
DRUGONE
数字孪生(Digital Twin)通过融合数据、模型与领域知识,实现对真实系统的动态虚拟映射,被认为是推动化工过程智能化与可持续发展的关键技术。然而,目前化工数字孪生的发展仍面临一个核心挑战:缺乏一种能够系统整合过程数据、物理模型、化学知识以及人工智能工具的统一框架,从而难以高效构建可扩展、可复用的数字孪生系统。本文中,研究人员提出了一种面向化工过程数字孪生的知识图谱框架,通过构建化学过程知识本体(ontology)以及自主功能代理(autonomous agents),实现模型、数据和过程上下文之间的统一组织与自动化协同。
研究人员开发了OntoModel与OntoProcess两套本体,用于分别表示物理模型知识与过程上下文知识,并利用MathML表达数学公式,实现模型的模块化拼接与跨平台调用。与此同时,该框架还能够无缝接入化学数据库、人工智能模型以及大语言模型,从而自动获取物化参数、推理过程现象并辅助模型构建。研究人员进一步通过三个案例验证了框架的有效性,包括自下而上的模型组装、自上而下的模型搜索以及基于模型的多目标反应优化。整体而言,该研究提出了一种面向未来化工数字化制造的新型知识驱动数字孪生基础设施。

化工行业正在快速迈向数字化转型。数字化技术不仅能够提升工艺开发效率、降低排放,还能够改善过程安全与生产可持续性。随着Industry 4.0概念的发展,“数字孪生”逐渐成为连接物理工厂与虚拟模型的重要核心技术。
尽管数字孪生具有巨大潜力,但当前化工领域的数字孪生系统通常难以扩展。原因在于,每一种单元操作和工艺流程往往都需要独立建立过程模型与数字表示,而且大量已有模型分散在商业软件或企业内部,缺乏统一管理与共享机制。
传统化工模型主要包括三类:基于物理规律的机理模型、基于统计学习的数据驱动模型以及混合模型。其中,物理模型虽然具有更强可解释性,但其知识表达通常缺乏标准化,很难与数据库、AI工具以及实时过程数据实现自动协同。与此同时,目前已有知识图谱研究更多聚焦于化学物种、反应网络或催化剂,而缺少一个能够系统组织“化工过程模型与上下文知识”的统一知识框架。
因此,研究人员提出了一种面向化工数字孪生的知识图谱框架,希望通过知识图谱技术实现模型、数据、过程现象与AI工具之间的统一连接。该框架不仅能够自动组装物理模型,还能够结合数据库、AI预测模型以及大语言模型实现动态知识扩展,从而为未来智能化化工过程开发提供基础设施。
方法
研究人员构建了由OntoModel与OntoProcess组成的知识图谱体系。其中,OntoModel用于描述变量、物理定律、公式、维度以及数据库API等模型知识;OntoProcess则用于表示化工过程中的上下文、规则与过程描述信息。
为了实现数学模型的标准化表达,研究人员采用MathML对公式进行语义化编码,并开发解析代理将其自动转换为SciPy、Pyomo与Julia等不同求解器可执行代码。与此同时,研究人员构建了一系列自主代理,包括模型组装代理、模型校准代理、规则推理代理、数据库查询代理、AI模型调用代理以及LLM聊天代理,用于自动完成模型搜索、参数拟合、知识推理与物化性质获取。
整个框架支持两种核心建模模式:一种是“自下而上”的模型组装,即基于已知过程现象逐层拼接模型;另一种是“自上而下”的模型搜索,即根据过程上下文自动筛选和校准候选模型。研究人员还开发了网页化部署系统,实现人与知识图谱之间的交互式建模。
结果
构建面向化工数字孪生的知识图谱框架
研究人员首先提出了整体知识图谱架构。该框架通过知识图谱统一管理变量、物理规律、过程现象以及上下文规则,并利用MathML表达数学公式,实现模型与代码实现之间的解耦。
研究人员开发了OntoModel与OntoProcess两种本体。其中,OntoModel主要用于组织模型中的变量、公式、单位和数据库接口,而OntoProcess则用于表示化工过程中的结构、能量、物质、时间等上下文信息。研究人员进一步通过SPARQL规则推理,实现不同模型在特定工艺场景下的自动适配。
与此同时,该框架还能够接入PubChem、ChemSpider、Wikipedia、RMG以及ChatGPT等外部资源,实现物化性质自动查询、AI预测与自然语言交互。
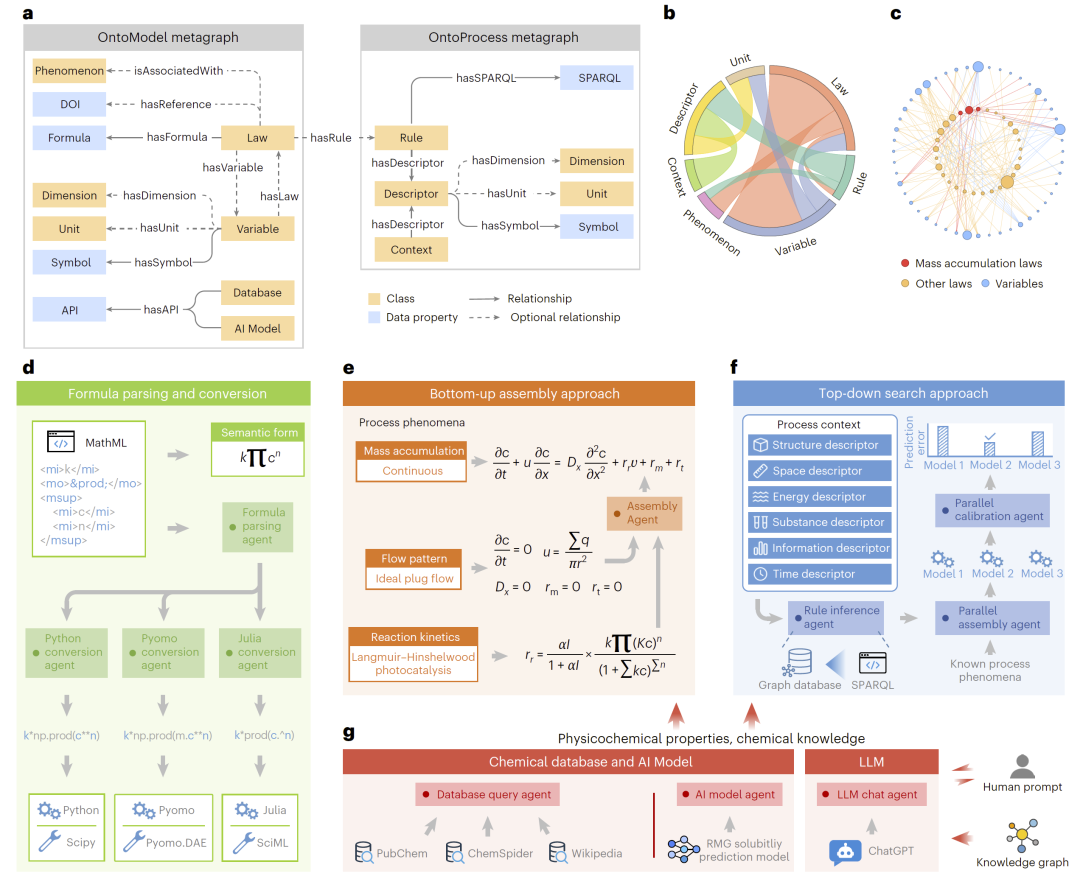
图1: 化工过程数字孪生知识图谱框架。
自下而上组装环形微反应器模型
研究人员随后利用一个环形微反应器案例验证“自下而上”模型组装能力。该反应器由三层同轴石英管组成,通过气液混合形成可控微混合过程。
研究人员将“气诱导环流”“卷吸混合”“Villermaux–Dushman反应动力学”等过程现象输入知识图谱后,系统能够自动检索并拼接相关公式,包括膜厚度、流速、混合时间与反应速率等子模型。
随后,模型校准代理利用实验数据自动拟合参数。结果显示,校准后的模型能够准确预测I3−浓度,并揭示该微反应器能够实现约0.1 ms量级的超快混合时间,优于传统T-mixer等混合设备。
研究人员认为,该案例证明了知识图谱能够实现多来源知识的模块化拼接,并显著提高化工模型的可复用性与透明性。
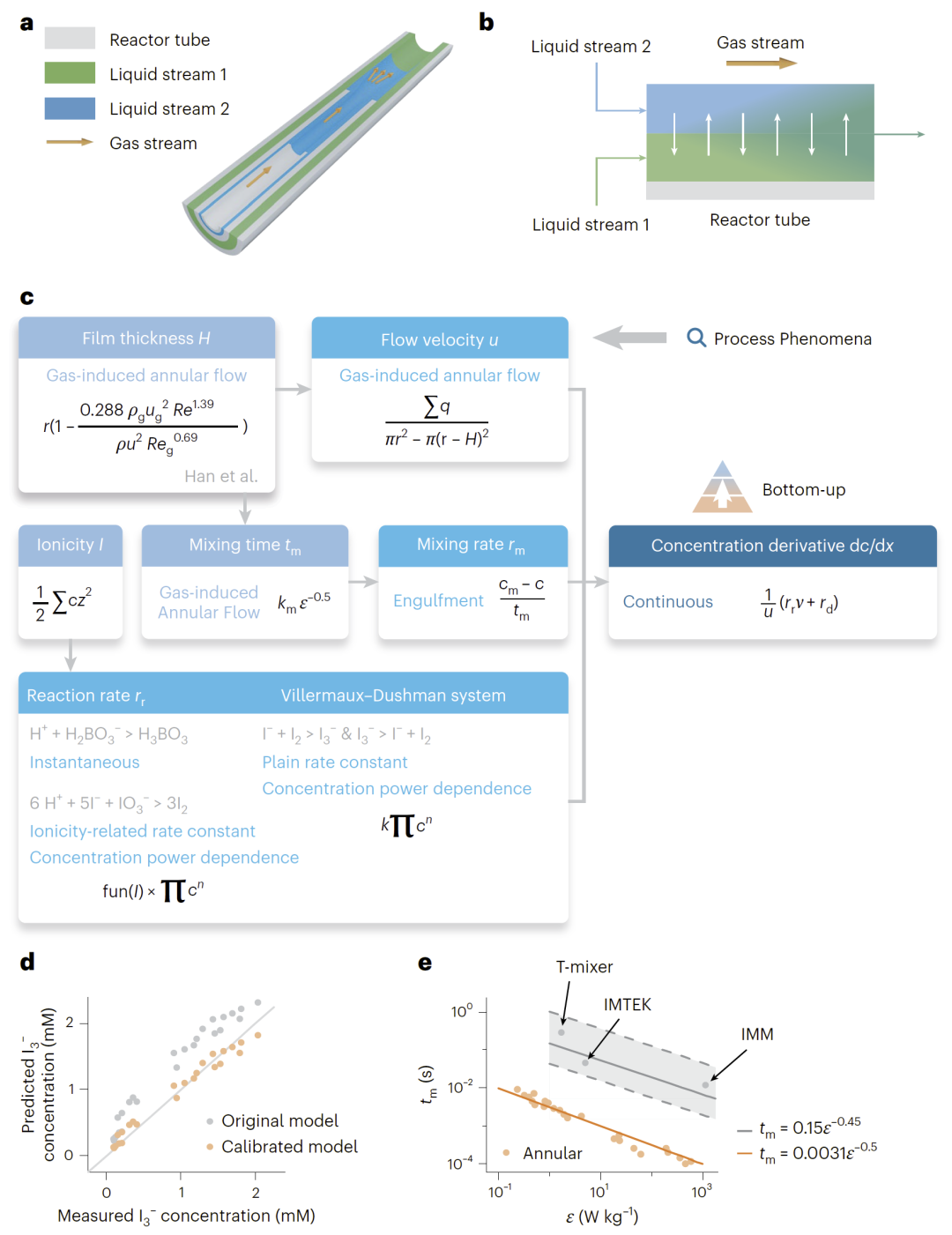
图2: 基于知识图谱的环形微反应器自下而上模型组装流程。
自上而下搜索Taylor–Couette反应器模型
研究人员进一步利用带肋Taylor–Couette反应器(TCR)验证“自上而下”的模型搜索能力。该系统具有复杂流动模式,包括Couette流、涡流以及湍流等。
在该案例中,研究人员并未预先指定唯一模型,而是让知识图谱根据过程上下文自动筛选适用的扩散系数关联式。系统利用SPARQL规则推理,自动比较Tam and Swinney、Moore and Cooney等多个模型,并结合实验数据进行并行校准。
结果显示,在不同操作条件与不同溶剂下,知识图谱能够自动识别最适合的模型。例如,在MeCN体系与360 rpm条件下,Moore and Cooney模型表现最佳,而在停止旋转时,则退化为常数扩散模型。
研究人员指出,该结果说明知识图谱不仅能够自动完成模型筛选,还能够维持模型在不同工艺场景中的互操作性与可迁移性。
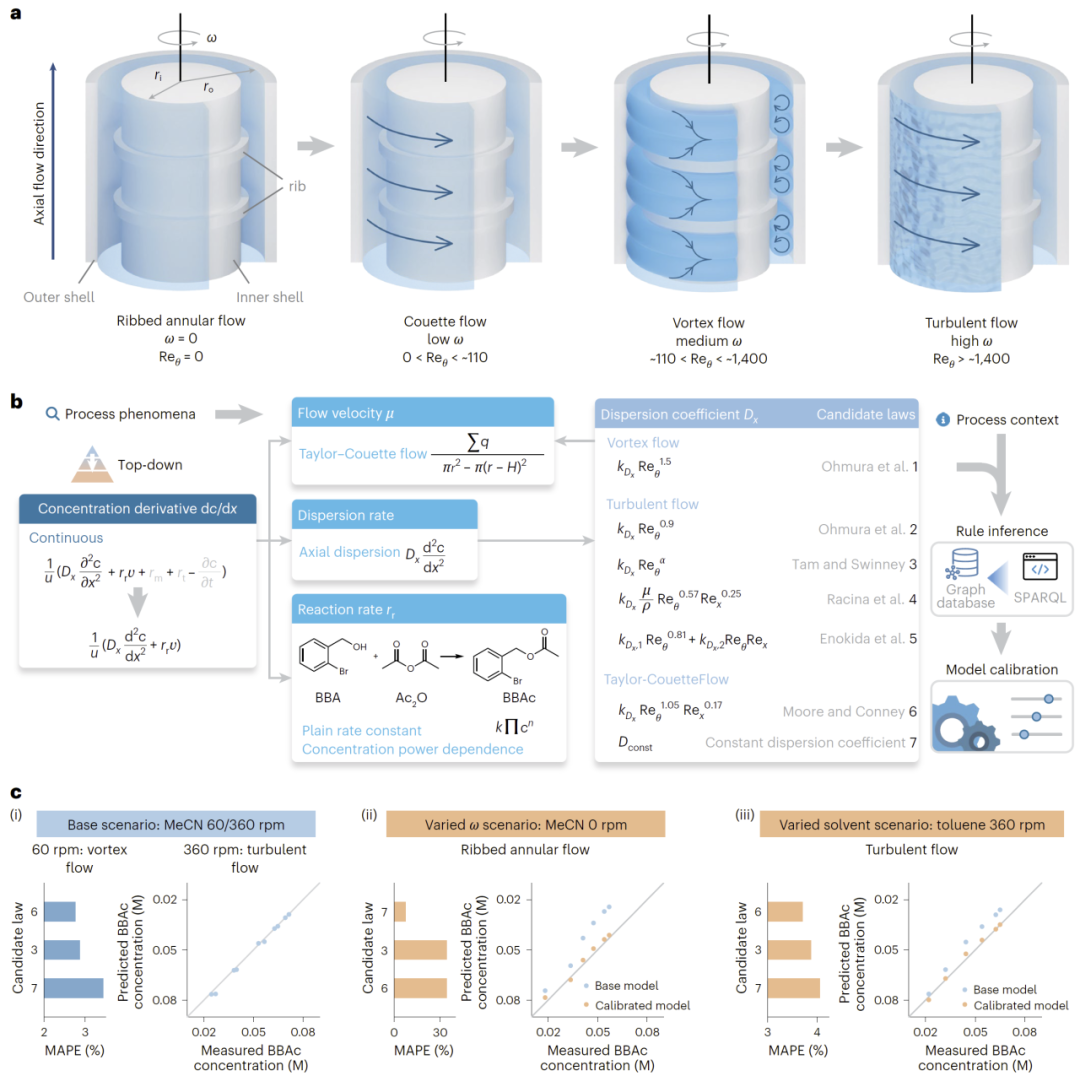
图3: 基于知识图谱的TCR模型搜索与自动校准流程。
知识图谱驱动的流动化学多目标优化
研究人员最后展示了知识图谱在流动化学优化中的应用。他们选择酰胺化反应作为案例,目标是在最大化时空产率(STY)的同时最小化E-factor。
研究人员首先利用ChatGPT查询反应动力学知识,并将其映射到知识图谱中的动力学现象类别。随后,数据库代理与AI模型代理自动获取密度、黏度、互溶性以及溶解度等物化参数。
在H2O/MeCN体系中,知识图谱识别出扩散与卷吸混合机制;而在H2O/EtOAc体系中,则自动识别液-液传质为主导机制。基于这些物理模型,系统进一步计算Pareto前沿,并指导实验探索最优工艺区域。
实验结果显示,模型预测与真实实验高度一致,整体MAPE低于5%。同时,与贝叶斯优化相比,该基于物理模型的方法在虚拟反应优化任务中表现更优,说明知识图谱能够有效利用化学机理知识提升优化效率。
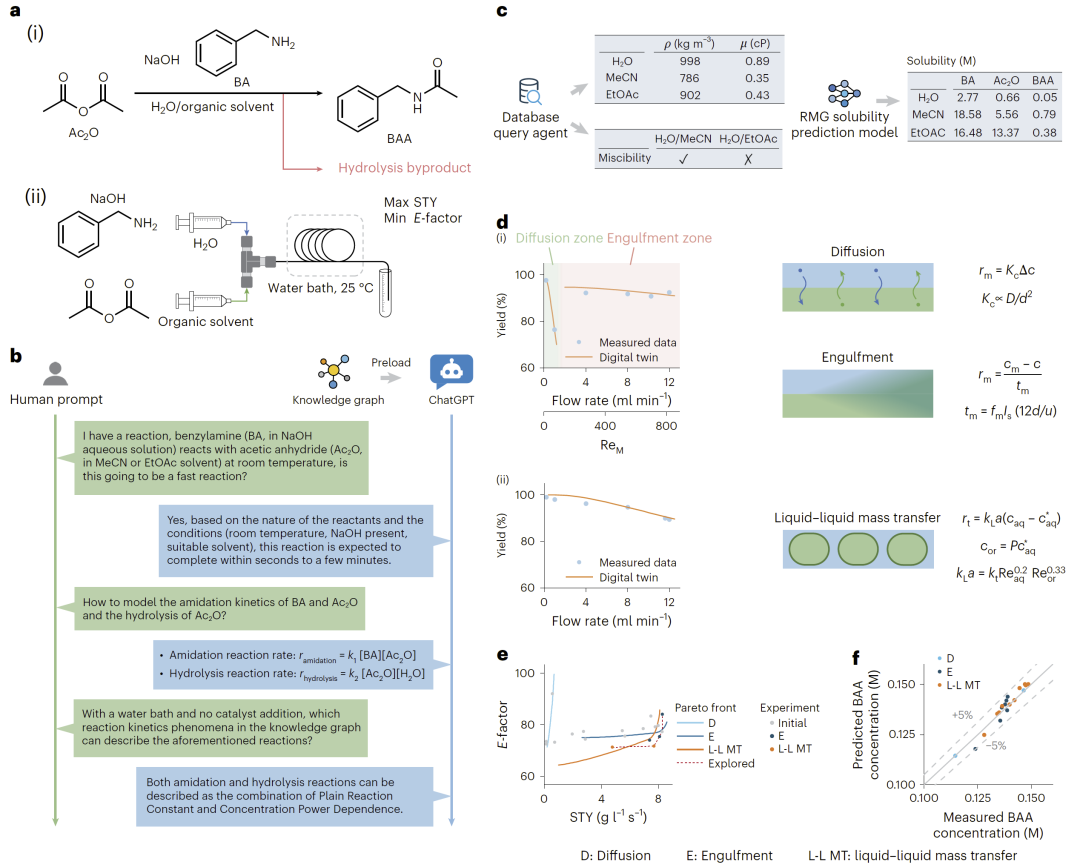
图4: 知识图谱驱动的流动化学多目标优化与Pareto前沿分析。
讨论
本研究提出了一种面向化工过程数字孪生的知识图谱框架,实现了模型知识、过程上下文、数据库资源、AI模型以及大语言模型之间的统一组织与协同。
研究结果表明,该框架能够通过自下而上与自上而下两种模式自动完成模型构建、筛选与校准,并支持多目标反应优化。这种方法不仅提高了化工模型的可复用性与透明性,也为数字孪生的大规模扩展提供了基础设施。
此外,研究人员强调,未来知识图谱还可以进一步结合反应本体、领域微调LLM以及符号回归等AI技术,实现新的化工机理发现与自动知识扩展。研究人员认为,该框架不仅适用于数字化制造,也有望成为未来化工教育、远程协作与智能科研的重要支撑平台。
整理 | DrugOne团队
参考资料
Zhang, S., Zhang, J. & Lapkin, A.A. A knowledge graph framework for digital twins of chemical processes. Nat Chem Eng (2026).
https://doi.org/10.1038/s44286-026-00392-1

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢