承兴
审核|赵杨博
终审|梁正 王净宇





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢