

新智元报道

【新智元导读】多模态大模型越来越会「看图、读表、解题」,但一个关键问题长期存在:模型到底缺什么能力?下一轮训练又该重点补哪里?
新智元报道
新智元报道
【新智元导读】多模态大模型越来越会「看图、读表、解题」,但一个关键问题长期存在:模型到底缺什么能力?下一轮训练又该重点补哪里?
过去,多数多模态大模型的训练方式更像「题海战术」——准备一批固定数据,不断重复训练;或者继续扩充题目,再进行新一轮微调。这样的方式确实能带来性能提升,但也存在两个明显问题。
首先,缺少对模型能力的精准诊断。模型可能在数学图表、OCR、空间推理等长尾任务上存在短板,但研究者往往很难准确定位这些问题,更难有针对性地补强。
其次,训练数据里的视觉内容长期缺乏真正扩展。很多工作虽然不断改写文本问题,但配套图像依然来自有限的数据集合,模型看到的「视觉世界」其实并没有变得更加丰富。
结果就是,模型在高频任务上越练越熟,在真正复杂、稀有、模型本身并不擅长的任务上却很容易停滞,甚至出现「越训练越退步」的现象。
针对这一问题,来自北京大学、山东大学的研究团队提出了一种新的多模态大模型训练框架:Diagnostic-driven Progressive Evolution(DPE),该工作一经发布便引发广泛关注,并登上Hugging Face Daily Papers热度日榜第二,周榜第五。

论文链接:https://arxiv.org/abs/2602.22859
代码:https://github.com/hongruijia/DPE
DPE的核心思想很直观:不要让模型盲目刷题,而是先测试、找错因,再围绕短板生成训练数据,最后用强化学习做针对性提升。
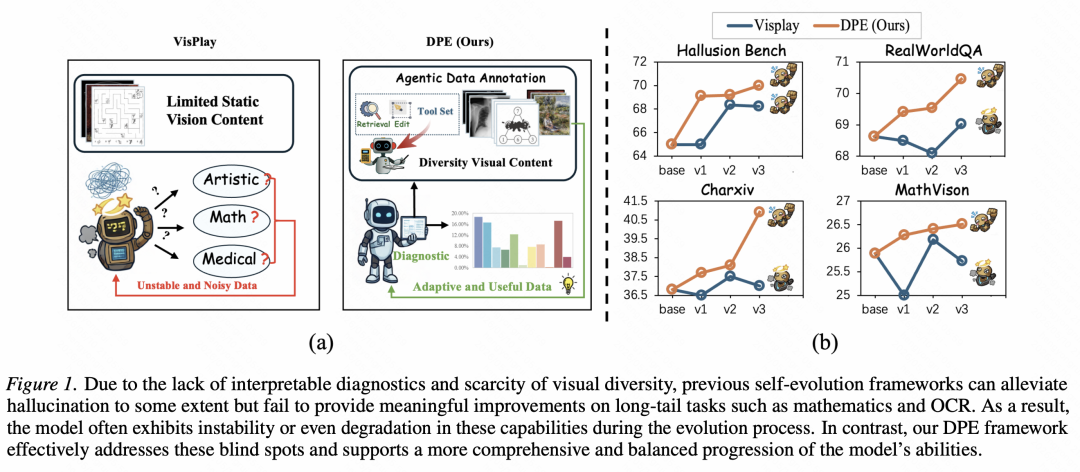
换句话说,它把人类学习中的「查漏补缺」搬进了多模态大模型训练:模型每进化一轮,都要先接受诊断;
诊断系统会判断它在哪些能力维度上薄弱,比如数学公式、图表理解、OCR、医学图像、空间地图、多图对齐等;
随后,多智能体系统会根据这些诊断结果去检索、编辑和构造新的图像-问题-答案样本;
最后,模型基于这些更有针对性的样本完成强化学习更新,并进入下一轮诊断。

DPE的整体流程可以概括成三步:诊断、生成、训练。
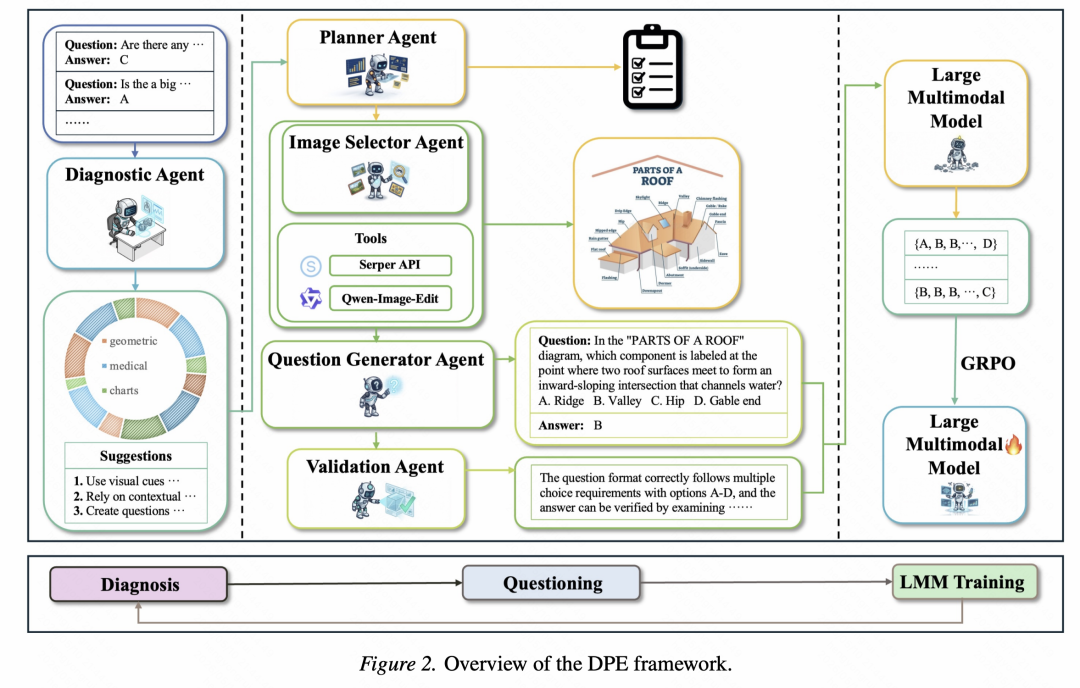
第一步是诊断。
系统先让当前模型做一组覆盖不同能力维度的多模态题目,并分析失败样本。诊断模块会输出每一类任务的采样比例,也就是下一轮训练应该把更多数据预算投向哪些弱项。
具体而言,论文将多模态逻辑推理划分为 12 个能力维度,包括几何图像、医学图像、统计图表、文本密集图像、流程图、数学公式、空间地图、自然场景、日常物体、艺术作品、建筑图像以及其他类别。每一轮训练开始前,DPE 会从诊断池中抽取 200 个样本,让当前模型作答,再由诊断智能体对答案的推理步骤和最终结果进行评估。
诊断的目标不只是打分,而是生成一份结构化报告:哪些类别准确率低?错误主要集中在哪些模式?下一轮数据应该增加哪类样本?问题难度和答案格式又该如何设计?
例如,诊断系统可能发现模型在图表任务中经常忽略坐标轴单位,在 OCR 任务中容易漏掉细小文字,在数学题中会跳过关键推导步骤,在多图任务中常常把实体对应关系搞错。这些错误模式会被直接写入下一轮数据生成指令。
第二步是生成。
DPE 不是简单改写原有问题,也不是只在固定图像上换问法,而是引入一个多智能体问题生成系统。这个系统由四类智能体组成:Planner Agent、Image Selector Agent、Question Generator Agent 和 Validation Agent。
Planner Agent 负责把诊断报告转化成可执行的数据生成计划;
Image Selector Agent 根据计划从外部图像池检索图片,并可借助图像编辑工具进行适度重组和增强;
Question Generator Agent 负责围绕图像生成问题和参考答案;
Validation Agent 则像一道质量闸门,检查样本是否类别一致、信息完整、答案可验证、格式合规。
这种设计解决了自进化训练中的一个关键瓶颈:模型不能只在旧图上自问自答,而要不断接触新的视觉内容。
更重要的是,这套生成系统并不是让智能体「自由发挥」,而是把诊断结果转化成一组可执行约束:每一轮先确定各能力类别的生成配额,再由 Planner 规定图像需求、问题类型、答案格式和难度方向;
Image Selector 从外部图像池检索、筛选,并在需要时进行裁剪、拼接和重组;
Validation Agent 则对类别一致性、信息完整性、答案可验证性和格式合规性逐项把关。这样生成出来的样本既能对准模型当前弱项,又能控制质量和分布,避免新数据把训练带偏。
第三步是训练。
DPE 使用带可验证奖励的 GRPO 强化学习来更新目标多模态大模型。一个重要细节是,DPE 会过滤掉太简单或太难的样本,优先保留「中等难度」的题目。直观来说,模型已经会的题没有太大学习价值,完全不会的题又可能带来噪声;最适合训练的是那些模型有机会学会、但当前还不稳定的样本。
完成一轮更新后,模型会再次进入诊断环节。于是,DPE 形成了一个螺旋式迭代:模型暴露盲点 -> 系统生成针对性数据 -> 强化学习修补短板 -> 再诊断新的盲点。

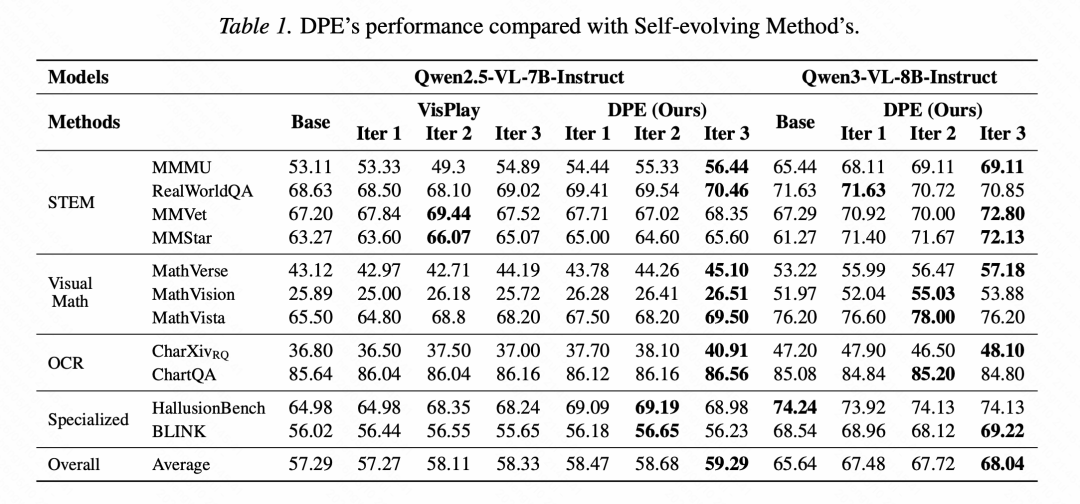
研究团队在两个开源多模态大模型上验证了 DPE:Qwen2.5-VL-7B-Instruct 和 Qwen3-VL-8B-Instruct。评测覆盖 11 个具有挑战性的多模态基准,包括 STEM、视觉数学、OCR、多图理解和幻觉抑制等方向。
主实验结果可以概括为三点。
第一,DPE 带来了更全面的能力提升。
在 Qwen2.5-VL-7B-Instruct 上,DPE 经过三轮迭代后,整体平均分从 57.29 提升到 59.29。其中,MMMU 从 53.11 提升到 56.44,CharXivRQ 从 36.80 提升到 40.91,MathVista 从 65.50 提升到 69.50,覆盖 STEM、OCR 和视觉数学等多个方向。
第二,DPE 的训练动态更稳。
相比 VisPlay 在部分基准上出现波动甚至回退,DPE 在三轮迭代中整体趋势更平滑。例如在 Qwen2.5-VL-7B-Instruct 上,DPE 的 MMMU 从 54.44 连续提升到 55.33、56.44;CharXivRQ 也从 37.70、38.10 继续提升到 40.91。这说明诊断闭环不只是带来短期增益,也能降低自进化训练中常见的分布漂移和性能震荡。
第三,DPE 具有可迁移性。
在更强的 Qwen3-VL-8B-Instruct 上,DPE 仍然带来明显收益:整体平均分从 65.64 提升到 68.04,MMMU 从 65.44 提升到 69.11,MMStar 从 61.27 提升到 72.13。这意味着,DPE 并不是只适用于某一个基座模型,而是可以作为一种更通用的诊断驱动训练范式。
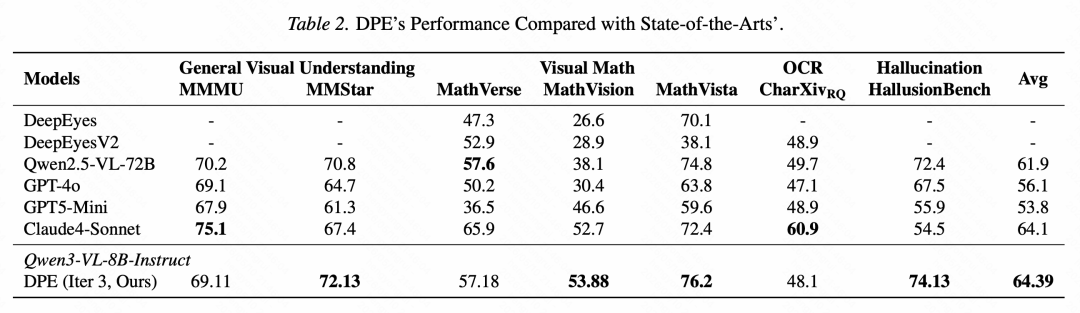
更值得注意的是,在论文报告的若干对比中,DPE 增强后的 Qwen3-VL-8B-Instruct 在所选 7 项指标上的平均分达到 64.39,高于 Qwen2.5-VL-72B 的 61.9 和 GPT-4o 的 56.1,也略高于 Claude4-Sonnet 的 64.1。这表明,在复杂多模态推理任务中,训练数据的针对性和质量,有时比单纯扩大参数规模更关键。

DPE 与传统静态数据训练的最大区别,在于它不是固定一批数据让模型反复学习,而是让数据分布随着模型能力变化而变化。
如果模型已经掌握了某类任务,DPE 就会减少这类样本的比例;如果诊断发现模型在某个长尾能力上持续薄弱,系统就会把更多生成预算分配给它。
这正像一位经验丰富的老师:不会让学生永远做同一种题,而是根据每次考试暴露出来的问题,调整下一次练习的题型和难度。
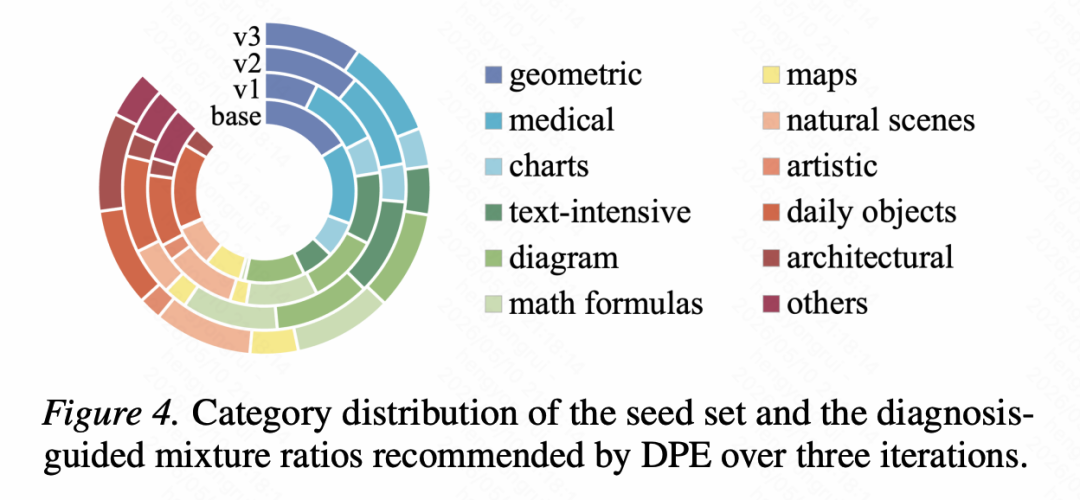
可视化结果也显示,DPE 的诊断模块并不是照搬种子数据的原始类别分布,也不是平均采样,而是会根据上一轮失败模式动态提高弱项类别比例。
例如,在第一轮中,DPE增加了文本密集图像和图表相关样本,CharXiv 准确率随之从 36.8 提升到37.7,并在后续迭代中继续提升;在第二轮中,系统增加了数学公式与符号推理相关样本,MathVision、MathVerse 和 MathVista 的表现也随之改善。这说明,DPE的提升并不只是来自「多造了一些题」,而是来自「知道该造什么题」。
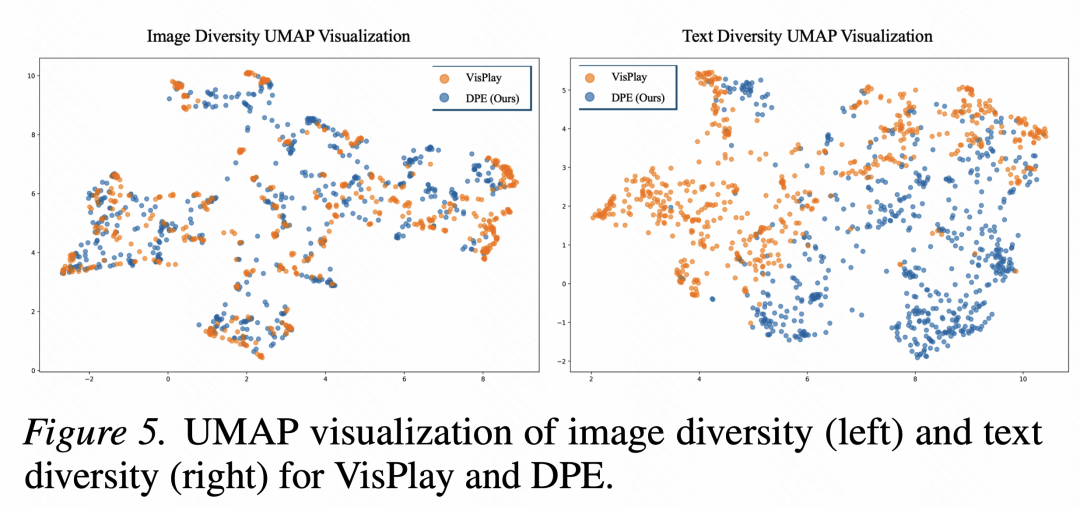
论文中的 UMAP 可视化进一步说明了「覆盖范围」的差异:VisPlay 主要围绕固定图像集演化,样本分布更容易集中在已有视觉区域;DPE 通过外部图像检索和编辑,在图像空间中覆盖了更宽的区域,并形成更多非重叠子簇。文本侧也呈现类似趋势,DPE 的问题分布覆盖更广,说明它不只是把旧图重新问一遍,而是在视觉内容和问题语义两个层面同时扩展训练分布。

DPE 的另一个亮点是数据效率。
论文在极低数据条件下评估 DPE:框架只使用 Vision-SR1-47K 中前 1K 样本作为种子数据;多智能体系统随后生成千级规模的训练样本。在与静态训练的对比中,DPE 使用约 3K 个迭代生成样本,就超过了使用 47K 静态数据的 Vision-R1。
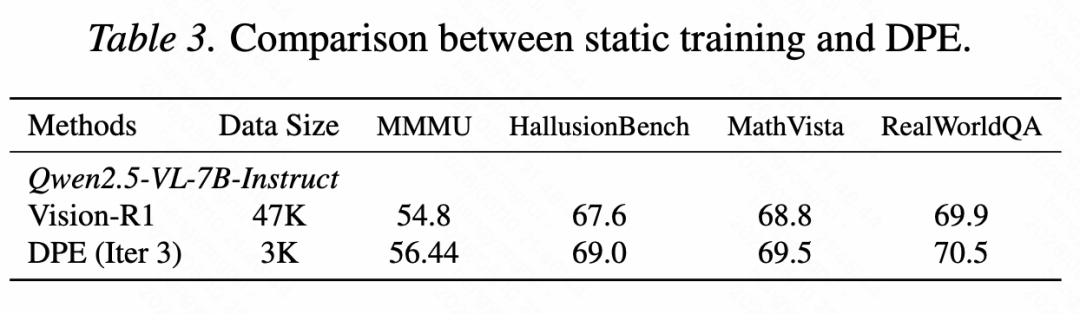
这组结果说明,在低数据预算、静态数据覆盖不足的情况下,真正影响训练收益的往往不是样本总量本身,而是数据是否能随模型短板动态调整。
静态数据会让模型在高频模式上很快饱和,却无法持续覆盖长尾弱项;
DPE 通过诊断模块持续发现新问题,把有限的数据预算集中投向尚未解决的能力缺口,从而弥补固定数据分布带来的差距,并获得更稳的提升。
为了验证诊断模块是否真的关键,论文还做了消融实验:移除诊断模块后,仍然进行三轮训练。
结果显示,没有诊断时,迭代收益明显变小,也更不稳定。在 CharXiv 上,完整 DPE 从 36.8 连续提升到 37.7、38.1、40.91;而去掉诊断后,结果基本停留在基线附近,分别为 36.8、36.7、37.5、36.7,甚至出现先升后降。
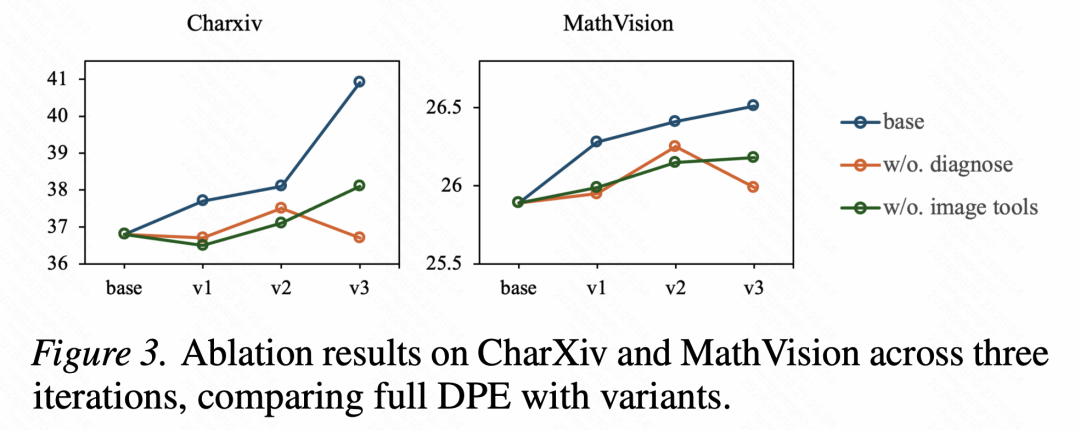
这意味着,如果没有明确的错误归因,模型训练很容易重新回到「随机刷题」状态:看似也在生成新数据,但并没有真正对准能力缺口。
另一个消融实验则验证了图像检索和编辑工具的重要性。移除图像工具后,模型更容易提前进入平台期,尤其在OCR和图表相关任务上收益受限。在CharXiv上,完整DPE三轮后达到40.91,而去掉图像工具后只有38.1,下降2.81 分。
原因也很直观:如果只在同一批或相似图像上不断变换文字问题,模型可能记住了狭窄的布局、字体和页面结构,却没有真正学会应对复杂多变的现实视觉场景。
DPE 通过检索外部图像并进行适度编辑,显著扩展了视觉多样性。

DPE 的意义,不只是提出一个新的训练管线。更重要的是,它把一个长期被忽视的问题摆到台前:大模型训练不应只是自动生成更多数据,而应具备诊断能力。
对于多模态大模型而言,真实世界任务分布是开放的、长尾的、不断变化的。模型今天学会了读普通图表,明天可能需要理解医学影像;今天能处理单张图片,明天可能要比较多张图片中的细微差异;今天在标准测试集上表现不错,明天面对噪声、遮挡、低分辨率和复杂排版时仍可能失败。
因此,未来的训练系统需要像老师一样,持续回答三个问题:模型现在会什么?不会什么?下一步最该练什么?
DPE给出了一个可扩展答案:通过诊断机制暴露盲点,通过多智能体系统生成弱项导向的数据,通过强化学习完成针对性更新,再用新一轮诊断继续校准方向。
论文作者也指出,未来可以继续引入更丰富的诊断信号,扩展更多模态数据来源,并探索更复杂的多智能体协作策略。这将推动多模态大模型从「被动吃数据」走向「主动发现问题、主动补齐能力」的新阶段。
如果说过去的大模型训练像是在盲目扩充题库,那么DPE更像是在给模型配备一套持续进化的错题本。
这本错题本,不只是记录错误,更会决定下一轮该学什么、怎么学、学到什么程度。
参考资料:https://arxiv.org/abs/2602.22859
编辑:LRST


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢