

科学发现的核心,在于科学家针对复杂问题提出新假说,并经过严格的实验验证。
不过,当前的科学问题已经开始变得越来越复杂。科学家不仅要掌握深入的领域知识,还要在海量文献、数据库、实验结果和证据之间找到有价值连接。以往这个过程,往往要花费数周、数月、甚至更久。
如今,专为结构化科学思维与假说生成而设计 AI Scientist,不仅加速了科学发现的速度,还帮助科学家跨越学科边界,提出可供实验验证的、具有明确新颖性的研究假说。
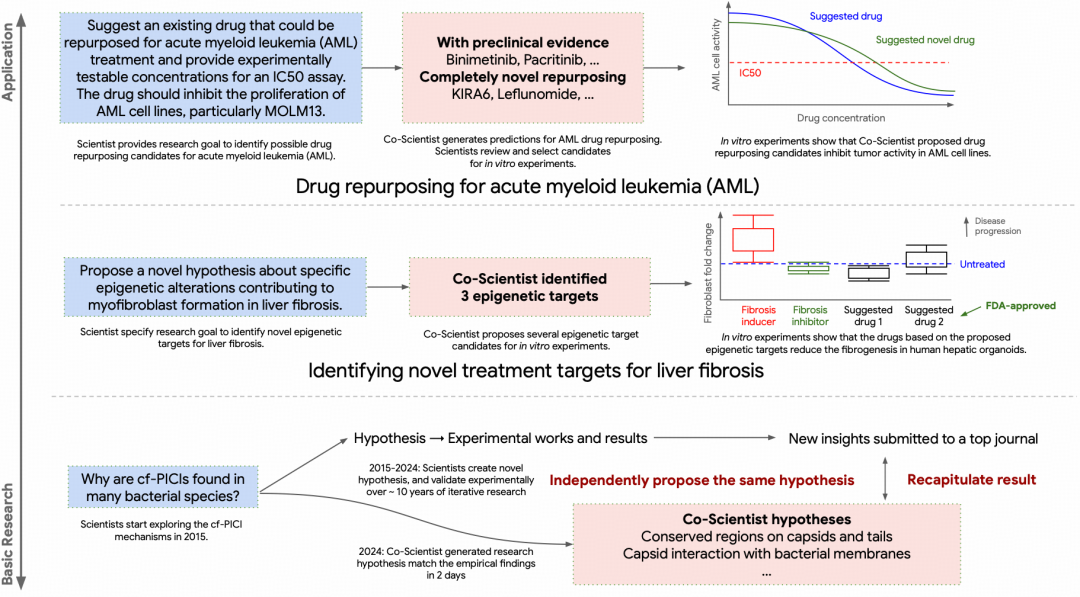
Google DeepMind 团队推出的多 Agent 系统 Co-Scientist 便是一个典型案例。据介绍,Co-Scientist 不仅为急性髓系白血病提出了新的候选药物和联合疗法,还发现了针对肝纤维化的新药物靶点,并揭示了抗菌药物耐药性背后的关键遗传机制。
相关研究论文已于今天发表在权威科学期刊 Nature 上。

论文链接:https://www.nature.com/articles/s41586-026-10644-y
值得一提的是,在抗微生物耐药任务中,Imperial College London 团队后来发表于《Cell》的研究表明,Co-Scientist 仅用两天提出的机制假说,与该团队研究人员实验所得、当时尚未公开的发现高度一致。
这些真实场景中的验证结果充分展示了 Co-Scientist 加速科学发现的潜力,预示着 AI 赋能科学家新时代的到来。
Co-Scientist:一个结构化科学思维引擎
Co-Scientist 并没有把科研过程完全交给 AI,而是保留了“human-in-the-loop”的协作方式。
科学家可以先用自然语言给出研究目标、偏好和约束,也可以提交初始假说,与 Co-Scientist 生成的假说共同参与后续排序和演化。在后续交互和迭代中,科学家可以插入反馈、调整方向,或授权 Co-Scientist 检索私有文献库、调用 AlphaFold 等专业工具。
在此基础上,Co-Scientist 将科研流程拆分为假说生成、文献评审、同行批评、竞争排序和迭代优化等子任务,并由不同专业 Agent 执行。整套系统由“主管 Agent”统一调度,其他 Agent 则通过异步任务队列并发运行。
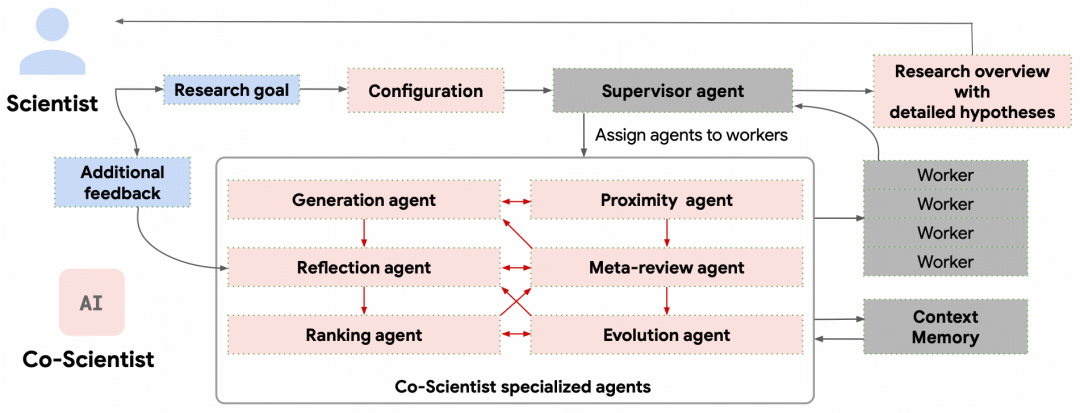
图|Co-Scientist 架构。
生成 Agent 负责生成初始假说。它有通过网络搜索文献、模拟专家之间的自我对弈式科学辩论、逐步推导可检验的中间假设,以及从已有假说的空白处寻找新方向。每条假说生成后附有摘要和分类标签,便于科学家快速浏览。
反思 Agent 扮演同行评审的角色,分四个层次审查假说。初步审查不调用外部工具,快速过滤明显缺陷;全面审查调用搜索工具做文献核查,评估正确性、新颖性和质量;深度验证把假说拆解为子假设逐一检验;观测回顾则判断该假说能否解释已有实验中尚未被解释清楚的现象。
排序 Agent 使用 Elo 评分机制对假说排序,通过两两辩论比较相对质量。高分假说进行多轮科学辩论式对比,低分假说则进行单轮快速比较。研究团队提出,相比简单比较提示词,科学辩论式提示词可以提高排序准确性,并降低位置偏差。
相似度 Agent 负责计算假说之间的相似度,并建立邻近图它不直接生成假说,而是帮助排序 Agent 判断哪些假说应该优先两两比较,同时识别相近或重复的想法,保留更多不同方向的候选假说。
演化 Agent 负责改进排名靠前的假说,例如补充文献依据、提高实验可行性、合并多个假说的优点,或提出不同方向的新解释。研究团队强调,它不会直接覆盖原有假说,而是生成新的候选版本,再重新进入排序和比较流程。
元审查 Agent 负责总结评审和辩论中反复出现的问题,并把这些反馈写入其他 Agent 的提示词,供下一轮生成、审查和排序使用。这是一种不依赖模型训练的系统级学习。计算结束后,它会把排名靠前的假说整理成研究概览,交给科学家判断。
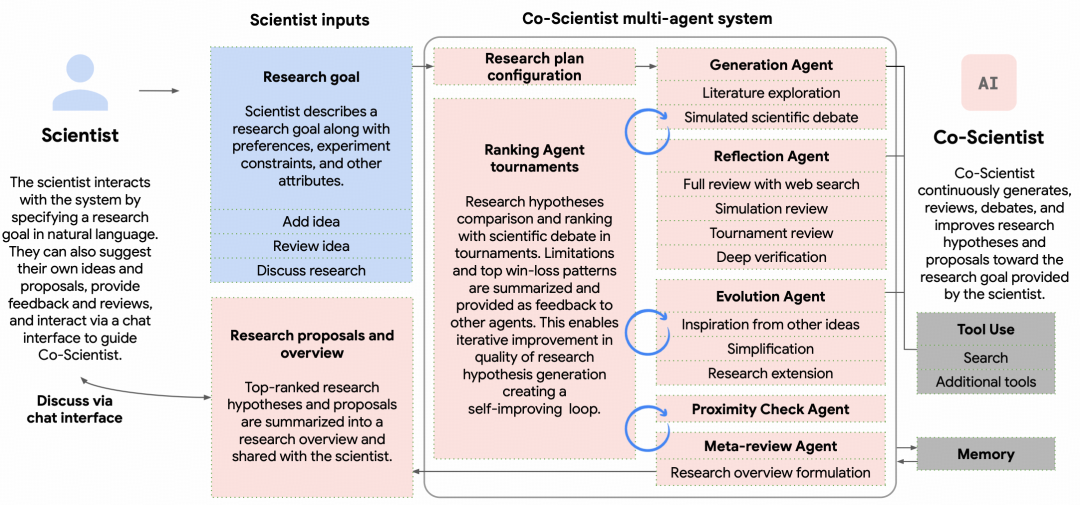
图|Co-Scientist 多 Agent 系统设计
系统评估:架构、指标与专家判断
在湿实验验证之前,研究团队先对 Co-Scientist 进行了系统评估,依次验证架构和评价指标是否合理、多 Agent 组件是否必要、测试时计算能否提升假说质量,以及生成结果相较于前沿模型和专家假说处于什么水平。
1.Agent 消融分析
为验证各 Agent 组件的作用,研究团队进行了消融实验,比较去掉或替换部分组件前后的系统表现。
结果显示,Reflection Agent 接入外部搜索工具后,可以减少把已有文献误判为新假说的情况;Ranking Agent 使用科学辩论式提示词后,排序准确性提高,位置偏差下降;Evolution Agent 的迭代改进也会提升假说质量。
以 Reflection Agent 为例,面对一组已经发表、应被判定为不新颖的想法时,不接入搜索工具的版本得到了 6.14/10 的新颖性评分;接入搜索后,这一评分降至 2.38/10,这说明文献检索有助于减少 Agent 对“虚假新颖性”的误判。
2.扩大测试时计算
研究团队接着考察测试时计算扩展的影响,验证 Agent 运行时间越长,假说质量是否继续提升。
研究团队选取截至 2025 年 2 月 3 日输入系统的 203 个研究目标,主题以生物医学为主,也包括数学和物理。他们把生成的假说按时间顺序分成 10 段,分别计算每段的最高 Elo 分和前 10 个假说的平均 Elo 分。
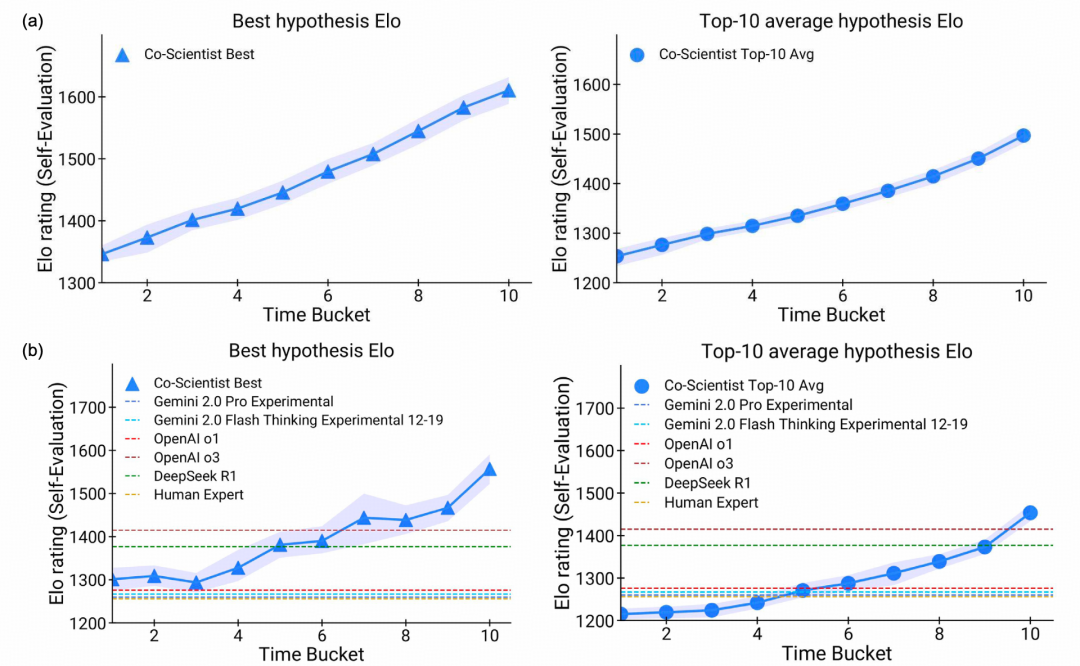
图|扩展测试时计算能够增强 Co-Scientist 的科学思维能力和假设质量。
结果显示,越晚生成的假说,两个指标整体越高,且未出现明显饱和;但 Elo 只是 Agent 内部的相对排序指标, 不等同于实验成功率。
3.与前沿模型和专家假说比较
为进一步比较系统能力,研究团队选取了 15 个由 7 位生物医学专家设计的高难度研究目标。这些目标采用统一格式,包含研究标题、目标、疾病或生物领域偏好、理想方案属性和实验技术约束。专家还为每个目标提供了自己的“最佳猜测”假说。
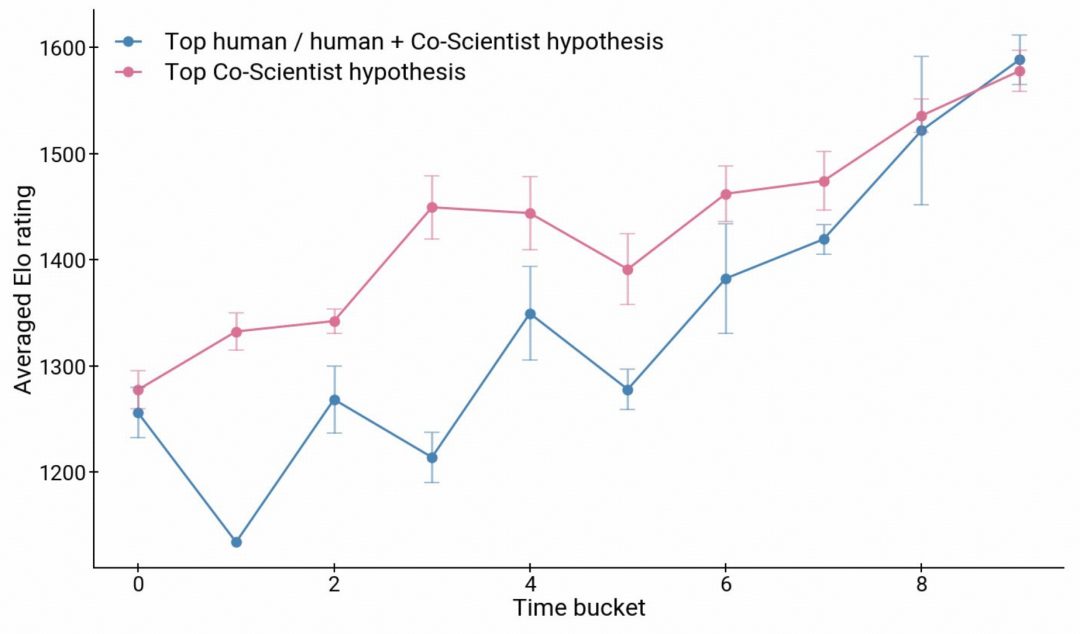
图|Co-Scientist 通过基于 Elo 的自动评估增强专家能力。
随后,研究团队将 Co-Scientist、专家最佳猜测,以及当时多种前沿 LLM 和推理模型的输出放入同一 Elo 比较中。结果显示,随着迭代推进,Co-Scientist 在 Elo 评分上最终超过这些基线。o3-mini-high 和 DeepSeek R1 也表现出竞争力,所需计算量和推理时间更少。单个强推理模型可以较快给出高质量答案,Co-Scientist 的优势在于长时间搜索和迭代改进。
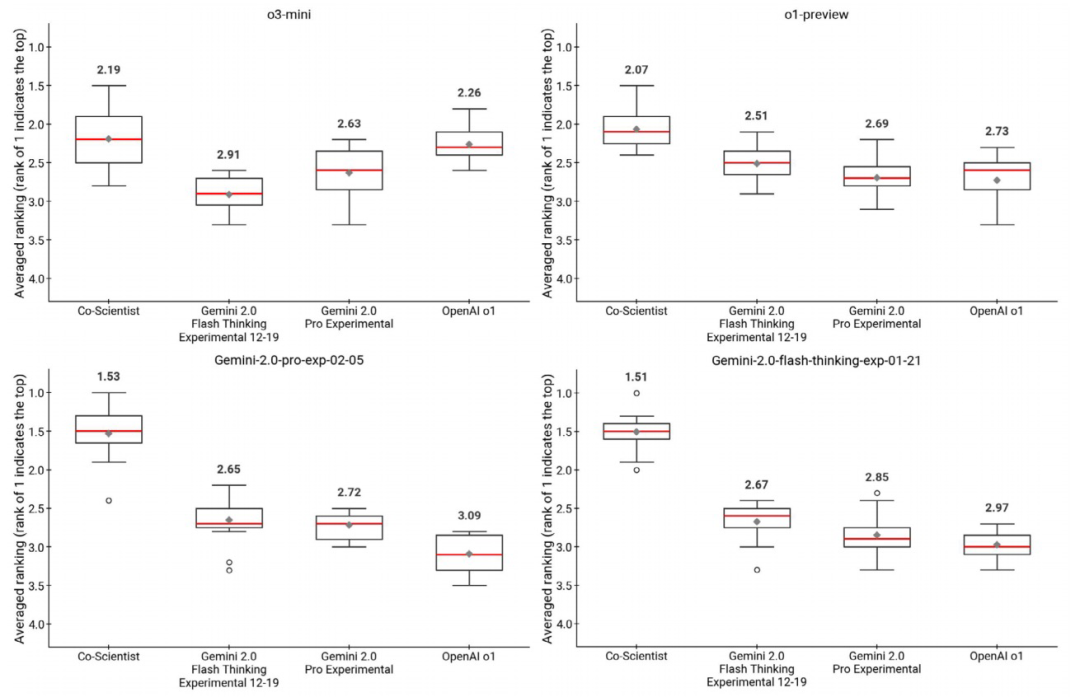
图|Co-Scientist 与其他基线的 LLM 偏好排名自动评估。
研究团队表示,Co-Scientist 不只会改进自己生成的假说,还能持续改进专家给出的初始想法。按 Elo 评分看,专家假说和 Agent 的协作结果后来甚至超过了 Agent 自生成假说。
4.人类专家盲评
除了基于 Agent 的自动评分,研究团队还进行了小规模专家评估。提出研究目标的专家比较了 Co-Scientist、Gemini 2.0 Flash Thinking、Gemini 2.0 Pro 和 OpenAI o1 的输出,并分别从新颖性和影响力两个维度打分。
结果显示,在 11个专家评估的研究目标上,Co-Scientist 的输出整体最受偏好:平均偏好排名为2.36,新颖性得分为 3.64/5,影响力得分为 3.09/5,高于几种基线模型。
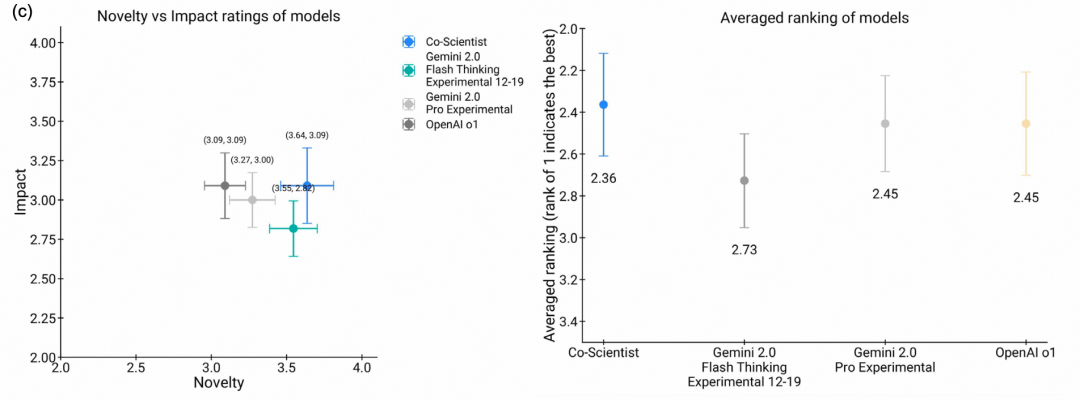
图|(左)专家对假设新颖性和影响力的平均评分,(右)专家总体偏好排名
不过,研究团队也强调,这只是小样本、主观专家判断,并不等同于客观科学发现验证。
此外,研究团队还使用多个 LLM 评判者做补充评测,结果显示,Co-Scientist 同样排名第一;但这些评估规模较小,仍需要进一步验证。
真实场景中的验证评估
为检验 Co-Scientist 生成的假说是否具备实验或独立证据支持,研究团队进一步选择了三个生物医学方向进行验证:AML 药物重定向与联合用药、肝纤维化候选靶点筛选,以及抗微生物耐药机制发现。
在 AML 任务中,研究团队从 2300 种已上市药物和 34 种癌症类型出发,先对 5 种首轮候选药物进行体外验证,随后又测试了 3 种更具新颖性的单药候选和 7 种联合用药组合。专家投入主要集中在任务定义和候选筛选两个环节,用时分别不到 1 小时和约 3 小时;而如果完全依赖人工完成类似搜索,通常需要数天到数周。
图|Co-Scientist 为急性髓系白血病(AML)生成的单药再利用候选物的体外生物学验证。
实验结果显示,Binimetinib、Pacritinib 和 Cerivastatin 均能抑制 AML 细胞活力。相比之下,Binimetinib 呈现出更清晰的 AML 细胞偏向性:在多条 AML 细胞系中,其 IC50 可低至 2 nM,而在非 AML 对照细胞系 TK6 中则显著升高。这提示,Binimetinib 不是简单用于既往的 RAS 突变 AML 场景,如果AML 细胞中 RAS-MEK-ERK 通路活性与化疗反应相关,这种药物就也许值得在初治阶段进一步评估。
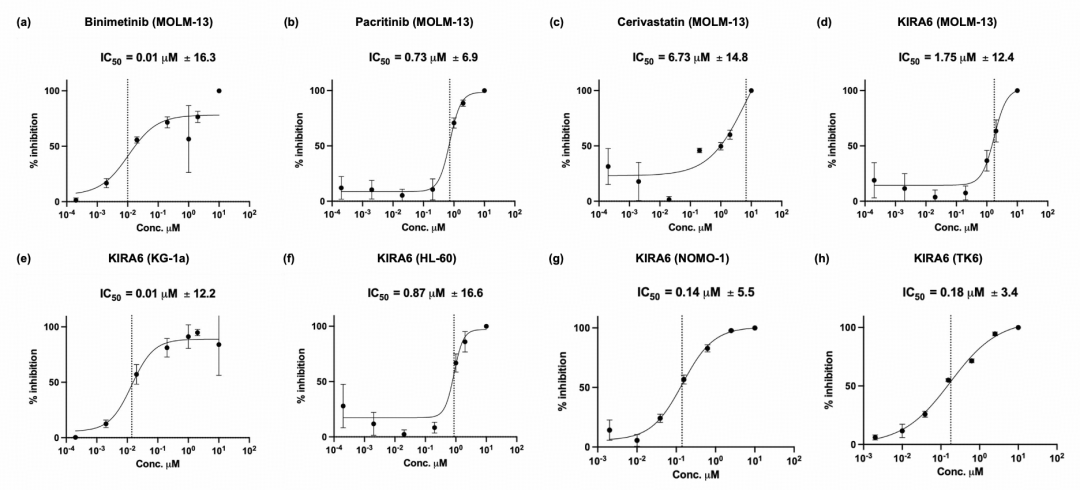
图|MOLM-13 AML 细胞经 Binimetinib、Pacritinib 和 Cerivastatin 处理后的剂量-反应曲线。
KIRA6 的结果则更接近对 Co-Scientist 所提出新候选药物的验证。在不接收额外外部输入或人工反馈的情况下,Co-Scientist 生成了更具新颖性的 AML 单药候选,专家最终选取其中 3 种进行测试。作为 IRE1α 抑制剂,KIRA6 在 KG-1a 细胞系中的 IC50 为 10 nM,而在非 AML 对照细胞系 TK6 中为 180 nM,两者相差 18 倍,提示其可能具有一定的 AML 细胞选择性,并具备进一步评估治疗窗口的基础。IRE1α 与 AML 的关系已有研究报道,但 KIRA6 作为 AML 再利用候选的直接证据仍较有限,因此 Co-Scientist 将其新颖性评为中等。
联合用药实验中,Co-Scientist 进一步在高维组合空间中提出了 7 种可优先测试的方案。JNJ-64619178 与Selinexor 在 MOLM-13 细胞系中显示出 CI<1 的协同效应;JQ1、Olaparib 与 MSA2 的三联组合也在热图分析中表现出协同信号。相比之下,KG-1a 的结果更为复杂,可能与其 TP53 突变及更耐药的分子特征有关,不同组合中同时出现了协同和拮抗现象。
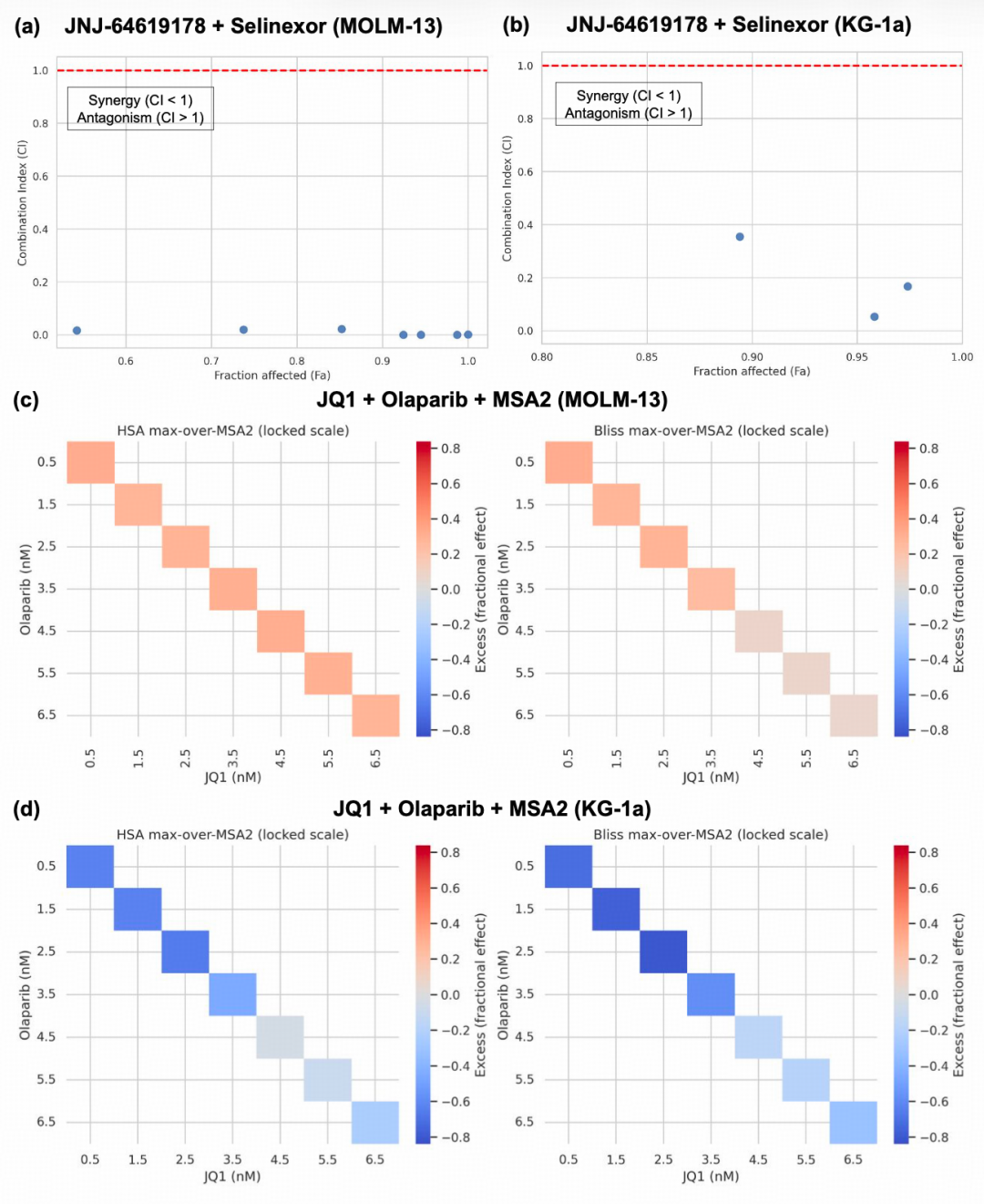
图| Co-Scientist 预测的急性髓系白血病(AML)协同多药组合验证。
在肝纤维化任务中,Co-Scientist 使用结合人类肝脏类器官和活细胞成像的方法,寻找严重肝纤维化的新治疗靶点。针对 3 种表观遗传靶点所选的候选药物中,有 2 种在人类肝脏类器官中表现出抗纤维化活性,且未观察到明显细胞毒性。其中,Vorinostat 已获 FDA 批准用于其他癌症适应症,因此具备进一步药物重定向的潜力。
图| Co-Scientist 预测三药组合的超额分数效应热图。
在抗微生物耐药任务中,Co-Scientist 提出的 cf-PICIs 宿主范围扩展机制,与另一研究团队经过多年实验得到的核心发现高度一致。两项成果随后均发表于 Cell,为这一机制提供了独立验证。
不足与未来方向
研究团队也指出,Co-Scientist 目前依然存在以下局限:
文献覆盖有盲区。Co-Scientist 的知识受到其依赖开放获取科学文献的限制,这可能导致遗漏付费墙后的关键既有成果,缺乏对阴性实验结果的访问。未来,可以改进将通过增强学习和知识库、提升文献搜索能力以扩大访问范围、实施更严格的外部数据库和工具事实核查,以及提高引文召回率,来提升系统稳健性。
输出质量受文献质量制约。论文团队指出,如果来源文献本身质量参差、相互矛盾,Co-Scientist 就可能有传播错误结论或不可重现结果的风险。未来,需要开发具备更强溯源能力的 Agent,将论断追溯到来源中的具体图件或数据,以减轻不可靠文献的影响。
其底层模型存在内在局限。Co-Scientist 继承了底层 LLM 的问题,包括事实准确性不足和幻觉风险。未来,仍需要提升模型的推理能力。
湿实验验证仍处早期。当前所有实验结果均为初步细胞层面验证,不能替代系统的临床前和临床评估。研究团队明确指出,即便假说通过了专家审核、有体外数据支持,也不能保证体内有效或临床成功。药物生物利用度、药代动力学、脱靶效应、患者选择标准,以及血液肿瘤中微环境带来的复杂影响,都可能引入体外实验无法预测的耐药机制。
研究方向趋同的潜在风险。研究团队专门提到,如果大量研究者依赖类似的 Agent 生成假说,可能导致科学探索方向趋同,削弱批判性思维。在缺乏同行评审和有效约束的情况下使用,还可能产出低质量的科学成果,进而加剧已有的科研可重复性危机。AI 有潜力降低科学信息的获取门槛,但需要建立可靠的验证机制,确保它是在增强而非替代人类的科学判断与创造力。
最后,他们也提出了未来几个主要方向。
例如,近期重点是增强系统稳定性。扩展知识库和学习能力,拓宽文献检索覆盖范围,加强针对外部数据库的事实核查,提升引用召回率。
中期计划则应关注扩展系统能力边界。整合能直接处理公开数据库和多模态数据的 Agent,以支持生物信息学和数据科学任务;引入来自人类和实验结果的强化学习,优化假说生成与精炼流程。同时扩大评估范围,检验 Co-Scientist 在更广泛科学领域的泛化能力,并开发更客观、更自动化的评估指标,以替代现有的排名机制。
长远来看,Co-Scientist 还需要与实验室自动化平台打通,逐步形成从假说生成、实验执行到迭代学习的闭环系统,从而提升科学发现的整体速度。
更多技术细节,详见原论文。
作者:夏千斯
如需转载或投稿,请直接在本文章评论区内留言。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢