

Stanford CS224W: Machine Learning with Graphs
代码下载:https://t.zsxq.com/tTV04
请索引第35个项目
 |  |

1. 引言
1.1 脑龄的概念
核磁共振成像(MRI)可用于评估大脑相对于个体实际年龄(或“真实年龄”)的“年龄”。在脑龄(brain-age)预测中,需要训练一个模型,将神经影像数据映射到实际年龄,模型的输出结果即为预测的脑龄。预测脑龄与实际年龄之间的差异,称为脑龄差距或脑龄差值,可以提供有关大脑健康状况和恢复能力的宝贵信息。
其原理是,如果模型能够准确预测实际年龄,那么当模型预测的脑龄高于实际年龄时,是因为它捕捉到了通常与老年大脑相关的特征。反之亦然,对于非常健康的大脑,模型预测的脑龄会低于实际年龄。
多项研究表明,大脑年龄与预期不符(脑龄差距为正值)的个体,其死亡风险、认知能力下降风险以及罹患阿尔茨海默病等神经退行性疾病的风险更高[1]。因此,脑龄模型可以作为有用的生物标志物,指导贯穿整个生命周期的脑健康干预措施。
1.2 为什么选择图神经网络?
传统的脑龄预测方法要么从图像中提取手工特征(例如区域体积或皮层厚度),要么直接将卷积神经网络应用于三维脑部扫描图像[2]。虽然这些方法效果尚可,但它们无法自然地捕捉脑网络的关联结构。基于体素的卷积神经网络将大脑视为一个规则的三维网格,但由于它无法感知大脑潜在的解剖连接,因此无法捕捉大脑作为网络的组织结构。
图神经网络(GNN)应用于脑连接数据的研究相对较新,最初的研究主要集中于疾病分类任务中的功能连接[3, 4]。针对脑龄预测,已有少量研究探索了基于GNN的功能连接或结构连接组方法[5]。然而,这些研究大多使用相对较小的数据集(数百名受试者),且并未系统地比较不同的GNN架构或图构建方式。
我们在此提出探索图神经网络,以从扩散磁共振成像纤维束追踪得到的脑结构图预测大脑年龄,并确定成功预测的重要因素。
1.3 脑结构图
大脑可以自然地被表示为一个网络:灰质区域构成节点,连接它们的白质纤维束构成边。这种表示方法被称为结构连接组,它描述了不同脑区是如何相互连接的[6]。
重要的是,这种网络组织并非随机的:大脑表现出一些特征属性,例如小世界拓扑结构(局部聚类程度高,全局通信效率高)、作为通信中心的枢纽区域(类似于大型机场作为国际航班的枢纽)以及模块化结构,其中密集连接的区域组支持特定功能[7, 8]。
这些网络特性会随着年龄而改变。老年人的大脑往往表现出通信效率下降、枢纽连接减弱以及远距离区域间整合度降低。因此,结构连接组是预测大脑年龄的一个很有前景的目标。让我们看看能否利用图神经网络来捕捉这些变化并预测大脑年龄!
2. 方法
2.1 数据
我们的样本包括来自英国生物银行[9]的10000名受试者,年龄范围为45至82岁。我们对样本的年龄分布或参与者的纳入标准没有任何限制。
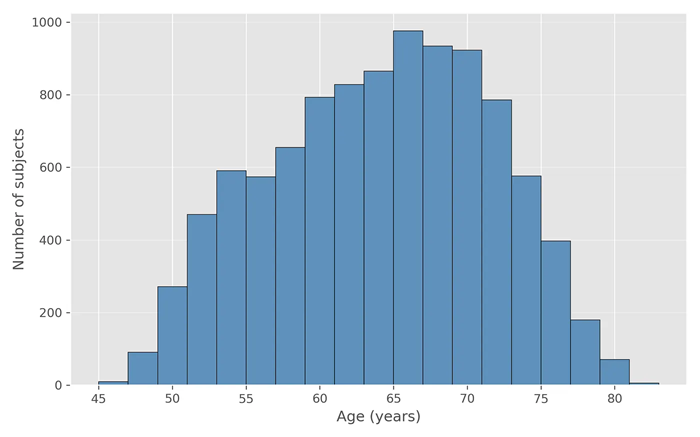
我们10000名受试者的年龄分布
2.2 扩散磁共振成像和纤维束成像
扩散磁共振成像(diffusion MRI)数据捕捉了脑组织中水分子的扩散情况[10]。在白质中,水分子优先沿轴突束扩散,因为细胞膜和髓鞘限制了水分子在其他方向上的运动。这种方向性偏好(各向异性)可用于通过称为纤维束追踪(tractography)的过程重建白质通路[11]。对于每个受试者,纤维束追踪会生成密集的白质纤维集合,每条纤维在三维空间中表现为连接两个灰质体素的折线。这些纤维将被用于构建我们大脑图的边界。
2.3 脑区划分
为了定义脑图的节点,我们需要根据预定义的图谱将大脑皮层划分为不同的区域。我们考虑了几个图谱:Glasser图谱(360个区域)[12]和Schaefer图谱(100、300、500、800个区域)[13]。此外,我们还添加了来自墨尔本皮层下图谱(Tian)的皮层下区域,分为两个尺度:S1尺度包含16个区域,S4尺度包含54个区域[14]。结合皮层和皮层下区域的划分,我们得到的脑图节点数从116个到854个不等。
2.4 脑图构建
我们构建了无向脑图,其中节点代表灰质脑区,边代表白质连接。如果至少有一条通路连接两个脑区,则我们将这两个脑区定义为一条边。
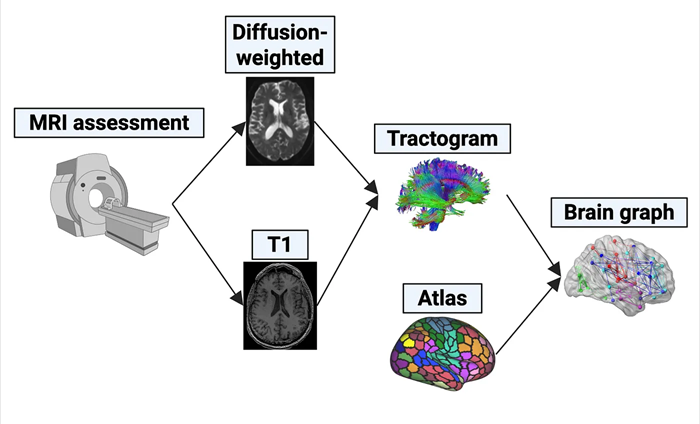
脑图构建。
2.4.1 节点特征
我们考虑了节点度(连接数)、强度(边权重之和)、聚类系数(节点邻居之间的连接程度)、特征向量中心性(基于与其他重要节点的连接程度)以及参与系数(跨网络模块的连接多样性)[15]。这些特征既反映了局部连接模式,也反映了每个节点在全局网络中的作用。以下是我们使用 Python 实现的参与系数(首先需要将节点划分为不同的模块)。
defmodularity(A, gamma=1):
"""
Produces a subdivision of the network into
nonoverlapping groups of nodes in a way that maximizes the number of
within-group edges, and minimizes the number of between-group edges.
The modularity quantifies the degree to which the
network can be subdivided into such groups.
Inputs:
W,
undirected weighted or binary connection matrix
gamma,
resolution parameter
gamma>1, detects smaller modules
0<=gamma<1, detects larger modules
gamma=1, classic modularity
Outputs:
Ci optimal community structure
Q maximized modularity
"""
N = len(A) # number of nodes
K = np.sum(A, axis=0) # degree
m = np.sum(K) # number of edges
B = A - gamma * np.outer(K, K) / m # modularity matrix
Ci = np.ones(N, dtype=int) # module indices
cn = 1# number of modules
U = [1, 0] # array of unexamined modules
ind = np.arange(N)
Bg = B.copy()
Ng = N
while U[0]:
e_vals, e_vecs = np.linalg.eig(Bg)
i1 = np.argmax(np.real(e_vals)) # maximal positive eigenvalue of Bg
v1 = e_vecs[:, i1] # corresponding eigenvector
S = np.ones(Ng, dtype=int)
S[v1 < 0] = -1
q = S.T @ Bg @ S # contribution to modularity
if q > 1e-10: # contribution positive: U(1) is divisible
qmax = q # maximal contribution to modularity
Bg[np.eye(Ng, dtype=bool)] = 0
indg = np.ones(Ng, dtype=bool) # array of unmoved indices
Sit = S.copy()
while np.any(indg): # iterative fine-tuning
Qit = qmax - 4 * Sit * (Bg @ Sit) # recompute Qit
if np.all(np.isnan(Qit[indg])) ornot np.any(indg): # break loop if all values are NaN or indg is all False
break
imax = np.argmax(Qit[indg])
imax = np.arange(Ng)[indg][imax] # find original index
Sit[imax] *= -1
indg[imax] = False
ifnot np.any(indg):
break
if np.nanmax(Qit[indg]) > q:
q = np.nanmax(Qit[indg])
S = Sit.copy()
ifabs(np.sum(S)) == Ng: # unsuccessful splitting of U(1)
U.pop(0)
else:
cn += 1
Ci[ind[S == 1]] = U[0] # split old U(1) into new U(1) and into cn
Ci[ind[S == -1]] = cn
U = [cn] + U
else: # contribution nonpositive
U.pop(0)
iflen(U) == 1and U[0] == 0: # termination condition
break
ind = np.where(Ci == U[0])[0]
bg = B[ind, :][:, ind]
Bg = bg - np.diag(np.sum(bg, axis=0)) # modularity matrix
Ng = len(ind) # number of vertices in U(1)
s = Ci[:, np.newaxis]
Q = np.sum(~(s - s.T) * B / m)
return Ci, Q
defparticipation_coef(W, Ci, flag=0):
"""
Parameters:
W, binary or weighted, directed or undirected connection matrix
Ci, community affiliation vector (from modularity)
flag, 0, undirected graph (default)
1, directed graph: out-degree
2, directed graph: in-degree
Returns:
P, participation coefficient
"""
if flag == 2:
W = W.T
n = len(W) # number of vertices
Ko = np.sum(W, axis=1) # degree
Gc = (W != 0) @ np.diag(Ci) # neighbor community affiliation
Kc2 = np.zeros(n) # community-specific neighbors
for i inrange(1, np.max(Ci) + 1):
Kc2 += np.square(np.sum(W * (Gc == i), axis=1))
epsilon=1e-10# Avoid division by zero
P = np.ones(n) - Kc2 / np.square(Ko + epsilon)
P[Ko == 0] = 0# P=0 for nodes with no (out)neighbors
return P2.4.2 边缘特征
我们计算了多个边缘权重指标。除了连接两个区域的白质束数量外,我们还计算了沿连接每对区域的流线平均的几个微观结构指标:
分数各向异性 (FA):衡量扩散的方向约束程度;对髓鞘形成和轴突密度敏感
平均/轴向/径向扩散率 (MD、AD、RD):衡量总体和方向扩散率;对组织完整性敏感
自由水 (FW):估计细胞外水含量;随萎缩增加
NODDI 指标 (ICVF、ISOVF、OD):基于模型的神经突密度、自由水和纤维弥散度估计
平均信号峰度 (MSK):捕捉非高斯扩散;反映组织复杂性
这些指标的目的是除了数量之外,还要衡量白质纤维的健康状况或质量。
2.5 图稀疏化
原始连接组矩阵非常密集,因为大多数区域对至少存在一些连接纤维束,包括纤维束追踪过程中产生的伪影。因此,有必要对图进行稀疏化,以聚焦于最有意义的连接,从而提升图神经网络(GNN)的学习效果。我们考虑了两种稀疏化方法:top-k 稀疏化和基于密度的稀疏化。
对于前 k 个连接稀疏化,我们仅保留每个节点的前 k 个最强连接。如果一条边在任一节点的前 k 个连接中,则保留该边。我们默认使用 k = 40,这样既能保留每个区域的主要投影目标,又能显著减少边的数量。
对于基于密度的稀疏化,我们保留最强的边,直到保留的边数达到总边数的一定比例。我们默认使用密度 0.1,这保留了总边数的 10%,并且与 k = 40 的 top-k 稀疏化方法得到的密度相似。
3. 实验
3.0 总体战略
在图构建阶段,有很多参数可以调整(图的大小、稀疏化方法、稀疏化阈值)。为了避免搜索空间爆炸,我们首先确定一种平衡的图构建策略:Glasser + Tian S4 分区(414 个节点),稀疏化采用密度为 0.1 的基于密度的方法。在实验结束时,我们将重新审视这一选择,并探讨不同图构建策略对模型性能的影响。
我们保留了 1000 名受试者(占 10%)作为固定测试集,该测试集在模型开发过程中从未使用。剩余的 9000 名受试者被分为训练集(约 8100 人)和验证集(约 900 人)。
我们以平均绝对误差 (MAE)作为主要评价指标,同时还报告了 R² 和预测年龄与真实年龄之间的皮尔逊相关系数。我们使用 MAE 作为损失指标,但皮尔逊相关系数对于评估模型质量至关重要,因为它具有尺度鲁棒性,并且能够直接衡量模型捕捉年龄相关变化的能力(而 MAE 则取决于初始年龄分布)。
3.1 第一阶段:基线 GCN
我们首先采用标准的图卷积网络(GCN) [16]作为基线模型。初始模型使用3层,隐藏层维度为128,采用均值池化进行图级读取,使用dropout(p=0.2),进行图归一化,并且除了图结构本身之外,没有其他节点特征。
基于此基线,我们得到的皮尔逊相关系数仅为0.05,平均绝对误差 (MAE) 为6.24 年。该模型几乎没有任何预测能力,表明图拓扑结构本身并不包含任何有用信息。
通过添加从图结构导出的节点特征(度、强度、聚类系数、特征向量中心性和参与系数),我们实现了0.47的相关性和5.46 年的 MAE ,这令人鼓舞,表明数据实际上包含可用的信号。
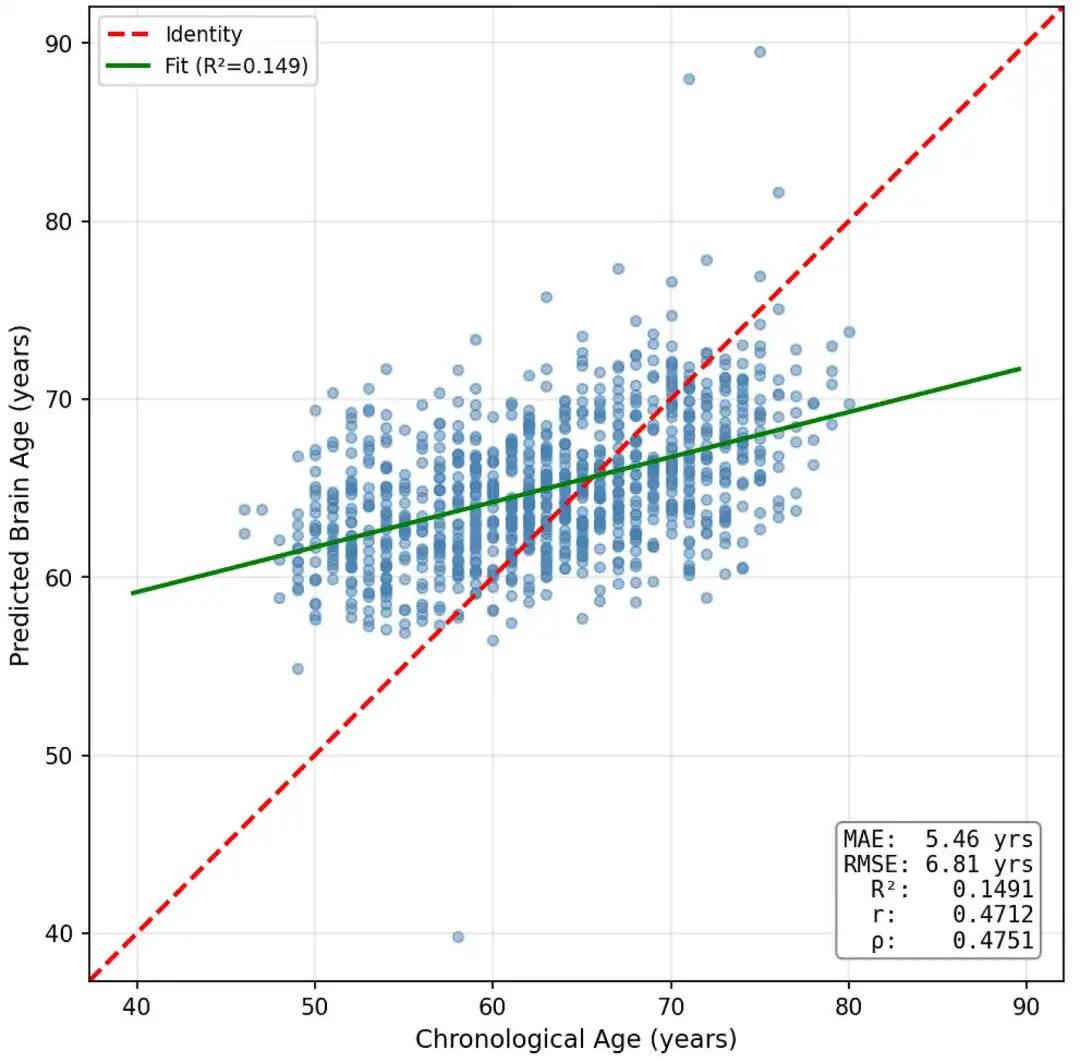
使用所有节点特征的 GCN(3 层,128 个隐藏维度)
3.2 第二阶段:GraphSAGE
为了提升基线 GCN 的性能,我们尝试将 GCN 的隐藏层维度增加到 256,结果相关性为 0.51,平均绝对误差 (MAE) 为 5.30,提升幅度不大。这表明模型容量并非瓶颈,模型也未出现欠拟合现象,因此我们开始探索不同的 GNN 架构。
通过改用GraphSAGE [17](它在将节点自身的嵌入及其邻居的嵌入组合起来之前,分别处理它们),我们实现了0.64的相关性和4.57 年的 MAE ,这是一个显著的进步。
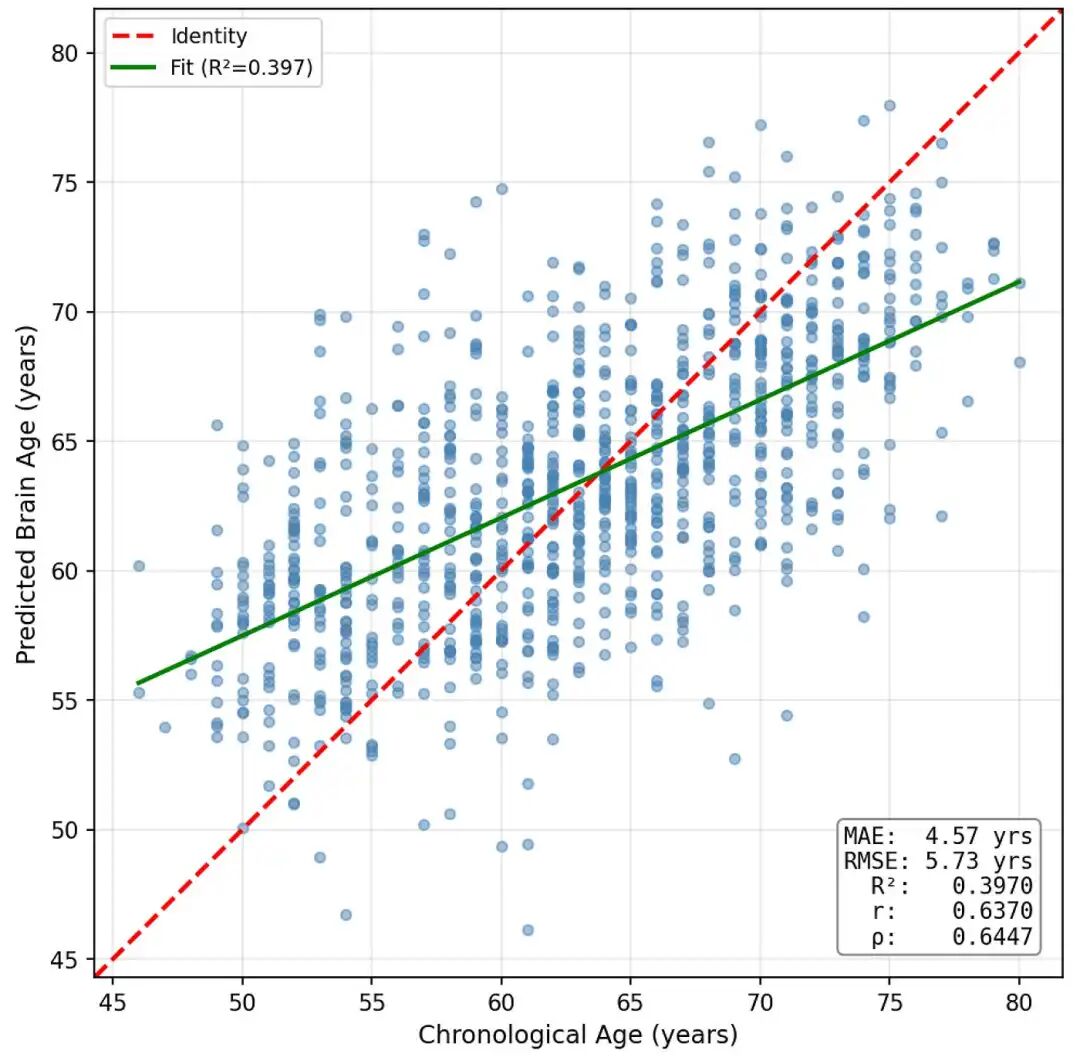
GraphSAGE(3 层,256 个隐藏维度)
让我们通过公式来理解这种改进。GCN 使用归一化邻接矩阵来计算节点更新:
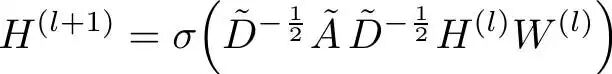
GCN更新公式
其中 Ã= A + I,D 是节点度矩阵,H 是节点特征,W 是可学习的权重矩阵。GCN 将邻居嵌入和自身嵌入混合使用相同的变换,这可能会模糊节点身份并导致过度平滑。
另一方面,GraphSAGE(均值)将这两种嵌入分开,为自身嵌入和邻居嵌入分别使用不同的可学习权重矩阵:
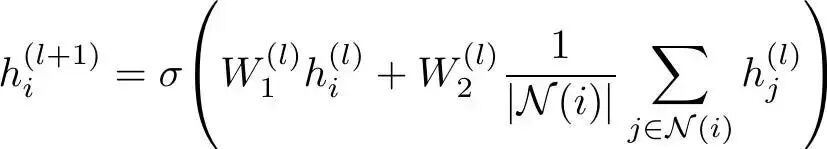
GraphSAGE 更新公式
因此,GraphSAGE 通过在更新中区别对待自身和邻居嵌入,能够保留区域的“身份”,并且某些与衰老相关的特征很可能是区域特有的。
3.3 第三阶段:边缘属性作为一等公民
到目前为止,我们的模型并没有充分利用边属性。图卷积网络(GCN)在一定程度上利用边权重来缩放消息,但我们目前为止最好的模型 GraphSAGE 完全没有使用边权重。然而,我们构建的边属性中包含大量相关信息,例如描述每个白质连接质量的微观结构指标(FA、MD、NODDI 等)。
为了更好地利用边中的信息,我们采用了GINE(带边特征的图同构网络) [18, 19] 架构,该架构将边属性显式地融入到消息传递过程中。GINE 并非简单地聚合邻居特征,而是基于边属性来调节消息:
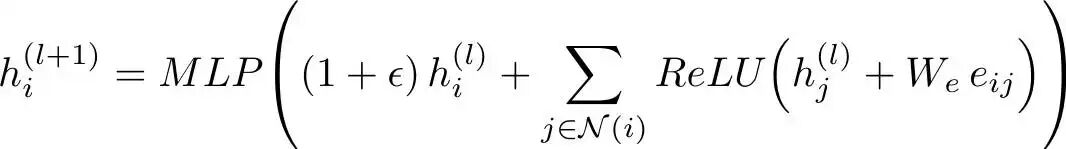
GINE 更新公式
其中 e 表示边缘特征,W 是一个线性映射,将边缘特征投影到节点嵌入的维度上。
GINE 的代码是:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GINEConv, GraphNorm, global_add_pool
classGINERegressor(nn.Module):
"""
Graph Isomorphism Network with Edge features for regression.
Parameters:
in_channels : int
Number of input node features.
edge_dim : int
Number of edge features.
hidden_channels : int
Hidden dimension for all layers.
num_layers : int
Number of GINE layers.
dropout : float
Dropout probability.
out_channels : int
Output dimension (1 for regression).
"""
def__init__(
self,
in_channels: int,
edge_dim: int = 0,
hidden_channels: int = 256,
num_layers: int = 3,
dropout: float = 0.2,
out_channels: int = 1,
):
super().__init__()
if num_layers < 1:
raise ValueError("num_layers must be >= 1")
self.edge_dim = edge_dim
self.dropout = dropout
# Projection of input to hidden dimension
self.input_proj = nn.Linear(in_channels, hidden_channels)
# GINE layers
self.convs = nn.ModuleList()
self.norms = nn.ModuleList()
for _ inrange(num_layers):
# MLP for GINEConv aggregation
mlp = nn.Sequential(
nn.Linear(hidden_channels, hidden_channels),
nn.ReLU(),
nn.Linear(hidden_channels, hidden_channels),
)
conv = GINEConv(mlp, edge_dim=edge_dim if edge_dim > 0elseNone)
self.convs.append(conv)
self.norms.append(GraphNorm(hidden_channels))
# Prediction head
self.readout = nn.Linear(hidden_channels, out_channels)
defforward(self, data):
"""
Forward pass.
Parameters:
data : torch_geometric.data.Data
Graph data with attributes:
- x: Node features [num_nodes, in_channels]
- edge_index: Edge connectivity [2, num_edges]
- edge_attr: Edge features [num_edges, edge_dim]
- batch: Batch assignment [num_nodes]
Returns:
torch.Tensor
Predicted values [batch_size].
"""
x, edge_index = data.x, data.edge_index
edge_attr = getattr(data, "edge_attr", None)
batch = getattr(data, "batch", None)
# Handle edge_attr based on edge_dim
if self.edge_dim == 0:
edge_attr = None
# Handle single graph case (no batch tensor)
if batch isNone:
batch = torch.zeros(x.size(0), dtype=torch.long, device=x.device)
# Input projection
x = self.input_proj(x)
# GINE layers
for conv, norm inzip(self.convs, self.norms):
x = conv(x, edge_index, edge_attr=edge_attr)
x = norm(x, batch)
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training)
# Global pooling (sum)
hg = global_add_pool(x, batch)
# Prediction
out = self.readout(hg).squeeze(-1)
return out此次架构变更显著提升了性能。GINE 使用了全部 13 个边缘属性(FA、MD、AD、RD、FW、NODDI 指标、MSK 和流线计数),相关性跃升至0.76,平均绝对误差 (MAE) 降至3.80 年。R² 达到 0.57,这意味着该模型现在可以解释超过一半的年龄方差。
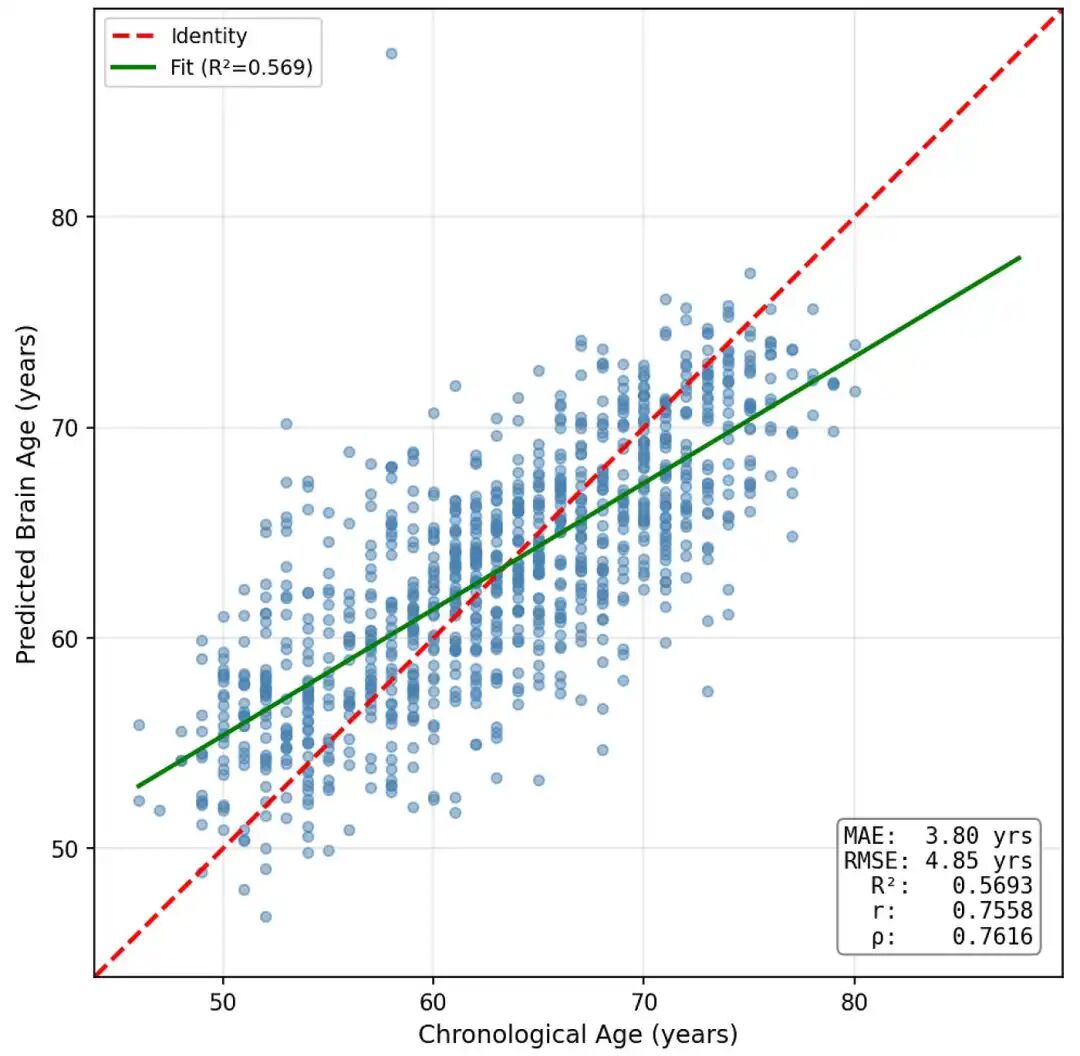
GINE(3 层,256 个隐藏维度)
这证实了白质连接的“质量”(而不仅仅是它们的存在)对于预测大脑年龄非常重要,并且考虑到这一点,与我们最好的仅拓扑模型相比,误差减少了近一年。
3.3.1 关于 GINE 与 GAT 的说明
我们尝试了GAT(图注意力网络),它也可以利用边属性中包含的信息。结果比GraphSAGE好,但比GINE差,相关性为0.69,平均绝对误差为4.34年。
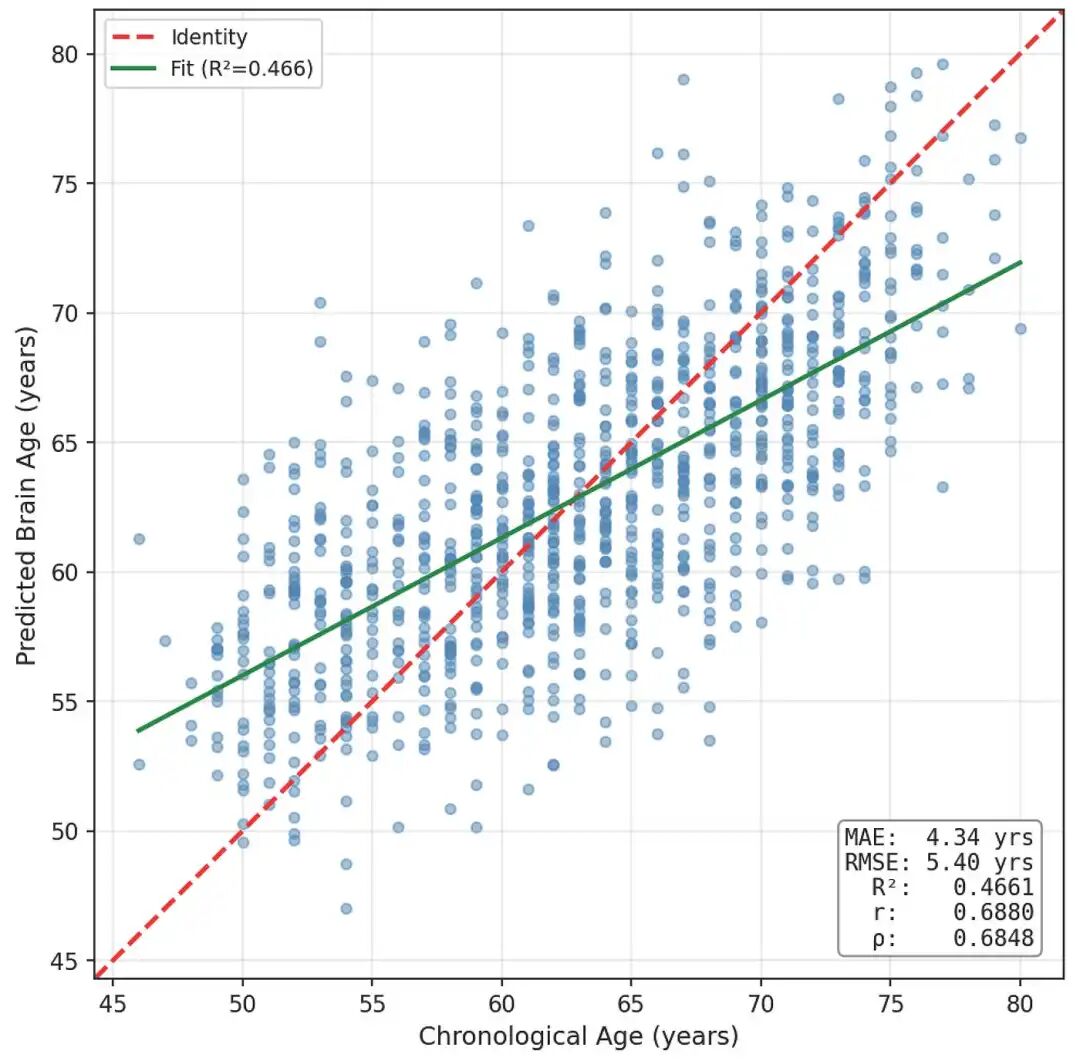
GAT(3 层,256 个隐藏维度)
为了理解这一点,让我们回顾一下 GAT 更新:
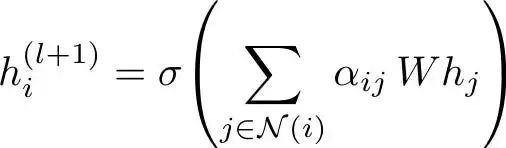
GAT 更新
其中,α(注意力系数)定义如下:
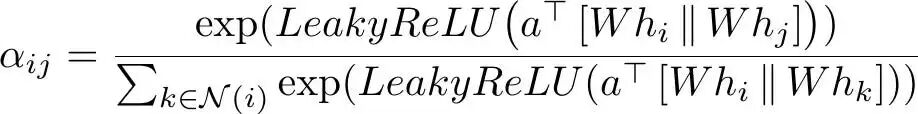
GAT注意力系数
GINE 和 GAT 在边缘特征处理方面的主要区别在于,GAT 使用边缘特征来计算注意力分数,但聚合本身仅基于节点特征。正如我们前面看到的,GINE 能够直接将边缘特征融入其消息中,从而塑造节点间的信息流,更好地利用边缘属性中包含的微观结构信息。
3.3.2 关于 GINE 与 GIN 的说明
为了确保性能提升来自边属性而不是来自 GINE 更新的 MLP,我们测试了标准GIN(图同构网络) [18],其架构与GINE相同,但没有边属性。
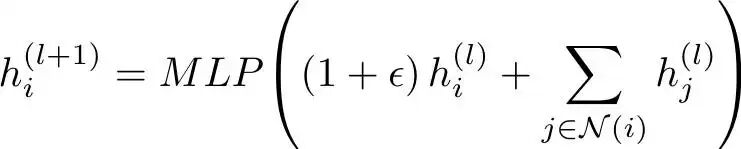
GIN 更新
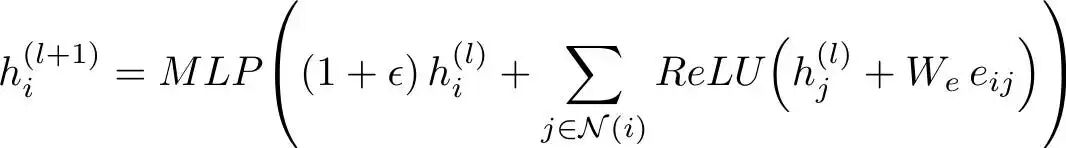
GINE 更新
我们发现GIN 的表现明显不如GINE,相关性为0.61,MAE 为4.73 年,证实了 GINE 在我们的连接组数据中严格优于 GIN,因为连接组数据的边缘属性具有生物学意义。
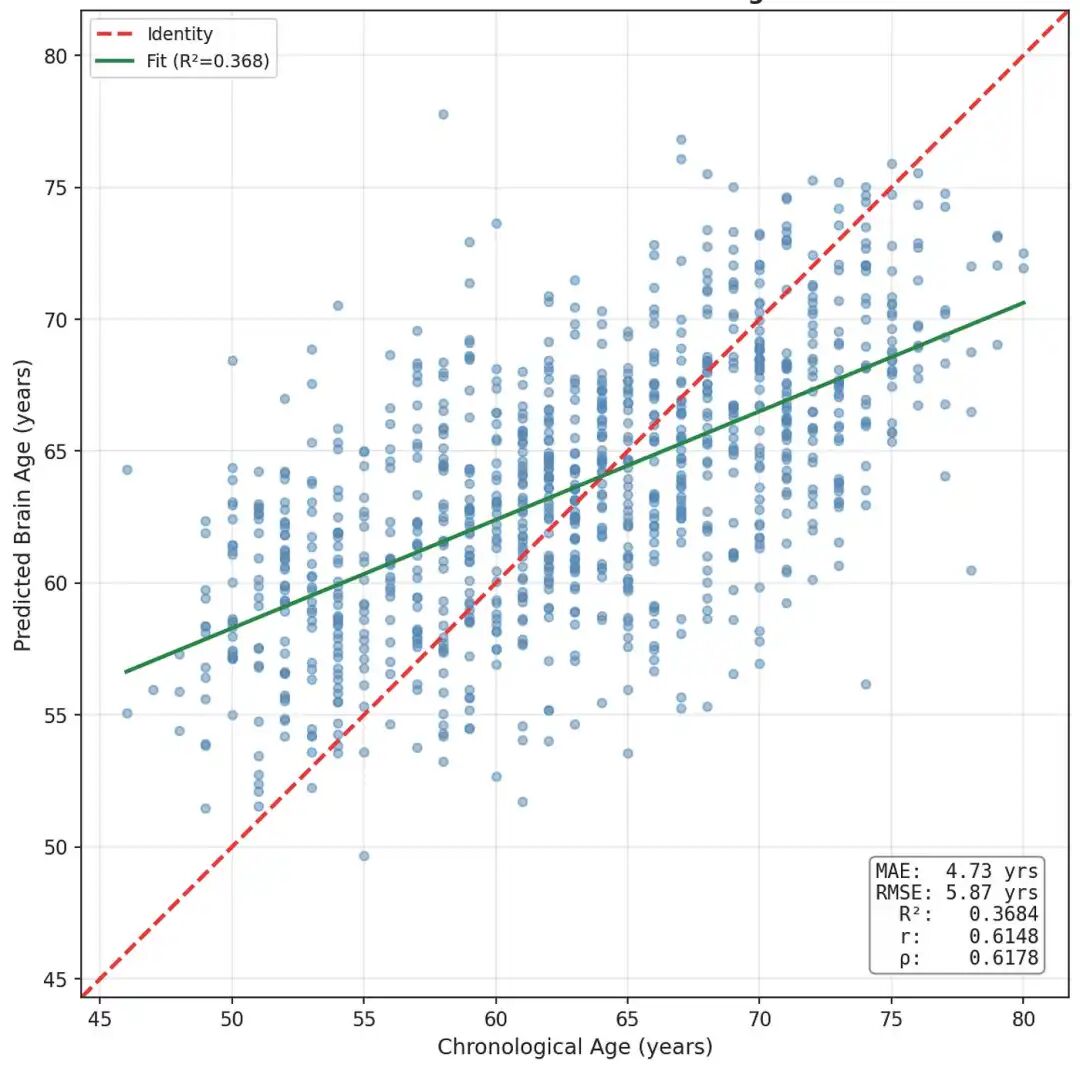
GIN(3 层,256 个隐藏维度)
3.4 第四阶段:稀疏性扫描
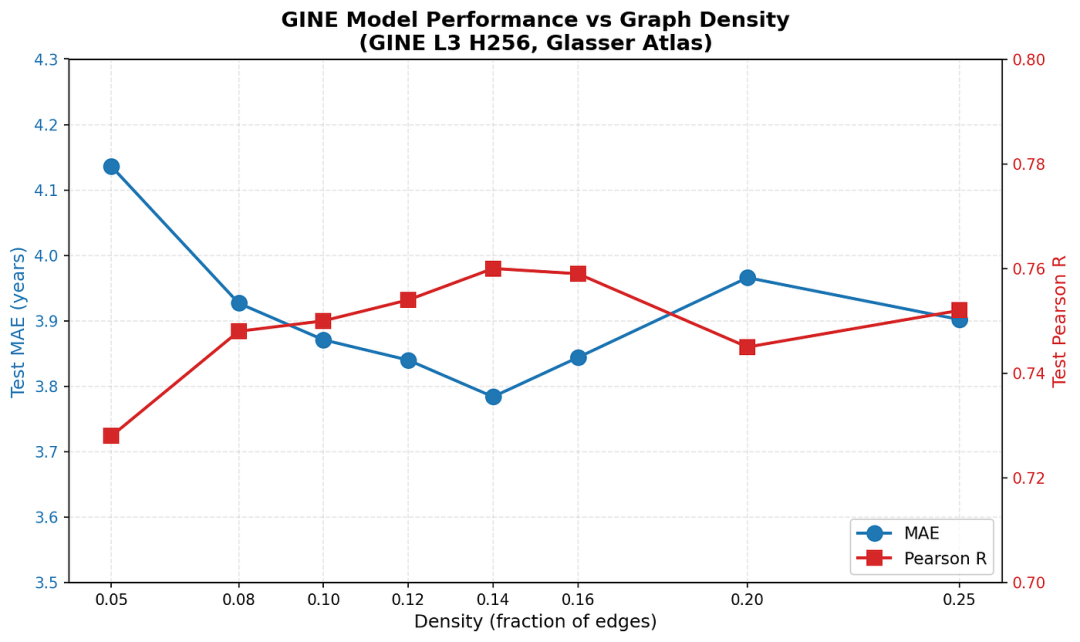
在确定GINE是我们最佳的架构之后,我们开始对探索图中不同程度的稀疏性感兴趣,首先是基于基于密度的稀疏化方法:
图密度与性能
我们注意到,随着图的密度增加,性能有所提升,但这种提升存在一个临界点。似乎存在一个最佳密度值,约为 0.14,更高的密度反而会导致性能下降。较弱的连接很可能是人为造成的,添加这些连接反而会增加噪声而非信号。
然而,结果也表明,稀疏图的效果非常出色。当密度设置为 0.08(仅保留总边数的前 8%)时,我们仍然获得了0.75的相关性和3.9 年的平均绝对误差 (MAE) ,与密度更高的图非常接近。这表明,最强的连接承载着主要的年龄相关预测信号,而较弱的连接只是添加了更精细的细节,以进一步完善预测结果。
我们还测试了另一种稀疏性方法:top-k 稀疏化,它保留每个节点的 k 个最强连接。
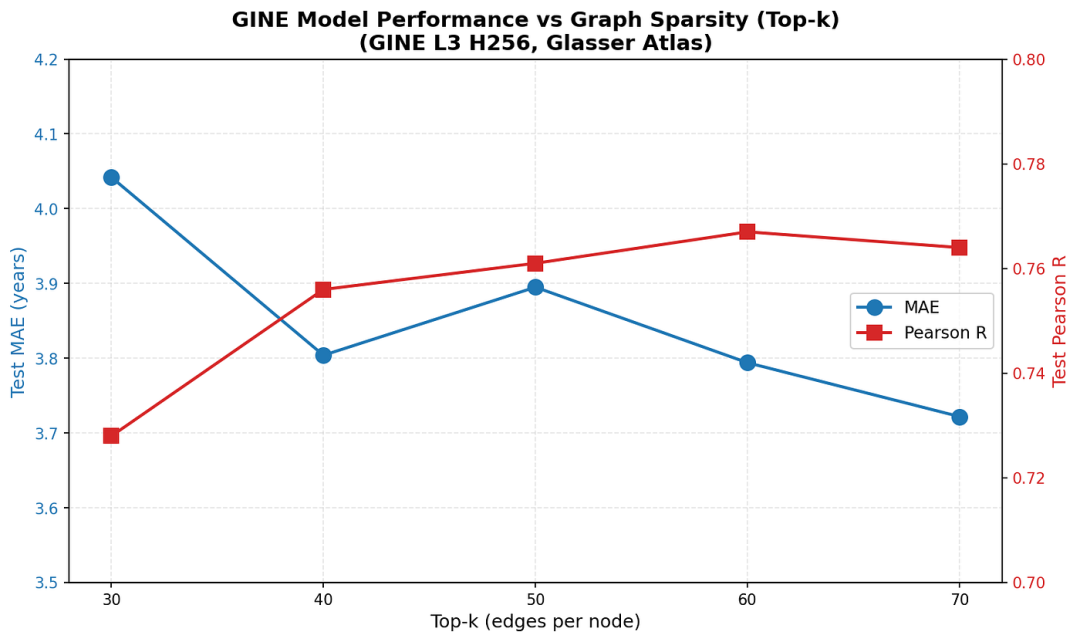
Top-k 参数与性能
值得注意的是,这次扫描的范围要窄得多,因为top_k = 30 ~ density = 0.07 和 top_k = 70 ~ density = 0.17。因此,我们观察到与密度扫描类似的趋势,即对于相对稀疏的图,增加更多边会导致更好的性能。
3.5 阶段 5:图分辨率扫描
然后,我们通过使用不同的脑区划分方法探索了各种图分辨率。需要说明的是,我们考虑了几种皮层划分图谱,这些图谱产生了不同大小的图:从 116 个节点(Schaefer 100 + Tian S1)到 854 个节点(Schaefer 800 + Tian S4)。到目前为止,我们所有的实验都是使用 Glasser + Tian S4 划分方法(414 个节点)进行的。
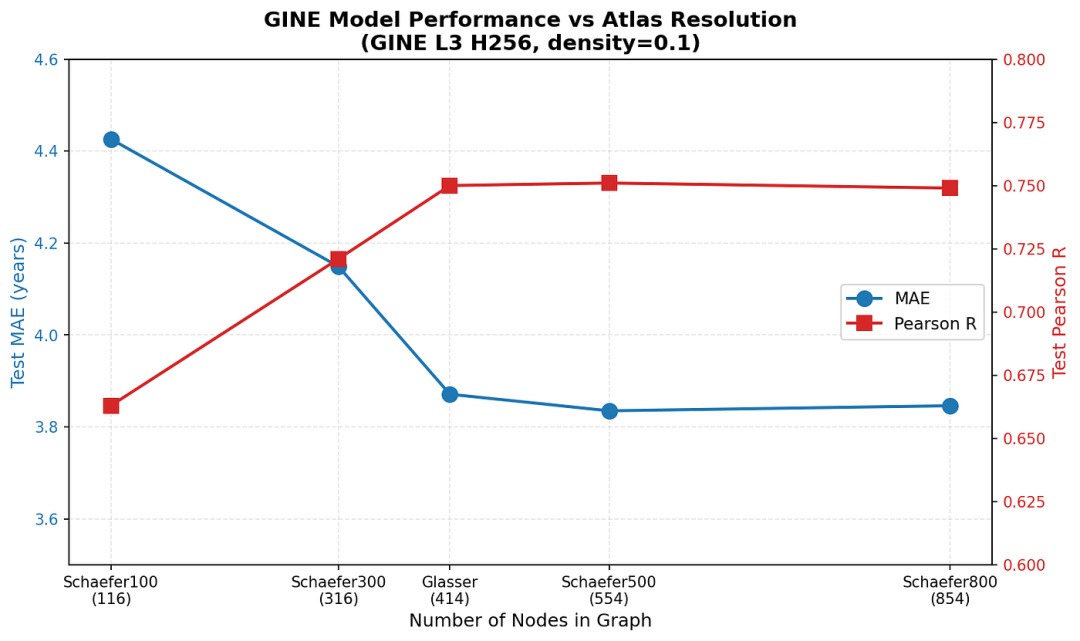
图表大小与性能
我们发现,从低分辨率(100个地块)到中高分辨率(500个地块)的划分,性能显著提升。这表明,粗略的地块划分会平均掉对年龄预测至关重要的局部微观结构变化。
我们还注意到收益递减现象,进一步提高分辨率并不能带来额外益处。可能是因为图像噪声过大,增加的空间分辨率无法提供与大脑衰老相关的信号。
3.6 第六阶段:边缘特征消融
由于我们的大部分收益都来自于边缘属性,因此一个自然而然的问题是确定每种边缘属性对模型性能的重要性。这也有助于理解哪种白质健康生物标志物对预测大脑年龄最为重要。
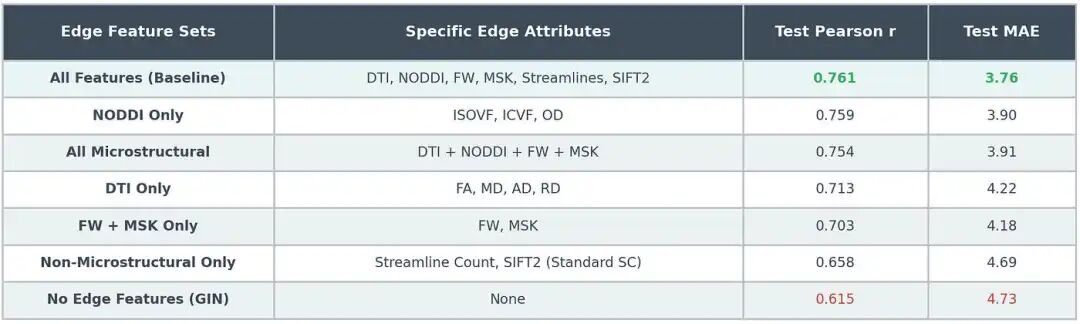
边缘特征消融
结果证实,微观结构特征是性能的主要驱动因素,优于标准连接组权重(流线计数和SIFT2衍生计数)。具体而言,NODDI指标(ICVF、ISOVF、OD)似乎包含最密集的预测信号,因为仅使用NODDI特征的模型与使用所有特征的模型几乎达到了相同的性能。
这表明,对于脑龄预测而言,组织微观结构完整性(由NODDI测量)比宏观尺度的纤维密度(由流线和SIFT2计数测量)或简单的DTI指标更具信息价值。将其他微观结构指标(如DTI或自由水)添加到NODDI中并没有真正提高预测性能,这表明它们提供的信息是冗余的。
4. 结论
总之,我们的结果表明,在结构连接组上使用图神经网络(GNN)可以捕捉到有意义的大脑衰老模式,尤其是在使用微观结构边缘属性、足够精细的脑区划分以及合适的图密度时。GINE架构取得了最佳性能,凸显了从纤维束追踪中提取的大脑图中边缘特征的价值。
尽管我们初步的实验在脑龄预测方面尚未超越以往的模型,但这仍然是一个很有前景的方向,因为它基于与现有方法不同的信息类型(脑区之间的结构连接模式,而非图像或功能连接)。我们可以设想,未来的方法会将来自不同模态(T1加权像、结构连接、功能连接)的信息融合起来,以提高预测精度,其中基于脑结构连接的图神经网络(GNN)可以作为多模态流程中的一个模块。
参考文献
[1] Gaser C, et al. BrainAGE in mild cognitive impaired patients: predicting the conversion to Alzheimer’s disease. *PLoS ONE*. 2013.
[2] Cole JH, Franke K. Predicting age using neuroimaging: innovative brain ageing biomarkers. *Trends in Neurosciences*. 2017.
[3] Ktena SI, et al. Metric learning with spectral graph convolutions on brain connectomes. *NeuroImage*. 2018.
[4] Parisot S, et al. Disease prediction using graph convolutional networks: application to autism spectrum disorder and Alzheimer’s disease. *Medical Image Analysis*. 2018.
[5] Stankevičiūtė K, et al. Population graph GNNs for brain age prediction. *MLCN Workshop, MICCAI*. 2020.
[6] Sporns O, Tononi G, Kötter R. The human connectome: a structural description of the human brain. *PLoS Computational Biology*. 2005.
[7] Bassett DS, Bullmore ET. Small-world brain networks. *The Neuroscientist*. 2006.
[8] van den Heuvel MP, Sporns O. Network hubs in the human brain. *Trends in Cognitive Sciences*. 2013.
[9] Sudlow C, et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. *PLoS Medicine*. 2015.
[10] Le Bihan D, et al. Diffusion tensor imaging: concepts and applications. *Journal of Magnetic Resonance Imaging*. 2001.
[11] Mori S, van Zijl PCM. Fiber tracking: principles and strategies — a technical review. *NMR in Biomedicine*. 2002.
[12] Glasser MF, et al. A multi-modal parcellation of human cerebral cortex. *Nature*. 2016.
[13] Schaefer A, et al. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity MRI. *Cerebral Cortex*. 2018.
[14] Tian Y, et al. Topographic organization of the human subcortex unveiled with functional connectivity gradients. *Nature Neuroscience*. 2020.
[15] Rubinov M, Sporns O. Complex network measures of brain connectivity: uses and interpretations. *NeuroImage*. 2010.
[16] Kipf TN, Welling M. Semi-supervised classification with graph convolutional networks. *ICLR*. 2017.
[17] Hamilton WL, Ying R, Leskovec J. Inductive representation learning on large graphs. *NeurIPS*. 2017.
[18] Xu K, et al. How powerful are graph neural networks? *ICLR*. 2019.
[19] Hu W, et al. Strategies for pre-training graph neural networks. *ICLR*. 2020.



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢