

我们推出了人工智能协作数学家(AI co-mathematician),这是一个供数学家交互式地利用人工智能代理开展开放式研究的工作平台。人工智能协作数学家经过优化,能够为数学工作流程的探索性和迭代性提供全方位支持,包括构思、文献检索、计算探索、定理证明和理论构建。该系统提供了一个异步的、有状态的工作空间,可以管理不确定性、完善用户意图、跟踪失败的假设并输出原生数学成果,从而模拟人类的协作工作流程。在早期测试中,人工智能协作数学家帮助研究人员解决了开放性问题,确定了新的研究方向,并发现了被忽略的文献。除了展示人工智能辅助数学发现的高度交互式范式外,人工智能协作数学家还在一些高难度问题求解基准测试中取得了最先进的成果,包括在 FrontierMath Tier 4 测试中获得 48% 的分数,这是所有受测人工智能系统中的新高分。

论文:AI co-mathematician: Accelerating mathematicians with agentic AI
单位:Google DeepMind, Google
发布日期:2026.05.07
请索引第94篇论文
 |  |
AI联合数学家:当AI成为你的科研合伙人,数学研究范式将被彻底颠覆
数学研究不再是孤独的探索,而是一场与AI智能体的深度协作。
2026年5月7日,Google DeepMind团队在arXiv上发布了一篇题为《AI Co-Mathematician: Accelerating Mathematicians with Agentic AI》的论文,正式推出了“AI联合数学家”系统。
这个系统在号称“未来几十年AI可能都无法解决”的最难数学基准FrontierMath Tier 4上取得了48%的准确率,刷新了所有AI系统的最高纪录。
更令人振奋的是,牛津大学数学家Marc Lackenby已经借助这个系统,解决了群论领域数十年无解的第21.10号问题。
01 数学研究的真实困境
数学研究在大众眼中,往往是数学家们在黑板上写下几行优雅的公式,然后宣布某个定理被证明。但这幅画面背后,隐藏着一个截然不同的现实。
一位数学家的日常,更像是一位侦探在昏暗灯光下翻阅厚厚的案卷——翻出来的,十有八九是死路,偶尔才能拼出一条线索。
他们可能花上整个上午,把一个直觉性的猜想拆开来反复端详,发现它在某个特殊情况下完全不成立,于是推倒重来。
可能花上几天,在文献堆里找一篇二十年前的老论文,就为了确认某个引理的精确条件。可能写满好几页草稿,最后发现逻辑链在第三步就断了。
这些过程——试错、反驳、重新定义、文献追溯——才是数学研究的真实面貌,只是它们从来不出现在最终发表的论文里。
近年来,人工智能在数学领域的进步确实令人瞩目。能解奥数题的模型、能辅助写Lean形式化证明的系统、能自动搜索算法结构的进化框架,一个接一个涌现出来。
但这些工具都有一个共同的局限:它们擅长“解一道题”,却不擅长“陪一位数学家做研究”。
02 从解题工具到研究伙伴
AI联合数学家不是另一个更聪明的聊天机器人,而是一个专门为数学家的真实工作方式量身设计的“工作台”。
它的目标不是取代数学家,而是像一位真正的研究伙伴那样,陪着数学家一起摸索、试错、讨论、推进。
系统摒弃了传统的单轮对话聊天模式,采用层级代理机制。用户通过Chat直接与“项目协调员”沟通,由其将目标拆解并分发给并行的“工作流协调员”,最后由“专门子智能体”执行具体的文献查阅、代码编写和逻辑推理。
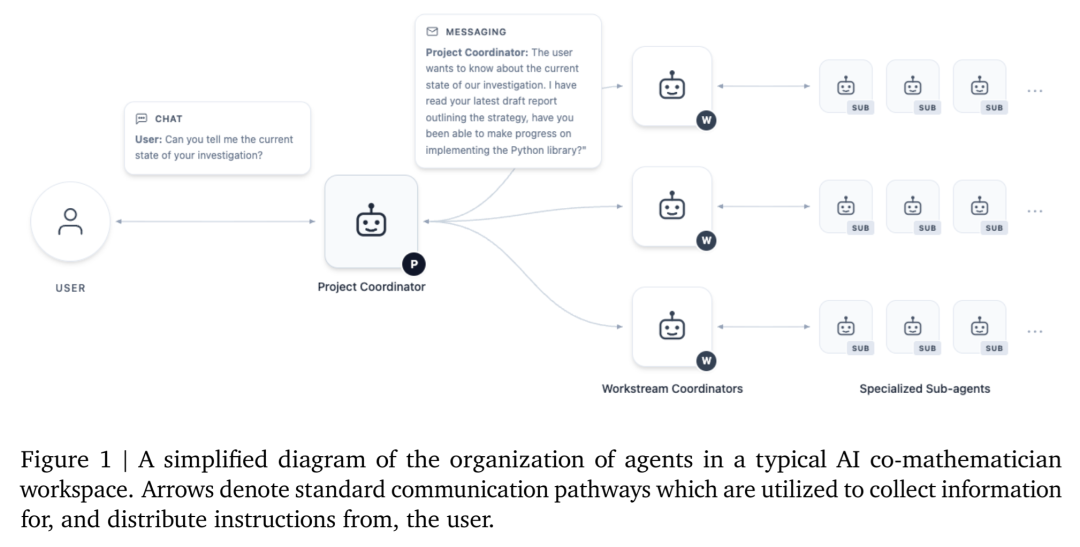
AI Co-Mathematician 多智能体协作架构蓝图
在100道未泄露的专家级数学题测试中,搭载多智能体架构的AI Co-Mathematician准确率达到87%,对单次调用的Gemini 3.1 Pro和Gemini 3.1 Deep Think形成了降维打击。
03 七条设计原则
研究团队在动手写一行代码之前,先花了相当多的精力思考数学研究的本质。他们提炼出了七条设计原则,这七条原则共同构成了整个系统的哲学基础。
第一条原则叫做“超越证明来拥抱数学”。哲学家希拉里·普特南曾经指出,把数学简化为纯粹的形式逻辑,是对数学“准经验性”本质的忽视。
数学家的日常工作包括提炼研究问题、梳理文献、头脑风暴、运行大量数值模拟来建立直觉等等,这些活动构成了研究的主体,而最终的形式证明只是其中一个环节。
第二条原则是“支持意图的迭代精化”。数学家通常在项目开始时并不清楚自己确切想做什么,问题的精确表述本身就是研究的一部分。
格奥尔格·康托尔的那句名言说得很清楚:“在数学中,提出一个问题的艺术比解答它更有价值。”
第三条原则是“产出原生数学产物”。数学家习惯于LaTeX格式的草稿、带有边注的工作文件、有内部引用的论文初稿。
系统的输出不是聊天消息,而是一份活生生的“工作论文”,有正文、有边注、有版本历史,和数学家自己手写的草稿一样自然。
第四条原则是“支持异步交互与灵活引导”。数学研究不是线性的,一个人同时在脑子里跑着好几条思路是常态。
这个系统在后台可以同时运行多个并行的“工作流”,处理不同的子问题,而数学家可以随时介入、调整方向,而不是呆呆等着系统“想完”再给结果。
第五条原则是“通过渐进式披露管理认知负载”。一个长时间运行的研究项目会积累大量信息:高层策略、低层执行日志、多个并行分支的进展、失败的尝试记录。
如果全部平铺在一个聊天窗口里,很快就会让人不知所措。系统按照代理层级来组织信息:用户主要与最顶层的“项目协调代理”交互,后者会过滤掉低层代理的执行细节。
第六条原则是“追踪、管理和传达不确定性”。数学需要极高的严谨性,一个有漏洞的引理可能让整篇论文崩塌。
语言模型的输出天然带有不确定性,不能全盘信任。这个系统不是假装不确定性不存在,而是把它当成一个需要被管理的核心变量。
第七条原则是“保存失败探索的历史”。在数学研究中,知道“什么不行”往往和知道“什么行”同样重要。
这个系统把失败的工作流和走到死路的探索,作为头等重要的永久记录保存下来,而不是悄悄重启、抹去痕迹。
04 系统架构:一支无形的研究团队
整个系统的核心比喻是“一支研究团队”。数学家与团队里最高层的“项目协调代理”交谈,就像与一位经验丰富的合作者讨论研究方向。
这位协调者不会自己去查文献、写代码或推证明,而是把具体任务分派给下层的“工作流协调代理”,每个工作流对应一个特定的研究目标。
工作流协调者又可以进一步创建更专门的“子代理”来执行具体任务,比如文献检索子代理、编程子代理、Gemini Deep Think证明子代理等。
所有这些代理共享一个文件系统,通过内部消息系统沟通,并将各自的工作成果写入共享存储空间。
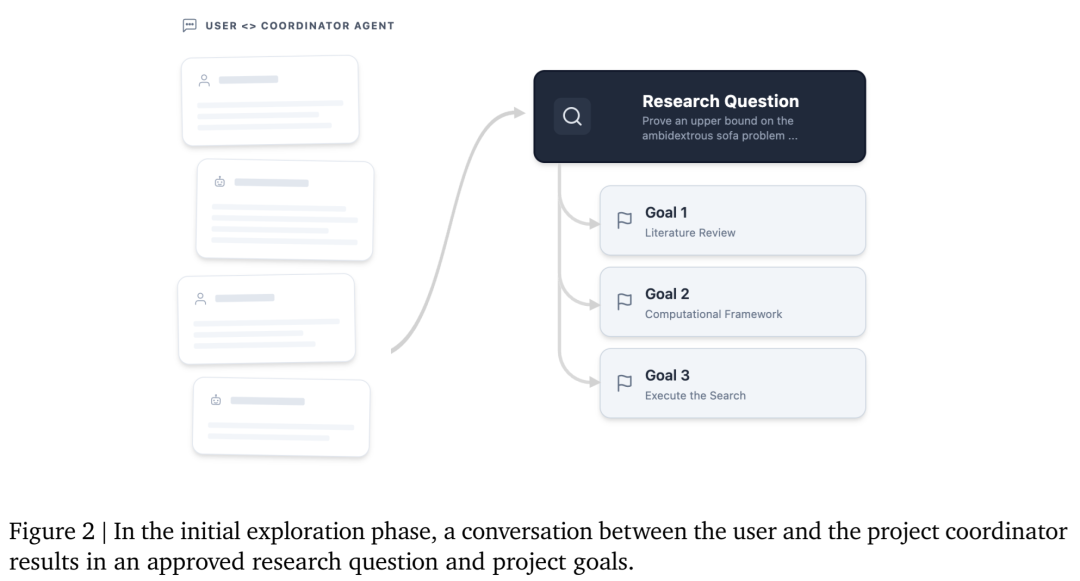
一旦研究问题和目标被确定,项目协调者就会安排各个工作流,以推动目标的实现
特别重要的一点是:数学家在整个过程中随时都可以介入。系统不会把数学家“锁在门外”等待结果,而是允许他随时通过聊天界面向项目协调代理发送指令、提供思路、或者调整研究方向。
这种双向互动是系统设计的核心——当系统遇到它无法自行解决的困难时,会主动浮现警告,明确告诉数学家“我们卡在这里了,你能帮我们想一个更好的方法吗?”

05 真实案例:移动沙发问题的探索
研究团队用一个具体的数学问题来演示系统的工作流程,这个问题来自计算几何领域:在走廊里移动沙发时,能绕过左手边和右手边直角转弯的最大沙发面积是多少?
这是一个经典数学问题的变体,研究团队之前已经用AlphaEvolve研究过它的下界,但上界仍然悬而未决。
数学家通过聊天界面上传了相关论文并说明想法:“我想研究这篇论文里讨论的移动沙发问题变体的上界证明。”
值得注意的是,项目协调代理没有立刻开始工作,而是先开启了一场对话,充当“声音板”。它回应道:“从文章中看,Baek已经证明经典沙发问题中Gerver的下界是精确的。但其他两个变体的上界仍然是开放问题……你想专注于其中一个,还是两个都研究?你是想证明某个特定下界是精确的,还是只要建立任何一个新的严格上界就行?”
经过几轮来回讨论,双方达成一致,明确研究目标后,系统才开始分配任务。
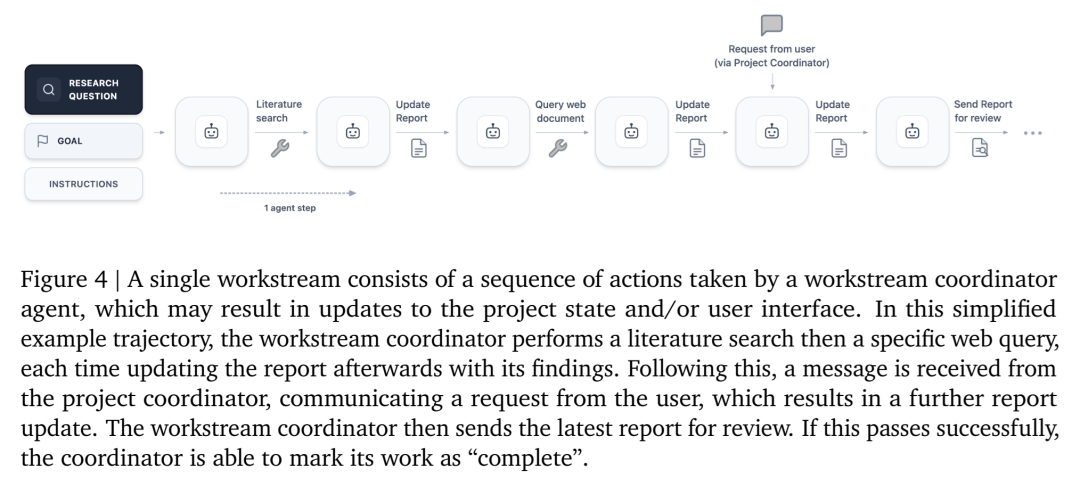
06 性能表现:刷新最难数学基准
在基准测试上,AI Co-Mathematician在FrontierMath Tier 4上取得了48%的准确率,创下了AI在该基准上的新SOTA分数。
具体来说,在去掉2道公开样例题后,它答对了48道非公开题中的23道。
FrontierMath是Epoch AI开发的高难数学基准,共收录350道原创题目,覆盖现代数学多个分支。其中最难的Tier 4只有50题。
Epoch团队描述,这一层级里的部分问题,AI可能在未来数十年内仍无法解决,人类专家解出一道题通常也需要数天。
相比之下,其基座模型Gemini 3.1 Pro在同一测试中的准确率仅为19%。
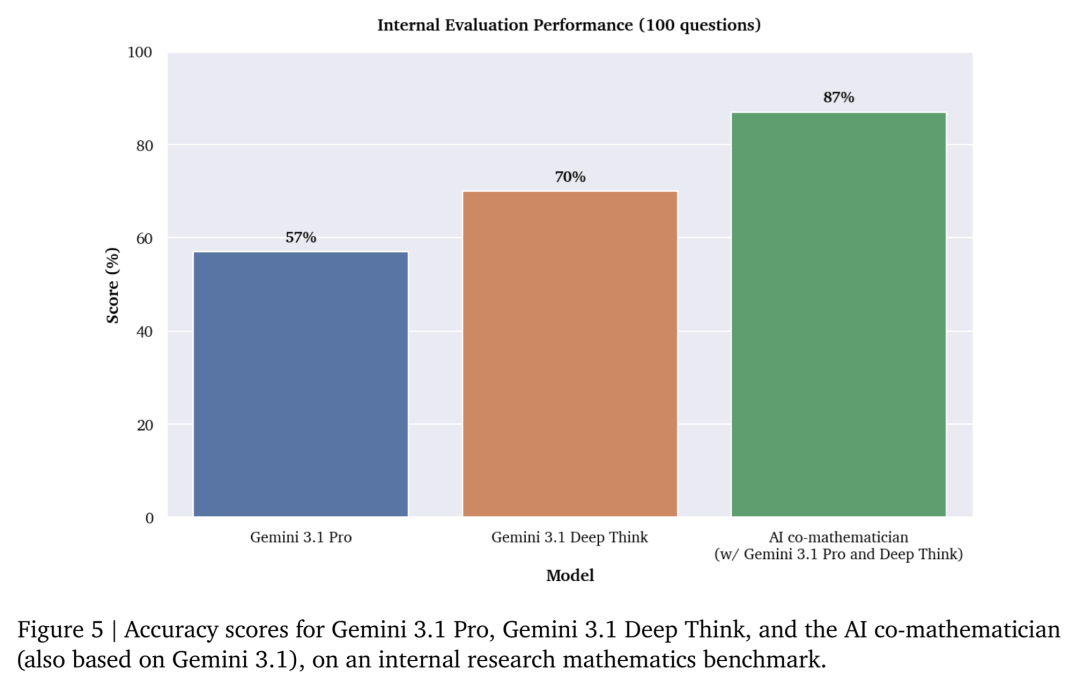
表 FrontierMath (Tier 4) 最难数学基准挑战对比
值得注意的是,这23道答对的题目里,有3道此前从未被任何已评测系统解出。
07 早期应用:解决真实数学问题
真实使用案例同样值得注意。研究团队指出,这些结果均由数学家直接完成,中间没有Google DeepMind研究人员介入。
牛津大学数学家Marc Lackenby借助该系统推进了Kourovka Notebook第21.10号问题。
过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。Lackenby看到之后突然意识到:“等一下,我知道该如何填补这个漏洞。”
于是,通过和AI的反复配合,Lackenby最终成功解答出了这道数学难题。
数学家Semon Rezchikov在哈密顿系统相关子问题上得到了一条包含关键引理的证明路线。
数学家Gergely Bérczi则获得了关于Stirling系数问题的证明尝试与计算证据。
不过,在Bérczi的研究中,相关证明在论文中仍被标注为“处于详细人工审查中”,Rezchikov的研究比较也主要是个案经验,而非受控实验。
这说明该模型在回路中的协作形态已经具有现实价值,但不能直推出Agent已经能够稳定、独立地完成开放式数学研究。
08 挑战与局限
研究团队也承认了该Agent系统的不足。
例如,多轮评审并不必然带来更可靠的结果。有时候原本存在缺陷的论证,会在反复修改后变得越来越像“已经通过审查”,但其中的真实漏洞并没有消失。
其次,不同Agent之间可能迟迟无法形成共识,导致Agent陷入无休止的修改与驳回循环,推理质量反而不断下降。
同时,该Agent系统目前也还无法脱离人类持续介入,稳定完成长程研究任务。
长时间自治也意味着用户必须让出一部分控制权,而当前模型在遭遇意外困难时,何时止步、何时求助的判断,仍然明显落后于人类研究者。
此外,预期排版精良的LaTeX文稿,很容易让人产生“内容严谨”的错觉。
09 未来方向
研究团队对未来方向的表述也相对克制。
他们认为,下一步更重要的,不是单纯追求更强的结果生成能力,而是发展新的评估框架,用来衡量协作效果、有状态探索能力,以及对不确定性的严格管理。
与此同时,如何控制自动化输出带来的语义噪声、减轻同行评审负担,并保住人类对论文价值的整体判断,也是未来研究者必须面对的问题。
与其说AI co-mathematician正在成为一名能够独立攻克难题的“数学家”,不如说它正在显露出另一种可能:在漫长、曲折而充满试错的研究过程中,AI作为人类可以持续协作的对象存在。
AI联合数学家系统已经在FrontierMath Tier 4基准测试中取得了48%的准确率,远超GPT-5.5 Pro的39.6%和GPT-5.4 Pro的37.5%。
牛津大学数学家Marc Lackenby借助这个系统解决了群论领域数十年无解的第21.10号问题。
数学研究正在从孤独的探索,转变为一场与AI智能体的深度协作。



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢