


🧬一个时代正在加速到来。
从Evo系列以单核苷酸分辨率开启长上下文基因组建模,到AlphaGenome将调控变异(Regulatory Variant)效应预测推向新高度,AI与基因组学的交叉正在点燃全球生命科学的新引擎。DNA —— 这本写满40亿年进化密码的“天书”,迎来了它的翻译官。
然而在整个领域飞速发展的背后,伴随而来的是模型参数越堆越高,上下文长度越卷越长,算力门槛令人望而却步。
今天,北京中关村学院与国际知名开源社区Hugging Face、意大利TIGEM及那不勒斯费德里科二世大学,用实际行动作出了回应——
我们带来的不仅仅是一个模型,更是一套全开放的技术普惠方案,一种科学信念,以及一条通往“生命语言GPT”的新路径。
破局:当多数人追逐“更大”,我们选择“更懂”
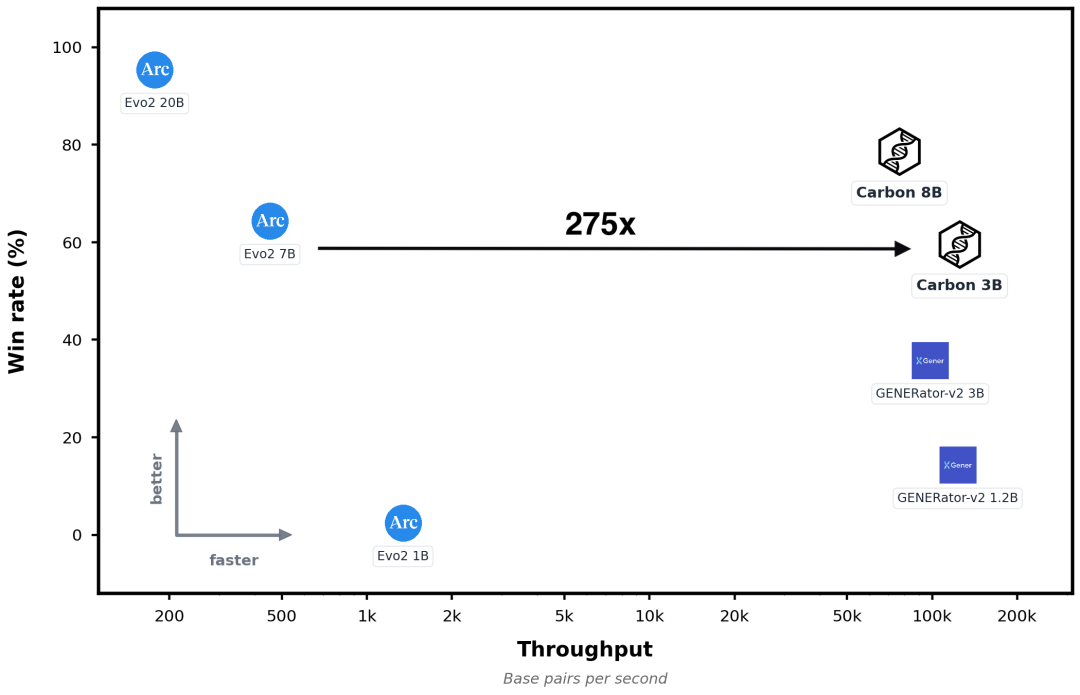
Carbon家族包含Carbon-500M、Carbon-3B、Carbon-8B三个版本。我们的旗舰模型Carbon-3B(30亿参数)在8大零样本DNA任务上,全面匹敌70亿参数的Evo2-7B;而Carbon-8B更进一步,在同等参数量下全面超越了Evo2-7B级别的表现。
但真正的震撼在于效率:Carbon-3B的运行速度是Evo2-7B的275倍。在单张A100上处理一个典型人类基因(约27,000个碱基对),Carbon仅需1.5秒,Evo2-7B需要超过400秒;若扩展至全人类基因组规模,这意味着不到2天vs. 超过1.5年的效率之差。
为什么一个“小”模型能有如此能量?
因为Carbon的强大,源于对“DNA序列建模”这个问题的深刻思考。
基于这一认知,Carbon团队在看似“朴实无华”的标准Transformer架构上,注入了三项直指问题本质的创新:
1
数据:从“堆量”到“提质”
基因组不是人类文本,它充斥着大量弱约束的“进化噪音”。Carbon从6万亿个碱基对的原始数据中,摒弃了“堆量”的传统观念,创新性地筛选高功能密度区域,将训练信号的有效生物浓度提升近一个数量级。我们认为数据不能只是量大,更要质高 ——这是 Carbon 对基因组预训练的核心洞察。
2
分词:化解效率与精度的"核心冲突"
单核苷酸分辨率与计算效率,是DNA大模型长期存在的“核心冲突”:逐碱基建模精度高却算力爆炸,粗粒度分词提速又必牺牲碱基敏感度。Carbon以非重叠 6-mer分词将序列压缩6倍,注意力成本最高降低36倍;更关键的是FNS算法,通过概率边缘化从6-mer词元中精确还原每个碱基(A/C/G/T)的独立概率。六碱基一步的效率,单碱基一步的精度,从此兼得。
3
训练:损失函数切换,攻克“损失阶梯”
团队首次系统揭示了DNA大模型训练中的“损失阶梯”现象——标准交叉熵在训练后期会因DNA序列的固有模糊性而陷入数值不稳定。Carbon在适当时机从 CE切换至FNS,不仅实现了训练稳定性与核苷酸级精度的双重突破,更消除了低精度(BF16)推理下的性能劣化。
普惠:从超算中心,到每一个人
• 热带雨林的野外工作站里,一台笔记本就能完成新物种的实时基因组比对,无需等待数据传回城市超算中心;
• 育种大棚旁的手提电脑上,正在生成明天就要试种的抗病基因序列,算力门槛不再是育种创新的天花板;
• 诊室里,遗传咨询师在患者身旁打开电脑,几分钟内完成全外显子组变异解读,让罕见病诊断不再被机房排期拖延。
把先进的AI工具从超算中心搬到每个人的桌面上——这是Carbon对“开放科学”最真诚的诠释。
赋能:生成式DNA模型的应用图景
当基因组模型变强大的同时开放普惠,将推动应用层面的链式反应:
🧬AI辅助疫苗与药物设计:快速生成编码最优抗原表位的DNA序列,加速 mRNA疫苗与基因疗法的迭代周期;
🌾 智慧育种:在作物与livestock基因组中精准编辑,培育更高产、更抗病、更耐逆的品种,应对全球粮食安全挑战;
🏥 精准医疗:辅助解释癌症患者与罕见病患者的遗传变异,为个性化治疗提供序列级依据,让“千人千药”从概念走向临床;
🧪合成生物学:设计基因表达调控回路,让微生物成为高效生产药物、生物燃料和绿色化学品的“细胞工厂”。
Carbon不仅是一个预测器,更是一个生成式的设计伙伴——它懂 DNA 的语法,能写出符合进化逻辑的新序列。
展望:从“碳基序列”到“生命语言的GPT”
Carbon是一个强大的小模型,但它更是一个起点。
现在的DNA语言模型,是无法理解人类语言的;而人类,也难以直接理解模型的输出。模型与使用者之间,横亘着一道巨大的模态鸿沟。你可以让Carbon生成一段DNA,但你很难直接用自然语言问它:“请为我设计一个只在肝细胞中表达、且免疫原性最低的基因调控序列。”
打通模态,将是下一代基因组模型的圣杯。
北京中关村学院与Hugging Face将持续保持紧密合作,共同致力于实现从DNA基础模型到真正意义上的“生命语言GPT”的跨越—— 一个既能读懂基因组、又能与人类自然对话、还能解释自己设计理由的智能体。
想象一下:一位医生用中文描述患者的临床表型,模型便能在基因组中定位可疑变异并解释其致病机理;一位生物工程师用英文描述想要的酶活性,模型便能生成并优化编码该酶的DNA序列,同时标注每一步设计决策的依据。
我们期待生命科学领域人机协同时代的到来。
结语
Carbon的命名,既是对生命基石“碳”元素的致敬,也暗喻着这个模型的特质:它是构成更复杂生命智能的基本单元,朴素、坚固、不可或缺。
即日起,Carbon,正式开源。
关于“生命语言GPT”的下一章,我们正在与Hugging Face共同书写。
🔗 资源导航
模型主页:https://huggingface.co/HuggingFaceBio
技术报告:https://paperswithcode.co/paper/83340
交互式演示:https://huggingface.co/spaces/HuggingFaceBio/carbon-demo
本文技术资料由北京中关村学院导师李秋熠、Hugging Face及TIGEM联合研究团队提供。

本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢