
导读: 大型语言模型 (LLM) 在模拟类人社交行为方面展现出潜力。社交图谱提供高质量的监督信号,这些信号编码了局部交互和全局网络结构,然而,但它们在 LLM 训练中仍未得到充分利用。为了弥补这一不足,阿里妈妈联盟算法团队提出了 Graphia——一个通用的基于 LLM 的社交图谱模拟框架。它利用图数据作为LLM 后训练阶段的监督信息,并引入强化学习机制:基于图神经网络 (GNN) 的结构奖励来训练专门的智能体,使其能够预测与谁交互(目标选择)以及如何交互(边生成),然后通过预先设计的图生成流程进行操作。
团队在以下两种设置进行评估:微观层面的TDGG任务,采用节点级交互对齐指标;以及宏观层面的IDGG任务,我们提出了用于对齐涌现网络属性的指标。
在三个真实世界的网络上,Graphia 在微观层面的对齐方面,综合目标选择得分提高了 6.1%,边分类准确率提高了 12%,边内容 BERTScore 提高了 27.9%。在宏观层面的对齐方面,它实现了更高的结构相似性和对幂律和回音室效应等社会现象的复现效果。
实验结果表明,社交图可以作为 LLM 训练后的高质量监督信号,提升LLM智能体的社会模拟仿真度。
该工作相关论文已被ACL 2026收录。

标题:GRAPHIA: Harnessing Social Graph Data to Enhance LLM-Based Social Simulation
作者:Jiarui Ji, Zehua Zhang, Zhewei Wei, Bin Tong, Guan Wang, Bo Zheng
链接:https://arxiv.org/abs/2510.24251
GitHub:https://github.com/Ji-Cather/Graphia.git
1、背景
基于大语言模型的社会模拟已成为计算社会科学的新兴范式,能够大规模探索回声器、信息传播等涌现社会现象。然而,现有方法在微观交互和宏观结构之间存在割裂,面临三个关键挑战:
(1)传统深度学习图生成模型仅能建模图拓扑结构[2,3],无法捕捉底层文本驱动的社会活动;而基于 LLM 的模拟器依赖定性案例研究或特定场景流水线(如 Twitter 模拟)[4],缺乏泛化能力。
(2)缺乏一个通用的训练框架,能够利用社交图数据作为监督信号,同时优化微观交互和宏观结构。现有 LLM 社会模拟方法多为免训练(training-free),无法从图数据中学习结构属性(如度分布、同质性)。
(3)缺乏统一指标来定量评估模拟社交图在交互和结构上与真实网络的匹配程度。微观评估依赖 LLM-as-a-judge,易受提示词影响;宏观评估局限于定性验证,难以跨数据集比较。
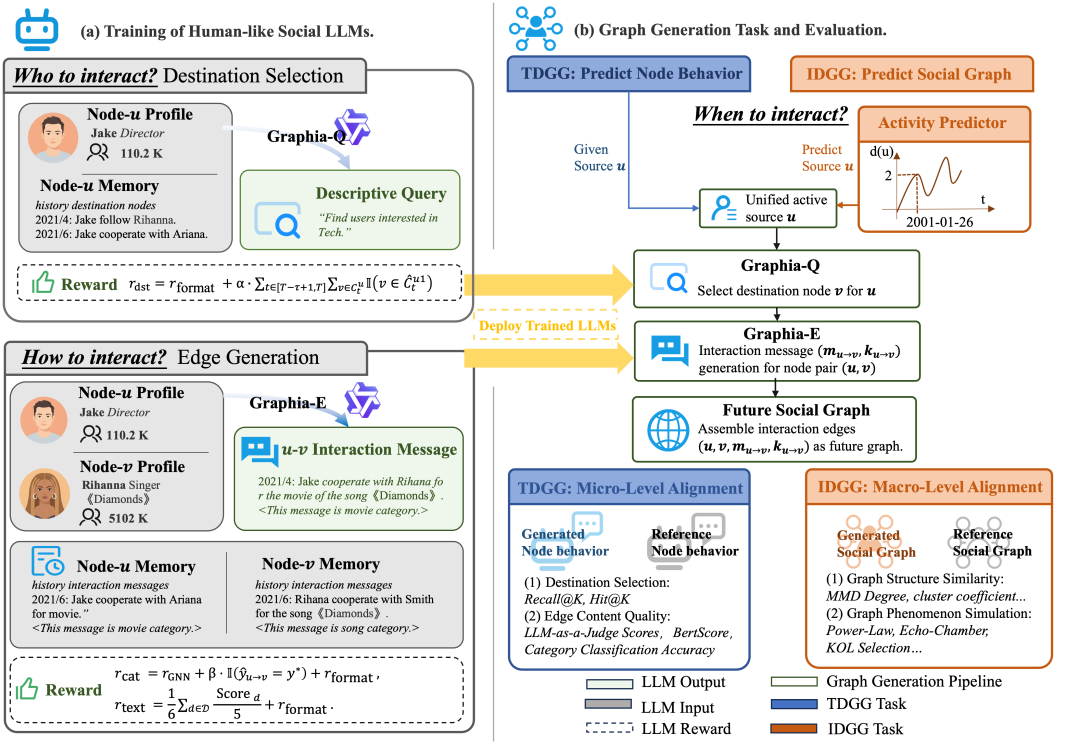
2、方法:Graphia 框架
2.1 问题形式化
我们关注动态文本属性社交图中的人类行为建模。社交图表示为时间戳子图序列
按照 GDGB 基准,我们将社会图模拟任务分解为两个设置:
● TDGG(Transductive Dynamic Graph Generation):给定源节点集合,评估微观交互对齐能力
● IDGG(Inductive Dynamic Graph Generation):源节点未知,需要建模完整的图演化过程,评估宏观结构对齐能力
2.2 Graphia 学习框架
Graphia 的核心是将社交图作为高质量监督信号用于 LLM 后训练。整体框架包含三个关键模块:
(1)活动预测(Activity Prediction) 为捕捉哪些节点会变得活跃,我们引入 Activity-Predictor,基于 Informer 架构实现。对于每个源节点 u,输入历史出度序列,预测未来时间窗口内的出度。预测的出度作为结构先验,用于 IDGG 任务中识别未来活跃的源节点。
(2)交互策略学习(Interaction Policy Learning)
我们将 LLM 视为通过强化学习训练的策略模型,训练两个专用 LLM:
● Graphia-Q(目标节点选择):对于每个源节点 u,生成描述性查询来检索候选目标节点集合。我们设计混合奖励函数,包含格式奖励和检索准确率奖励,训练 LLM 生成能准确检索真实目标节点的查询。我们采用 GRPO 优化模型。
● Graphia-E(边生成):为每个节点对 (u, v) 生成交互消息和交互类别。我们设计两类奖励:1)类别预测:采用课程式奖励,从 GNN 软指导逐渐过渡到精确匹配;2)消息生成:采用 LLM-as-a-judge 范式,从六个维度评估(目标达成、情境保真、人格深度、动态适应、沉浸质量、内容丰富)。训练Graphia-E过程中,先用 SFT 微调 backbone LLM,然后基于设计的奖励函数用 GRPO 优化模型。
2.3 图生成流程
我们为 TDGG 和 IDGG 设计不同的生成流程:
TDGG Pipeline:(1)给定源节点 u,Graphia-Q 基于节点画像和记忆生成描述性查询;(2)用查询检索目标节点集合;(3)Graphia-E 为每个目标节点生成交互消息。
IDGG Pipeline:(1)Activity-Predictor 预测所有节点的出度;(2)选择出度大于 0 的活跃源节点;(3)对活跃源节点应用 Graphia-Q 和 Graphia-E;(4)组装完整的未来图序列。
3、实验结果
我们在三个社交网络数据集上评估 Graphia:Propagate-En(淘宝电商平台)、Weibo Tech 和 Weibo Daily(来自 GDGB[5] 基准)。
3.1 微观对齐(TDGG 任务)
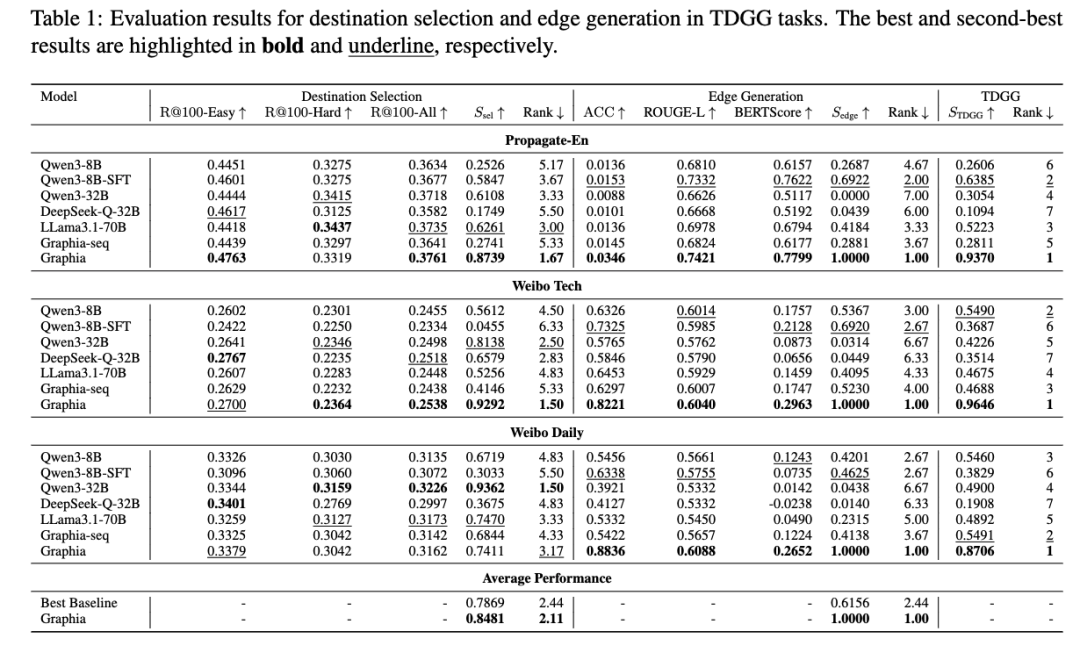
目标节点选择:Graphia 在目标选择任务中表现优异。在聚合选择得分上,Graphia 达到 0.848,超越最佳基线 Qwen3-32B 6.1%。值得注意的是,尽管基于 8B 参数 backbone,Graphia 在多个数据集上超越或媲美更大规模 LLM(如 Qwen3-32B、Llama3.1-70B)。
边生成:我们采用 LLM-as-a-judge 和自动指标进行评估。如图 2 所示,Graphia 在六个评估维度上均取得最高分,平均分超越最佳基线 0.77 点(+28%)。在自动指标上,Graphia 在类别预测准确率上平均提升 12%,BERTScore 平均提升 27.9%。
3.2 宏观对齐(IDGG 任务)
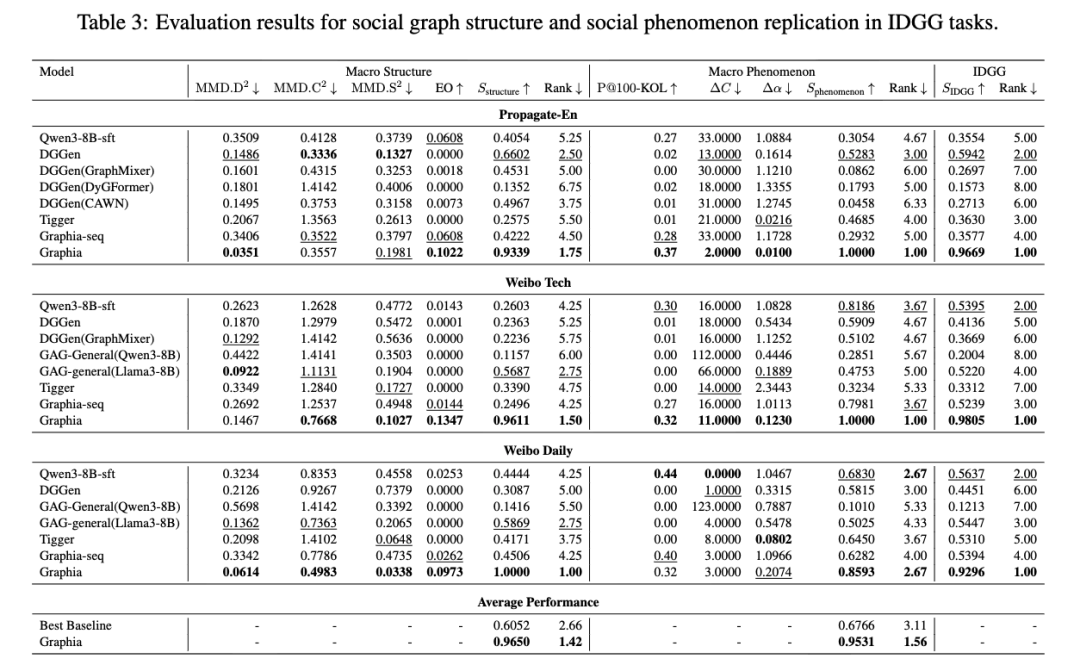
宏观结构复现:Graphia 在所有数据集上取得最低的 MMD 分数(度分布、聚类系数、谱特性),表明生成的图结构与真实网络高度相似。在边重叠(EO)指标上,Graphia 同样领先,而大多数深度学习模型 EO 接近零。
社会现象复现:我们提出三个定量指标:(1)KOL 识别精度(P@100-KOL);(2)回声器对齐(ΔC);(3)幂律指数差距(Δα)。Graphia 在这些指标上均取得最佳或次佳表现,宏观现象复现得分超越最佳基线 27.65%。
4、总结与展望
本文的贡献主要体现在以下两点:
(1)首个统一训练框架:Graphia 是首个利用社交图数据作为监督信号来增强 LLM 社会模拟的框架。通过训练专用 LLM 智能体预测"与谁交互"和"如何交互",Graphia 能够有效对齐微观行为和宏观结构。
(2)微观 - 宏观评估范式:我们扩展了 TDGG 和 IDGG 任务,提出了定量指标来联合评估交互保真度和网络真实性。实验表明 Graphia 在微观和宏观层面均显著优于现有方法。
社会网络模拟(Agent-Based Modeling, ABM)是一个长期被广泛研究的问题。随着大语言模型在人类行为模拟方面能力的显现,越来越多研究开始尝试将大模型作为中枢构建虚拟社会。
然而,现有工作往往依赖定性案例研究进行评估,在可复现性和评估标准化方面受到质疑。Graphia 提出了一种基于图数据监督的全新训练视角,以更系统、更可量化的方式提升 LLM 社会模拟的真实性。
未来工作可从以下方向深入:(1)因果机制分析:探索智能体行为背后的可解释因果驱动因素;(2)结构奖励设计:引入更高阶拓扑属性(如社区凝聚、三元闭包)到奖励函数中,提升模型在不同图结构下的泛化能力。
参考文献
🏷 关于我们
阿里妈妈联盟算法团队依托淘宝联盟与内容营销业务,基于海量时空传播图网络,构建多Treatment价量关系等先进营销算法模型,实现智能选品、智能权益投放;在程序化流量中深耕个性化排序与匹配策略,在内容营销中覆盖企划、投放到评估的全链路智能化,包括站外趋势预测、增量人群挖掘、多触点增量预估等关键技术。团队持续突破AI前沿,探索基于强化学习与大语言模型(LLM)的多模态表征、智能文案生成及营销AI Agent,并广泛应用于同款比价、内容理解、选品出价等场景。
欢迎对智能营销与算法创新感兴趣的同学加入我们!
📮 投递简历邮箱:tongbin.tb@taobao.com

关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢